

本文是RDD论文的阅读笔记。RDD是一个分布式内存抽象,用来在大集群上进行内存计算,具备容错能力。RDD主要针对迭代算法和交互式数据挖掘设计,考虑到大部分的应用程序在数据项上进行同一个操作,只允许粗粒度的变换可以简化故障恢复过程。
弹性分布式数据集(RDD)
RDD抽象
RDD是一个只读的、分区的记录集合。RDD创建的方式只能是
- 从稳定存储中加载
- 由其他RDD变换而来(例如
map,filter和join)
这样一来,RDD不需要随时备份,因为总是能够从最早的RDD变换而来。另外,RDD支持持久化和分区。持久化持久保存RDD便于再次使用,分区操作控制分区策略进行优化。
Spark编程接口
开发者可以从稳定存储加载数据,通过变换创建RDD。可以通过动作使用RDD获得返回值或者导出在存储系统。典型的动作有
count:返回数据集中的元素数量collect:返回元素本身save:保存数据集到存储系统
另外,开发者可以使用persist持久化后续会多次用到的RDD。
示例:控制台日志挖掘
假设运维人员希望从保存在HDFS中的超大日志中分析错误,那么他可以首先筛选出错误日志:
lines = spark.textFile("hdfs://...")
errors = lines.filter(_.startsWith("ERROR"))
errors.persist()
可以使用count获取错误日志的数量
errors.count()
进一步,能够在错误日志中查找更加具体的信息。
// Count errors mentioning MySQL:
errors.filter(_.contains("MySQL")).count()
// Return the time fields of errors mentioning
// HDFS as an array (assuming time is field
// number 3 in a tab-separated format):
errors.filter(_.contains("HDFS"))
.map(_.split(’\t’)(3))
.collect()
程序的世系图如下:
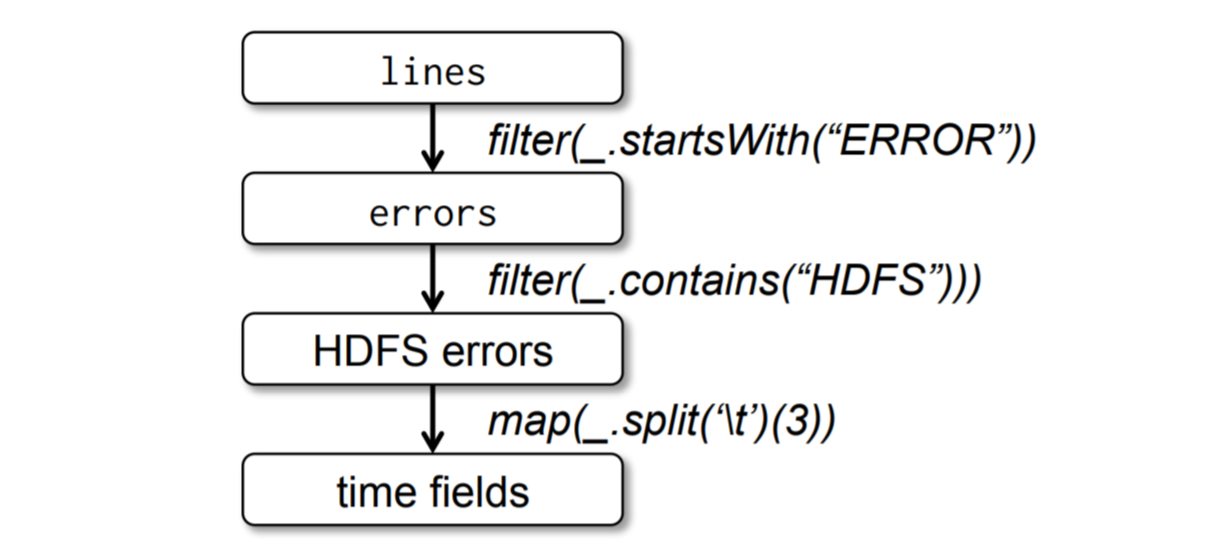
由于errors会被多次使用,因此对它进行持久化可以优化查询速度。
RDD模型的优势
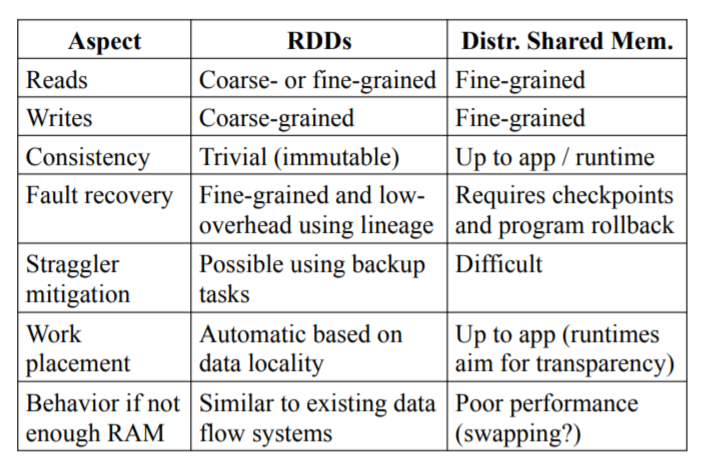
和现有比较先进的分布式共享内存(DSM)相比,RDD主要有以下差别:
- RDD只能通过粗粒度的变换操作创建,极大地简化了容错设计
- 借助不可修改的性质,可以通过运行副本任务来缓解慢节点问题,而DSM需要处理两个互备任务操作同一段数据的问题
- 通过数据位置调度任务提升性能
- 当内存不足的时候,因为RDD的变换都是流式地,因此即使使用硬盘存储也不会太影响性能
不适合RDD的应用
RDD比较适合批量任务,就是在RDD所以的元素上执行一种操作。而对于那种需要做异步细粒度更新状态的任务,RDD就不太适合。
Spark编程接口
在Spark中,用户需要编写一个驱动程序(driver),连接到工作节点(worker),驱动程序需要将变换操作以闭包的形式传递给工作节点。RDD数据是静态类型的,不过Scala支持类型推断,因此很多时候不需要指定类型。
Spark中的RDD操作
Spark中主要的变换和动作如下表所示:

通过变换创新的RDD属于惰性操作,只有在执行动作的时候会进行实际的运算。其中部分变换,例如join只能和键值对组成的RDD上操作。另外,用户也可以要求持久化一些RDD,获取RDD的分区顺序。
示例应用
逻辑斯蒂回归
val points = spark.textFile(...)
.map(parsePoint).persist()
var w = // random initial vector
for (i <- 1 to ITERATIONS) {
val gradient = points.map{ p =>
p.x * (1/(1+exp(-p.y*(w dot p.x)))-1)*p.y
}.reduce((a,b) => a+b)
w -= gradient
}
页排名
PageRank稍微复杂一点,算法根据链接关系不断更新网页的排名。在每次迭代中,每次网页发送的贡献值给它链接的网页,
为网页自身的排名,
为链接的数量。然而计算排名为
,其中
为所有贡献值的和,
为网页总数。
// Load graph as an RDD of (URL, outlinks) pairs
val links = spark.textFile(...).map(...).persist()
var ranks = // RDD of (URL, rank) pairs
for (i <- 1 to ITERATIONS) {
// Build an RDD of (targetURL, float) pairs
// with the contributions sent by each page
val contribs = links.join(ranks).flatMap {
(url, (links, rank)) =>
links.map(dest => (dest, rank/links.size))
}
// Sum contributions by URL and get new ranks
ranks = contribs.reduceByKey((x,y) => x+y)
.mapValues(sum => a/N + (1-a)*sum)
}
对应的数据世系图如下:
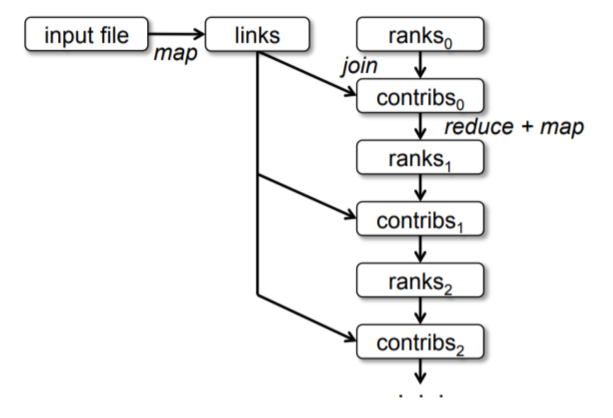
随着迭代次数增加,依赖关系变深,可以给ranks设置检查点加速故障恢复。另外,可以控制RDD的分区策略来减少节点之间通信成本,加速计算。例如,可以将links和ranks都按照url的哈希值分区,那么join操作就不需要节点之间通信就能完成。
links = spark.textFile(...).map(...)
.partitionBy(myPartFunc).persist()
表示RDD
RDD采用图进行保存,RDD通过接口提供五种信息的访问:分区、依赖、函数、分区规则元数据以及数据存放元数据。RDD提供的接口如下所示:
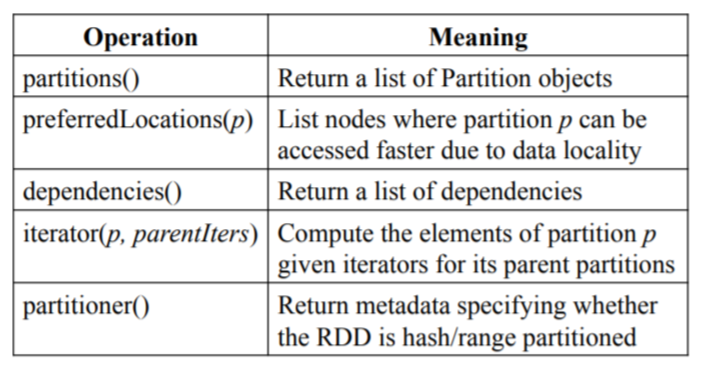
RDD中的依赖关系有两种:
- 窄依赖:父RDD的分区至多被子RDD的一个分区使用
- 宽依赖:父RDD的分区被子RDD的多个分区使用
窄依赖的特征相当重要:
- 在窄依赖中,每个分区的变换都可以并行独立执行
- 故障恢复也更加高效
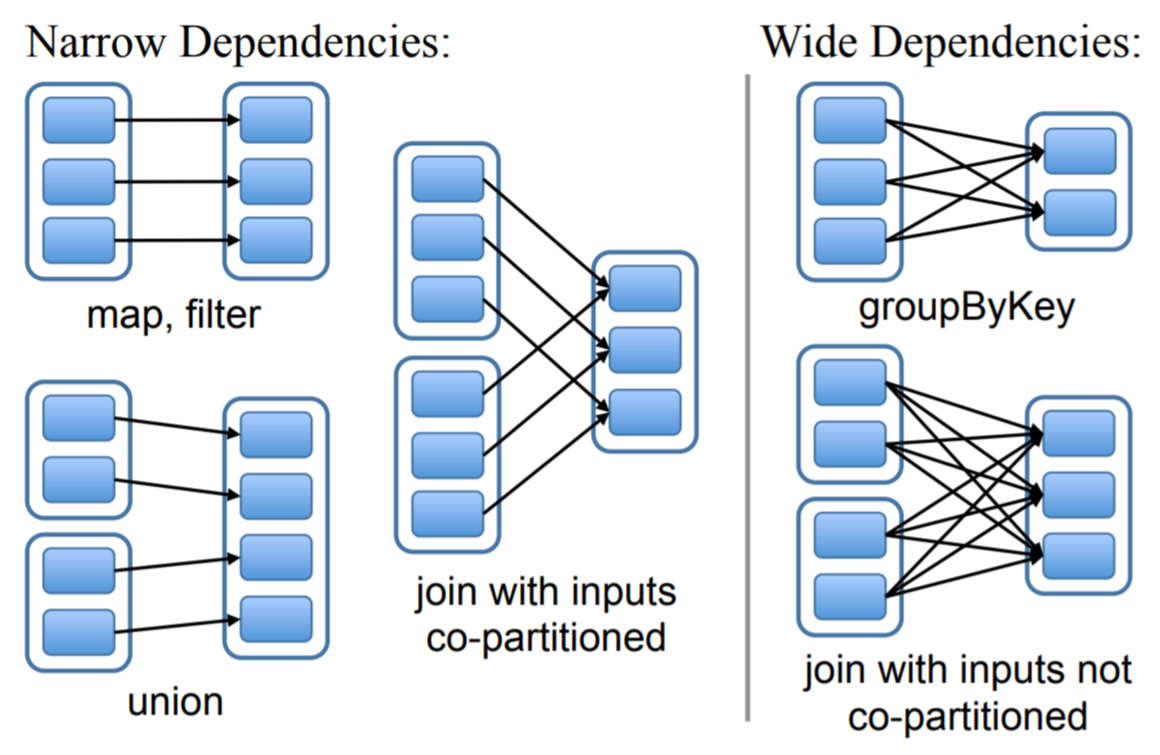
- HDFS文件:
partitions()返回每个分区在文件的位置,preferredLocations(p)会返回分区所在节点,iterator(p,parentIters)读取分区 map:将函数作用在父RDD分区的每条记录上union:它的分区为父RDD分区的并集sample:保存一个随机数生成器,从父RDD记录中采样join:如果两个父RDD由同一个partitioner分区,那么变换是窄依赖,否则为宽依赖或者混合依赖,生成的子RDD会带有partitioner。
