

应用场景
- 表单验证里面,验证字符的合法性,如邮箱是否合法,手机号是否合法等等
- 信息过滤,如论坛帖子或者评论中的非法字符,例如 sql注入、js脚本注入、煽动性的言论
- 信息采集,采集别人网站上面的内容,例如整页采集时 筛选出需求的部分
- 信息替换
- 页面伪静态的规则
测试地址
修饰符
js 修饰符的用法,是修饰符一定要写到 // 之后,可以一次性使用多个修饰符 /^...$/igm
i执行对大小写不敏感的匹配。实际上就是不区分大小写的匹配g执行全局匹配(查找所有匹配而非在找到第一个匹配后停止)。m执行多行匹配
转义字符
如果匹配的字符串在正则中有特殊含义的都必须加转义字符。如[]$.*?+|^{}()
但是能要乱加转义
1. 量词
前导字符: 就是紧挨着(
+、*、?)等的前一个字符
n+匹配任何包含至少一个n的字符串。匹配一个或多个前导字符n*匹配任何包含零个或多个n的字符串。前导字符有没有也可以n?匹配任何包含零个或一个n的字符串n{X}匹配包含X个n的序列的字符串n{X,Y}匹配包含X到Y个n的序列的字符串,包括X和Y个n{X,}匹配包含至少X个n的序列的字符串n$匹配任何结尾为n的字符串。从末尾开始匹配^n匹配任何开头为n的字符串。(注意位置在前面)js is so cool, js, 如果使用/^js/g(为js的匹配规则,g表示全局匹配, 匹配规则放在//里面). 表示 匹配当前字符串的开头是不是js^n$表示只匹配字符串n, 也就是匹配整个字符串/js$/g匹配当前字符串的结尾是不是js
2. 懒惰限定符
*?重复任意次,但尽可能少重复如 "acbacb" 正则 "a.*?b" 只会取到第一个"acb" 原本可以全部取到但加了限定符后,只会匹配尽可能少的字符 ,而"acbacb"最少字符的结果就是"acb"
- +?` 重复1次或更多次,但尽可能少重复
与上面一样,只是至少要重复1次
??重复0次或1次,但尽可能少重复如 "aaacb" 正则 "a.??b" 只会取到最后的三个字符"acb"
{n,m}?重复n到m次,但尽可能少重复如 "aaaaaaaa" 正则 "a{0,m}" 因为最少是0次所以取到结果为空
{n,}?重复n次以上,但尽可能少重复如 "aaaaaaa" 正则 "a{1,}" 最少是1次所以取到结果为 "a"
3. 元字符
.表示单个字符,表示任意字符。除了换行和行结束符*表示任意字符串(0个或多个任意字符,除了换行和行结束符).也是任意一个字符,*表示任意个前导字符。二者组合表示任意字符串\w匹配任何数字、字母、下划线。一个\w表示一个字符\W匹配任何非数字、非字母、非下划线。\d查找数字。\D查找非数字字符\s查找空白字符\S查找非空白字符\b匹配单词边界(边界字母个数没有限制;\b放前面表示匹配单词前面的边界,\b表示匹配单词后面的边界)\B匹配非单词边界\n查找换行符\r查找回车符\t查找制表符
4. 中括号/方括号/[]
方括号表示一个范围,也称为 字符簇
[abc]查找方括号之内的任何字符。[^abc]查找任何不在方括号之间的字符。(方括号中的^表示取反)[0-9]查找任何从0至9的数字。表示一个字符[a-z]查找任何从小写a到小写z的字符。[A-Z]查找任何从大写A到大写Z的字符。[A-z]查找任何从大写A到小写z的字符。包括下划线。[5-8]查找5 <=目标<= 8的字符(red|blue|green) 查找任何指定的选项。(竖线|表示或者)/[0-9]|[a-z]/g表示查找0~9和a~z的字符
5. 分组/捕获和反向引用
正则中出现的小括号,就叫捕获或者分组
在正则语法中(在 /…/ 内),在捕获的后面,用 \1 来引用前面的捕获。用 \2 表示第二个捕获的内容….
在正则语法外(如 replace 时),用 $1 来引用前面的捕获
var str1 = "1111 3213 4345 12341 2990 2323";
// 匹配连续4个数字
var result = str1.match(/\d{4}/g); // [ '1111', '3213', '4345', '1234', '2323' ]
// 匹配连续4个数字, 第1个和第3个数字相同
var result1 = str1.match(/(\d)\d\1\d/g); // [ '1111', '4345', '2323' ]
// 匹配连续4个数字, 第1个和第3个数字相同, 并且第2个和第4个数字相同
var result2 = str1.match(/(\d)(\d)\1\2/g); // [ '1111', '2323' ]
console.log(result2);
禁止引用
(?:正则) 这个小括号中的内容不能够被引用
var result3 = str1.match(/(?:\d)(\d)\1\2/g); // 这样是 ❌的, 第一个括号内是不可以被引用的 所以\1只能引用第二个括号的内容, \2 也就无效了
console.log(result3); // null
6. 环视(断言/零宽断言/正向预测/负向预测)
every(?=n) 匹配任何其后紧接指定字符串 n 的字符串。
有一个字符串是 abacad ,从里面查找 a ,什么样的 a 呢?后面必须紧接b的a。
正则语法是:/a(?=b)/g
var str1 = "abacad";
var result = str1.match(/a(?=b)/g);
console.log(result); // [ 'a' ]
延伸一下,案例中的a、b都是正则表达式,实际上换一个复杂一点的正则表达式也是可以的
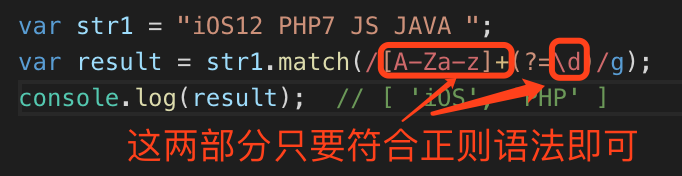
var str1 = "iOS12 PHP7 JS JAVA ";
var result = str1.match(/[A-Za-z]+(?=\d)/g);
console.log(result); // [ 'iOS', 'PHP' ]
var str2 = "iOS12 PHP7 JS JAVA hello中国 ";
var result2 = str2.match(/[A-Za-z]+(?=\d|[\u4e00-\u9fa5])/g);
console.log(result2); // [ 'iOS', 'PHP', 'hello' ]
every(?!n) 匹配任何其后没有紧接指定字符串 n 的字符串。
有一个字符串是abacad,从里面查找a,什么样的a呢?后面不能紧接b的a
正则语法是:/a(?!b)/g
var str1 = "abacad";
var result = str1.match(/a(?!b)/g);
console.log(result); // [ 'a', 'a' ]
另外,还会看到(?!B)[A-Z]这种写法,其实它是[A-Z]范围里,排除B的意思,前置的(?!B)只是对后面数据的一个限定,从而达到过滤匹配的效果
var str1 = "ABCDEFG";
var result = str1.match(/(?!B)[A-Z]/g); // [ 'A', 'C', 'D', 'E', 'F', 'G' ]
var result2 = str1.match(/(?![B-D])[A-Z]/g); // [ 'A', 'E', 'F', 'G' ]
var str1 = "423234d6345743";
// 从头匹配到尾, 必须是纯数字
var result = str1.match(/^\d+$/g);
console.log(result); // null
var result1 = str1.match(/(?!^\d+$)^[A-Za-z0-9]+$/g);
console.log(result1); // [ '423234d6345743' ] 如果是纯数字则为null

