

分类
1.同步映射
Hashtable
2.非同步映射
HashMap
3.jdk-并发包的同步map
ConcurrentHashMap
发展历史
1.早期
只有Hashtable。
2.jdk5
HashMap
3.jdk-并发包
ConcurrentHashMap
映射的底层数据结构
1.数组
索引不相同的数据value,写到数组。
2.链表
索引相同的数据value,写到同一个索引的链表——防止索引值相同的数据冲突。
如何得到数组的索引?
数组的索引只能是数字类型,所以需要经过以下流程:key:hash算法计算——hashcode:除以数组大小得到余数——数组索引,这么转换以下,就得到了数字类型的数组索引。
为什么一定要经过hash算法转换呢?别的算法转换不行吗?
也可以,但是如果别的算法太简单,会容易导致不同的字符串转换之后得到的值容易重复。所以才要使用hash算法尽量让不同的字符串经过hash算法转换之后得到的值不容易重复。
比如,下面的简单的转换算法: 把字符串按照某种算法转换为数字,比如,每个字母都有一个ASCII编码对应的数字。所以如果这个算法是基于ASCII编码 + 某种计算规则,就可以得到这个单词的数字,这个数字就可以作为数组的索引。
上面的算法有点简单,可能会带来一种问题,就是很多不同的单词计算之后得到的数字是一样的。怎么办?使用更复杂的算法。这种更复杂的算法就是哈希算法。作用就是为了解决字符串——》数字作为数组索引带来的索引值相同的问题。
具体就是让字符串——》数字的值更加分散,更加大。这样得到的值就不容易重复。
jdk是如何优化map的?
主要是jdk8对jdk7的优化。这里以map数据结构举例子,其他集合类差不多。
map
链表——》红黑树
并发map
1.锁
显式锁-分段锁——》CAS + 隐式锁(即synchronized)
2.链表
链表——》平衡树-红黑树
总结
1.map
主要是对链表的优化
2.并发map
链表的优化和map一样。
除此之外,还有锁的优化。
要理解jdk的发展历史,其实是有一些关键点可以被抓住的。抓住了这个关键点之后,会发现不管是map还是并发,它的优化其实一样的。至于不同的部分,比如并发map对锁的优化,和并发集合比,其优化的方向和实现原理也是一样的。
更多优化细节,以及为什么要这么优化,继续看下文。
HashMap
数据结构示意图
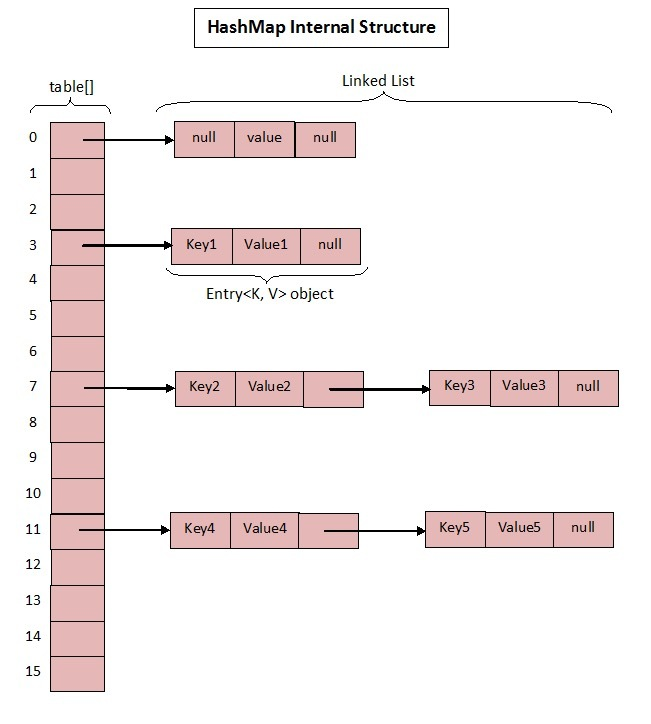
说明
主要关注两点,也就是围绕底层的两个数据结构来理解
1.数组
节点数组
2.链表
节点链表
//节点数组-jdk7
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
节点数据结构
包含三个字段
1.key
2.value
3.next指针
指向下一个节点
//节点的数据结构-jdk7
static class Entry<K,V> implements Map.Entry<K,V> {
final K key; //key
V value; //value
Entry<K,V> next; //指向下一个指针
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
HashMap源码实现-细节
为什么数组长度必须是2的n次方?
