

前言
简单说,刚起步用 MySQL;
有钱并且业务量适中用 Oracle,核心业务用 Oracle,非核心业务用云数据库;
资金不充足业务量较大用 MySQL + 开源中间层;业务量超大只能自研。
大数据和关系型数据库不是一个方向,主要用于存储其他类型数据了,订单、交易等数据一般不会放大数据,更适合日志,浏览记录等。
最佳实践-技术选型
1.京东 //已经成为apache项目
2.Mycat
当当,sharding-jdbc
支持
1.分表分库
早期只支持分库。
后来还支持分表。
2.读写分离
早期不支持。
1.5支持。
实现原理
基于jdbc,轻量级jar包的形式和程序代码一起部署。
代码
baijifeilong.github.io/2018/11/26/…
参考
juejin.cn/post/684490…
www.infoq.cn/article/201…
京东,Apache ShardingSphere
支持
1.分表分库
2.读写分离
实现原理
包含两部分
1.一部分是和当当sharding-jdbc一模一样的功能
2.一部分是代理中间件
京东实践
www.infoq.cn/article/1Qv…
发展历史
1.一开始是当当负责人创建
2.后面跳槽到京东
3.最后,由京东开源
参考
shardingsphere.apache.org/document/cu… //官方中文文档
github.com/apache/incu… //github
Mycat
实现原理
代理中间件
注:个人开源。
基于阿里开源Cobar。
分片
使用步骤
1.开源软件.set哪一个分片(3); //假设总共有两个节点,余数是0,就是第0个节点;余数是1,就是第1个节点
2.3/2=1,所以是第1个节点。
这是显示设置哪一个节点。如何自动定位到哪一个节点?上面的是硬编码写死的方法。如果想要自动路由到哪一个节点,使用配置文件方法。
<sharding:inline-strategy id="databaseStrategy" sharding-column="user_id" algorithm-expression="ds$->{user_id % 2}" /> //总共两个节点,使用求余数算法。1.余数是0,就是0节点 2.余数是1,就是1节点。//写的时候,是哪个节点;读的时候,仍然还是同一个节点。//如果是使用按数据范围,或者日期范围(本质上也是数据范围),也是写的时候是哪一个节点,读的仍然是同一个节点。
如何唯一定位一张表?
数据库名字_表名字,二者结合起来唯一定位。
不同库的同一个表的名字,可以一样,也可以不一样。
路由算法
按范围
适合顺序增长的数据,比如:
1.整数类型的数据
useId
2.还有时间类型的数据
日期字段
单库是1000万
所以,每个1000万单独一个库。
分片-多维度字段查询的问题?
1.怎么知道当前登录userId是哪个库?userId后四位用来分片。
2.怎么知道当前orderId是哪个库? orderId字段包含userId后四位,就知道了是哪一个分片。
3.怎么知道当前时间段的数据是哪个库? 除了userId和orderId,即不包含分片字段的值,那么肯定就只能使用整个集群冗余的解决方案。
4.商户id维度 //同3
代理商id维度
hash
hash求余数
key是什么?
userId这样的唯一标识符字段。
分片/分表分库之后带来的问题-多维度查询
多维度查询 就是选择了分表的维度字段之后,如果要按其他字段查询怎么办?这种应用场景非常常见,比如下面几个应用场景。
解决方案-组合字段
1.分片字段
用户ID的后四位
2.订单ID字段的组成:orderId+userId后四位
订单ID建索引,用户ID后四位用于负载均衡,即路由当前订单到同一个数据库服务器。
3.如何知道日期、商户id/代理商id是分片/分表分库到哪一个库?其他维度只能通过整个集群冗余来实现。
解决方案-整个集群冗余
冗余 //整个集群冗余,一个集群一个维度 //缺点:1.数据一致性 2.浪费磁盘空间
同步复制数据 //数据同步基于binlog。会带来数据一致性问题,这个不可避免,只能权衡。//备库适合做实时性要求不高的读写
具体怎么做?
垂直切分缓解了原来单集群的压力,但是在抢购时依然捉襟见肘。原有的订单模型已经无法满足业务需求,于是我们设计了一套新的统一订单模型,为同时满足C端用户、B端商户、客服、运营等的需求,我们分别通过用户ID和商户ID进行切分,并通过PUMA(我们内部开发的MySQL binlog实时解析服务)同步到一个运营库。
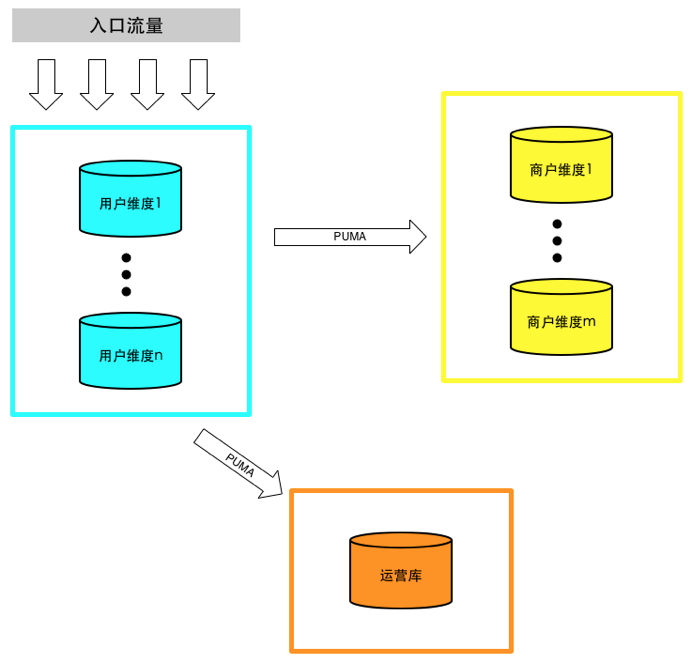
tech.meituan.com/2016/11/18/… //参考美团,就是每个维度,都要多出来一个集群的冗余。
表代替索引 m.blog.itpub.net/29254281/vi…
跨库查询 分别查询各个库,再组合到一起。
1.用户表 手机号登录查询
2.订单表 ID
date
商家ID
代理商ID
路由/负载均衡
ID/Key-唯一标识符------hashcode-----求余数=机器节点
核心步骤都是一模一样的!
