

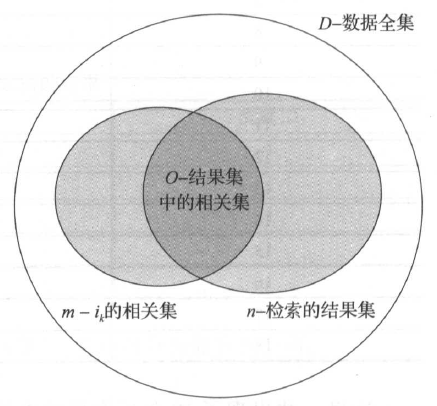
和机器学习的算法类似,信息检索或搜索的效果究竟需要如何进行科学的评估。检索质量最基本的两个评测指标是精度( Precision ) 和召回率( Recall )。假设一个数据集D中,和一个信息需求ik相关的数据集合是m,在用户输入需求后,某个检索系统返回了结果集合n ,而o是集合m和n的交集,如下图
那么精度p的定义为:
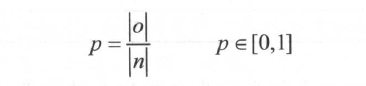
召回率r的定义为:
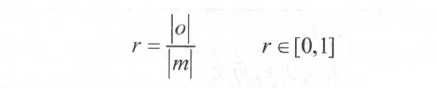
上述的定义是假设用户已经检测了整个返回的结果集合n 。试想一下真实的场景,用户最典型的行为是从头到尾开始阅读,因此随着检阅数据的不断增加,精度和召回率是不断变化的。这里将结合表(下图)提到的美食案例来进行阐述,表展示了拥有10篇文章的文档集合。后面标明了每篇文章是否包含“美食”这个关键词, 以及是否和美食的主题相关,可以看到,总共有8篇文章包含关键词“美食”,还有5篇文章是和美食主题相关。
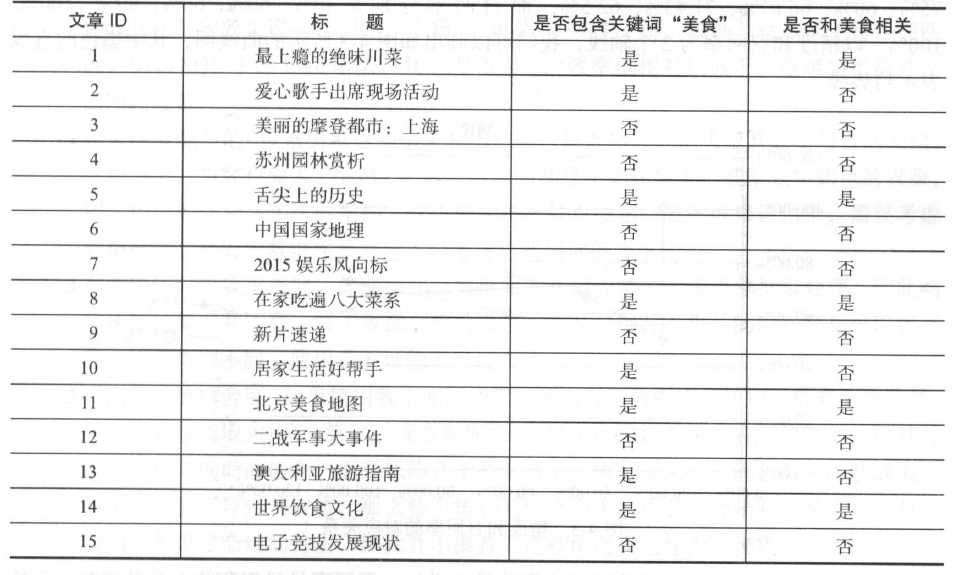
相关性的判定总是带有主观性,这也是离线测试面临的问题。在实际应用中比较像电视里播放的选秀节目,需要专业的人士来做裁判,而且可能需要多个评委来综合评定,避免个别人的主观想法影响了整个测试集合。这里让我们假设表中的判断都是准确的吧。
当用户搜索“美食”这个关键词时,某系统A 按如下形式依次返回8篇包含“美食” 关键词的文章。

假设用户从第一个排位开始阅读,直到将8个返回的结果全部读完。看到第一位的文章5,属于相关,那么这个时候的精度是1/1=100% ,其中分子1和分母1都表示文章5;召回率是1/5 = 20% ,其中分子1表示文章5,分母5表示文章1、5、8、11和14 。
再往下,看到第二位的文章10,不相关,那么这个时候的精度是1/2 = 50% ,其中分母2表示前两位的文章5和10;召回率仍然是1/5 = 20% 。依此类推,看到第三至八位后,精度分别是66.67% 、75% 、60% 、66.67% 、71.43% 、62.5% ,而召回率分别是40% 、60% 、60% 、80% 、100% 、 100% 。以精度和召回率为2个轴线,我们可以画出曲线图,其中黑色的直线表示趋势线。
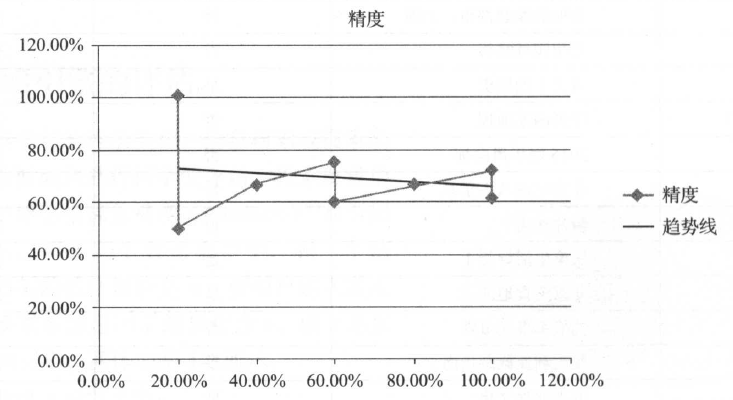
从曲线图中可以发现: 随着返回结果数量的增加,召回率是呈现逐步上升的趋势,而精度虽有波动,但整体上是下降的趋势。召回率和精度大体上是呈现反比关系。这也是实际应用中常见的模式,而且越是检索质量高的系统,这个特征越明显。可见,召回率和精度虽然都很重要,但是鱼和熊掌不可兼得。
因此,设计者应该根据实际需求,尽量均衡这两者之间的得失。例如,在识别诈骗案例的时候,一般都是希望稍有嫌疑就拉入审核的名单,因此召回率更重要,较低的精度可以通过人工审核来弥补。而在知识问答系统中,就不见得需要返回很多条的候选,只要保证排在最前面的答案足够精准即可。
精确率和召回率的概念比较简单,计算也很方便,因此广泛应用于信息检索的评估中。在此基础之上,人们又延伸和定义了其他几个常见的衡量指标,即F值、前n精度、R精度、平均精度均值、归一化折损累积增益、斯皮尔曼系数等。