首先,我们看一下HashMap默认的数组长度是多少。
//jdk7-HashMap:默认数组长度是16,2的4次方
/**
* The default initial capacity - MUST be a power of two.
* 必须是2的次方(注意不是倍数,是次方)
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 //众所周知as known as,是16 //<<是按位与
那么为什么必须是2的n次方呢?
我们再来看一下,HashMap是如何计算索引的。
/**
* Returns index for hash code h.
计算数组索引
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; //数组长度必须是2的n次方
return h & (length-1); //因为这里是使用按位与&计算数组索引,而不是使用除法计算余数得到数组索引
}
我们看到,是使用按位与,而不是我们想象中的除法取余数。
按位与是如何计算数组索引的?
2的n次方,比如16就是1 0000,按位与的时候,需要先减1,减1之后的值是1111。key的hashcode值和数组大小-1的值(每个位数全部都是1,即1111),进行按位与计算,就可以得到数组索引。
总结
所以,现在总结如下,求余数有两种方法:
1.按位与&
2.除法求余数
那么为什么HashMap要使用按位与计算索引呢?很明显,按位与的方法速度更快。至于为什么更快,这里涉及计算机硬件的底层知识,我们只要知道cpu做按位与比除法求余数更快即可。
扩容
上面讲到,数组的默认大小是16,2的4次方。如果写数据的时候,发现数组大小不够,那么就会进行扩容。
详细看代码。//jdk7-HashMap
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*
* 添加节点到节点数组
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) { //如果数组元素数量比负载因子的值大,那么扩容 //负载因子的值12=负载因子(默认是0.75)*数组大小16
resize(2 * table.length); //每次翻倍扩容,确保扩容之后的大小仍然是2的次方
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* 扩容
*
* ---
* 核心思想是
* 1.复制数据
* 2.索引需要重新计算,即rehash
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity)); //复制数据
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* Transfers all entries from current table to newTable.
* 从旧数组复制数据到新数组
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) { //重新计算索引,即rehash
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e; //复制数据
e = next;
}
}
}
代码的注释,已经把流程说的非常清楚了。
最佳实践
因为扩容,要做两件事情
1.复制旧数组数据到新数组
2.重新计算索引,即rehash
所以,这是一件特别耗费资源的事情。定义数据的时候,最好一开始就要想清楚,需要多少数据,就创建多大的大小。具体做法就是在构造方法的时候,传入预估的数组大小。
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity //初始化大小, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
负载因子
负载因子主要是用于扩容,扩容的时机有两种
1.大小不够了,才扩容
可以把负载因子设置为1,这样负载因子就没有起作用。
2.提前扩容
比1小,比如默认值是0.75,那么就会提前扩容,比如数组元素的数量到了12就开始扩容。
jdk8的优化
先来看一下数据结构
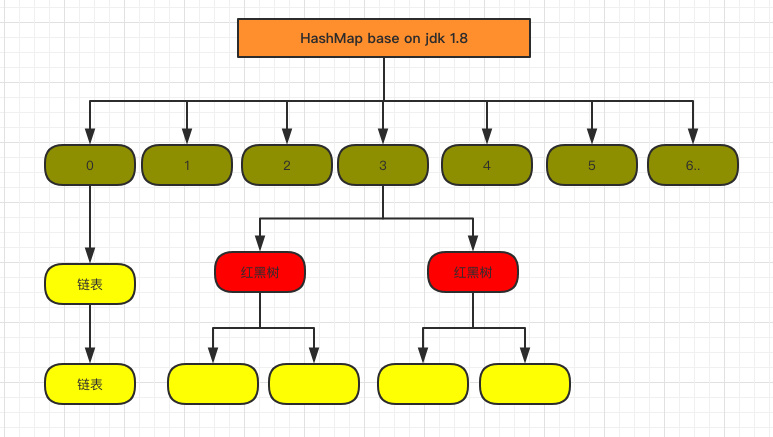
说明
jdk8优化的地方在于jdk7的缺点,jdk7的缺点是,对于相同的索引。插入数据的数据结构是链表。链表有个问题就是,如果大部分索引一样,那么所有的数据都跑到链表去了,所以jdk8要解决的问题就是,对于那种链表上的数据数量太多(具体数量可以看情况配置)的情况,就把链表数据结构转换为红黑树。
链表的速度是N,平衡二叉树的速度是logN。
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K, V>[] tab;
Node<K, V> p;
int n, i;
if ((tab = table) == null || (n = tab.length) == 0) {
n = (tab = resize()).length;
}
if ((p = tab[i = (n - 1) & hash]) == null) { //key和数组索引之间的关系?key:hash计算——hashcode:和数组大小,进行按位与计算——数组索引
tab[i] = newNode(hash, key, value, null); //数据不存在,就插入到数组
} else { //数据存在,就插入到链表
Node<K, V> e;
