

认识并查集
并查集 Union Find是一种很不一样的树结构,之前学习的树结构都是由父亲指向孩子,而并查集则是由孩子指向父亲的树结构。它可以非常高效地解决连接问题,如下图:

并查集就可以高效地解决这一类问题。
特点
1.并查集可以快速地判断网络中节点间的连接状态。
2.并查集可以快速求出两个集合的并集。
对于一组数据,并查集主要支持两个动作:
1.union(p,q):合并p,q两个数据所在的集合。
2.isConnected(p,q):对于给定的两个数据,查询它们是否属于同一个集合。
然后我们来设计一个并查集的接口
public interface UF {
int getSize();
boolean isConnect(int p, int q);
void unionElements(int p, int q);
}
这里传入的参数类型设置的是int,但并查集并不关心传入参数的类型,因为我们可以将p,q当成id映射成其他的数据类型。
Quick Find(第一版并查集)
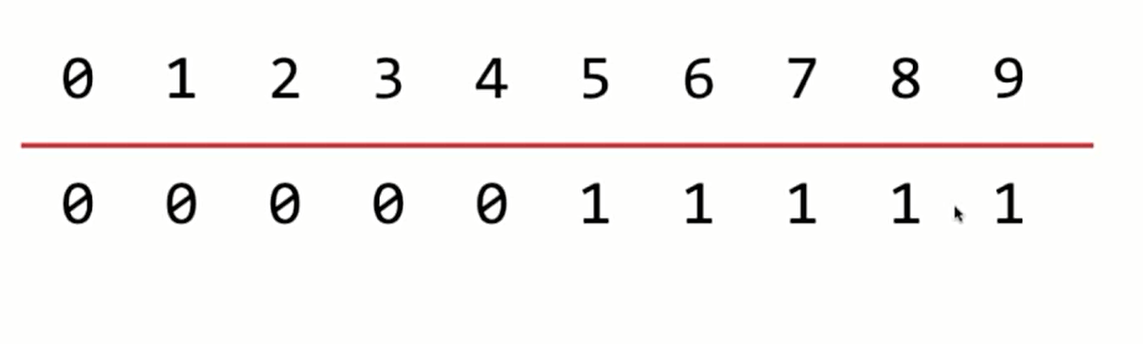
并查集的基本数据表示
在并查集内部对每个数据进行编号,并且标出每个编号对应的集合。
代码实现:
public class UnionFind1 implements UF{
private int[] id;
public UnionFind1(int size){
id = new int[size];
/**
* 假设每个数据都属于不同的集合
*/
for (int i = 0; i < id.length; i++){
id[i] = i;
}
}
@Override
public int getSize() {
return id.length;
}
}
对于一个数据查找它的id的过程我们可以抽象为一个函数,叫做find。很明显这个find函数的时间复杂度为O(1)。所以也称为Quick Find。
代码实现:
/**
* 查找元素p对应的集合编号
* @param p
* @return
*/
private int find(int p){
if (p < 0 && p >= id.length){
throw new IllegalArgumentException("p is out of bound.");
}
return id[p];
}
/**
* 查询元素p,q是否属于同一个集合
* @param p
* @param q
* @return
*/
@Override
public boolean isConnect(int p, int q) {
return find(p) == find(q);
}
Quick Find 下的Union
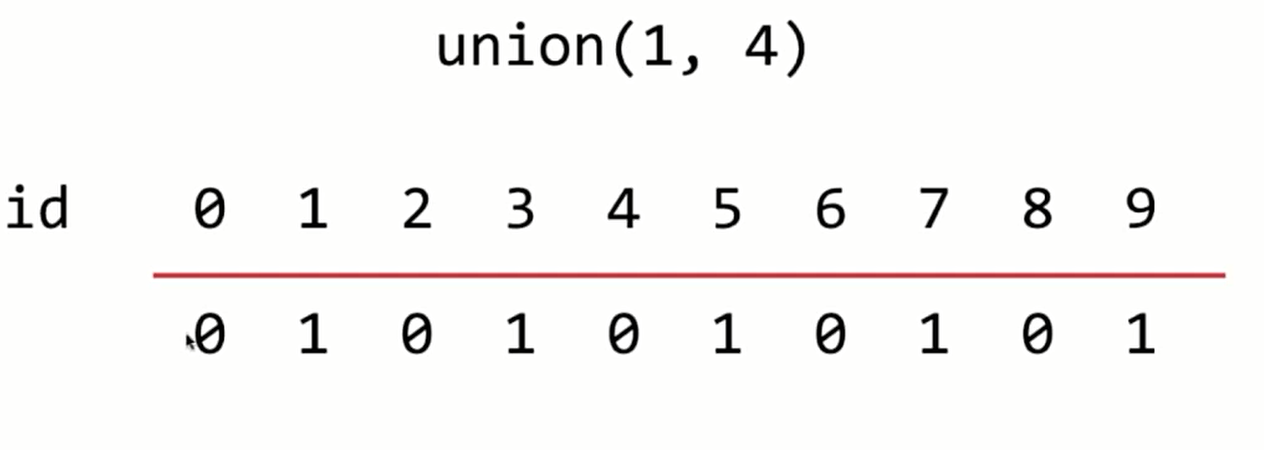

代码实现:
/**
* 合并元素p,q所属的集合
* @param p
