

这里有一份简洁的前端知识体系等待你查收,看看吧,会有惊喜哦~如果觉得不错,麻烦star哈~
前言
react 是数据驱动的框架,也是目前前端最火的框架之一,学习react,我们照旧从应用维度跟设计维度进行学习。
应用维度
问题
从技术的应用维度看,首先考虑的是要解决什么问题,这是技术产生的原因。问题这层,用来回答“干什么用”。
react 的诞生其实是要解决两个问题。UI细节问题问题 和 数据模型的问题。
UI细节问题问题
传统UI操作关注太多细节,jQuery虽然可以给我们提供了便捷的API,以及良好的浏览器兼容,但开发人员还是要手动去操作DOM,关注太多细节,不仅降低了开发效率,还容易引入BUG。
react以数据为中心,数据驱动视图,而不直接操作dom,也就是只负责描述界面应该显示成什么样子,而不关心实现细节。
数据模型的问题
在react之前,前端管理数据的模型是MVC架构。传统的MVC架构难以扩展和维护,当应用程序出现问题,很难知道是model还是view出现问题。
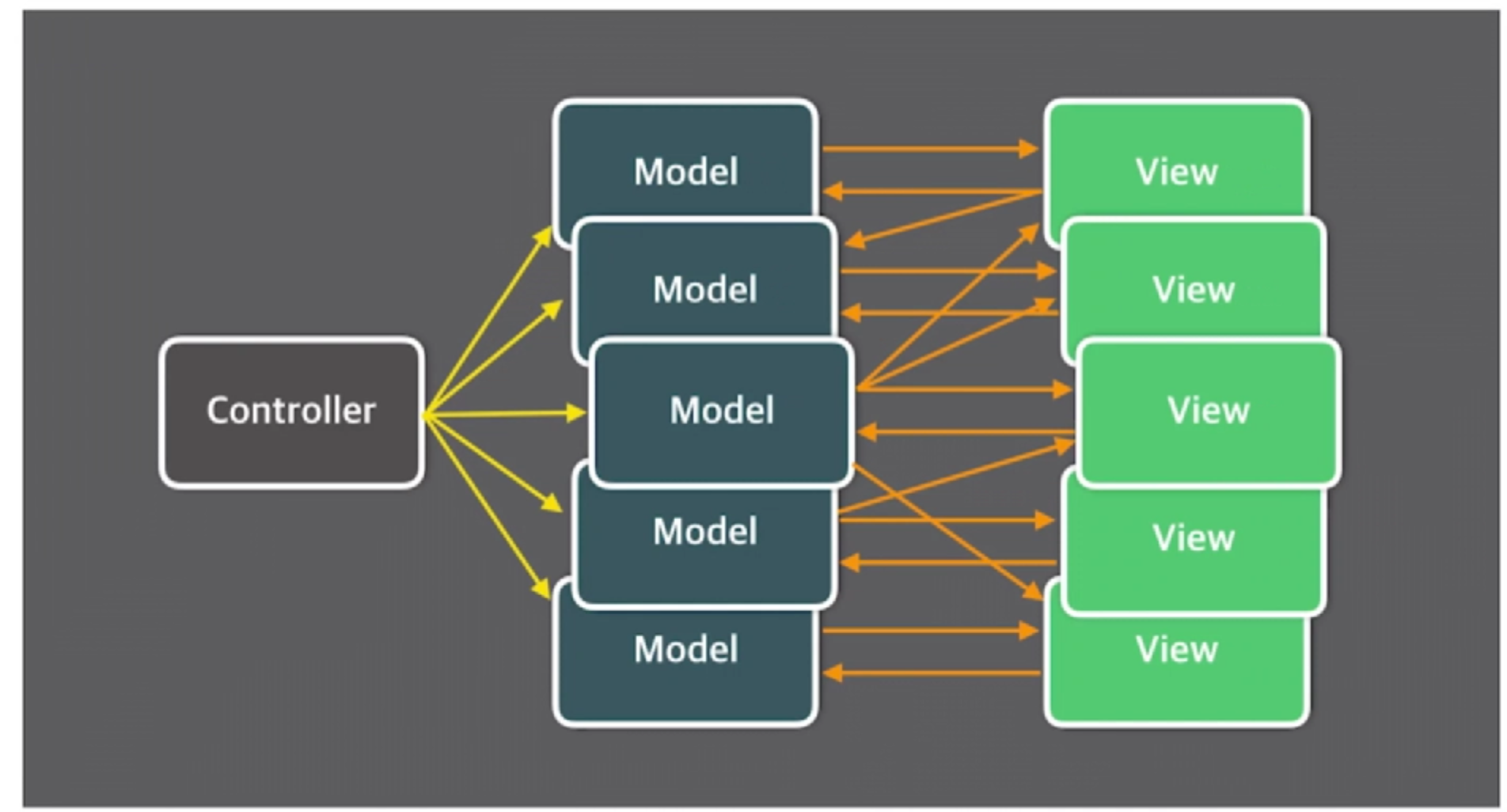
react采用的是单向数据流,可以很好的避免类似的问题。
技术规范
技术被研发出来,人们怎么用它才能解决问题呢?这就要看技术规范,可以理解为技术使用说明书。技术规范,回答“怎么用”的问题,反映你对该技术使用方法的理解深度。
React 的基本原则
要真正理解 React,开发者必须要明白这几点:
- React 界面完全由数据驱动;
- React 中一切都是组件;
- props 是 React 组件之间通讯的基本方式。
下面逐一分析。
笔者认为:学习框架,关键是要关注框架本身解决了什么问题,以及如何解决,这些才是框架最核心的部分,如果胡子眉毛一把抓,很容易就迷失在知识的海洋中。
细心的你肯定会发现,react的三个基本原则,正是解决上文提到的两大传统的良方。
针对UI细节问题,react的解决方案就是:数据驱动与组件化;
针对数据模型,react的解决方案是单向数据流,而props为单向数据流提供了支持。
学习react的过程中,牢记两大传统问题以及react开出的解决方案,有利于你形成系统思维,强化你的react的理解。
界面完全由数据驱动
React 的哲学,简单说来可以用下面这条公式来表示:
UI = f(data)
等号左边的 UI 代表最终画出来的界面;等号右边的 f 是一个函数,也就是我们写的 React 相关代码;data 就是数据,在 React 中,data 可以是 state 或者 props。
UI 就是把 data 作为参数传递给 f 运算出来的结果。这个公式的含义就是,如果要渲染界面,不要直接去操纵 DOM 元素,而是修改数据,由数据去驱动 React 来修改界面。
我们开发者要做的,就是设计出合理的数据模型,让我们的代码完全根据数据来描述界面应该画成什么样子,而不必纠结如何去操作浏览器中的 DOM 树结构。
这样一种程序结构,是声明式编程(Declarative Programming)的方式,代码结构会更加容易理解和维护。
组件:React 世界的一等公民
在 React 中一切皆为组件。这是因为:
- 用户界面就是组件;
- 组件可以嵌套包装组成复杂功能;
- 组件可以用来实现副作用。
第一点用户界面就是组件,很好理解,我们需要一个按钮,就可以实现一个Button组件,在 React 中,一个组件可以是一个类,也可以是一个函数,这取决于这个组件是否有自己的状态。
第二点,组件可以嵌套包装组成复杂功能。现实中的应用是很复杂的,React 中的组件可以重复嵌套,就是为了支持现实中的用户界面需要。
第三点,组件可以用来实现副作用。并不是说组件必须要在界面画一些东西,一个组件可以什么都不画,或者把画界面的事情交给其他组件去做,自己做一些和界面无关的事情,比如获取数据。
组件之间的语言:props
父组件想要传递数据给子组件,可以通过 props。
同样,子组件想要传递数据给父组件,可以让父组件传递一个函数类型的 props 进来,当子组件要传递数据给父组件时,调用这个函数类型 props,就把信息传递给了父组件。
如果两个完全没有关系的组件之间有话说,情况就复杂了一点,比如下图中,两个橙色组件之间如果有话说,就没法直接通过 props 来传递信息。
一个比较土的方法,就是通过 props 之间的逐步传递,来把这两个组件关联起来。如果之间跨越两三层的关系,这种方法还凑合,但是,如果这两个组件隔了十几层,或者说所处位置多变,那让 props 跨越千山万水来相会,实在是得不偿失。
另一个简单的方式,就是建立一个全局的对象,两个组件把想要说的话都挂在这个全局对象上。这种方法当然简单可行,但是,我们都知道全局变量的危害罄竹难书,如果不想将来被难以维护的代码折磨,我们最好对这种方法敬而远之。
一般,业界对于这种场景,往往会采用第三方数据管理工具来解决,比如 Redux 和 Mobx 。
其实,不依赖于第三方工具,React 也提供了自己的跨组件通讯方式,这种方式叫 Context,后面会介绍。
小结:
- 父组件向子组件通信:props
- 子组件向父组件通信
- 利用回调函数
- 利用自定义事件机制
- 跨级组件通信:context
- 没有嵌套关系的组件通信:自定义事件机制
组件设计
我们日常创建组件的一般步骤,是这样的:
- 创建静态 UI
- 考虑组件的状态组成:状态(state) 及 状态的改变(effect、reducer)
- 考虑组件的交互方式:状态的触发(dispatch)
如果要设计出更优雅的组件,我们还要了解组件设计原则。
React 组件设计原则,简单说来,就是高内聚、低耦合。
低耦合
就是要减少组件之间的耦合性,让系统易于理解、易于维护。
所以,创建组件的原则,归纳起来有两点:
- 何时创建组件:单一职责原则
- 每个组件只做一件事
- 如果组件变得复杂,那么应该拆分成小组件
- 数据状态管理:DRY原则
- 能计算得到的状态就不要单独存储
- 组件尽量无状态,所需数据通过 props 获取
更具体一点,在设计 React 组件时,要注意以下事项:
- 保持接口小,props 数量要少;
- 根据数据边界来划分组件,充分利用组合;
- 把 state 往上层组件提取,让下层组件只需要实现为纯函数。
高内聚
传统的网页应用分为三层,分别是用 HTML 实现的“内容”,用 CSS 实现的“样式”,还有用 JS 实现的“动态行为”。
HTML、CSS 和 JS 被分开管理,导致的问题是要修改一个功能,需要至少修改三个文件,这就违背了高内聚的原则。
在 React 中,当你要修改一个功能的内容和行为时,在一个文件中就能完成,这样就满足了高内聚的要求。
在react中处理CSS,官方没有一个统一的标准,请看后面样式处理的章节。
组件设计的内容远不止这些。社区有非常多的最佳实践,请看组件设计模式
状态管理·组件状态
在前面的章节中,我们反复声明过 React 其实就是这样一个公式:
UI = f(data)
f 的参数 data,除了 props,就是 state。props 是组件外传递进来的数据,state 代表的就是 React 组件的内部状态。
为什么要了解 React 组件自身状态管理
虽然有 Redux 和 Mobx 这样的状态管理工具,不过,我们首先不要管这些第三方工具,先从了解 React 组件自身的管理开始。
为什么呢?