参考
developer.51cto.com/art/201812/…
tech.meituan.com/2016/11/18/…
分库之后带来的问题
sql查询和操作问题
1.join连接
2.count(*)统计数量
3.order by排序
即但凡是涉及到数据不在同一个库的问题,最简单的解决方法都是分多次读数据然后再组合所有数据进行后续操作,优点是实现简单,缺点是性能低了一点,但是一般这种场景并不多,所以解决方案越简单越好。
跨库/分布式事务问题
---读写分离---
背景
大部分互联网业务读多写少,数据库的读往往最先成为性能瓶颈。
1.读 //读写分离是解决读的性能问题
2.写 //分表分库是解决 单表单库的数据量大 + 单机写的性能 问题
读写数据 //读写分离是提高读写能力 存储数据 //分表分库是提高存储能力,因为单机存储数据数量有限
实现思路
本质是区分写和读,区分完了之后再分别路由到写和读的机器。
解决方案
客户端实现
1.自己实现 //没必要,不推荐 2.开源软件 //现有的开源软件方案
服务器端实现
1.官方推荐Router 2.官方提供实现Proxy
开源软件
1.分表分库中间件
分表分库的软件sharding-jdbc也同时包含了读写分离实现,即可以根据sql解析出是写还是读。
2.阿里
3.360公司
工作使用
都没有读写分离。
具体实现步骤
自动识别sql是写还是读,然后路由到不同的服务器节点。引入中间件之后,对应用层是透明的。
总结
使用步骤
1.调用开源软件.读或写方法()设置读/写;
2.业务操作-读或写
这是显式地设置为读或写。如果想要自动识别是读还是写呢?分片中间件解析sql的时候,基于关键字字段识别是读还是写。总的来说,这些解决方案基本上对应用层面是透明的,即要做到非常的易于使用,无论是自己实现还是使用开源软件,基本上都只需要配置或者代码里设置当前是读/写或者完全就是自动识别不需要任何配置。引入中间件就是完全透明,中间件解析sql时自动识别是读还是写。
如果有多个从/读节点呢,怎么知道是哪一个从节点?所有的读节点数据都一样,不需要区分,路由到任意一个都可以。
读写分离和缓存解决方案的对比
总结
1.读写分离,解决“数据库读性能瓶颈”问题
2.水平切分,解决“数据库数据量大”问题
3.对于互联网大数据量,高并发量,高可用要求高,一致性要求高,前端面向用户的业务场景,微服务缓存架构,可能比数据库读写分离架构更合适 //缓存比读写分离更能解决读多的问题,因为1.缓存比读数据库快 2.读写分离数据库比缓存的高可用要差 3.数据库连接池也要区分读写数据库,也就是说但凡是提供读写分离的解决方案,不管是自己实现还是开源软件都需要在应用程序层面的跟数据库相关的方面都需要区分读写数据库
老师,您好 我个人的想法是可以加入缓存,例如注册后登录这种业务,可以在注册后加入数据库,并加入缓存,登录的时候先查缓存再查库表。 例如存入redis中并设置十分钟的过期时间。登录的时候先查redis,再查库表,如果redis中没有,说明就是过期的数据,这时候查从机就肯定存在了,希望能得到老师的点评,谢谢。
作者回复: 赞同,并不是说一有性能问题就上读写分离,而是应该先优化,例如优化慢查询,调整不合理的业务逻辑,引入缓存等,只有确定系统没有优化空间后,才考虑读写分离或者集群。//1.优化单机数据库表设计 sql 2.缓存 3.最后没有办法才是读写分离,因为读写分离带来的变化和影响最大,虽然性能最高
注:单机可以支持10万级别的用户量。
读写分离带来的问题
复制延迟 //读的时候数据不一致
延迟时间 //数据量大1s以上,数据量特别大即海量数据1min
解决方案 //核心业务走主,非核心业务才走从
参考
time.geekbang.org/column/arti… //专栏里有数据库的架构文章,可以好好参考一下,基本上算是业界的最佳实践了