实现
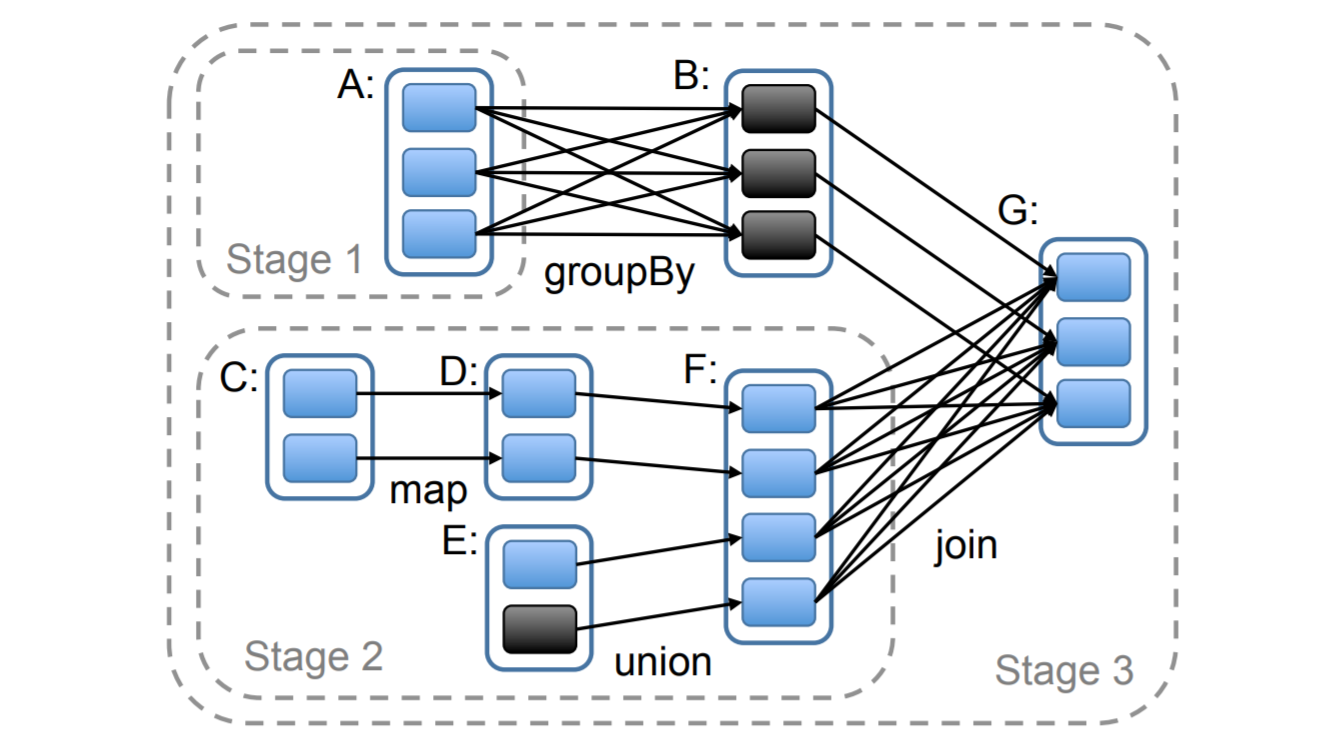
任务调度
在执行运算的时候,调度器会分析世系图,生成一个由不同阶段组成的DAG。每个阶段由窄依赖构成,便于进行并行计算。DAG的边界是宽依赖或者已经计算好的RDD分区。调度器会调度计算未计算的分区,调度器会根据数据存在位置调度任务。在宽依赖中,节点可以保存中间结果来加快故障恢复。
当任务发生故障,那么调度器把任务分配给其他节点,如果父RDD分区丢失,那么丢失的分区也要重新计算。目前调度器是没有容错能力的,不过备份数据世系图就足够了。
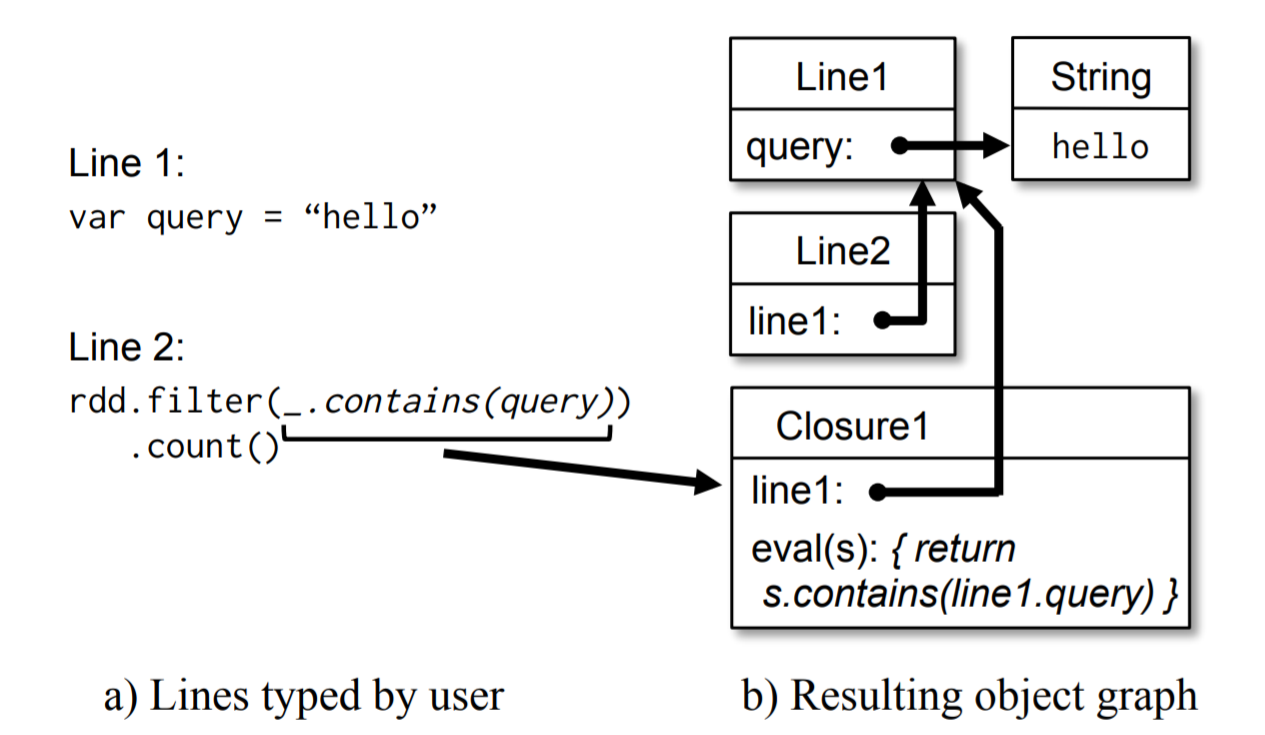
解释器集成
解释器为每一行编译一个类,然后使用一个函数调用它。Spark解释器在Scala解释器基础上修改了:
- 类传输:为了能让工作节点访问每一行的节码,解释器采用HTTP共享字节码
- 修改代码生成:为了序列化前面行的数据,每一行会引用前一行对象
内存管理
Spark提供了三种保存RDD的方式:
- 内存中的未序列化Java对象:JVM可以直接访问,高性能
- 内存中的序列化Java对象:内存空间有限的时候,内存利用率高
- 硬盘中:保存大到内存中无法保存的RDD
系统采用LRU策略管理内存,每次内存不够的时候淘汰最不近使用的RDD分区(和新分区属于同一个RDD的分区除外)。另外,Spark也支持用户手动设置RDD的持久化优先级。
检查点支持
虽然数据世系可以用来回复RDD,但是如果依赖关系过深,那么恢复速度会很慢。因此,有必要通过设置检查点来加速故障恢复,系统将这个决定权交给了用户,用户可以调用persist设置REPLICATE持久化RDD建立检查点。
参考文献
- Zaharia, Matei, et al. "Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing." Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation. USENIX Association, 2012.