第一个原因,因为 React 组件自身的状态管理是基础,其他第三方工具都是在这个基础上构筑的,连基础都不了解,无法真正理解第三方工具。
另一个重要原因,对于很多应用场景,React 组件自身的状态管理就足够解决问题,犯不上动用 Redux 和 MobX 这样的大杀器,简单问题简单处理,可以让代码更容易维护。
组件自身状态 state
什么数据放在 state 中
判断一个数据应该放在哪里,用下面的原则:
- 如果数据由外部传入,放在 props 中;
- 如果是组件内部状态,是否这个状态更改应该立刻引发一次组件重新渲染?如果是,放在 state 中;不是,放在成员变量中。
修改 state 的正确方式
不能直接修改 state 对象,必须使用 this.setState。
因为使用 setState 函数,那不光修改 state,还能引发组件的重新渲染。
state 改变引发重新渲染的时机
React 为了性能考虑,不会每次 setState 都引发重新渲染。
this.setState({count: 1});
this.setState({caption: 'foo'});
this.setState({count: 2});
连续的同步调用 setState,第三次还覆盖了第一次调用的效果,但是效果只相当于调用了下面这样一次:
this.setState({count: 2, caption: 'foo'});
每个 setState 都引发一次重新渲染,实在太浪费了。
React 非常巧妙地用任务队列解决了这个问题,可以理解为每次 setState 函数调用都会往 React 的任务队列里放一个任务,多次 setState 调用自然会往队列里放多个任务。React 会选择时机去批量处理队列里执行任务,当批量处理开始时,React 会合并多个 setState 的操作,比如上面的三个 setState 就被合并为只更新 state 一次,也只引发一次重新渲染。
因为这个任务队列的存在,React 并不会同步更新 state,所以,在 React 中,setState 也不保证同步更新 state 中的数据。
state 不会被同步修改
简单说来,调用 setState 之后的下一行代码,读取 this.state 并不是修改之后的结果。
console.log(this.state.count);// 修改之前this.state.count为0
this.setState({count: 1})
console.log(this.state.count);// 在这里this.state.count依然为0
这是因为React 的任务队列机制。setState 只是给任务队列里增加了一个修改 this.state 的任务,这个任务并没有立即执行,所以 this.state 并不会立刻改变。
但也有例外。由 React 的生命周期函数或者事件处理函数之外引起的 setState ,就可以同步更新 state。
看下面的代码,结果可能会出乎你的所料:
setTimeout(() => {
this.setState({count: 2}); //这会立刻引发重新渲染
console.log(this.state.count); //这里读取的count就是2
}, 0);
为什么 setTimeout 能够强迫 setState 同步更新 state 呢?
可以这么理解,当 React 调用某个组件的生命周期函数或者事件处理函数时,React 会想:“嗯,这一次函数可能调用多次 setState,我会先打开一个标记,只要这个标记是打开的,所有的 setState 调用都是往任务队列里放任务,当这一次函数调用结束的时候,我再去批量处理任务队列,然后把这个标记关闭。”
因为 setTimeout 是一个 JS 函数,和 React 无关,对于 setTimeout 的第一个函数参数,这个函数参数的执行时机,已经不是 React 能够控制的了,换句话说,React 不知道什么时候这个函数参数会被执行,所以那个“标记”也没有打开。
当那个“标记”没有打开时,setState 就不会给任务列表里增加任务,而是强行立刻更新 state 和引发重新渲染。这种情况下,React 认为:“这个 setState 发生在自己控制能力之外,也许开发者就是想要强行同步更新呢,宁滥勿缺,那就同步更新了吧。”
虽然有办法同步更新state,但要谨慎使用。
React 选择不同步更新 state,是一种性能优化。
而且,每当你觉得需要同步更新 state 的时候,往往说明你的代码设计存在问题,绝大部分情况下,你所需要的,并不是“state 立刻更新”,而是,“确定 state 更新之后我要做什么”,这就引出了 setState 另一个功能。
setState 的第二个参数
setState 的第二个参数可以是一个回调函数,当 state 真的被修改时,这个回调函数会被调用。
console.log(this.state.count); // 0
this.setState({count: 1}, () => {
console.log(this.state.count); // 这里就是1了
})
console.log(this.state.count); // 依然为0
当 setState 的第二个参数被调用时,React 已经处理完了任务列表,所以 this.state 就是更新后的数据。
如果需要在 state 更新之后做点什么,请利用第二个参数。
函数式 setState
setState 的第一个参数除了可以是对象,其实也可以传入一个函数。
当 setState 的第一个参数为函数时,任务列表上增加的就是一个可执行的任务函数了,React 每处理完一个任务,都会更新 this.state,然后把新的 state 传递给这个任务函数。
setState 第一个参数的形式如下:
function increment(state, props) {
return {count: state.count + 1};
}
可以看到,这是一个纯函数,不光接受当前的 state,还接受组件的 props,在这个函数中可以根据 state 和 props 任意计算,返回的结果会用于修改 this.state。
如此一来,我们就可以这样连续调用 setState:
this.setState(increment);
this.setState(increment);
this.setState(increment);
用这种函数式方式连续调用 setState,就真的能够让 this.state.count 增加 3,而不只是增加 1。
最佳实践
最佳实践回答“怎么能用好”的问题,反映你实践经验的丰富程度。
组件设计模式
聪明组件和傻瓜组件
聪明组件和傻瓜组件:让我们更好的组织代码
在 React 应用中,最简单也是最常用的一种组件模式,就是“聪明组件和傻瓜组件”。
软件设计中有一个原则,叫做“责任分离”,简单说就是让一个模块的责任尽量少,如果发现一个模块功能过多,就应该拆分为多个模块,让一个模块都专注于一个功能,这样更利于代码的维护。
使用 React 来做界面,无外乎就是获得驱动界面的数据,然后利用这些数据来渲染界面。
把获取和管理数据的逻辑放在父组件,也就是聪明组件;把渲染界面的逻辑放在子组件,也就是傻瓜组件。
这么做的好处,是可以灵活地修改数据状态管理方式,比如,最初你可能用 Redux 来管理数据,然后你想要修改为用 Mobx,如果按照这种模式分割组件,那么,你需要改的只有聪明组件,傻瓜组件可以保持原状。
因为傻瓜组件一般没有自己的状态,我们可以利用 PureComponent 来提高傻瓜组件的性能。
PureComponent 帮我们处理了shouldComponentUpdate。
值得一提的是,PureComponent 中 shouldComponentUpdate 对 props 做得只是浅层比较,不是深层比较,如果 props 是一个深层对象,就容易产生问题。
比如,两次渲染传入的某个 props 都是同一个对象,但是对象中某个属性的值不同,这在 PureComponent 眼里,props 没有变化,不会重新渲染,但是这明显不是我们想要的结果。
虽然 PureComponent 可以提高组件渲染性能,但是它也不是没有代价的,它逼迫我们必须把组件实现为 class,不能用纯函数来实现组件。
如果你使用 React v16.6.0 之后的版本,可以使用一个新功能 React.memo 来完美实现 React 组件,比如:
const Joke = React.memo(() => (
<div>
<img src={SmileFace} />
{this.props.value || 'loading...' }
</div>
));
高阶组件
高阶组件:让我们更好的抽象公共逻辑
在开发 React 组件过程中,很容易发现这样一种现象,某些功能是多个组件通用的,如果每个组件都重复实现这样的逻辑,肯定十分浪费,而且违反了“不要重复自己”(DRY,Don't Repeat Yourself)的编码原则,我们肯定想要把这部分共用逻辑提取出来重用。
我们说过,在 React 的世界里,组件是第一公民,首先想到的是当然是把共用逻辑提取为一个 React 组件。不过,有些情况下,这些共用逻辑还没法成为一个独立组件,换句话说,这些共用逻辑单独无法使用,它们只是对其他组件的功能加强。
举个例子,对于很多网站应用,有些模块都需要在用户已经登录的情况下才显示。比如,对于一个电商类网站,“退出登录”按钮、“购物车”这些模块,就只有用户登录之后才显示,对应这些模块的 React 组件如果连“只有在登录时才显示”的功能都重复实现,那就浪费了。
这时候,我们就可以利用“高阶组件(HoC)”这种模式来解决问题。
高阶组件的基本形式
高阶组件,本质是一个函数,它接受至少一个 React 组件为参数,并且能够返回一个全新的 React 组件作为结果,当然,这个新产生的 React 组件是对作为参数的组件的包装,所以,有机会赋予新组件一些增强的“神力”。
一个最简单的高阶组件是这样的形式:
const withDoNothing = (Component) => {
const NewComponent = (props) => {
return <Component {...props} />;
};
return NewComponent;
};
有了高阶组件,我们就可以用它来抽取共同逻辑。
高阶组件的高级用法