* @param q
*/
@Override
public void unionElements(int p, int q) {
int pID = find(p);
int qID = find(q);
if (pID == qID){
return;
}
for (int i = 0; i < id.length; i++){
if (id[i] == pID){
id[i] = qID;
}
}
}
小结
这一版的并查集的本质就是用数组模拟了一下并查集的操作过程,主要缺点在于union操作的时间复杂度过高。
Quick Union (第二版并查集)真正的并查集底层实现
实现思路
将每一个元素看做一个节点,然后采用开头说的一种由孩子节点指向父亲节点的树结构,对于树的根节点让它指向自身。
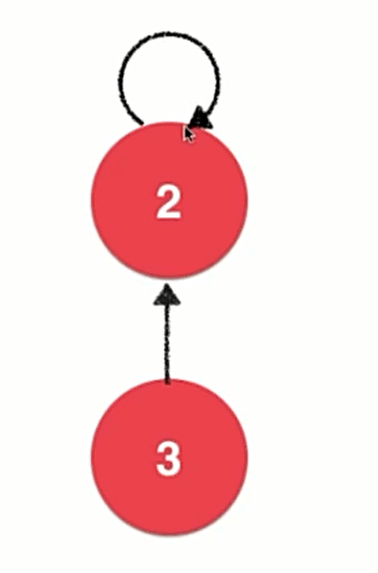
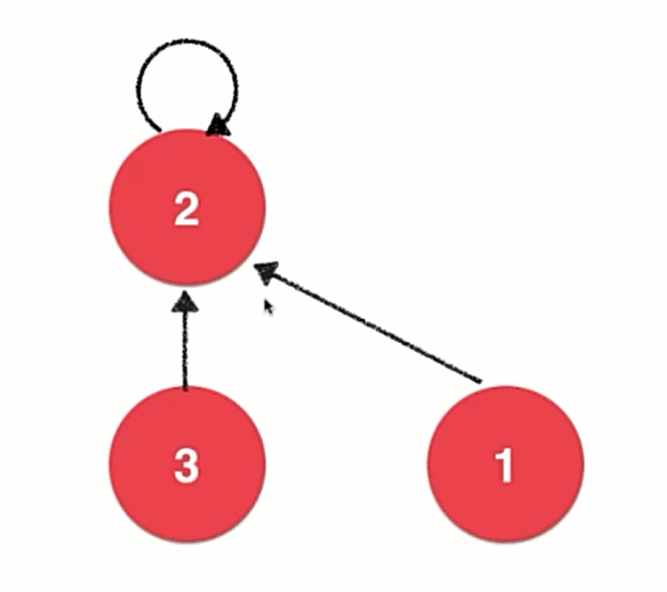
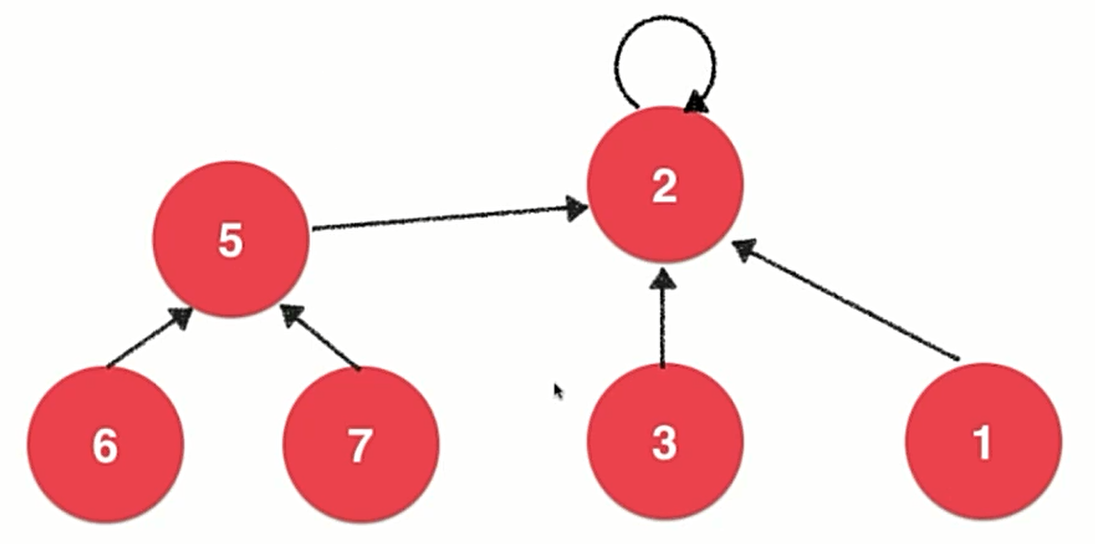
Quick Union 下的数据表示
由于每个节点只有一个指针,因此我们依然可以用数组来存储这些元素。

如图,parent[i]表示的就是第i个节点指向了哪个元素,在初始时每个元素都指向自己。
因为在合并时需要找到元素所属树的根节点,所以这里的union的时间复杂度为O(h),h为树的深度。同理,find操作也为O(h)。
代码实现
public class UnionFind2 implements UF{
private int[] parent;
public UnionFind2(int size){
parent = new int[size];
for (int i = 0; i < size; i++){
parent[i] = i;
}
}
@Override
public int getSize() {
return parent.length;
}
/**
* 查找元素p对应集合编号
* @param p
* @return
*/
private int find(int p){
if (p < 0 && p >= parent.length){
throw new IllegalArgumentException("p is out of bound.");
}
while (p != parent[p]){
p = parent[p];
}
return p;
}
/**
* 查询元素p,q是否属于一个集合
* @param p
* @param q
* @return
*/
@Override
public boolean isConnect(int p, int q) {
return find(p) == find(q);
}
/**
* 合并元素p,q所属的集合
* O(h)
* @param p
* @param q