K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) {
e = p;
} else if (p instanceof TreeNode) {
e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);
} else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
/// treeify是插入时同时检查和执行的
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
{
treeifyBin(tab, hash); //如果当前链表的大小是否大于预设的阈值,大于时就要转换为红黑树。
}
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
break;
}
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) {
e.value = value;
}
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
/// 扩张也是同步判断和执行的,所以恰好触发时会比较慢
if (++size > threshold) {
resize();
}
afterNodeInsertion(evict);
return null;
}
ConcurrentHashMap-jdk7
数据结构示意图
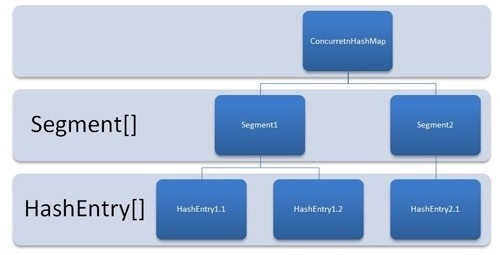
说明
底层的数据结构还是一样,就是数组+链表。但是,现在多了一个数组(就是示意图里的中间那一层),以前是节点数组,现在还有一个段数组,一个段就是一个节点数组。
为什么要这么设计?
因为现在上锁的数据范围是一个段的数据,而不是整个map的数据。在写一个段的数据的时候,对其他段的写可以同时进行,不影响。
//写数据
/**
* Maps the specified key to the specified value in this table.
* Neither the key nor the value can be null.
*
* <p> The value can be retrieved by calling the <tt>get</tt> method
* with a key that is equal to the original key.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>
* @throws NullPointerException if the specified key or value is null
*/
@SuppressWarnings("unchecked")
public V put(K key, V value) {
Segment<K,V> s; //定义段数据
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j); //段数组
return s.put(key, hash, value, false); //写数据到段
}
/**
* 写节点数据到节点数组(段)
* <pre>
* @author gzh
* @date 2019年6月26日 上午9:40:45
* @param key
* @param hash
* @param value
* @param onlyIfAbsent
* @return
* </pre>
*/
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value); //获取锁
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node); //写数据
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock(); //释放锁
}
return oldValue;
}
//读数据(不需要上锁,可以并发读,所以速度特别快)
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code key.equals(k)},
* then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* 读数据
* 不需要锁。因为写数据的时候,数据使用volatile修饰,读线程可以写线程修改之后的最新数据。
* @throws NullPointerException if the specified key is null
*/
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
/**
* ConcurrentHashMap list entry. Note that this is never exported
* out as a user-visible Map.Entry.
* 节点数据结构
*/
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value; //volatile修饰,确保读线程可以看见写线程修改之后的最新数据——这样,读方法就不需要使用锁,可以并发读!
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
段数组的大小?为什么是这个大小?
