

背景
es默认对中文是一个个字进行分词处理,这样查询效率较低 如下图所示:
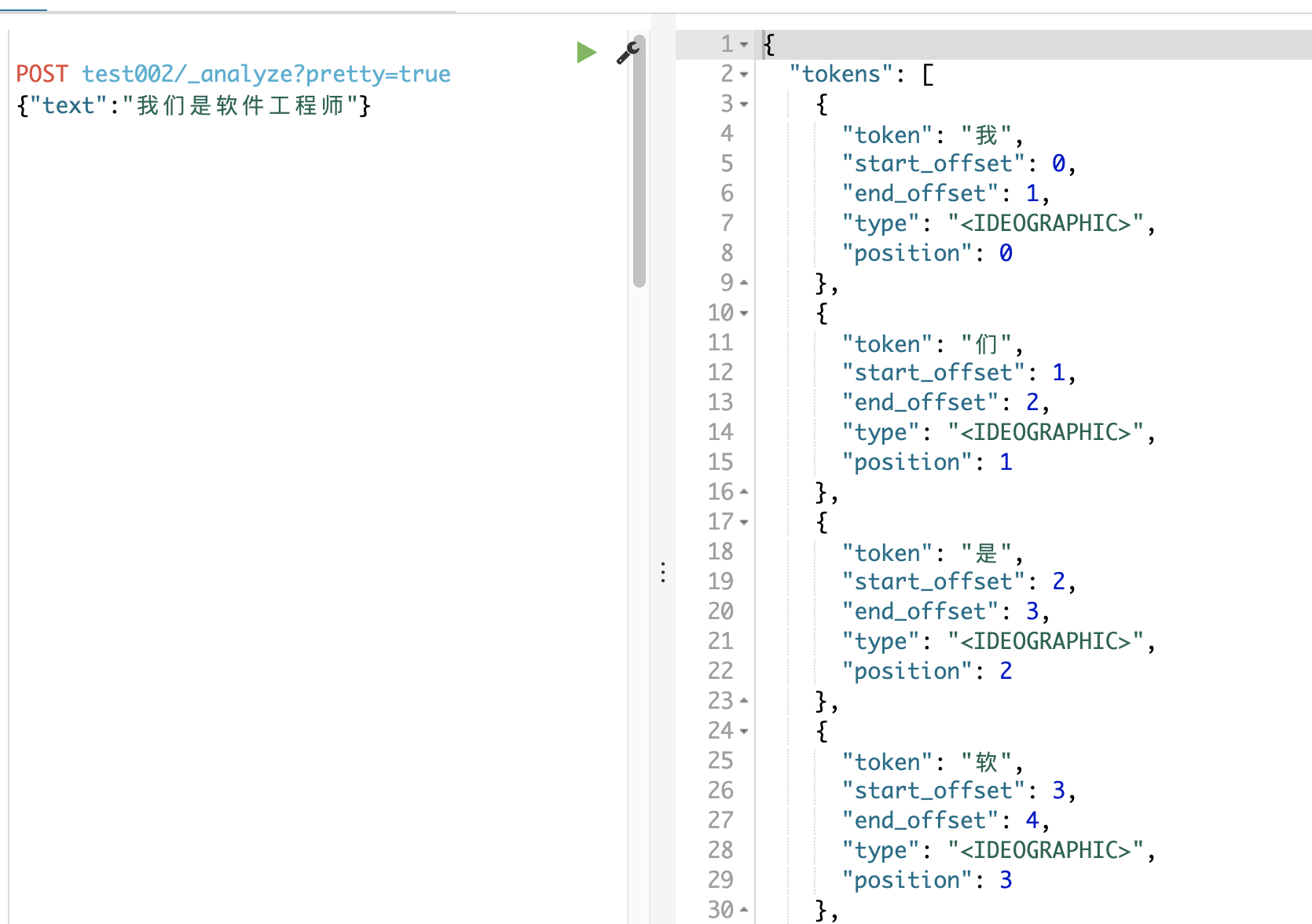
这不符合我们的预期呀 ·~~·, 我们需要添加一个中文分词器
1. 添加中文分词器
1. 下载对应版本
github: github.com/medcl/elast… (找到与es对应的版本)
ES是6.4.3 找到:elasticsearch-analysis-ik-6.4.3.tar.gz下载
scp -r elasticsearch-analysis-ik-6.4.3.tar.gz root@xxxx:/home/es/ik/
2. 打包配置
//解压
tar -zxvf elasticsearch-analysis-ik-6.4.3.tar.gz
//mvn打包
mvn install
//找到zip
scp -r target/release/elasticsearch-analysis-ik-6.3.0.zip /home/es/elasticsearch-6.4.3/plugins/ik/
//更改 java版本和es版本
vi plugin-descriptor.properties
