从思想出发:
实际开发中,有时候我们可能需要从不同的库中获取数据,那么这个时候我们就需要进行多数据源的配置了,既然多个数据源,那么我们肯定需要得到多个DataSource实例,在得到多个DataSource之后,就是把DataSource分配到不同的业务模块了
第一步获取不同的数据源:
使用配置类,创建多个数据源的Bean,使用注解@ConfigurationProperties(此注解的作用是把配置文件的内容封装到字段/对象/数组/集合等中,但是封装单个key-value用@value),使用该注解把配置文件封装到bean中该属性对应的bean必须符合javaBean规范(setter/getter方法)
注解中的属性prefix:根据属性前缀获取对应的属性进行封装
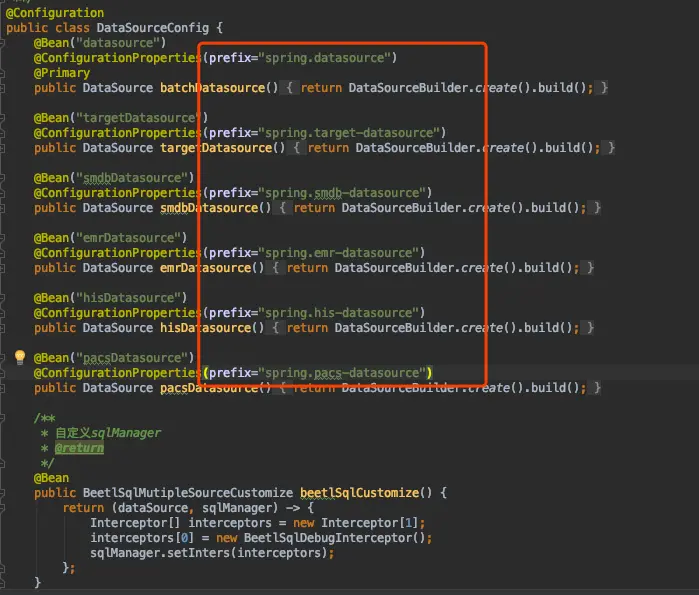
我们观察代码就可以看到prefix属性后面都填有"spring.xxx-datasource" 表示我们自定义的某个特定对象的区分前缀,当系统启动的时候,spring会自动根据我们配置prefix配置的前缀找到对应的然后解析前缀后面的字符是否符合要封装bean的属性名,然后进行封装。
我们可以结合配置文件进行观察:
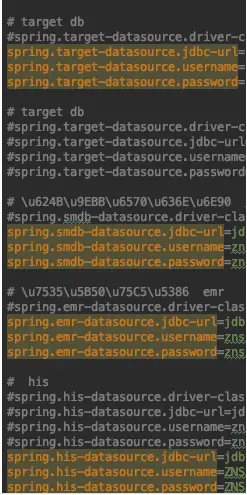
观察配置文件,我们发现我们所配置的数据源连接的key均是我们在config文件中所配置的@Configuration中属性prefix前缀然后+"."+数据源配置属性(jdbc-url/username/password)这样的结构,由此我们可以证实系统启动时,spring容器会通过@Configuration注解中的prefix定位到配置文件以prefix作为前缀的属性,然后spring会继续解析prefix . 后的属性舒服与要封装的bean的属性(实际是通过setter/getter方法,这就是为什么使用@Configuration注解,封装的Bean需要符合JavaBean规范)一致
分配DatatSource
不同的DataSource已经获取到了,那么下一步就是把DataSource分配给不同的业务模块了
那么beetlSql是怎么实现的了?