*/
@Override
public void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot){
return;
}
parent[pRoot] = qRoot;
}
}
两种实现的性能测试
测试代码
import java.util.Random;
/**
* className Main
* description TODO
*
* @author ln
* @version 1.0
* @date 2019/7/1 18:33
*/
public class Main {
private static double testUF(UF uf, int m){
int size = uf.getSize();
Random random = new Random();
long startTime = System.nanoTime();
/**
* m次合并操作
*/
for (int i = 0; i < m; i++){
int a = random.nextInt(size);
int b = random.nextInt(size);
uf.unionElements(a, b);
}
/**
* m次查询操作
*/
for (int i = 0; i < m; i++){
int a = random.nextInt(size);
int b = random.nextInt(size);
uf.isConnect(a, b);
}
long endTime = System.nanoTime();
return (endTime - startTime) / 1000000000.0;
}
public static void main(String[] args) {
int size = 10000;
int m = 10000;
UnionFind1 uf1 = new UnionFind1(size);
System.out.println("UnionFind1: " + testUF(uf1, m) + " s");
UnionFind2 uf2 = new UnionFind2(size);
System.out.println("UnionFind2: " + testUF(uf2, m) + " s");
}
}
测试结果
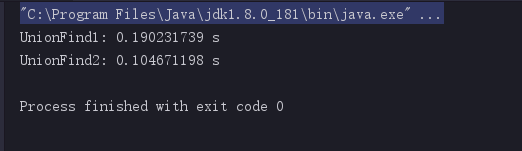
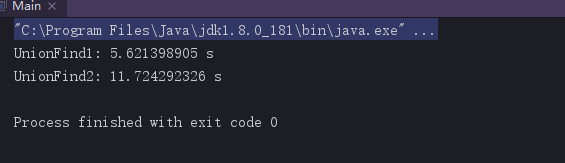
但是当我们增加操作次数时再次测试会得到以下的结果
基于size的优化
思路
在合并集合时始终让节点个数少的树的根节点指向节点多的树的根节点。
代码实现
public class UnionFind3 implements UF{
private int[] parent;
/**
* 用于记录每个树的大小
* sz[i]表示以i为根的集合中元素的个数
*/
private int[] sz;
public UnionFind3(int size){
parent = new int[size];
sz = new int[size];
for (int i = 0; i < size; i++){
parent[i] = i;
sz[i] = 1;
}
}
@Override
public int getSize() {
return parent.length;
}
/**
* 查找元素p对应集合编号
* @param p
* @return
*/
private int find(int p){
if (p < 0 && p >= parent.length){
throw new IllegalArgumentException("p is out of bound.");
}
while (p != parent[p]){
p = parent[p];
}
return p;
}
/**
* 合并元素p,q所属的集合
* O(h)
* @param p
* @param q
*/
@Override
public void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot){
return;
}
/**
* 让节点少的树的根节点指向节点多的树的根节点
*/
if (sz[pRoot] < sz[qRoot]){
parent[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
}
else {
parent[qRoot] = pRoot;
sz[pRoot] += sz[qRoot];
}
}
}
测试
与之前的测试方式相同,代码如下
public static void main(String[] args) {
int size = 100000;
int m = 100000;
UnionFind1 uf1 = new UnionFind1(size);
System.out.println("UnionFind1: " + testUF(uf1, m) + " s");
UnionFind2 uf2 = new UnionFind2(size);
System.out.println("UnionFind2: " + testUF(uf2, m) + " s");
UnionFind3 uf3 = new UnionFind3(size);
System.out.println("UnionFind3: " + testUF(uf3, m) + " s");
}
测试结果:
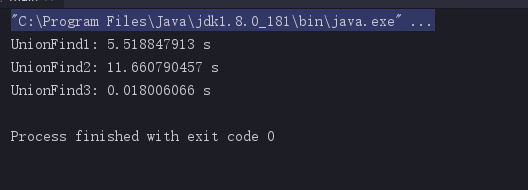
基于rank的优化
根据树的节点个数来优化也有极端的情况
