

本文过于枯燥,是之前探索性能优化时的笔录,但用心读完一定会提升大家对前端性能优化的认知。
性能优化的基础认知
当访问一个站点的时候,究竟做了什么 [ DNS寻址以及IP优先级 ]
根据ip访问京东首页,Status Code 301/302跳转有什么区别,实际上把跳转永久的定义到了京东域名上,京东做了另一次寻址,因为静态访问ip的时候是固定到了某一台机器/某一个机房的服务器了,京东为什么这样做?它可以直接把ip解析给我,也可以看站点实际是没问题的,它可以重新把它定义到它的域名服务器上,通过域名服务器去查找哪一个ip服务器离我最近,也有可能是网络环境/链路最好,ip返回给我,这样访问京东体验是最好的,所以这样做。
当我们登陆的时候也用到域名这个东西,在用户登陆当中实际是要种cookie的,怎么判断每一个请求是否合法,是否需要登陆,在第一次登陆时候,往我本地种了一个cookie;在登陆一次之后,每次发送请求的时候都会把我登陆时候服务器种下的cookie带过去,它检测到有这个cookie就认为我是合法用户,其实session这个东西不存在的,只是服务器端维护了一个临时缓存来验证我是否登陆了。
域名如何解析?
刚才是在www.baidu.com实际进入到子域名之后www变了,并不是后面的.com变了,实际上在输入地址的时候,是先解析的.com,当然.com之前还有一个.[面试的时候如果说先解析什么,解析的不是.com是.],.是什么 是公网,是最外层的域名,然后才会解析到com,因为跟com平级的还有很多,然后解析到baidu的子域名,如果前面是空的话,就把w3c缩写那部分放到前面就解析到baidu首页了,最后最后解析到了news的ip,然后返回页面,由此可以看出域名是从右像左解析的,为什么说 没有加这个点,因为大部分运营商其实根本没有到公网上找这个域名去匹配ip,它自己本地可能存了一份,比如说常用的50万个网站,就是一张哈希map,它把这些域名和ip一一对应上,当访问某一个域名的时候[网络请求首先走运营商,运营商发现我本地有这个ip地址,把ip地址返回就可以了,通过ip地址定位网上的资源/站点]没有必要在上公网查,这是最常见的优化方案,很普遍,各大运营商都在用了。
没有加这个点,因为大部分运营商其实根本没有到公网上找这个域名去匹配ip,它自己本地可能存了一份,比如说常用的50万个网站,就是一张哈希map,它把这些域名和ip一一对应上,当访问某一个域名的时候[网络请求首先走运营商,运营商发现我本地有这个ip地址,把ip地址返回就可以了,通过ip地址定位网上的资源/站点]没有必要在上公网查,这是最常见的优化方案,很普遍,各大运营商都在用了。
PS:IP地址和域名是一对多的关系
一个IP可以对应多个不同的域名,但是一个域名只能对应一个IP地址。就跟人的名字一样,你可 以有多个名字。但是这些名字都是指的你。(同名同姓的是例外)
拓展资料:
- IP地址:每个连接到Internet上的主机都会分配一个IP地址,IP地址是用来唯一标识互联网上计算机的逻辑地址,机器之间的访问就是通过IP地址来进行的。IP地址采用二进制的形式表示的话很长,比较麻烦,为了便于使用,IP地址经常被写成十进制的形式,用“.”分开,叫做“点分十进制表示法”,如:127.0.0.1。
- 域名:IP地址毕竟是数字标识,使用时不好记忆和书写,因此在IP地址的基础上又发展出一种符号化的地址方案,来代替数字型的IP地址。每一个符号化的地址都与特定的IP地址对应。这个与网络上的数字型IP地址相对应的字符型地址,就被称为域名。目前域名已经成为互联网品牌、网上商标保护必备的要素之一,除了识别功能外,还有引导、宣传等作用。如:www.hstc.edn.cn。
- DNS:在Internet上域名与IP地址之间是一对一(或者多对一)的,域名虽然便于人们记忆,但机器之间只能互相认识IP地址,它们之间的转换工作称为域名解析,域名解析需要由专门的域名解析服务器来完成,DNS就是进行域名解析的服务器。域名的最终指向是IP。
- URL:统一资源定位符(英语UniformResourceLocator的缩写)俗称为网址,网址格式为:<协议>://<域名或IP>:<端口>/<路径>。<协议>://<域名或IP>是必需的,<端口>/<路径>有时可省略。如:https://www.baidu.com/。
webserver背后做的事儿