节点数组的大小,即每个段的大小?为什么是这个大小?
jdk8的优化
数据结构示意图
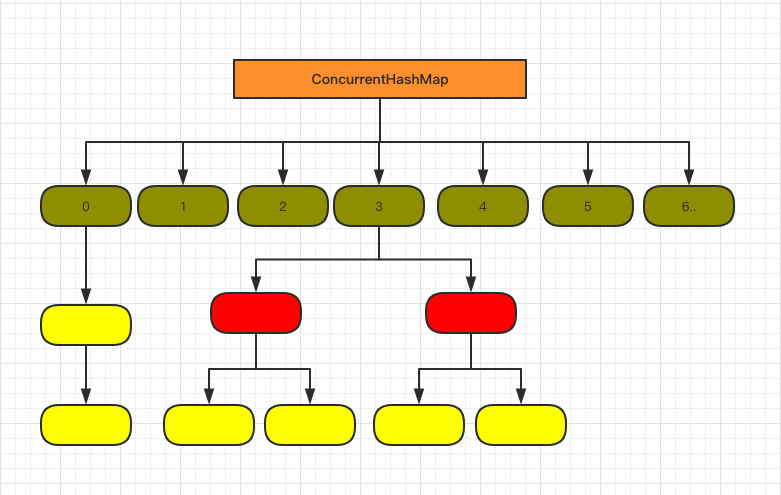
说明
1.数据结构
和HashMap一样,就是数组 + 链表。
2.锁
但是,锁这一块,改动比较大,直接放弃了分段锁,而是基于CAS或synchronized。
jdk8-没有使用分段锁,而是直接使用的synchronzied关键字,说明jdk8对synchronized进行了大量的优化。
/**
* Implementation for put and putIfAbsent
* 写数据
* 基于两种解决方案
* 1.基于CAS
* 2.不行的话,再基于synchronized
*
* 每次写数据,只有一种解决方案成功了。
*/
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) {
throw new NullPointerException();
}
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K, V>[] tab = table; ; ) {
Node<K, V> f; //节点数据
int n, i, fh;
if (tab == null || (n = tab.length) == 0) {
tab = initTable();
} else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K, V>(hash, key, value, null))) { //基于CAS
break; // no lock when adding to empty bin
}
} else if ((fh = f.hash) == MOVED) {
tab = helpTransfer(tab, f);
} else {
V oldVal = null;
synchronized (f) { //jdk8-没有使用分段锁,而是直接使用的synchronzied关键字,说明jdk8对synchronized进行了大量的优化
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K, V> e = f; ; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent) {
e.val = value;
}
break;
}
Node<K, V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K, V>(hash, key,
value, null);
break;
}
}
} else if (f instanceof TreeBin) {
Node<K, V> p;
binCount = 2;
if ((p = ((TreeBin<K, V>) f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent) {
p.val = value;
}
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD) {
treeifyBin(tab, i); //如果链表数据太多,那么链表转换为红黑树
}
if (oldVal != null) {
return oldVal;
}
break;
}
}
}
addCount(1L, binCount);
return null;
}
CAS
是什么?比较然后设置。
实现原理?AQS有个int类型的数据state,通过state(哪个线程持有锁,重入了几次锁) + 阻塞队列(线程排队)。
如何使用?提供AQS类封装了Unsafe.比较然后设置/交换方法(),所以使用的时候是调用AQS.比较然后设置方法()。
jdk8是基于CAS思想,和jdk7基于CAS思想是一样的。不过,具体的实现方式有点不一样:
1.jdk7
1)Segment继承了显式锁类
2)调用显式锁.AQS类的CAS()方法
//AQS类
/**
* Atomically sets synchronization state to the given updated
* value if the current state value equals the expected value.
* This operation has memory semantics of a <tt>volatile</tt> read
* and write.
*
* @param expect the expected value
* @param update the new value
* @return true if successful. False return indicates that the actual
* value was not equal to the expected value.