高阶组件只需要返回一个 React 组件即可,没人规定高阶组件只能接受一个 React 组件作为参数,完全可以传入多个 React 组件给高阶组件。
我们可以用高阶组件封装登录与登出的逻辑,如下:
const withLoginAndLogout = (ComponentForLogin, ComponentForLogout) => {
const NewComponent = (props) => {
if (getUserId()) {
return <ComponentForLogin {...props} />;
} else {
return <ComponentForLogout{...props} />;
}
}
return NewComponent;
};
链式调用高阶组件
高阶组件最巧妙的一点,是可以链式调用。
假设,你有三个高阶组件分别是 withOne、withTwo 和 withThree,那么,如果要赋予一个组件 X 三个高阶组件的超能力,可以连续调用高阶组件,如下:
const SuperX = withThree(withTwo(withOne(X)));
高阶组件本身就是一个纯函数,纯函数是可以组合使用的,所以,我们其实可以把多个高阶组件组合为一个高阶组件,然后用这一个高阶组件去包装X,代码如下:
const hoc = compose(withThree, withTwo, withOne);
const SuperX = hoc(X);
在上面代码中使用的 compose,是函数式编程中很基础的一种方法,作用就是把多个函数组合为一个函数。
React 组件可以当做积木一样组合使用,现在有了 compose,我们就可以把高阶组件也当做积木一样组合,进一步重用代码。
假如一个应用中多个组件都需要同样的多个高阶组件包装,那就可以用 compose 组合这些高阶组件为一个高阶组件,这样在使用多个高阶组件的地方实际上就只需要使用一个高阶组件了。
不要滥用高阶组件
高阶组件虽然可以用一种可重用的方式扩充现有 React 组件的功能,但高阶组件并不是绝对完美的。
首先,高阶组件不得不处理 displayName,不然 debug 会很痛苦。当 React 渲染出错的时候,靠组件的 displayName 静态属性来判断出错的组件类,而高阶组件总是创造一个新的 React 组件类,所以,每个高阶组件都需要处理一下 displayName。
如果要做一个最简单的什么增强功能都没有的高阶组件,也必须要写下面这样的代码:
const withExample = (Component) => {
const NewComponent = (props) => {
return <Component {...props} />;
}
NewComponent.displayName = `withExample(${Component.displayName || Component.name || 'Component'})`;
return NewCompoennt;
};
对于 React 生命周期函数,高阶组件不用怎么特殊处理,但是,如果内层组件包含定制的静态函数,这些静态函数的调用在 React 生命周期之外,那么高阶组件就必须要在新产生的组件中增加这些静态函数的支持,这更加麻烦。关于这点,请参考这里
其次,高阶组件支持嵌套调用,这是它的优势。但是如果真的一大长串高阶组件被应用的话,当组件出错,你看到的会是一个超深的 stack trace,十分痛苦。
关于高阶组件的进阶内容,请参考高阶组件实现方法
render props 模式
render props 模式:让我们更好的抽象公共逻辑,同时又避免了高阶组件的一些问题
高阶组件并不是 React 中唯一的重用组件逻辑的方式,且高阶组件存在一些弊端,所以又诞生了render props 模式,也称为“以函数为子组件”的模式。
所谓 render props,指的是让 React 组件的 props 支持函数这种模式。因为作为 props 传入的函数往往被用来渲染一部分界面,所以这种模式被称为 render props。
一个最简单的 render props 组件 RenderAll,代码如下:
const RenderAll = (props) => {
return(
<React.Fragment>
{props.children(props)}
</React.Fragment>
);
};
这个 RenderAll 预期子组件是一个函数,它所做的事情就是把子组件当做函数调用,调用参数就是传入的 props,然后把返回结果渲染出来,除此之外什么事情都没有做。
使用 RenderAll 的代码如下:
<RenderAll>
{() => <h1>hello world</h1>}
</RenderAll>
可以看到,RenderAll 的子组件,也就是夹在 RenderAll 标签之间的部分,其实是一个函数。这个函数渲染出 <h1>hello world</h1>,这就是上面使用 RenderAll 渲染出来的结果。
当然,这个 RenderAll 没做任何实际工作,接下来我们看 render props 真正强悍的使用方法。
传递 props
下面是实现 render props 的 Login 组件,可以看到,render props 和高阶组件的第一个区别,就是 render props 是真正的 React 组件,而不是一个返回 React 组件的函数。
const Login = (props) => {
const userName = getUserName();
if (userName) {
const allProps = {userName, ...props};
return (
<React.Fragment>
{props.children(allProps)}
</React.Fragment>
);
} else {
return null;
}
};
当用户处于登录状态,getUserName 返回当前用户名,否则返回空,然后我们根据这个结果决定是否渲染 props.children 返回的结果。
当然,render props 完全可以决定哪些 props 可以传递给 props.children,在 Login 中,我们把 userName 作为增加的 props 传递给下去,这样就是 Login 的增强功能。
一个使用上面 Login 的 JSX 代码示例如下:
<Login>
{({userName}) => <h1>Hello {userName}</h1>}
</Login>
不局限于 children
render props 这个模式不必局限于 children 这一个 props,任何一个 props 都可以作为函数,也可以利用多个 props 来作为函数。
我们来扩展 Login,不光在用户登录时显示一些东西,也可以定制用户没有登录时显示的东西,我们把这个组件叫做 Auth,对应代码如下:
const Auth= (props) => {
const userName = getUserName();
if (userName) {
const allProps = {userName, ...props};
return (
<React.Fragment>
{props.login(allProps)}
</React.Fragment>
);
} else {
<React.Fragment>
{props.nologin(props)}
</React.Fragment>
}
};
用法如下:
<Auth
login={({userName}) => <h1>Hello {userName}</h1>}
nologin={() => <h1>Please login</h1>}
/>
依赖注入
render props 其实就是 React 世界中的“依赖注入”。
所谓依赖注入,指的是解决这样一个问题:逻辑 A 依赖于逻辑 B,如果让 A 直接依赖于 B,当然可行,但是 A 就没法做得通用了。依赖注入就是把 B 的逻辑以函数形式传递给 A,A 和 B 之间只需要对这个函数接口达成一致就行,如此一来,再来一个逻辑 C,也可以用一样的方法重用逻辑 A。
在上面的代码示例中,Login 和 Auth 组件就是上面所说的逻辑 A,而传递给组件的函数类型 props,就是逻辑 B 和 C。
render props 和高阶组件的比较
首先,render props 模式的应用,就是做一个 React 组件,而高阶组件,虽然名为“组件”,其实只是一个产生 React 组件的函数。
render props 不像高阶组件有那么多毛病,如果说 render props 有什么缺点,那就是 render props 不能像高阶组件那样链式调用,当然,这并不是一个致命缺点。
render props 相对于高阶组件还有一个显著优势,就是 props 传递更加灵活。
总结:当需要重用 React 组件的逻辑时,建议首先看这个功能是否可以抽象为一个简单的组件;如果行不通的话,考虑是否可以应用 render props 模式;再不行的话,才考虑应用高阶组件模式。
mixin
mixin:一样可以抽象公共逻辑,但现在已经不提倡使用。这里只做简单介绍。
React 在使用 createClass 构建组件时提供了 mixin 属性。mixin有两个作用:
- 共享工具方法。
- 生命周期继承,props 与 state 合并。
ES6 Classes 不支持 mixin。
mixin 的问题:
- 破坏了原有组件的封装:mixin 方法会混入方法,给原有组件带来新的特性,但它也可能带来了新的 state 和 props,这意味着组件有一 些“不可见”的状态需要我们去维护,但我们在使用的时候并不清楚。另外,mixin 也有可能去依赖其他的 mixin,这样会建立一个 mixin 的依赖链,当我们改动其 中一个 mixin 的状态时,很可能会直接影响其他的 mixin。
- 命名冲突:尽管我们可以通过更改名字来解决,但遇到第三方引用,或已经引用了几个 mixin 的情况下, 总是要花一定的成本去解决冲突。
- 增加复杂性
高阶组件与mixin的比较
高阶组件与 mixin 的不同之处
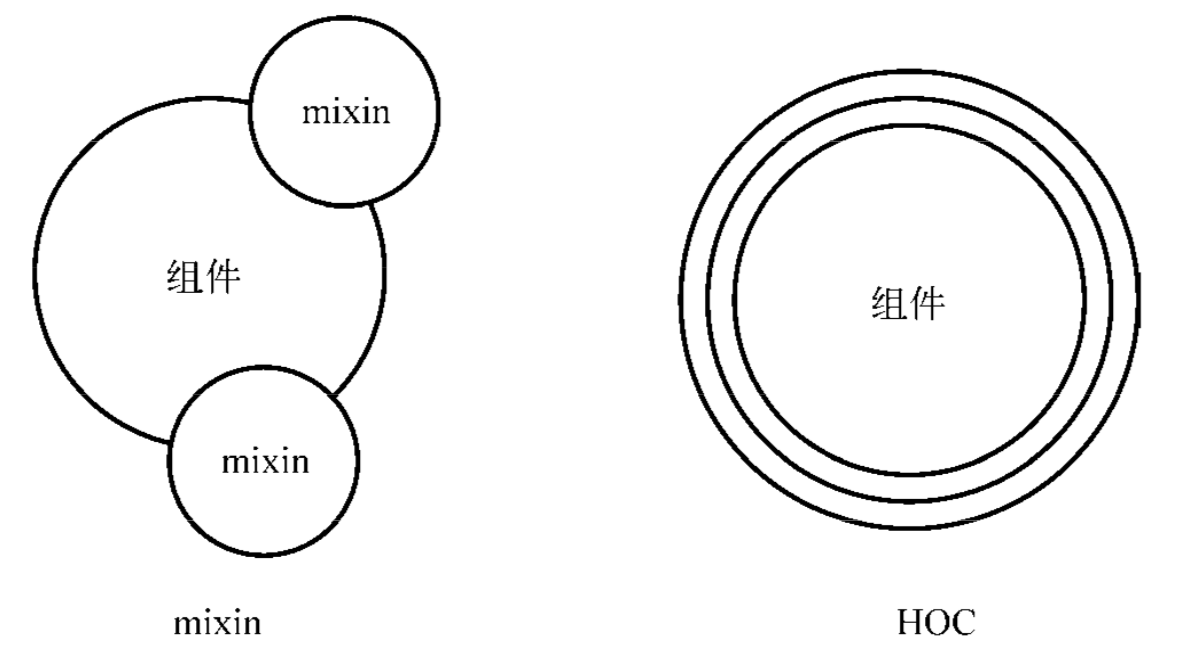
高阶组件符合函数式编程思想。对于原组件来说,并不会感知到高阶组件的存在,只需要把功能套在它之上就可以了,从而避免了使用 mixin 时产生的副作用。