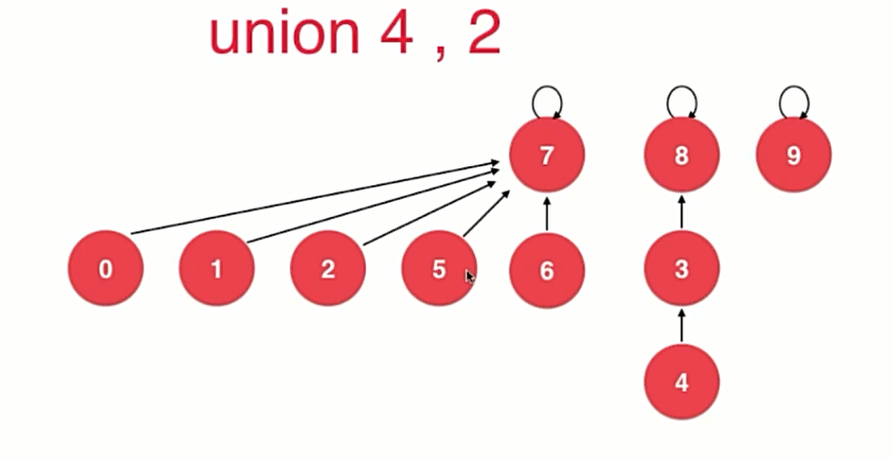
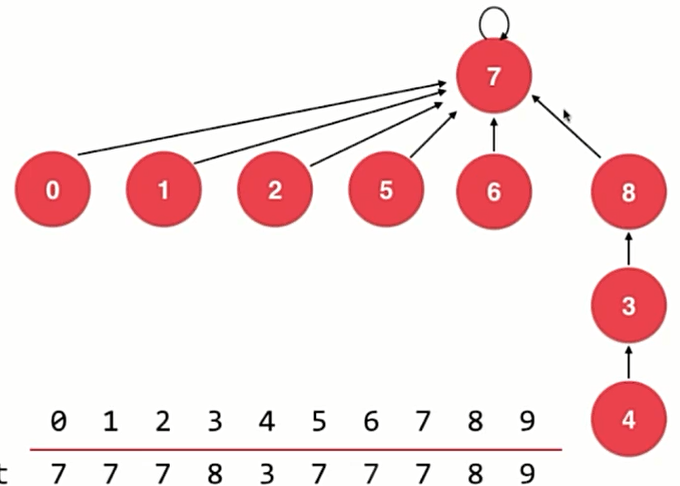
思路
在每棵树的根节点上记录整棵树的高度,合并时让高度小的树合并到高度大的树。
代码实现 **
public class UnionFind4 implements UF{
private int[] parent;
/**
* 用于记录每个树的大小
* rank[i]表示以i为根的树的高度
*/
private int[] rank;
public UnionFind4(int size){
parent = new int[size];
rank = new int[size];
for (int i = 0; i < size; i++){
parent[i] = i;
rank[i] = 1;
}
}
/**
* 查找元素p对应集合编号
* @param p
* @return
*/
private int find(int p){
if (p < 0 && p >= parent.length){
throw new IllegalArgumentException("p is out of bound.");
}
while (p != parent[p]){
p = parent[p];
}
return p;
}
/**
* 合并元素p,q所属的集合
* O(h)
* @param p
* @param q
*/
@Override
public void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot){
return;
}
/**
* 让高度小的树的根节点指向高度大的树的根节点
* 合并两个高度相同的树时要维护rank数组
*/
if (rank[pRoot] < rank[qRoot]){
parent[pRoot] = qRoot;
} else if (rank[pRoot] > rank[qRoot]){
parent[qRoot] = pRoot;
} else {
parent[qRoot] = pRoot;
rank[pRoot]++;
}
}
}
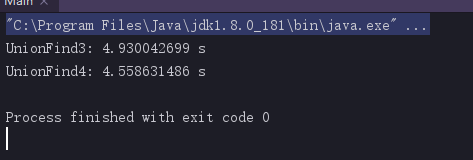
测试
这里只比较uf3和uf4,将数据量和操作数加到千万级。
结果如下:
路径压缩
路径压缩也是一种优化方法,其思想是在一个节点寻找其根节点的过程中降低整个树的高度。
核心代码为
parent[p] = parent[parent[p]];
即让当前节点指向其父亲节点的父亲节点(其实可以直接让当前节点直接指向根节点,用递归即可实现,这里我就不演示了)。
这个优化方法可以加在rank优化的基础上,使效率再次提高。
只需在uf4的find方法上加入上述的核心代码即可。
Writtern by Autu.
2019.7.1