3. 重启
来看看效果
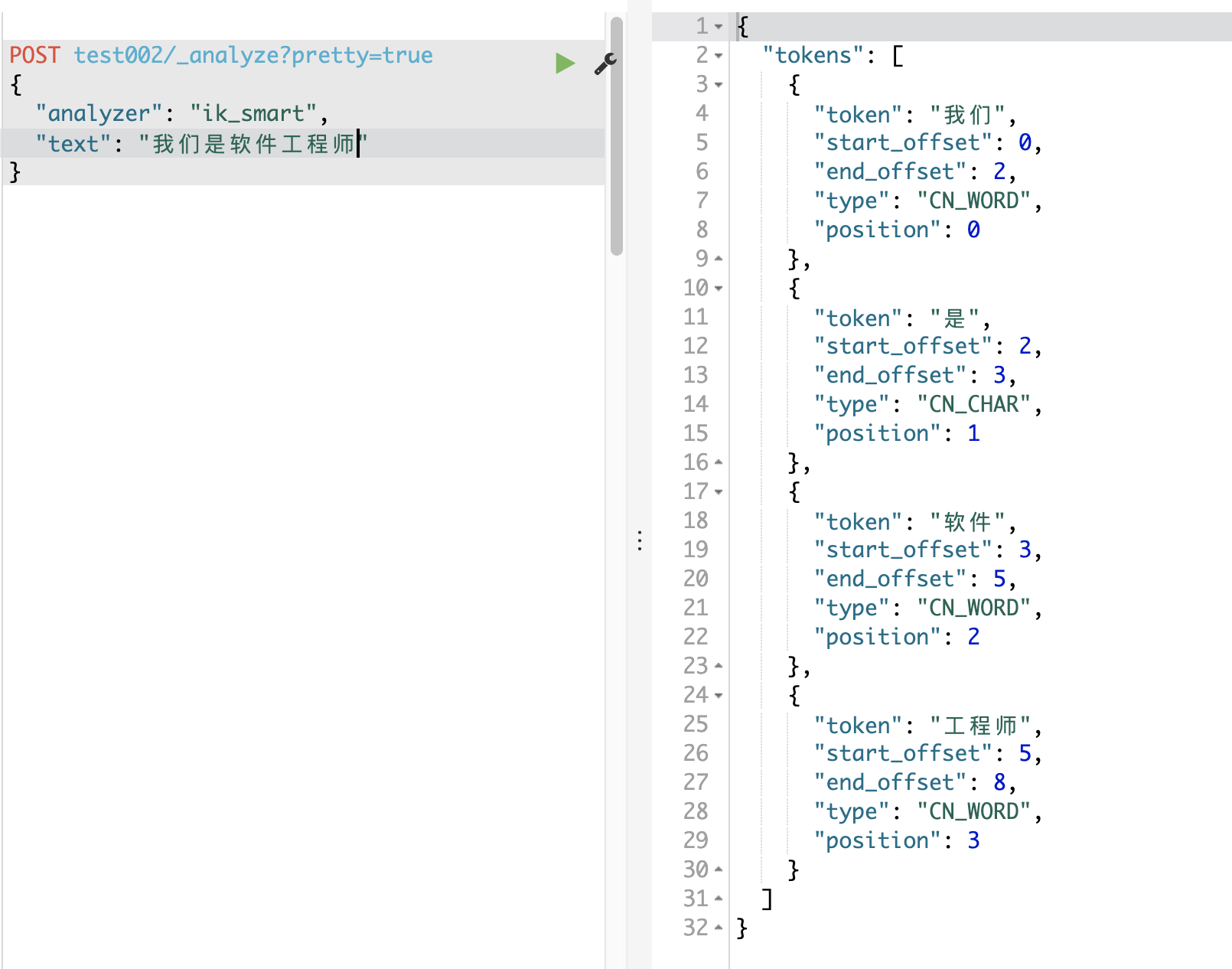
优秀,完成!!!
2. 自定义分词
我们除了可以使用es分词器外,也可以自定义分词
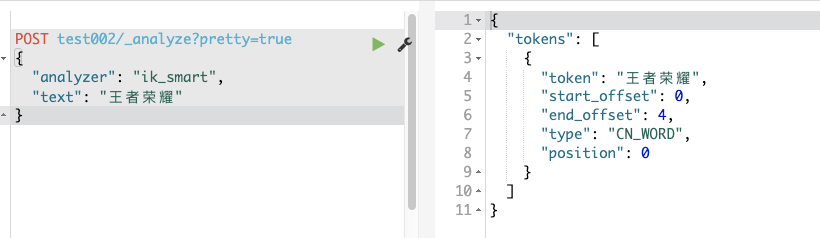
POST test002/_analyze?pretty=true
{
"analyzer": "ik_smart",
"text": "王者荣耀"
}
效果如下:
- 找到elasticsearch-6.4.3/plugins/ik/config 目录下:
- vi cumtom/new_word_2.dic 文件,在文件中填入你不想分词的词语。

- 更改配置文件 vi IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 ***配置这里******-->
<entry key="ext_dict">custom/new_word_2.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
~
然后重新运行es,就可以生效了。