提供者模式
提供者模式:让我们更好的跨层级传递数据
在 React 中,props 是组件之间通讯的主要手段,但是,有一种场景单纯靠 props 来通讯是不恰当的,那就是两个组件之间间隔着多层其他组件,下面是一个简单的组件树示例图图:
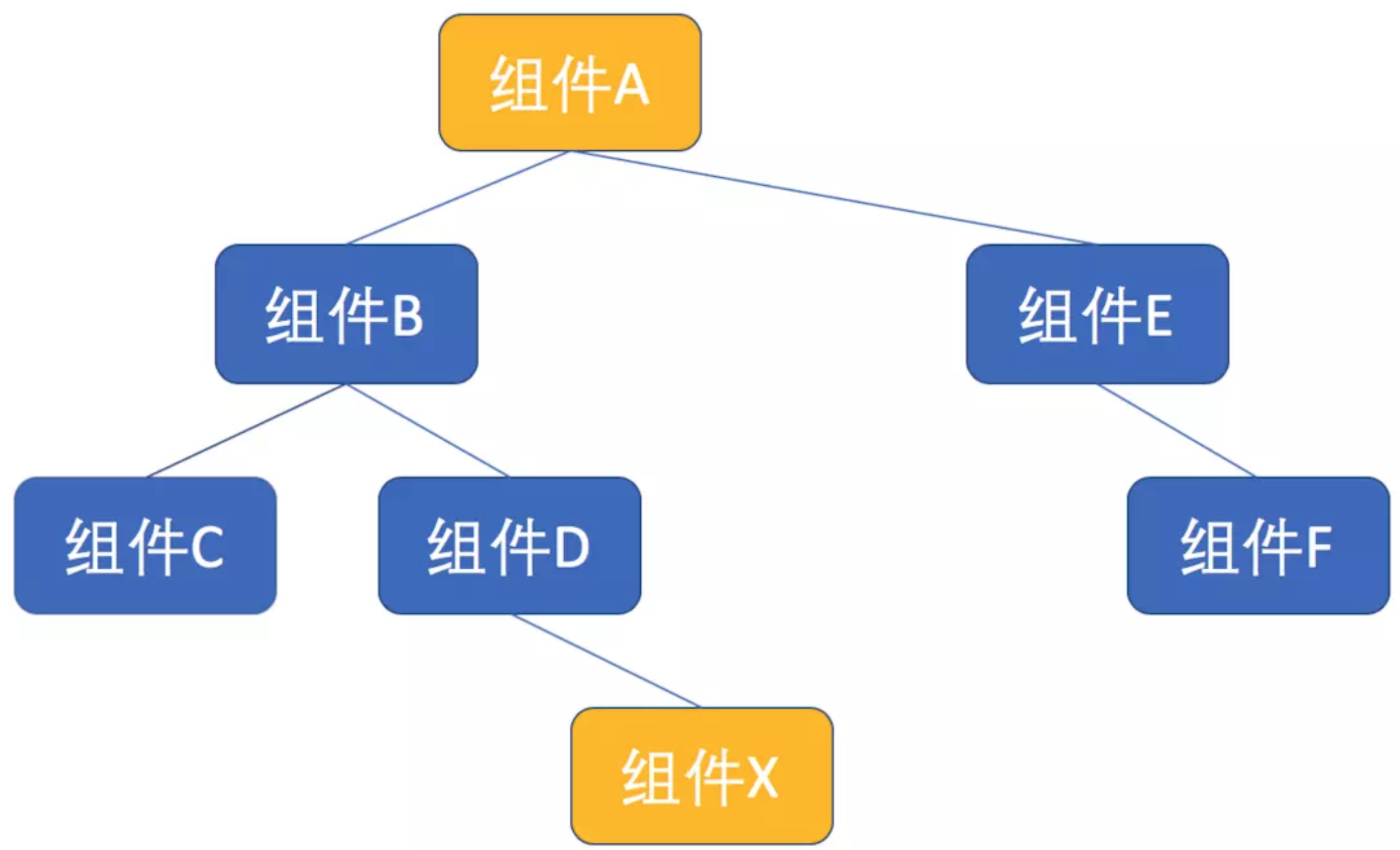
在上图中,组件 A 需要传递信息给组件 X,如果通过 props 的话,那么从顶部的组件 A 开始,要把 props 传递给组件 B,然后组件 B 传递给组件 D,最后组件 D 再传递给组件 X。
其实组件 B 和组件 D 完全用不上这些 props,但是又被迫传递这些 props,这明显不合理,要知道组件树的结构会变化的,将来如果组件 B 和组件 D 之间再插入一层新的组件,这个组件也需要传递这个 props,这就麻烦无比。
可见,对于跨级的信息传递,我们需要一个更好的方法。
在 React 中,解决这个问题应用的就是“提供者模式”。
提供者模式
提供者模式有两个角色,一个叫“提供者”(Provider),另一个叫“消费者”(Consumer)。在上面的组件树中,组件 A 可以作为提供者,组件 X 就是消费者。
既然名为“提供者”,它可以提供一些信息,而且这些信息在它之下的所有组件,无论隔了多少层,都可以直接访问到,而不需要通过 props 层层传递。
避免 props 逐级传递,即是提供者的用途。
如何实现提供者模式
实现提供者模式,需要 React 的 Context 功能,可以说,提供者模式只不过是让 Context 功能更好用一些而已。
所谓 Context 功能,就是能够创造一个“上下文”,在这个上下文笼罩之下的所有组件都可以访问同样的数据。
提供者模式的一个典型用例就是实现“样式主题”(Theme),由顶层的提供者确定一个主题,下面的样式就可以直接使用对应主题里的样式。这样,当需要切换样式时,只需要修改提供者就行,其他组件不用修改。
React v16.3.0 之前的提供者模式
在 React v16.3.0 之前,要实现提供者,就要实现一个 React 组件,不过这个组件要做两个特殊处理。
- 需要实现 getChildContext 方法,用于返回“上下文”的数据;
- 需要定义 childContextTypes 属性,声明“上下文”的结构。
下面就是一个实现“提供者”的例子,组件名为 ThemeProvider:
class ThemeProvider extends React.Component {
getChildContext() {
return {
theme: this.props.value
};
}
render() {
return (
<React.Fragment>
{this.props.children}
</React.Fragment>
);
}
}
ThemeProvider.childContextTypes = {
theme: PropTypes.object
};
对于 ThemeProvider,我们创造了一个上下文,这个上下文就是一个对象,结构是这样:
{
theme: {
//一个对象
}
}
接下来,就是使用这个“上下文”的组件。这里有两种方式:
使用类的方式:
class Subject extends React.Component {
render() {
const {mainColor} = this.context.theme;
return (
<h1 style={{color: mainColor}}>
{this.props.children}
</h1>
);
}
}
Subject.contextTypes = {
theme: PropTypes.object
}
使用纯函数组件:
const Paragraph = (props, context) => {
const {textColor} = context.theme;
return (
<p style={{color: textColor}}>
{props.children}
</p>
);
};
Paragraph.contextTypes = {
theme: PropTypes.object
};
这两种方式访问“上下文”的方式有些不同,都必须增加 contextTypes 属性,必须和 ThemeProvider 的 childContextTypes 属性一致,不然,this.context 就不会得到任何值。
最后,我们看如何结合”提供者“和”消费者“。
我们做一个组件来使用 Subject 和 Paragraph,这个组件不需要帮助传递任何 props,代码如下:
const Page = () => (
<div>
<Subject>这是标题</Subject>
<Paragraph>
这是正文
</Paragraph>
</div>
);
上面的组件 Page 使用了 Subject 和 Paragraph,现在我们想要定制样式主题,只需要在 Page 或者任何需要应用这个主题的组件外面包上 ThemeProvider,对应的 JSX 代码如下:
<ThemeProvider value={{mainColor: 'green', textColor: 'red'}} >
<Page />
</ThemeProvider>
当我们需要改变一个样式主题的时候,改变传给 ThemeProvider的 value 值就搞定了。
React v16.3.0 之后的提供者模式
首先,要用新提供的 createContext 函数创造一个“上下文”对象。
const ThemeContext = React.createContext();
这个“上下文”对象 ThemeContext 有两个属性,分别就是——对,你没猜错——Provider 和 Consumer。
const ThemeProvider = ThemeContext.Provider;
const ThemeConsumer = ThemeContext.Consumer;
使用“消费者”如下:
const Paragraph = (props, context) => {
return (
<ThemeConsumer>
{
(theme) => (
<p style={{color: theme.textColor}}>
{props.children}
</p>
)
}
</ThemeConsumer>
);
};
实现 Page 的方式并没有变化:
<ThemeProvider value={{mainColor: 'green', textColor: 'red'}} >
<Page />
</ThemeProvider>
两种提供者模式实现方式的比较
在老版 Context API 中,“上下文”只是一个概念,并不对应一个代码,两个组件之间达成一个协议,就诞生了“上下文”。
在新版 Context API 中,需要一个“上下文”对象(上面的例子中就是 ThemeContext),使用“提供者”的代码和“消费者”的代码往往分布在不同的代码文件中,那么,这个 ThemeContext 对象放在哪个代码文件中呢?
最好是放在一个独立的文件中,这么一来,就多出一个代码文件,而且所有和这个“上下文”相关的代码,都要依赖于这个“上下文”代码文件,虽然这没什么大不了的,但是的确多了一层依赖关系。
为了避免依赖关系复杂,每个应用都不要滥用“上下文”,应该限制“上下文”的使用个数。
组合组件
组合组件:简化父组件向子组件传递props的方式
组合组件模式要解决的是这样一类问题:父组件想要传递一些信息给子组件,但是,如果用 props 传递又显得十分麻烦。
利用 Context 可以解决问题,但非常繁琐,组合组件让我们可以用更简洁的方式去实现。
问题描述
很多界面都有 Tab 这样的元件,我们需要一个 Tabs 组件和 TabItem 组件,Tabs 是容器,TabItem 是一个一个单独的 Tab,因为一个时刻只有一个 TabItem 被选中,很自然希望被选中的 TabItem 样式会和其他 TabItem 不同。
这并不是一个很难的功能,首先我们想到的就是,用 Tabs 中一个 state 记录当前被选中的 Tabitem 序号,然后根据这个 state 传递 props 给 TabItem,当然,还要传递一个 onClick 事件进去,捕获点击选择事件。
按照这样的设计,Tabs 中如果要显示 One、Two、Three 三个 TabItem,JSX 代码大致这么写:
<TabItem active={true} onClick={this.onClick}>One</TabItem>
<TabItem active={false} onClick={this.onClick}>Two</TabItem>
<TabItem active={false} onClick={this.onClick}>Three</TabItem>
这样写可以实现功能,但未免过于繁琐,且不利于维护。我们希望可以简单点,最好代码就这样:
<Tabs>
<TabItem>One</TabItem>
<TabItem>Two</TabItem>
<TabItem>Three</TabItem>
</Tabs>
类似这种场景,父子组件不通过 props 传递,二者之间有某种神秘的“组合”,就是我们所说的“组合组件”。
实现方式
我们先写出 TabItem 的代码,如下:
const TabItem = (props) => {
const {active, onClick} = props;
const tabStyle = {
'max-width': '150px',
color: active ? 'red' : 'green',
border: active ? '1px red solid' : '0px',
};
return (
<h1 style={tabStyle} onClick={onClick}>
{props.children}
</h1>
);
};
有了 TabItem ,我们再看下 TabItem 的调用方式。
<Tabs>
<TabItem>One</TabItem>
<TabItem>Two</TabItem>
<TabItem>Three</TabItem>
</Tabs>
没有 props 传递,怎么悄无声息地把 active 和 onClick 传递给 TabItem ?
我们可以把 props.children 拷贝一份,这样就有机会去篡改这份拷贝,最后渲染这份拷贝就好了。
我们来看 Tabs 的实现代码:
class Tabs extends React.Component {
state = {
activeIndex: 0
}
render() {
const newChildren = React.Children.map(this.props.children, (child, index) => {
if (child.type) {
return React.cloneElement(child, {
active: this.state.activeIndex === index,
onClick: () => this.setState({activeIndex: index})
});
} else {
return child;
}
});
return (
<Fragment>
{newChildren}
</Fragment>
);
}
}
在 render 函数中,我们用了 React 中不常用的两个 API:
- React.Children.map
- React.cloneElement
使用 React.Children.map,可以遍历 children 中所有的元素,因为 children 可能是一个数组嘛。
使用 React.cloneElement 可以复制某个元素。这个函数第一个参数就是被复制的元素,第二个参数可以增加新产生元素的 props,我们就是利用这个机会,把 active 和 onClick 添加了进去。
这两个 API 双剑合璧,就能实现不通过表面的 props 传递,完成两个组件的“组合”。
实际应用
应用组合组件的往往是共享组件库,把一些常用的功能封装在组件里,让应用层直接用就行。在 antd 和 bootstrap 这样的共享库中,都使用了组合组件这种模式。
模式总结
所谓模式,就是特定于一种问题场景的解决办法。
模式(Pattern) = 问题场景(Context) + 解决办法(Solution)
如果不搞清楚场景,单纯知道有这么一个办法,就好比拿到了一杆枪却不知道这杆枪用于打什么目标,是没有任何意义的。并不是所有的枪都是一样的,有的枪擅长狙击,有的枪适合近战,有的枪只是发个信号。
模式就是我们的武器,我们一定要搞清楚一件武器应用的场合,才能真正发挥这件武器的威力。
高阶组件实现方法
实现高阶组件的方法有:
属性代理
定义:高阶组件通过被包裹的 React 组件来操作 props。
import React from 'react';
const MyContainer = WrapComponent =>
class extends React.Component {
render () {
return <WrapComponent {...this.props} />;
}
};
高阶组件的作用有:控制 props、通过 refs 使用引用、抽象 state 和使用其他元素包裹。
控制 props
我们可以读取、增加、编辑或是移除从 WrappedComponent 传进来的 props,但需要小心删除与编辑重要的 props。我们应该尽可能对高阶组件的 props 作新的命名以防止混淆。
通过 refs 使用引用
在高阶组件中,我们可以接受 refs 使用WrappedComponent 的引用。
import React, {Component} from 'React';
const MyContainer = WrappedComponent =>
class extends Component {
proc (wrappedComponentInstance) {
wrappedComponentInstance.method ();
}
render () {
const props = Object.assign ({}, this.props, {
ref: this.proc.bind (this),
});
return <WrappedComponent {...props} />;
}
};
当 WrappedComponent 被渲染时,refs 回调函数就会被执行,这样就会拿到一份Wrapped-Component 实例的引用。这就可以方便地用于读取或增加实例的 props,并调用实例的方法。
抽象 state
我们可以通过 WrappedComponent 提供的 props 和回调函数抽象 state,高阶组件可以将原组件抽象为展示型组件,分离内部状态。
import React, {Component} from 'React';
const MyContainer = WrappedComponent =>
class extends Component {
constructor (props) {
super (props);
this.state = {
name: '',
};
this.onNameChange = this.onNameChange.bind (this);
}
onNameChange (event) {
this.setState ({
name: event.target.value,
});
}
render () {
const newProps = {
name: {
value: this.state.name,
onChange: this.onNameChange,
},
};
return <WrappedComponent {...this.props} {...newProps} />;
}
};
我们把 input 组件中对 name prop 的 onChange 方法提取到高阶组件中,这样就有效地抽象了同样的 state 操作。可以这么来使用它
import React, {Component} from 'React';
@MyContainer
class MyComponent extends Component {
render () {
return <input name="name" {...this.props.name} />;
}
}
通过这样的封装,我们就得到了一个被控制的 input 组件。
使用其他元素包裹 WrappedComponent
我们还可以使用其他元素来包裹 WrappedComponent,这既可以是为了加样式,也可 以是为了布局。
import React, {Component} from 'React';
const MyContainer = WrappedComponent =>
class extends Component {
render () {
return (
<div style={{display: 'block'}}>
{' '}<WrappedComponent {...this.props} />
</div>
);
}
};
反向继承
定义:高阶组件继承于被包裹的 React 组件(从字面意思上看,它一定与继承特性相关)
简单例子:高阶组件返回的组件继承于 WrappedComponent。因为被动地继承了 WrappedComponent,所有的调用都会反向,这也是这种方法的由来。
const MyContainer = WrappedComponent =>
class extends WrappedComponent {
render () {
return super.render ();
}
};
在反向继承方法中,高阶组件可以使用 WrappedComponent 引用,这意味着它可以使用WrappedComponent 的 state、props 、生命周期和 render 方法。但它不能保证完整的子组件树被解析。
反向继承两大特点:
渲染劫持
渲染劫持指的就是高阶组件可以控制 WrappedComponent 的渲染过程,并渲染各种各样的结 果。我们可以在这个过程中在任何 React 元素输出的结果中读取、增加、修改、删除 props,或 读取或修改 React 元素树,或条件显示元素树,又或是用样式控制包裹元素树。
正如之前说到的,反向继承不能保证完整的子组件树被解析,这意味着将限制渲染劫持功能。 渲染劫持的经验法则是我们可以操控 WrappedComponent 的元素树,并输出正确的结果。但如果 元素树中包括了函数类型的 React 组件,就不能操作组件的子组件。
const MyContainer = WrappedComponent =>
class extends WrappedComponent {
render () {
if (this.props.loggedIn) {
return super.render ();
} else {
return null;
}
}
};
控制 state
高阶组件可以读取、修改或删除WrappedComponent 实例中的 state,如果需要的话,也可以 增加 state。但这样做,可能会让WrappedComponent 组件内部状态变得一团糟。大部分的高阶组 件都应该限制读取或增加 state,尤其是后者,可以通过重新命名 state,以防止混淆。
const MyContainer = WrappedComponent =>
class extends WrappedComponent {
render () {
return (
<div>
<h2>HOC Debugger Component</h2>
<p>Props</p>
{' '}
<pre>{JSON.stringify (this.props, null, 2)}</pre>
{' '}
<p>State</p>
<pre>{JSON.stringify (this.state, null, 2)}</pre>
{' '}
{super.render ()}
</div>
);
}
};
状态管理·第三方工具
上文提到了状态管理·组件状态,接下来我们来看看社区主流的状态管理工具。
Redux
理解 Redux
要理解 Redux,首先要明白我们为什么需要 Redux,或者说,Redux 适用于什么样的场景。
在真实应用中,React 组件树会很庞大很复杂,两个没有父子关系的 React 组件之间要共享信息,怎么办呢?
最直观的做法,就是将状态保存在一个全局对象中,这个对象,叫 store。
如果 store 是一个普通对象,谁都可以修改,那状态就乱套了。所以我们要做一些限制,让 store 只接受特定事件,如果要修改 store 的数据,就往 store 发送这些事件, store 对事件进行响应,从而修改状态。
这里说的事件,就是 action ,而对应修改状态的函数,就是reducer。
Redux 的主要贡献,就是限制了对状态的修改方式,让所有改变都可以被追踪。
适合 Redux 的场景
对于某个状态,到底是放在 Redux 的 Store 中呢,还是放在 React 组件自身的状态中呢?
针对这个问题,有以下原则:
第一步,看这个状态是否会被多个 React 组件共享。
第二步,看这个组件被 unmount 之后重新被 mount,之前的状态是否需要保留。
第三步,到这一步,基本上可以确定,这个状态可以放在 React 组件中了。
Redux 和 React 结合的最佳实践
一、Store 上的数据应该范式化。
所谓范式化,就是尽量减少冗余信息,像设计 MySQL 这样的关系型数据库一样设计数据结构。
二、使用 selector。
对于 React 组件,需要的是『反范式化』的数据,当从 Store 上读取数据得到的是范式化的数据时,需要通过计算来得到反范式化的数据。你可能会因此担心出现问题,这种担心不是没有道理,毕竟,如果每次渲染都要重复计算,这种浪费积少成多可能真会产生性能影响,所以,我们需要使用 seletor。业界应用最广的 selector 就是 reslector 。
reselector 的好处,是把反范式化分为两个步骤,第一个步骤是简单映射,第二个步骤是真正的重量级运算,如果第一个步骤发现产生的结果和上一次调用一样,那么第二个步骤也不用计算了,可以直接复用缓存的上次计算结果。
绝大部分实际场景中,总是只有少部分数据会频繁发生变化,所以 reselector 可以避免大量重复计算。
三、只 connect 关键点的 React 组件
当 Store 上状态发生改变的时候,所有 connect 上这个 Store 的 React 组件会被通知:『状态改变了!』
然后,这些组件会进行计算。connect 的实现方式包含 shouldComponentUpdate 的实现,可以阻挡住大部分不必要的重新渲染,但是,毕竟处理通知也需要消耗 CPU,所以,尽量让关键的 React 组件 connect 到 store 就行。
一个实际的例子就是,一个列表种可能包含几百个项,让每一个项都去 connect 到 Store 上不是一个明智的设计,最好是只让列表去 connect,然后把数据通过 props 传递给各个项。
如何实现异步操作
使用 Redux 对于同步状态更新非常顺手,但是,遇到需要异步更新状态的场景,例如调用 AJAX 从服务器获得数据,这时候单用 Redux 就不够了,需要其他方式来辅助。
至今为止,还无法推荐一个杀手级的方法,各种方法都在吹嘘自己多厉害,但是任何一种方法都是易用性和复杂性的平衡。
最简单的 redux-thunk,代码量少,只有几行,用起来也很直观,但是开发者要写很多代码;而比较复杂的 redux-observable 相当强大,可以只用少量代码就实现复杂功能,但是前提是你要学会 RxJS,RxJS 本身学习曲线很陡,内容需要 一本书 的篇幅来介绍,这就是代价。
读者在自己的项目中,无论选择什么方式,一定要考虑这个方式的复杂度和学习成本。
在这里我不想过多介绍任何一种 Redux 扩展,因为任何一种都比不上 React 将要支持的 Suspense,Suspense 才是 React 中做异步操作的未来,在第 19 小节会详细介绍 Suspense。
Mobx
理解 Mobx
我们用 Mobx 来实现一个很简单的计数工具,首先,需要有一个对象来记录计数值,代码如下:
import {observable} from 'mobx';
const counter = observable ({
count: 0,
});
在上面的代码中,counter 是一个对象,其实就是用 observable 函数包住一个普通 JS 对象,但是 observable 的介入,让 counter 对象拥有了神力。
我们用最简单的代码来展示这种“神力”,代码如下:
import {autorun} from 'mobx';
window.counter = counter;
autorun (() => {
console.log ('#count', counter.count);
});
把 counter 赋值给 window.counter,是为了让我们在 Chrome 的开发者界面可以访问。用 autorun 包住了一个函数,这个函数输出 counter.count 的值,这段代码的作用,我们很快就能看到。
在 Chrome 的开发者界面,我们可以直接访问 window.counter.count,神奇之处是,如果我们直接修改 window.counter.count 的值,可以直接触发 autorun 的函数参数!