*/
protected final boolean compareAndSetState(int expect, int update) {
// See below for intrinsics setup to support this
return unsafe.compareAndSwapInt(this, stateOffset, expect, update); //最终都是调用Unsafe.比较然后设置()
}
2.jdk8
//ConcurrentHashMap
static final <K, V> boolean casTabAt(Node<K, V>[] tab, int i,
Node<K, V> c, Node<K, V> v) {
return U.compareAndSwapObject(tab, ((long) i << ASHIFT) + ABASE, c, v); //基于Unsafe.比较然后交换数据() //jdk8是在ConcurrentHashMap直接调用Unsafe.比较然后设置(),而没有通过显式锁类,所以和显式锁类没有什么关系。因为,jdk8是基于CAS + synchrosized,和显式锁类没有任何关系。虽然在CAS这一块,底层的思想/调用是一样的。
}
jdk8对synchronized的优化
1.可重入
同一个线程可以多次获取
2.自旋
获取多次
3.排队
就是普通的对象隐式锁
CAS
其实就是两种情况,比较原始值100和期待值100是否相等
1.如果相等
说明没有别的线程修改这个变量,那么当前线程就把原始值100改为新的值1000。//总共有3个值,1.原始值2.期待值3.新的值,即要更新的值——即就是所谓的比较然后设置/交换,这个是cpu指令支持的,所以是原子的。//有3个值的意思是,CAS的方法输入参数包含了三个值,哪三个值?就是前面提到的三个值。理解了方法的输入参数这三个值,就明白了CAS原理。
2.如果不等
说明有别的线程修改这个变量,那么当前线程自旋锁循环获取锁,直到获取到锁,执行CAS。
速度
1.查找
1。因为映射的底层数据结构是基于数组,所以速度是1。
2.插入和删除
N/2,所以是N。因为需要遍历数据。
哈希函数
什么是哈希函数?
1.输入
任意长度的数据
2.输出
固定长度的数据。比如,MD5 100多位;SHA-2 200多位。位数越多,越安全,因为越不容易重复。
总结 本质上是一个算法,按固定的算术规则计算得到的值。
从数学的角度看,就是一个函数。函数也是输入和输出。
MD5
SHA-2
RSA也是
只不过有秘钥。
什么是映射?
1.就是键值对
2.映射=数组(数据结构) + 哈希函数(算法)
1)写数据
输入:键
输出:哈希值 //作用:作为数组的索引
算法:哈希函数
2)读数据
输入:键
输出:固定值
最终输出:键值对的值
算法:哈希函数
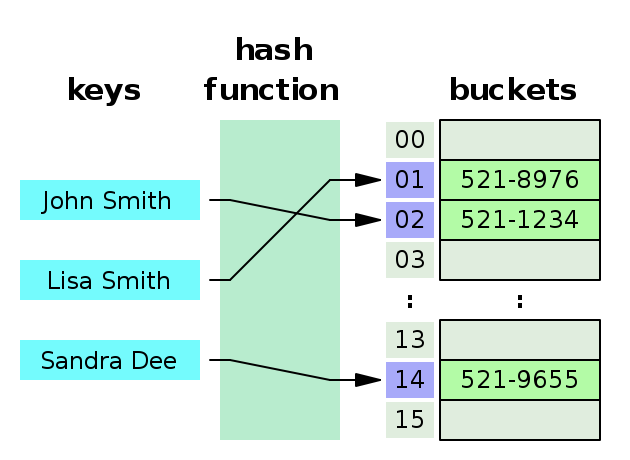
Hashtable

Hashtable与HashMap的区别?
底层原理和底层实现?
HashMap是对Hashtable的完善?具体是完善了什么东西?
底层原理差不多,主要是细节,包括算法细节的完善。
Hashtable与 字典类Dictionary和属性类Properties的区别?
1)HashMap实现了Map接口,Hashtable继承了抽象类Dictionary 旧版本jdk:Hashtable以及实现的接口都是旧版本jdk1.0。 新版本jdk:HashMap以及实现的接口都是新版本jdk2.0。
2)读取配置文件 旧版本jdk:Properties类也是旧版本jdk1.0,继承了HashMap,作用是专门用于从配置文件读取键值对。 新版本jdk:HashMap没有专门用于从配置文件读取键值对的子类。但是开源项目common configuration封装了HashMap,提供了读取配置文件的功能。
总结
1.hash哈希/hash table 哈希表
2.散列/散列表
3.字典dictionary
4.关联数组associated array
5.map映射
以上所有叫法都是映射,什么是映射?就是键值对。
映射函数(即哈希函数)又是干什么的?有什么作用?
映射 = 数组(数据结构) + 映射函数(算法)
哈希表
separate chaining and open addressing.
1.直接定址法?
2.数字分析法?
平衡二叉树(红黑树)?