beetlSql考虑到了开发者的感受,为了使得开发者编程更加便捷,不需要在不同的service层去使用不同的DataSource,而是通过配置文件,然后把数据源与dao进行关联,那么开发者只需要在业务层对dao进行调用就可以了,那么beetlsql是怎么做到的呢
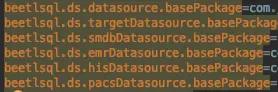
我们观察上述配置的key:都是beetlsql.ds为前缀,这意味着当dao执行的时候,会根据配置文件获取到定位到对应的key,然后根据前缀紧接着的DataSource的名字,然后后面紧接着的就是basePackege表示包,这个配置配置的就是数据源DataSource对应的dao所在的包路径,配置完毕以后,dao执行的时候,beetlSql就会帮助我们让dao自动配合对应的DataSource操作数据
相似
Spring支持的JDBCTemplate配置多个数据源也是一样的思想:

比之传统的JDBCTemplate,只是BeetlSql又使用DI+AOP的思想,通过配置把DataSouce与对应的业务模块连接了起来
其实这所有的思想都是可以追溯到Spring的DI
补充
在上述学习的时候,我发现了@Bean的一些东西,我们创建同类多个对象的时候都会使用@Bean(name="xxx"),上面我使用@Bean注解的时候:

我们可以看到我是没有写@Bean注解的名称的,我们使用idea ctrl+p快捷键查看@Bean注解的属性有哪些
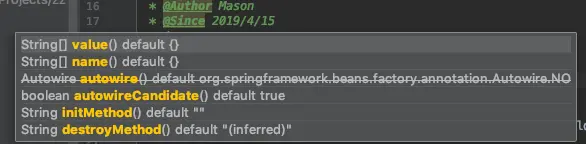
我们可以看到@Bean注解是有value属性,所以我书写@Bean("dataSource")的时候,因为@Bean存在value属性,当有且仅有一个属性value的时候,可以省略属性名称(key)不写
但是这里我们不是应该使用name属性吗?为什么使用的是value?
这个时候我们进入@Bean内部观察一下
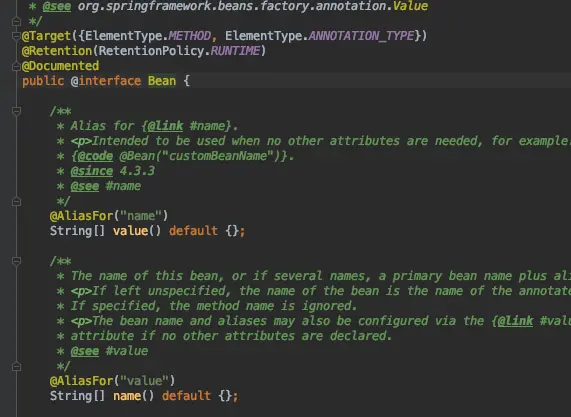
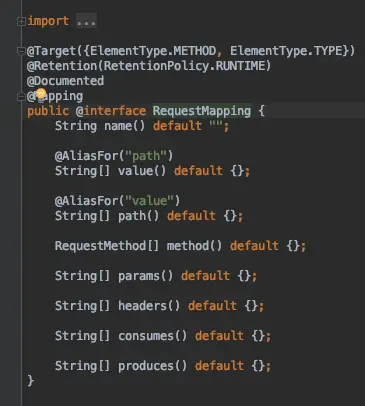
可以看到value属性上使用了一个注解@AliasFor("name"),而name属性上又有一个@AliasFor("value"),这表示属性value与name是互为别名的意思,可以互相取值
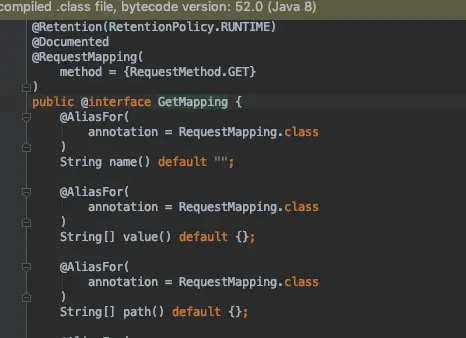
@AliasFor还用于@RequestMapping/@GetMapping等地方