这个现象说明,mobx 的 observable 拥有某种“神力”,任何对这个对象的修改,都会立刻引发某些函数被调用。和 observable 这个名字一样,被包装的对象变成了“被观察者”,而被调用的函数就是“观察者”,在上面的例子中,autorun 的函数参数就是“观察者”。
Mobx 这样的功能,等于实现了设计模式中的“观察者模式”(Observer Pattern),通过建立 observer 和 observable 之间的关联,达到数据联动。不过,传统的“观察者模式”要求我们写代码建立两者的关联,也就是写类似下面的代码:
observable.register(observer);
Mobx 最了不起之处,在于不需要开发者写上面的关联代码,Mobx自己通过解析代码就能够自动发现 observer 和 observable 之间的关系。
我们很自然想到,如果让我们的数据拥有这样的“神力”,那我们就不用在修改完数据之后,再费心去调用某些函数使用这些数据了,数据管理会变得十分轻松。
用 decorator 来使用 Mobx
Mobx 和 React 并无直接关系,为了建立二者的关系,需要安装 mobx-react
还是以 Counter 为例,看如何用 decorator 使用 Mobx,我们先看代码:
import {observable} from 'mobx';
import {observer} from 'mobx-react';
@observer
class Counter extends React.Component {
@observable count = 0;
onIncrement = () => {
this.count++;
};
onDecrement = () => {
this.count--;
};
componentWillUpdate () {
console.log ('#enter componentWillUpdate');
}
render () {
return (
<CounterView
caption="With decorator"
count={this.count}
onIncrement={this.onIncrement}
onDecrement={this.onDecrement}
/>
);
}
}
在上面的代码中,Counter 这个 React 组件自身是一个 observer,而 observable 是 Counter 的一个成员变量 count。
注意 observer 这 个decorator 来自于 mobx-react,它是 Mobx 世界和 React 的桥梁,被它“装饰”的组件,就是一个“观察者”。
本例中,成员变量 count 是被观察者,只要被观察者一变化,作为观察者的 Counter 组件就会重新渲染。
独立的 Store
真实的业务场景是一个状态需要多个组件共享,所以 observable 一般是在 React 组件之外。
我们重写一遍 Counter 组件,代码如下:
const store = observable ({
count: 0,
});
store.increment = function () {
this.count++;
};
store.decrement = function () {
this.count--;
}; // this decorator is must
@observer
class Counter extends React.Component {
onIncrement = () => {
store.increment ();
};
onDecrement = () => {
store.decrement ();
};
render () {
return (
<CounterView
caption="With external state"
count={store.count}
onIncrement={this.onIncrement}
onDecrement={this.onDecrement}
/>
);
}
}
Mobx 和 Redux 的比较
Mobx 和 Redux 的目标都是管理好应用状态,但是最根本的区别在于对数据的处理方式不同。
Redux 认为,数据的一致性很重要,为了保持数据的一致性,要求Store 中的数据尽量范式化,也就是减少一切不必要的冗余,为了限制对数据的修改,要求 Store 中数据是不可改的(Immutable),只能通过 action 触发 reducer 来更新 Store。
Mobx 也认为数据的一致性很重要,但是它认为解决问题的根本方法不是让数据范式化,而是不要给机会让数据变得不一致。所以,Mobx 鼓励数据干脆就“反范式化”,有冗余没问题,只要所有数据之间保持联动,改了一处,对应依赖这处的数据自动更新,那就不会发生数据不一致的问题。
值得一提的是,虽然 Mobx 最初的一个卖点就是直接修改数据,但是实践中大家还是发现这样无组织无纪律不好,所以后来 Mobx 还是提供了 action 的概念。和 Redux 的 action 有点不同,Mobx 中的 action 其实就是一个函数,不需要做 dispatch,调用就修改对应数据
如果想强制要求使用 action,禁止直接修改 observable 数据,使用 Mobx 的 configure,如下:
import {configure} from 'mobx';
configure({enforceActions: true});
总结一下 Redux 和 Mobx 的区别,包括这些方面:
- Redux 鼓励一个应用只用一个 Store,Mobx 鼓励使用多个 Store;
- Redux 使用“拉”的方式使用数据,这一点和 React是一致的,但 Mobx 使用“推”的方式使用数据,和 RxJS 这样的工具走得更近;
- Redux 鼓励数据范式化,减少冗余,Mobx 容许数据冗余,但同样能保持数据一致。
样式处理
基本样式设置
我们可以使用 classnames 库来操作类。
// 如果不使用 classnames 库,就需要这样处理动态类名:
import React, {Component} from 'react';
class Button extends Component {
render () {
let btnClass = 'btn';
if (this.state.isPressed) {
btnClass += ' btn-pressed';
} else if (this.state.isHovered) {
btnClass += ' btn-over';
}
return <button className={btnClass}>{this.props.label}</button>;
}
}
// 使用了 classnames 库代码后,就可以变得很简单:
import React, { Component } from 'react';
import classNames from 'classnames';
class Button1 extends Component {
// ...
render () {
const btnClass = classNames ({
btn: true,
'btn-pressed': this.state.isPressed,
'btn-over': !this.state.isPressed && this.state.isHovered,
});
return <button className={btnClass}>{this.props.label}</button>;
}
}
CSS模块
CSS 模块化要解决两个问题:CSS 样式的导入与导出。灵活按需导入以便复用代码,导出时要能够隐藏内部作用域,以免造成全局污染。
CSS 模块化解决方案有两种:Inline Style、CSS Modules。
Inline Style
这种方案彻底抛弃 CSS,使用 JS 或 JSON 来写样式,能给 CSS 提供 JS 同样强大的模块化能力。但缺点同样明显,Inline Style 几乎不能利用 CSS 本身 的特性,比如级联、媒体查询(media query)等,:hover 和 :active 等伪类处理起来比较 复杂。另外,这种方案需要依赖框架实现,其中与 React 相关的有 Radium、jsxstyle 和 react-style。
CSS Modules
依旧使用 CSS,但使用 JS 来管理样式依赖。CSS Modules 能最大化地结合现有 CSS 生态和 JS 模块化能力,其 API 非常简洁,学习成本几乎为零。 发布时依旧编译出单独的 JS 和 CSS 文件。webpack css-loader 内置 CSS Modules 功能。
CSS Modules 注意事项
样式默认局部
使用了 CSS Modules 后,就相当于给每个 class 名外加了 :local,以此来实现样式的局部化。如果我们想切换到全局模式,可以使用 :global 包裹
使用 composes 来组合样式
/* components/Button.css */
.base { /* 所有通用的样式 */ }
.normal {
composes: base;
/* normal其他样式 */
}
.disabled {
composes:base;
/* disabled 其他样式 */
}
生成的 HTML 变为:
<button class="button--base-abc53 button--normal-abc53"> Processing... </button>
由于在 .normal 中组合了 .base,所以编译后的 normal 会变成两个 class。 此外,使用 composes 还可以组合外部文件中的样式:
/* settings.css */
.primary-color {
color: #f40;
}
/* components/Button.css */
.base { /* 所有通用的样式 */ }
.primary {
composes: base;
composes: $primary-color from './settings.css'; /* primary 其他样式 */
}
实现 CSS 与 JS 变量共享
:export 关键字可以把 CSS 中的变量输出到 JS 中
/* config.scss */
$primary-color: '#f40';
:export {
primaryColor: $primary-color;
}
/* app.js */
import style from 'config.scss';
// 会输出 #F40 console.log(style.primaryColor);
React Router
随着 AJAX 技术的成熟,现在单页应用(Single Page Application)已经是前端网页界的标配,名为“单页”,其实在设计概念上依然是多页的界面,只不过从技术层面上页之间的切换是没有整体网页刷新的,只需要做局部更新。
要实现“单页应用”,一个最要紧的问题就是做好“路由”(Routing),也就是处理好下面两件事:
- 把 URL 映射到对应的页面来处理;
- 页面之间切换做到只需局部更新。
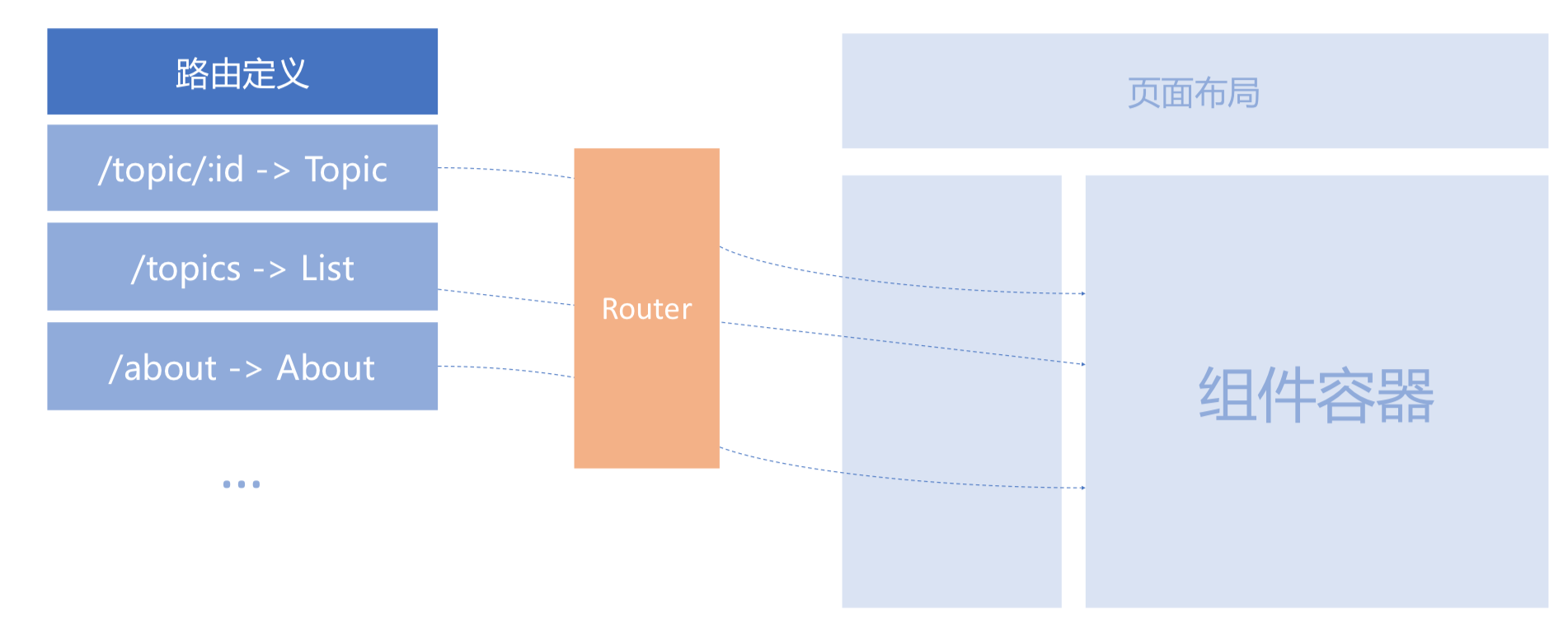
react router v4 的动态路由
react-router 的 v3 和 v4 版完完全全是不同的两个工具,最大的区别是 v3 为静态路由, v4 做到了动态路由。
所谓“静态路由”,就是说路由规则是固定的。
所谓动态路由,指的是路由规则不是预先确定的,而是在渲染过程中确定的。
使用
react-router 的工作方式,是在组件树顶层放一个 Router 组件,然后在组件树中散落着很多 Route 组件(注意比 Router 少一个“r”),顶层的 Router 组件负责分析监听 URL 的变化,在它保护伞之下的 Route 组件可以直接读取这些信息。
很明显,Router 和 Route 的配合,就是之前我们介绍过的“提供者模式”,Router 是“提供者”,Route是“消费者”。
更进一步,Router 其实也是一层抽象,让下面的 Route 无需各种不同 URL 设计的细节,不要以为 URL 就一种设计方法,至少可以分为两种。
第一种很自然,比如 / 对应 Home 页,/about 对应 About 页,但是这样的设计需要服务器端渲染,因为用户可能直接访问任何一个 URL,服务器端必须能对 /的访问返回 HTML,也要对 /about 的访问返回 HTML。
第二种看起来不自然,但是实现更简单。只有一个路径 /,通过 URL 后面的 # 部分来决定路由,/#/ 对应 Home 页,/#/about 对应 About 页。因为 URL 中#之后的部分是不会发送给服务器的,所以,无论哪个 URL,最后都是访问服务器的 / 路径,服务器也只需要返回同样一份 HTML 就可以,然后由浏览器端解析 # 后的部分,完成浏览器端渲染。
在 react-router,有 BrowserRouter 支持第一种 URL,有 HashRouter 支持第二种 URL。
动态路由
假设,我们增加一个新的页面叫 Product,对应路径为 /product,但是只有用户登录了之后才显示。如果用静态路由,我们在渲染之前就确定这条路由规则,这样即使用户没有登录,也可以访问 product,我们还不得不在 Product 组件中做用户是否登录的检查。
如果用动态路由,则只需要在代码中的一处涉及这个逻辑:
<Switch>
<Route exact path='/' component={Home}/>
{
isUserLogin() &&
<Route exact path='/product' component={Product}/>,
}
<Route path='/about' component={About}/>
</Switch>
常见API
<Link>:普通链接,不会触发浏览器刷新<NavLink>:类似<Link>但是会添加当前选中状态<Prompt>:满足条件时提示用户是否离开当前页面<Redirect>:重定向当前页面,例如登录判断<Route>:路由配置的核心标记,路径匹配时显示对应组件<Switch>:只现实第一个匹配路由
React Router技巧
- 如何通过URL传递参数:
- 如何获取参数:this.props.match.params
- 路由匹配进阶资料
服务器端渲染
最近几年浏览器端框架很繁荣,以至于很多新入行的开发者只知道浏览器端渲染框架,都不知道存在服务器端渲染这回事,其实,网站应用最初全都是服务器端渲染,由服务器端用 PHP、Java 或者 Python 等其他语言产生 HTML 来给浏览器端解析。
相比于浏览器端渲染,服务器端渲染的好处是:
- 缩短首屏渲染时间
- 更好的搜索引擎优化
大体流程
React v16 之前的版本,代码是这样:
import React from 'react';
import ReactDOMServer from 'react-dom/server';
// 把产生html返回给浏览器端
const html = ReactDOMServer.renderToString(<Hello />);
从 React v16 开始,上面的服务器端代码依然可以使用,但是也可以把 renderToString 替换为 renderToNodeStream,代码如下:
import React from 'react';
import ReactDOMServer from 'react-dom/server';
// 把渲染内容以流的形式塞给response
ReactDOMServer.renderToNodeStream(<Hello />).pipe(response);
此外,浏览器端代码也有一点变化,ReactDOM.render 依然可以使用,但是官方建议替换为 ReactDOM.hydrate,原来的 ReactDOM.render 将来会被废弃掉。
renderToString 的功能是一口气同步产生最终 HTML,如果 React 组件树很庞大,这样一个同步过程可能比较耗时。
renderToNodeStream 把渲染结果以“流”的形式塞给 response 对象,这意味着不用等到所有 HTML 都渲染出来了才给浏览器端返回结果,“流”的作用就是有多少内容给多少内容,这样可以改进首屏渲染时间。
“脱水”和“注水”
React 有一个特点,就是把内容展示和动态功能集中在一个组件中。比如,一个 Counter 组件既负责怎么画出内容,也要负责怎么响应按键点击,这当然符合软件高内聚性的原则,但是也给服务器端渲染带来更多的工作。
设想一下,如果只使用服务器端渲染,那么产生的只有 HTML,虽然能够让浏览器端画出内容,但是,没有 JS 的辅助是无法响应用户交互事件的。
如何让页面响应用户事件?其实我们已经做过这件事了,Counter 组件里面已经有对按钮事件的处理,我们所要做的只是让 Counter 组件在浏览器端重新执行一遍,也就是 mount 一遍就可以了。
也就是说,如果想要动态交互效果,使用 React 服务器端渲染,必须也配合使用浏览器端渲染。
现在问题变得更加有趣了,在服务器端我们给 Counter 一个初始值(这个值可以不是缺省的 0),让 Counter 渲染产生 HTML,这些 HTML 要传递给浏览器端,为了让 Counter 的 HTML“活”起来点击相应事件,必须要在浏览器端重新渲染一遍 Counter 组件。在浏览器端渲染 Counter 之前,用户就可以看见 Counter 组件的内容,但是无法点击交互,要想点击交互,就必须要等到浏览器端也渲染一次 Counter 之后。
接下来的一个问题,如果服务器端塞给 Counter 的数据和浏览器端塞给 Counter 的数据不一样呢?
在 React v16 之前,React 在浏览器端渲染之后,会把内容和服务器端给的 HTML 做一个比对。如果完全一样,那最好,接着用服务器端 HTML 就好了;如果有一丁点不一样,就会立刻丢掉服务器端的 HTML,重新渲染浏览器端产生的内容,结果就是用户可以看到界面闪烁。因为 React 抛弃的是整个服务器端渲染内容,组件树越大,这个闪烁效果越明显。
React 在 v16 之后,做了一些改进,不再要求整个组件树两端渲染结果分毫不差,但是如果发生不一致,依然会抛弃局部服务器端渲染结果。
总之,如果用服务器端渲染,一定要让服务器端塞给 React 组件的数据和浏览器端一致。
为了达到这一目的,必须把传给 React 组件的数据给保留住,随着 HTML 一起传递给浏览器网页,这个过程,叫做“脱水”(Dehydrate);在浏览器端,就直接拿这个“脱水”数据来初始化 React 组件,这个过程叫“注水”(Hydrate)。
前面提到过 React v16 之后用 React.hydrate 替换 React.render,这个 hydrate 就是“注水”。
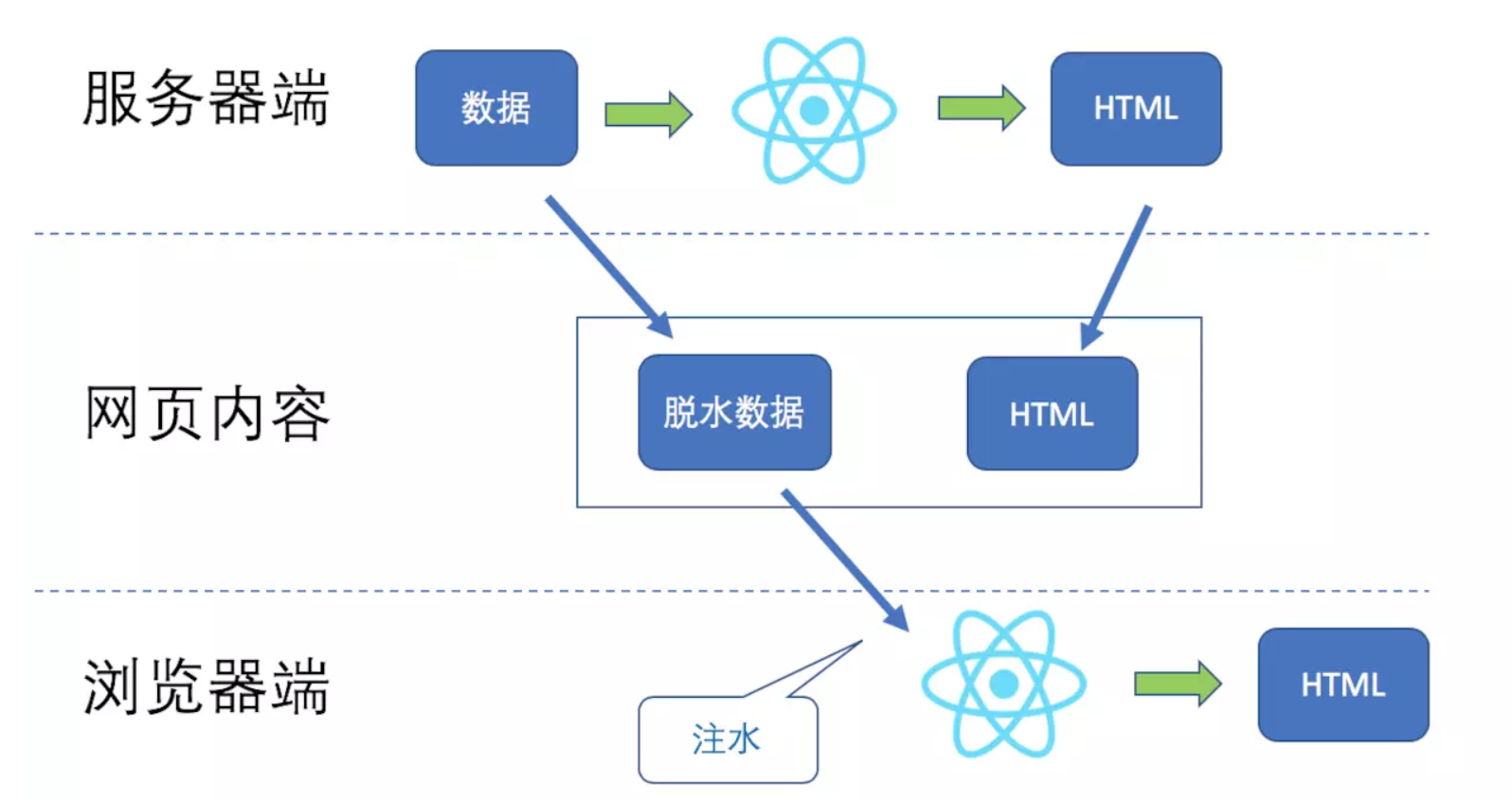
总之,为了实现React的服务器端渲染,必须要处理好这两个问题:
- 脱水
- 注水
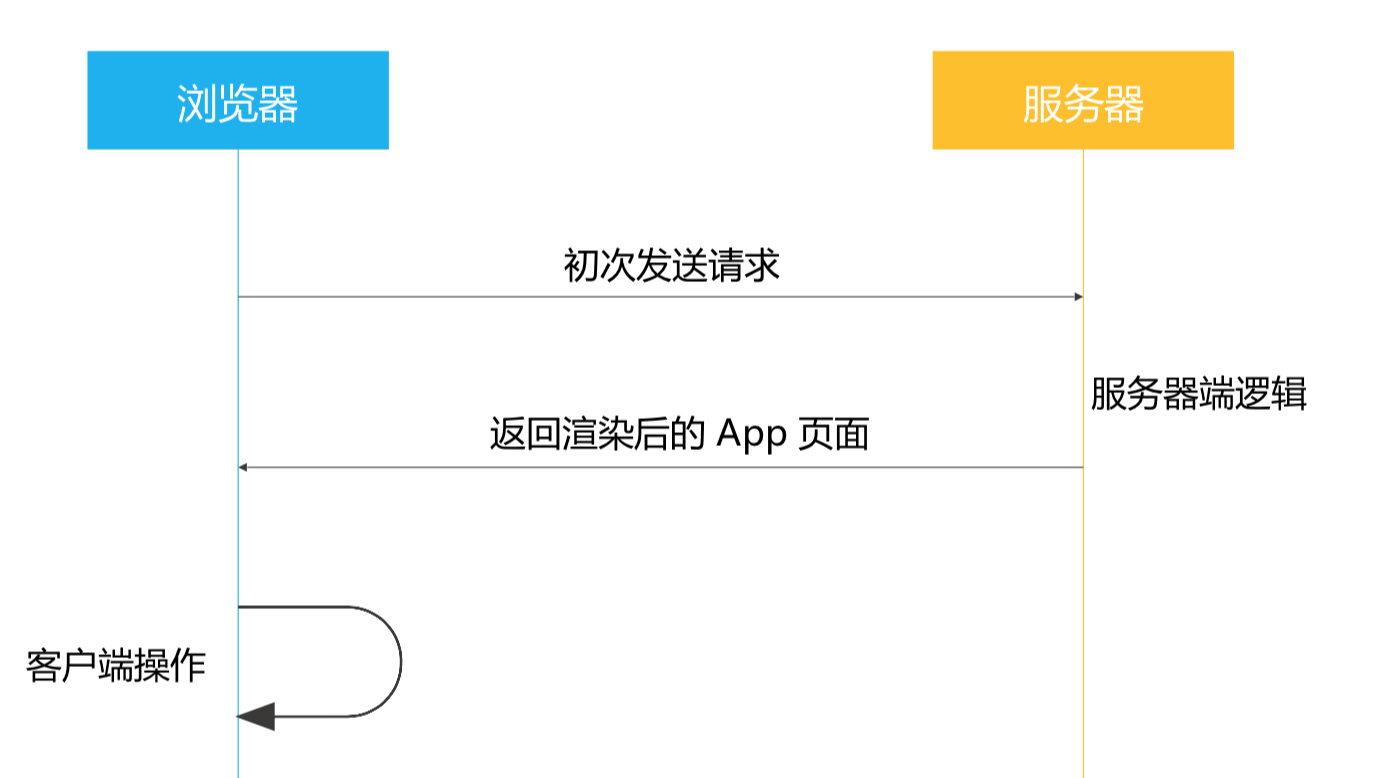
同构应用
有很多文章都提到同构应用,其实就是首屏使用服务端渲染,后面使用浏览器端渲染的应用。
使用 Next.js 实现服务端渲染
上文提到服务器端渲染,不过,服务器端渲染的问题并不这么简单,一个最直接的问题,就是怎么处理多个页面的『单页应用』?
