

正则表达式由两种基本字符类型组成:
-原义文本字符
-元字符
*元字符是在正则表达式中有特殊含义的非字母字符
*字符类
我们可以使用元字符[ ]来构建一个简单的类
所谓类是指符合某些特性的对象
使用元字符^创建反向类/负向类
*范围类
在[ ]组成的类内部是可以连写的[a-zA-Z]
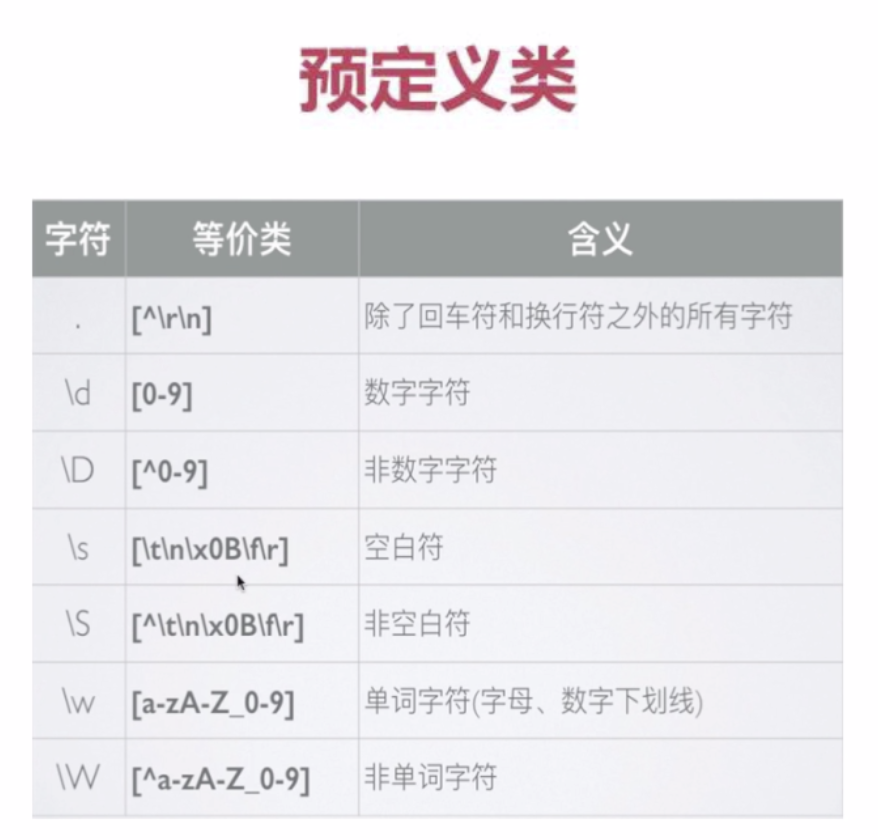
*预定义类
正则表达式提供预定义类来匹配常见的字符类
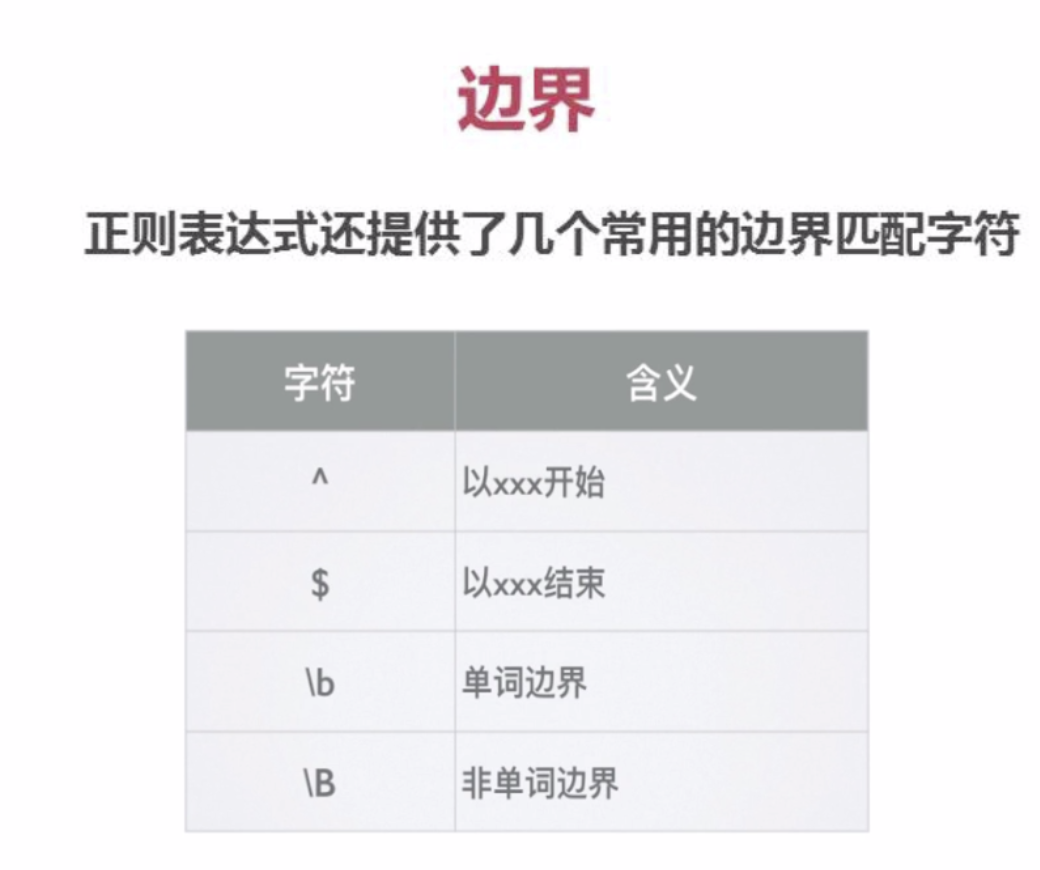
边界
比如 This is a boy. 想去掉把This改为Th0,正则表达式应为str.replace(/\Bis\b/,0)
*贪婪模式:
'12345678'.replace(/\d{3,6}/g,'X') 'X78'
*非贪婪模式:
让正则表达式尽可能少的匹配,也就是说一旦成功匹配不再继续尝试就是非贪婪模式
做法很简单:在量词后面加上?即可 ‘123456789’.match(/\d{3,5}?/g);
使用( )可以达到分组的功能,使量词作用于分组
*或
使用 | 可以达到或的效果
*正则表达式对象属性:
global:是否全文搜索,默认false
ignoreCase:是否大小写敏感,默认false
multiline:多行搜索,默认值是false
lastIndex:是当前表达式匹配内容的最后一个字符的下一个位置
source:正则表达式的文本字符串
*RegExp.prototype.test(str)
用于测试字符串参数中是否存在匹配正则表达式模式的字符串
for example: var reg1 = / \d / , var reg2 = / \d/g , var str = '45' reg1.test(str) reg2.test(str)
结果是不一样的,reg2.test(str)再每第3次的时候会变为false,然后字符串再从新的开始 (解决办法:可以每次实例化一个对象 例如:(/\d/g).test()
*RegExp.prototype.exec(str)
使用正则表达式模式对字符串执行搜索,并将更新全局RegExp对象的属性以反映匹配结果
*Stringl.prototype.search(reg)
*String.prototype.match(reg)
match()方法将检索字符串,以找到一个或多个与regexp匹配的文本
regexp是否具有标志g对结果影响很大
1.非全局调用: 
*String.prototype.split(reg)
在一些复杂的分割情况下,我们可以使用正则表达式解决 ‘a1b2c3d'split(/\d/) ; ['a','b','c','d']
*String.prototype.replace
String.prototype.replace(reg,function)
function参数含义
function会在每次匹配替换的时候调用,有四个参数,
1、匹配字符串
2、正则表达式分组内容,没有分组则没有该参数
3、匹配项在字符串中的index
4、原字符串