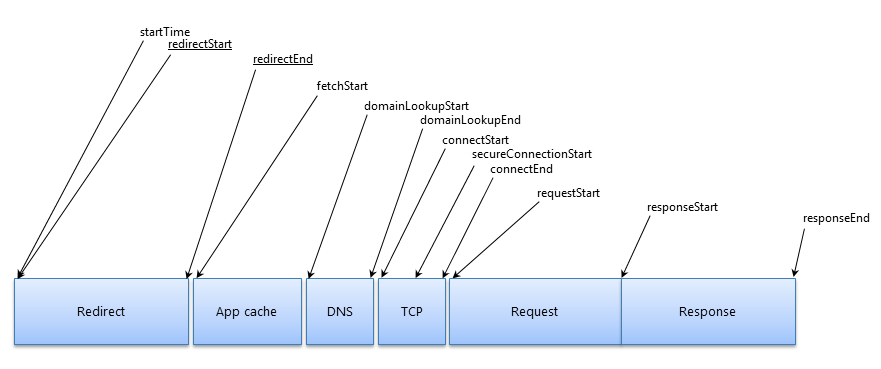
之前说DNS在倒数第三层,IP实际上是TCP这一层,但实际上IP跟TCP是相辅相成的,因为TCP是作为传输协议,是作为倒数第四层,而IP属于网络层的协议,倒数第三层,IP地址是寻址,查到了IP通过TCP传输数据,所以是相辅相成的;如果没有TCP就没有办法传输数据,找到了这个地址没有办法进行数据的交互;webserver背后的事实际上就是Request,我的客户端它去请求的时候发送到服务器,服务器在responseStart和responseEnd这中间发生了什么?还有Response之前一点的时间因为requestStart和RequestEnd到responestStart这个时间其实还有一段距离,这段距离就是服务器在做自己的处理,请求发送了,到我接受完了,OK拿数据开始处理,处理之后才是responseStart,才开始返回数据;
页面渲染流程
HTML页面请求
- HTML文档下载:
html -> 文档自身javascript -> jslink -> cssvideo -> .ogg .mp4audio -> mp3img -> 图片src - HTML文档解析:
*render树生成(可见): 偏向白话一点,颜色/距离/位置等,并不在乎结构,因为结构已经交给了上一层来完成,只关心页面显示级别的元素,display:none就不在render树里
逐级解析DOM树(p、label、a、link、javascript、尽量减少页面的reflow、js绘制dom节点会阻塞其他标签解析甚至下载,如:document.write、img);
[reflow:回流;当页面结构发生改变的时候,render树被重新组装了;margin等/repaint:重绘;不改变页面结构border-color等]
[执行document.write时候会阻塞其他js执行,也会阻塞至少一条js下载通道,下载通道:当一个页面向服务器发起请求的时候,会建立很多条通道来拉取信息,拉取过程当中有的浏览器可以建立通道有7条有的是9条,ie只有2条,通道每一个都是很宝贵的,每多一个通道就代表可以并行下载多条资源,所以当得知这个方法会阻塞通道就不要使用]
[img:如果要加载分辨率很大的图片,可以先加载分辨率小的图片占位置,用户只在乎这个位置有没有图片,当占位之后就可以加载比较清晰的图片]
浏览器的JS引擎
为什么js写完不用环境直接就能执行呢?因为我们的平台就是浏览器,跟系统跟环境没有任何关系,如果有一天浏览器不支持js支持另一种语言了,那可能就用到搭建环境了;
- V8(c++)-> V8时Google发布的开源Javascript引擎,采用C++编写,在Google的Chrome浏览器中被使用,V8引擎可以独立运行,也可以用来嵌入到C++应用程序中执行[性能最好,node也适用的这个引擎]
- SpiderMonkey -> SpiderMonkey时Mozilla项目的一部分,是一个用C语言实现的Javascript脚本引擎[火狐浏览器的开源社区]
- rhino(Java) -> Rhino是用纯Java写成的Javascript的开放源代码实现,它最常被用于嵌入Java应用程序,以使为终端用户提供脚本的能力。[假设java想调用我js代码执行并且返回想要的结果可以用到它]
使用WebPageTest分析JD的网络性
通过webpagetest工具分析国内站点,解释它的一些参数。
- 访问www.webpagetest.org/
- 为了明显看出效果,把地址修改成旧金山
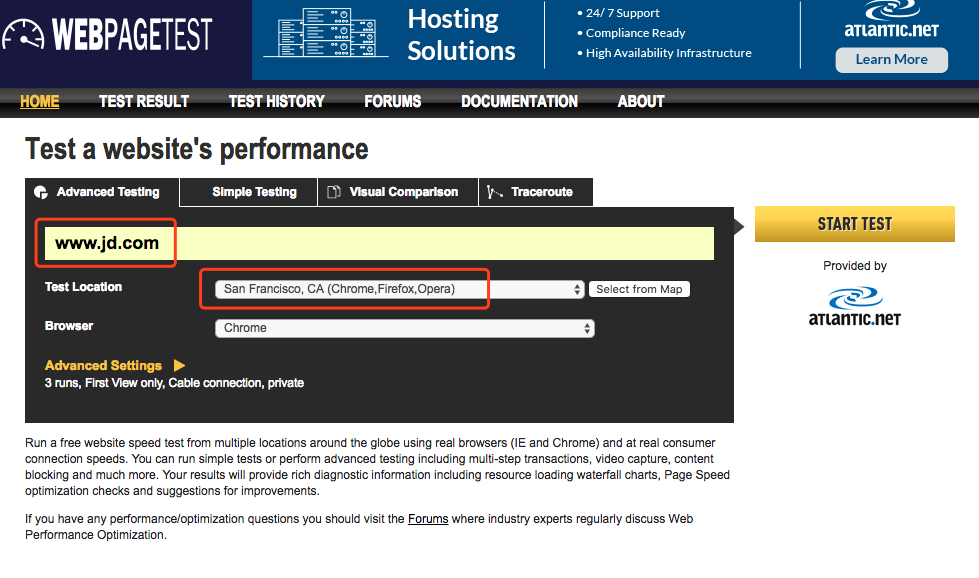
把上面串一下:之前说过url里输入网址的时候DNS解析是从右向左,然后找到域名 之后 匹配ip 建立连接 下载资源,是这样的过程。如果第一次没有查到到这个节点,路由是一个接一个,一个接一个 可能中间接入了20次or30次才找到京东节点,这样消耗时间有点多,但第二次我访问已经建立好的链路,或者说这个链路我本来没有找到,但是我的DNS里已经存储了www.jd.com,我拿到的就是jd本身的ip。实际上第二次我不是不需要解析的,我拿到了ip,不用找域名服务器,直接拿ip找jd的地址就可以了。
最后还是老规矩,欢迎大家点赞和纠错,祝各位工作日愉快