所谓单页应用,就是虽然用户感觉有多个页面,但是实现上只有一个页面,用户感觉到页面可以来回切换,但其实只是一个页面并没有完全刷新,只是局部界面更新而已。
假设一个单页应用有三个页面 Home、Prodcut 和 About,分别对应的的路径是 /home、/product 和 /about,而且三个页面都依赖于 API 调用来获取外部数据。
现在我们要做服务器端渲染,如果只考虑用户直接在地址栏输入 /home、/product 和 /about 的场景,很容易满足,按照上面说的套路做就是了。但是,这是一个单页应用,用户可以在 Home 页面点击链接无缝切换到 Product,这时候 Product 要做完全的浏览器端渲染。换句话说,每个页面都需要既支持服务器端渲染,又支持完全的浏览器端渲染,更重要的是,对于开发者来说,肯定不希望为了这个页面实现两套程序,所以必须有同时满足服务器端渲染和浏览器端渲染的代码表示方式。
getInitialProps
我们通过一个简单的例子来讲解Next.js中最重要的概念getInitialProps。
import React from 'react';
const timeout = (ms, result) => {
return new Promise (resolve => setTimeout (() => resolve (result), ms));
};
const Home = props => (
<h1>
Hello {props.userName}
</h1>
);
Home.getInitialProps = async () => {
return await timeout (200, {userName: 'Morgan'});
};
export default Home;
这里模拟了一个延时操作用以获取userName,并将其展示在页面上。
这段代码的关键在于getInitialProps。
这个 getiInitialProps 是 Next.js 最伟大的发明,它确定了一个规范,一个页面组件只要把访问 API 外部资源的代码放在 getInitialProps 中就足够,其余的不用管,Next.js 自然会在服务器端或者浏览器端调用 getInitialProps 来获取外部资源,并把外部资源以 props 的方式传递给页面组件。
注意 getInitialProps 是页面组件的静态成员函数,也可以在组件类中加上 static 关键字定义。
class Home extends React.Component {
static async getInitialProps () {}
}
我们可以这样来看待 getInitialProps,它就是 Next.js 对代表页面的 React 组件生命周期的扩充。React 组件的生命周期函数缺乏对异步操作的支持,所以 Next.js 干脆定义出一个新的生命周期函数 getInitialProps,在调用 React 原生的所有生命周期函数之前,Next.js 会调用 getInitialProps 来获取数据,然后把获得数据作为 props 来启动 React 组件的原生生命周期过程。
这个生命周期函数的扩充十分巧妙,因为:
- 没有侵入 React 原生生命周期函数,以前的 React 组件该怎么写还是怎么写;
- getInitialProps 只负责获取数据的过程,开发者不用操心什么时候调用 getInitialProps,依然是 React 哲学的声明式编程方式;
- getInitialProps 是 async 函数,可以利用 JS 语言的新特性,用同步的方式实现异步功能。
Next.js 的“脱水”和“注水”
我们打开Next应用的网页源代码,可以看到类似下面的内容:
<script>
__NEXT_DATA__ = {
"props":{
"pageProps": {"userName":"Morgan"}},
"page":"/","pathname":"/","query":{},"buildId":"-","assetPrefix":"","nextExport":false,"err":null,"chunks":[]}
</script>
Next.js 在做服务器端渲染的时候,页面对应的 React 组件的 getInitialProps 函数被调用,异步结果就是“脱水”数据的重要部分,除了传给页面 React 组件完成渲染,还放在内嵌 script 的 NEXT_DATA 中,这样,在浏览器端渲染的时候,是不会去调用 getInitialProps 的,直接通过 NEXT_DATA 中的“脱水”数据来启动页面 React 组件的渲染。
这样一来,如果 getInitialProps 中有调用 API 的异步操作,只在服务器端做一次,浏览器端就不用做了。
那么,getInitialProps 什么时候会在浏览器端调用呢?
当在单页应用中做页面切换的时候,比如从 Home 页切换到 Product 页,这时候完全和服务器端没关系,只能靠浏览器端自己了,Product页面的 getInitialProps 函数就会在浏览器端被调用,得到的数据用来开启页面的 React 原生生命周期过程。
关键点是,浏览器可能会直接访问 /home 或者 /product,也可能通过网页切换访问这两个页面,也就是说 Home 或者 Product 都可能被服务器端渲染,也可能完全只有浏览器端渲染,不过,这对应用开发者来说无所谓,应用开发者只要写好 getInitialProps,至于调用 getInitialProps 的时机,交给 Next.js 处理就好了。
服务端渲染小结
react 提供了renderToString、renderToNodeStream、hydrate等API支持服务端渲染,但Facebook官方并没有使用react的服务端渲染,导致react服务端渲染没有一个官方标准。
服务端渲染的思路并不难,就是在服务端渲染出HTML传给浏览器去解析。
难就难在,服务端渲染的数据从何而来。如果服务端渲染的数据和浏览器端渲染的数据不一致,浏览器端会重新执行渲染,页面会出现闪烁。
为什么有了服务端渲染,还需要关注浏览器端渲染呢?
这是因为服务端渲染只是返回了HTML,页面能绘制出来,却没办法响应用户操作,所以必须重新进行浏览器端渲染,让页面可以正常响应用户操作。当浏览器端渲染出的HTML跟服务端返回的HTML不一致时,就会出现上面说的闪烁。
要解决这个问题,就引入了“注水”跟“脱水”的概念。
服务端渲染时,获取的数据,一方面用于生成最终的HTML,另一方面,也会包含在HTML中返回给浏览器端,这个过程称为“脱水”。
浏览器端拿到脱水的数据进行渲染,就保证了渲染出的HTML跟服务端返回的一致,这个过程就是“注水”,涉及的API就是hydrate。
原理搞明白了,如何实施呢?如果我们做的是单页应用,那问题更加麻烦。因为用户可以通过不同的URL返回页面,这意味着我们每个页面都要既支持服务端渲染,也支持浏览器端渲染,但我们肯定不希望为每个页面写两份代码!
这就轮到 Next.js 登场了。
Next.js 是目前解决服务端渲染最好的框架。他通过增加 getInitialProps 这个API优雅的解决了上述的问题。
Next.js 将服务端渲染脱水后的数据,通过 NEXT_DATA 返回给浏览器端,首屏加载可以使用该数据进行渲染,就保证前后数据一致,页面不会闪烁。
浏览器可能会直接访问 /home 或者 /product,也可能通过网页切换访问这两个页面,也就是说 Home 或者 Product 都可能被服务器端渲染,也可能完全只有浏览器端渲染,不过,这对应用开发者来说无所谓,应用开发者只要写好 getInitialProps,至于调用 getInitialProps 的时机,交给 Next.js 处理就好了。
常用开发调试工具
开发react应用最常用的调试工具有:ESLint,Prettier,React DevTool,Redux DevTool
ESLint
- 使用.eslintrc进行规则的配置
- 使用airbnb的JS代码风格
Prettier
- 代码格式化的神器
- 保证更容易写出风格一致的代码
小技巧:在Chrome中监测react性能:在URL后加?react_perf,比如:localhost:3000/?react_perf
组件测试
React 让前端单元测试变得容易:
- React 应用很少需要访问浏览器API
- 虚拟DOM可以在nodejs环境运行和测试
- Redux隔离了状态管理,纯数据层单元测试
React 组件的单元测试,只有三个要点:
- 用 Jest;
- 用 Enzyme;
- 保持 100% 的代码覆盖率。
Jest
“测试驱动”难以开展,主要有几个原因:
- 单元测试用例庞大,执行时间过长。
- 单元测试用例之间相互影响。
Jest 较好地解决了上面说的问题,因为 Jest 最重要的一个特性,就是支持并行执行。
Jest 为每一个单元测试文件创造一个独立的运行环境,换句话说,Jest 会启动一个进程执行一个单元测试文件,运行结束之后,就把这个执行进程废弃了,这个单元测试文件即使写得比较差,把全局变量污染得一团糟,也不会影响其他单元测试文件,因为其他单元测试文件是用另一个进程来执行。
更妙的是,因为每个单元测试文件之间再无纠葛,Jest 可以启动多个进程同时运行不同的文件,这样就充分利用了电脑的多 CPU 多核,单进程 100 秒才完成的测试执行过程,8 核只需要 12.5 秒,速度快了很多。
使用 create-react-app 产生的项目自带 Jest 作为测试框架,不奇怪,因为 Jest 和 React 一样都是出自 Facebook。
jest中文教程
Enzyme
Enzyme 是最受欢迎的 React 测试工具库。
Enzyme 的官网地址
代码覆盖率
一个应用不光所有的单元测试都要通过,而且所有单元测试都必须覆盖到代码 100% 的角落。
如果对覆盖率的要求低于 100%,时间一长,质量必定会越来越下滑
在 create-react-app 创造的应用中,已经自带了代码覆盖率的支持,运行下面的命令,不光会运行所有单元测试,也会得到覆盖率汇报。
npm test -- --coverage 代码覆盖率包含四个方面:
- 语句覆盖率
- 逻辑分支覆盖率
- 函数覆盖率
- 代码行覆盖率
只有四个方面都是 100%,才算真的 100%。
市场应用趋势
随着技术生态的发展,和应用问题的变迁,技术的应用场景和流行趋势会受到影响。这层回答“谁用,用在哪”的问题,反映你对技术应用领域的认识宽度。