是否同步
1.HashMap 不同步。
2.ConcurrentHashMap 与HashMap的唯一区别就是同步。
注:Hashtable也是同步的,但是已被弃用!
3.Collections.同步Map(); 与并发HashMap的区别? 并发HashMap,是使用同步关键字synchronized同步方法。//Hashtable的同步也是同步方法。
Collections.同步Map(); 是使用使用同步关键字同步对象和同步代码块。//其他的Collections.同步集合数据类型/映射数据类型(); 也是同理。
是否插入有序LinkedHashMap
与HashMap的唯一区别就是确保插入顺序。
实现原理也是双链表。
是否数据有序TreeMap
与HashMap的唯一区别是,数据有序。
List、Set、Map的区别?
1.List
是先插入数据到集合,然后想排序的时候再给数据排序。
步骤
1)插入数据
2)排序数据
怎么排序?使用各种算法书籍里都有介绍的排序算法。
排序算法是怎么排序的?本质是比较数据和交换数据,但是研究排序算法的目的是为了更快的排序,所以排序算法本质上是在研究如何更快的比较数据和交换数据。
2.TreeSet/TreeMap
是插入数据的时候,就开始排序,也是比较数据和交换数据。
如果是普通的比较数据和数据数据,那么速度很慢。
怎么才能快起来?使用平衡二叉树(jdk使用的是平衡二叉树中的红黑树)!
最佳实践
1.Hashtable及其实现接口和子类
已经被官方弃用。
2.HashMap、并发ConcurrentHashMap、数据有序TreeMap、插入有序LinkedHashMap
推荐使用。
map的底层数据结构?
1.数组 //读快,速度1
数组[hashcode]。
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; //数组
2.链表 //写快,速度1
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next; //链表
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
map如何防止hashcode(即数组索引)重复?
这里说的hashcode重复,是指索引重复,hashcode就是索引。
首先,我们知道map的key需要经过hash转换为hashcode,hashcode才是最终的数组索引,map就是数组。
所以,索引重复有2种情况,
1.key相同
因为hash算法相同,如果key相同,得到的hashcode肯定相同。
2.key不同
虽然,hash算法将hashcode这个值散列得足够分散,一般情况下不会出现重复的情况。
但是,理论上存在重复的情况。
如何解决key不同情况下的hashcode值相同这个问题,就是hash算法要解决的问题。
如果hashcode重复,map如何处理?
1.key相同 因为是相同的key,相同的hashcode,所以这是重复数据,就不需要插入。map会判断是否存在该key/hashcode。
2.key不同
其实这种情况,虽然key不同,但是hashcode相同,map的处理方式仍然同上,和上一种情况一样。
但是,key不同的情况,必须是要插入数据的。
所以,只能使用hash算法尽量保证不同key的hashcode不同。不同的hash算法,就是为了解决这个问题。
hash算法/散列函数?
1.没有解决冲突的算法 //直接定址 2.可以解决冲突的算法 //开放探测定址
www.nowamagic.net/academy/det…
map是数组,那是不是一段连续的存储空间?
是的。
key、hashcode和索引i之间的关系?
key——》hashcode(hash算法)——》i(数组索引)。
hash算法
代码
Object.hashCode()方法。
主要包含两种运算
1.位移
2.按位与&
数组-底层实现
计算机组成原理
这个问题本质上是访问内存地址的问题。如何访问内存地址?首先,我们得明白内存的分类:
1.连续内存 //对应的数据结构是数组
2.非连续内存 //对应的数据结构是链表
那么,不管是连续内存还是非连续内存,内存访问数据就是访问内存地址,找到地址就找到那个地址保存的数据/值。
所以,比如数组,是怎么访问内存地址/数据的呢?基于数组的起始地址,然后再加上一个偏移量。这个偏移量就是数组的索引,因为每个元素的数据类型和内存大小固定,所以根据索引计算偏移量,得到了偏移量就可以定位到某个元素的内存地址,到此为止就找到了那个数据。
但是链表不行,因为链表是基于指针,而指针指向哪个地址,你是不知道的。所以是需要遍历数据。而数组是根据索引——偏移量——元素内存地址这么计算出来的,真正的寻址只需要寻址一次,而链表要寻址多次即遍历多次。
