

简介
之前我们已经回顾了GC算法背后的核心概念,现在开始关注JVM中可以找到的特定实现。首先要认识到的一个重要事实是:对于大多数jvm,需要两种不同的GC算法——一种用于清理年轻一代,另一种用于清理旧一代。
您可以从内嵌到JVM中的相关算法中进行选择。如果没有显式指定垃圾收集算法,将使用特定于平台的缺省值。在这一章中,我们将解释这些算法的工作原理。
下面的列表是一种快速的方法,列出了所有可能的算法组合。注意,这对于Java 8来说是正确的,对于较老的Java版本,可用的组合可能略有不同:
Young Tenured JVM options
1 Incremental Incremental -Xincgc
2 Serial Serial -XX:+UseSerialGC
3 Parallel Scavenge Serial -XX:+UseParallelGC -XX:-UseParallelOldGC
4 Parallel New Serial N/A
5 Serial Parallel Old N/A
6 Parallel Scavenge Parallel Old -XX:+UseParallelGC -XX:+UseParallelOldGC
7 Parallel New Parallel Old N/A
8 Serial CMS -XX:-UseParNewGC -XX:+UseConcMarkSweepGC
9 Parallel Scavenge CMS N/A
10 Parallel New CMS -XX:+UseParNewGC -XX:+UseConcMarkSweepGC
11 G1 -XX:+UseG1GC
上面的组合看起来太复杂,其实不要担心。实际上,这一切都归结为上表的四个组:2/6/10/11。其余的要么不受欢迎和支持,要么在现实世界中不实用。因此,在接下来的章节中,我们将介绍以下几种组合的工作原理:
- 用于年轻代和老代的串行GC(Serial GC)
- 用于新生代和老年代的并行GC(Parallel GC)
- 新生代的Parallel New + 老年代的并行标记擦除算法(CMS)
- G1:它包含了新生代和老年代的集合
Serial GC(串行GC)
串行垃圾收集器对年轻代使用标记复制算法( mark-copy),对老年代使用标记清理压缩算法( mark-sweep-compact )。顾名思义——这两个收集器都是单线程收集器,无法并行处理任务。这两种收集器还会触发stop-the-world暂停,停止所有应用程序线程。 因此,这种GC算法不能利用现代硬件中常见的多个CPU内核。与可用内核的数量无关,JVM在垃圾收集期间只使用一个内核。 可以通过以下命令启动串行垃圾收集器:
java -XX:+UseSerialGC com.mypackages.MyExecutableClass
这个选项通常在只有一个CPU的环境中运行几百兆堆大小的JVM下才有意义。对于大多数服务器端部署来说,这是一种不太常见的组合。大多数服务器端部署都是在具有多个CPU的平台上完成的,这意味着通过选择串行GC,可以人为地限制系统资源的使用。这会导致空闲资源,否则可用来减少延迟或增加吞吐量。 接着看一下使用串行GC时垃圾收集器日志是什么样子的,以及从中可以获得哪些有用的信息。为此,我们使用以下参数在JVM上打开GC日志:
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps
输出结果如下:
2015-05-26T14:45:37.987-0200: 151.126: [GC (Allocation Failure) 151.126: [DefNew: 629119K->69888K(629120K), 0.0584157 secs] 1619346K->1273247K(2027264K), 0.0585007 secs] [Times: user=0.06 sys=0.00, real=0.06 secs]
2015-05-26T14:45:59.690-0200: 172.829: [GC (Allocation Failure) 172.829: [DefNew: 629120K->629120K(629120K), 0.0000372 secs]172.829: [Tenured: 1203359K->755802K(1398144K), 0.1855567 secs] 1832479K->755802K(2027264K), [Metaspace: 6741K->6741K(1056768K)], 0.1856954 secs] [Times: user=0.18 sys=0.00, real=0.18 secs]
这段GC日志中的信息显示了关于JVM内部正在发生什么的大量信息。事实上,在这个代码片段中发生了两个垃圾收集事件,一个清理年轻代,另一个处理整个堆。让我们从分析发生在年轻一代中的第一个集合开始。
Minor GC
下面的代码片段包含关于清除年轻代的GC事件的信息:
2015-05-26T14:45:37.987-0200[1]:151.126[2]:[GC[3](Allocation Failure[4]) 151.126: [DefNew[5]:629119K->69888K[6](629120K)[7], 0.0584157 secs]1619346K->1273247K[8](2027264K)[9],0.0585007 secs[10]][Times: user=0.06 sys=0.00, real=0.06 secs][11]``
- 2015-05-26T14:45:37.987-0200 - GC事件开始时间。
- 151.126 - 相对于JVM启动时间,GC事件启动的时间。以秒为单位来衡量。
- GC - 用于区分次要GC和完整GC的标志。这一次它表明这是一个小型GC。
- Allocation Failure - GC触发的原因。在本例中,GC是由于数据结构不适合年轻代中的任何区域而触发的。
- DefNew - 使用的垃圾收集器的名称。这个神秘的名字代表单线程标记复制垃圾收集器,用于清新生代
- 629119K->69888K - 新生代GC前后大小。
- (629120K) -新生代的总大小。
- 1619346K->1273247K -GC前后使用的堆总大小。
- (2027264K) -总的堆大小。
- 0.0585007秒- GC事件持续时间(以秒为单位)。
- [Times: user=0.06 sys=0.00, real=0.06秒]- GC事件持续时间,有几个测量维度: 用户-垃圾收集器线程在此收集期间消耗的总CPU时间,用于操作系统调用或等待系统事件的系统时间 实时时间,您的应用程序已停止。
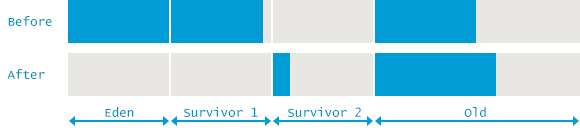
从上面的代码片段中,我们可以确切地了解在GC事件期间JVM内的内存消耗情况。在此收集之前,堆使用总量为1,619,346K。其中,年轻一代消费了629119k。由此我们可以计算出老一代的使用量为990,227K。
在下一批数字中隐藏了一个更重要的结论,表明在收集之后,年轻一代的使用量减少了559,231K,但是总的堆使用量仅减少了346,099K。由此我们可以再次推导出213,132K个物体由年轻一代提升到老一代。
下面的图演示了这个GC事件,显示了GC启动之前和结束之后的内存使用情况:
Full GC
2015-05-26T14:45:59.690-0200[1]: 172.829[2]:[GC (Allocation Failure) 172.829: [DefNew: 629120K->629120K(629120K), 0.0000372 secs[3]]172.829:[Tenured[4]: 1203359K->755802K[5](1398144K)[6],0.1855567 secs[7]] 1832479K->755802K[8](2027264K)[9],[Metaspace: 6741K->6741K(1056768K)][10][Times: user=0.18 sys=0.00, real=0.18 secs][11]
- 2015-05-26T14:45:59.690-0200 - GC事件启动时间。
- 172.829 - GC事件启动时的时间(相对于JVM启动时间)。以秒为单位来衡量。
- [DefNew: 629120K->629120K(629120K),0.0000372s - 类似于前面的例子,由于分配失败,在这个事件期间,新生代发生了一次较小的垃圾收集。对于这个集合,与以前运行相同的DefNew收集器,它将年轻一代的使用从629120K减少到0。请注意,JVM由于错误行为而错误地报告了这一点,而是报告年轻一代已经完全满了。这个收集过程花费了0.0000372秒。用于清理旧空间的垃圾收集器的永久名称。
- Tenured表示正在使用单线程stop-the-world mark-sweep-compact垃圾收集器。
- 1203359K->755802K老一代使用前后的事件。
- (1398144K)老一代人的总容量。
- 0.1855567秒的时间就完成了对老一代的清理。
- 1832479K->755802K使用了整个堆的前代和后代的收集。
- (2027264K) JVM可用的总堆。
- [Metaspace: 6741K->6741K(1056768K)]关于Metaspace集合的类似信息。可以看到,在事件期间Metaspace中没有收集垃圾。
- [Times: user=0.18 sys=0.00,real=0.18s] GC事件持续时间,在不同的类别中度量:垃圾回收线程在此收集系统调用期间消耗的用户CPU总时间,或等待应用程序停止的系统事件实际时钟时间。由于串行垃圾收集器总是只使用一个线程,因此实时时间等于用户和系统时间的总和。
与Minor GC的区别是显而易见的——除了新生代,在整个GC事件中,老年代和元数据空间也被清理了。事件前后的内存布局如下图所示:

