

3.python中的字符串对象
1.PyStringObject和PyString_Type
//[stringobject.h]
typedef struct{
PyObject_VAR_HEAD
long ob_shash;
int ob_sstate;
char ob_sval[1];
} PyStringObject;
//[stringobject.c]
PyTypeObject PyString_Type = {
PyObject_HEAD_INIT(&PyType_Type)
0,
"str",
sizeof(PyStringObject), // basic size
sizeof(char), //itemsize
// ...
}
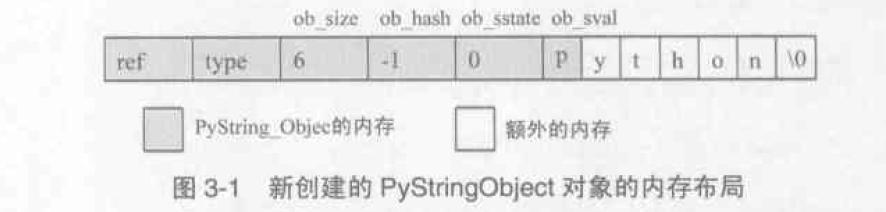
- ob_sval指的是一段长度为ob_size+1个字节的内存,必须满足ob_sval[ob_size] == '\0'
- ob_shash是缓存的该对象的hash值
- ob_sstate标记了该对象是否已经经过intern机制的处理
2 创建PyStringObject对象
//[stringobject.c]
// 从原生字符串创建
PyObject* PyString_FromString(const char *str) {
register size_t size;
register PyStringObejct *op;
size = strlen(str);
if (size > PY_SSIZE_T_MAX) {
return NULL;
}
if (size == 0 && (op = nullstring )!= NULL) { // intern机制: 和下面的一个分支都是为了缓存特定的对象,一个是空字符串,一个是单个字符字符串,第一次使用后会存在,之后不必再次创建PyObject对象(这些对象之前都被初始化成了NULL)
return (PyObject *) op;
}
if (size == 1 && (op = characters[*str & UCHAR_MAX]) != NULL) {
return (PyObject *) op;
}
op = (PyStringObject *)PyObject_MALLOC(sizeof(PyStringObject) + size); // 加上包含'\0'的额外内存
PyObject_INIT_VAR(ob, &PyString_Type, size);
op->ob_shash=-1;
op->ob_sstate=SSTATE_NOT_INTERNED;
memcpy(op->ob_sval, str, size+1);
if (size==0) {
PyObject *t = (PyObject *) op;
PyString_InternInPlace(&t);
op = (PyStringObject *) t;
nullstring = op;
} else if (size == 1) {
PyObject *t = (PyObject *) op;
PyString_InternInPlace(&t);
op = (PyStringObject *) t;
characters[*str & UCHAR_MAX] = op;
}
return (PyObejct *) op;
}
3 字符串对象的intern机制
//[stringobject.c]
void PyString_InternInPlace(PyObject **p) {
register PyStringObject *s = (PyStringObject *)(*p);
PyObject *t;
if (!PyString_CheckExact(s)) return;
if (PyString_CHECK_INTERNED(s)) return;
if (interned == NULL) {
interned = PyDict_New();
}
t = PyDict_GetItem(interned, (PyObject *) s);
if (t) {
Py_INCREF(t);
Py_DECREF(*p);
*p = t;
return;
}
PyDict_SetItem(interned, (PyObject *)s, (PyObject *)s);
s->ob_refcnt -= 2; // 减去key 和 value的引用
PyString_CHECK_INTERNED(s) = SSTATE_INTERNED_MORTAL; // 当析构时会根据这个属性,做出在interned中删除的操作
}
其他
- characters 是静态变量
static PyStringObject *characters[UCHAR_MAX+1];开始都是NULL指针 = join字符串效率比 + 好, 因为PyStringObject 是不可变对象(varObject只是因为是变长的),两者申请内存不同
- join 计算所有 PyStringObject 的size 得出需要分配的内存,一次分配 = 而concat(+) 需要分配n-1次内存,并且伴有析构
4.python中的List对象
// [listobject.h]
typedef struct{
PyObject_VAR_HEAD
PyObject **ob_item; // list[0] 实际就是ob_item[0]
int allocated; // 类似cap, 而ob_size是当前的元素数量
} PyListObject;
实际的操作和c++ vector类似略。有一个比较特别的是free_list的维护
// [listobject.c]
// list只有这一个创建入口
PyObject* PyList_New(int size) {
PyListObject *op;
size_t nbytes;
nbytes = size * sizeof(PyObject *);
if (nbytes / sizeof(PyObject *) != (size_t) size)
return PyErr_NoMemory();
if (num_free_lists) {
num_free_lists--; //记录当前free_lists的最大值
op = free_lists[num_free_lists];
_Py_NewReference((PyObejct *) op);
} else {
op = PyObject_GC_New(PyListObject, &PyList_Type);
}
if (size <=0)
op->ob_item = NULL;
else {
op->ob_item = (PyObject **) PyMem_MALLOC(nbytes);
memset(op->ob_item, 0, nbytes);
}
op->ob_size=size;
op->allocated = size;
return (PyObject *) op;
}
# define MAXFREELISTS 80
static PyListObject *free_lists[MAXFREELISTS];
static int num_free_lists=0;
// 创建和更新是在释放PyListObject时候维护的
static void list_dealloc(PyListObject *op){
int i;
if (op->ob_item!=NULL) {
i=op->ob_size;
while (--i>=0) {
Py_XDECREF(op->ob_item[i]);
}
PyMem_FREE(op->ob_item);
}
if (num_free_lists < MAXFREELISTS && PyList_CheckExact(op))
free_lists[num_free_lists++] = op; //保存当前释放元素的list
else
op->ob_type->tp_free((PyObject *) op);
}
4.python中的Dict对象
实现是散列表,采用二次探针解决冲突
//[dictobject.h]
typedef struct{
Py_ssize_t me_hash;
PyObejct *me_key;
Pyobject *me_value;
} PyDictEntry;
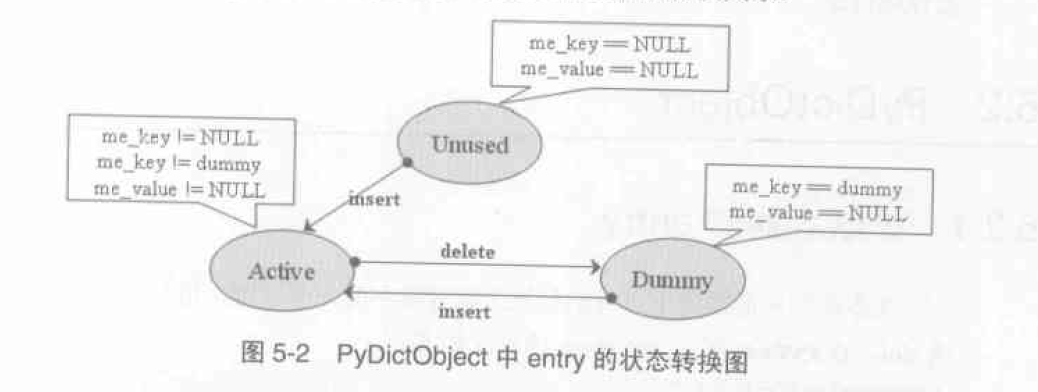
entry会有三种状态 dummy状态是探测连上的元素伪删除后的状态
//[dictobject.h]
#define PyDict_MINSIZE 8
typedef struct _dictobject PyObject;
struct _dictobject{
PyObject_HEAD
Py_ssize_t ma_fill; // active + dummy个数
Py_ssize_t ma_used; // active
Py_ssize_t ma_mask; // 所有的entry个数,之所以这样命名因为hash值会和这个值取&
PyDictEntry *ma_table; // entry数量小于8个时会指向 ma_smalltable
PyDictEntry *(*ma_lookup) (PyDictObject *mp. PyObject *key, long hash);
PyDictEntry ma_smalltable[PyDict_MINSIZE];
}
其他包括缓冲池之类的会和list类似,lookup这块会多点东西
python提供了两种搜索策略,一个lookdict一个lookdict_string
//[dictobhect.c]
static dictentry* lookdict(dictobject *mp, PyObejct *key, register long hash){
/** 返回永远不是NULL,而是一个me_value为NULL的entry可以直接被使用, 如果没找到但是有dummy的entry会返回这个dummy
*/
register size_t i;
register size_t perturb;
register dictentry *freeslot;
register size_t mask = mp->ma_mask;
dictentry *ep0 = mp->ma_table;
register dictentry *ep;
register int restore_error;
register int checked_error;
register int cmp;
PyObject *err_type, *err_value, *err_tb;
PyObject *startkey;
i = hash & mask;
ep = &ep0[i];
if (ep->me_key==NULL || ep->me_key == key)
return ep;
if (ep->me_key==dummy)
freeslot = ep;
else{
if (ep->me_hash == hash){
startkey = ep->me_key;
cmp = PyObject_RichCompareBool(startkey, key, Py_EQ); // 确定值是否相等,lookdict_string的差别在于这边使用的方法
if (cmp > 0)
return ep;
}
freelot = NULL;
}
// 二次探寻
for (perturb=hash;;perturb >>= PERTURB_SHIFT{
i = (i<<2) + i + perturb + 1;
ep = &ep0[i & mask];
if (ep->me_key == NULL)
return freeslot == NULL ? ep: freeslot;
if (ep->mp_key == key)
return eq;
if (ep->me_hash == hash && ep->me_key != dummy){
startkey = ep->me_key;
cmp = PyObject_RichCompareBool(startkey, key, Py_EQ);
if (cmp > 0)
return ep;
}
if (ep->me_key == dummy && freeslot == NULL)
freeslot = ep;
}
}
其他的关于元素操作,table 缩减内存策略的略,会和STL类似
