1.准备基础环境
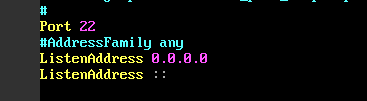
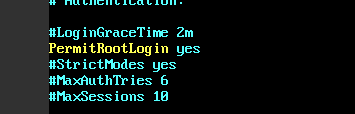
- 配置远程登录
修改ssh的配置文件,监听22端口并允许远程登录
- 安装jdk,如果已安装需要卸载
yum search java-1.8.0 | grep -i --color jdk
yum install java-1.8.0-openjdk.x86_64
- 编辑 etc/profile文件,并在最后写入下面的配置代码
vim /etc/profile
export JAVA_HOME=/opt/java/jdk1.8.0_211
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /ect/profile
查看最终的版本号,如有显示版本号,即代表安装成功
java -version
- 实现多台机器免密登录
在master服务器也就是第一台服务器上执行如下命令参数一个秘钥对,并把公钥发给datanode
ssh-keygen -t rsa
ssh-copy-id -i 数据节点IP地址
ssh 数据节点IP地址
过程中如果ssh出现错误,可以ssh -vvv IP地址查看调试信息
2.部署Hadoop 2.9.2
- 使用清华源安装hadoop
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
tar -zxcf hadoop-2.9.2.tar.gz
-
配置hadoop 注意要进入到hadoop的安装目录底下找到对应的文件夹再执行下面的命令,下面是我电脑的

-
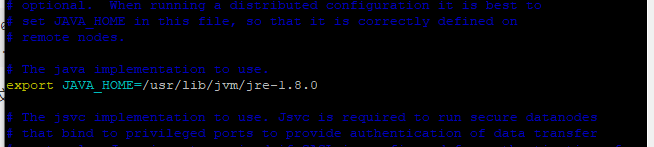
vim hadoop-env.sh
- vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.69:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
</configuration>
- vim httpfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/name</value>
<description>为了保证元数据的安全一般配置多个不同目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/data</value>
<description>datanode 的数据存储目录</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>HDFS 的数据块的副本存储个数, 默认是3</description>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>192.168.0.69:50090</value>
<description>secondarynamenode 运行节点的信息,和 namenode 不同节点</description>
</property>
</configuration>
- mapred-site.xml 修改hadoop的资源调度框架为yarn
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.0.69</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>YARN 集群为 MapReduce 程序提供的 shuffle 服务</description>
</property>
</configuration>
- vim salves 只有一个数据节点
192.168.0.70
- 同步所有配置文件到数据节点
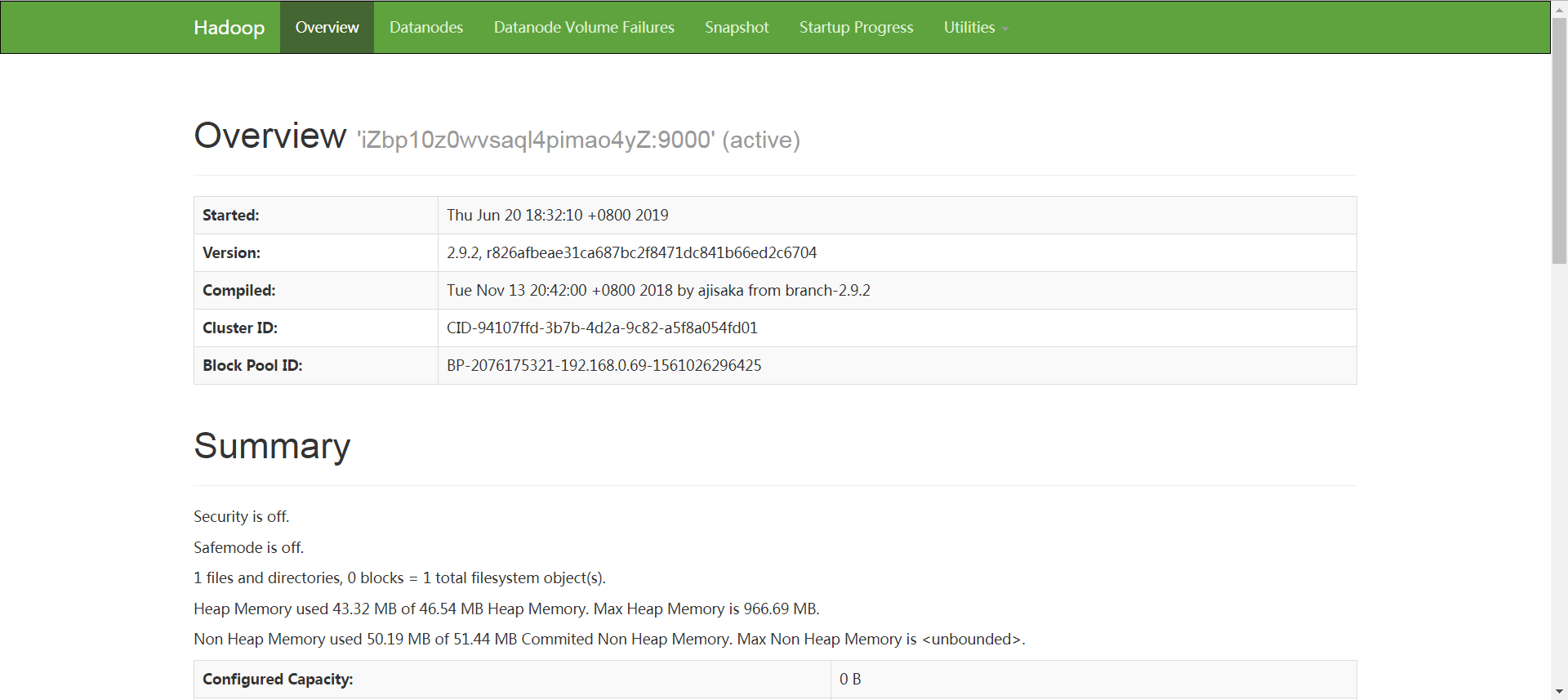
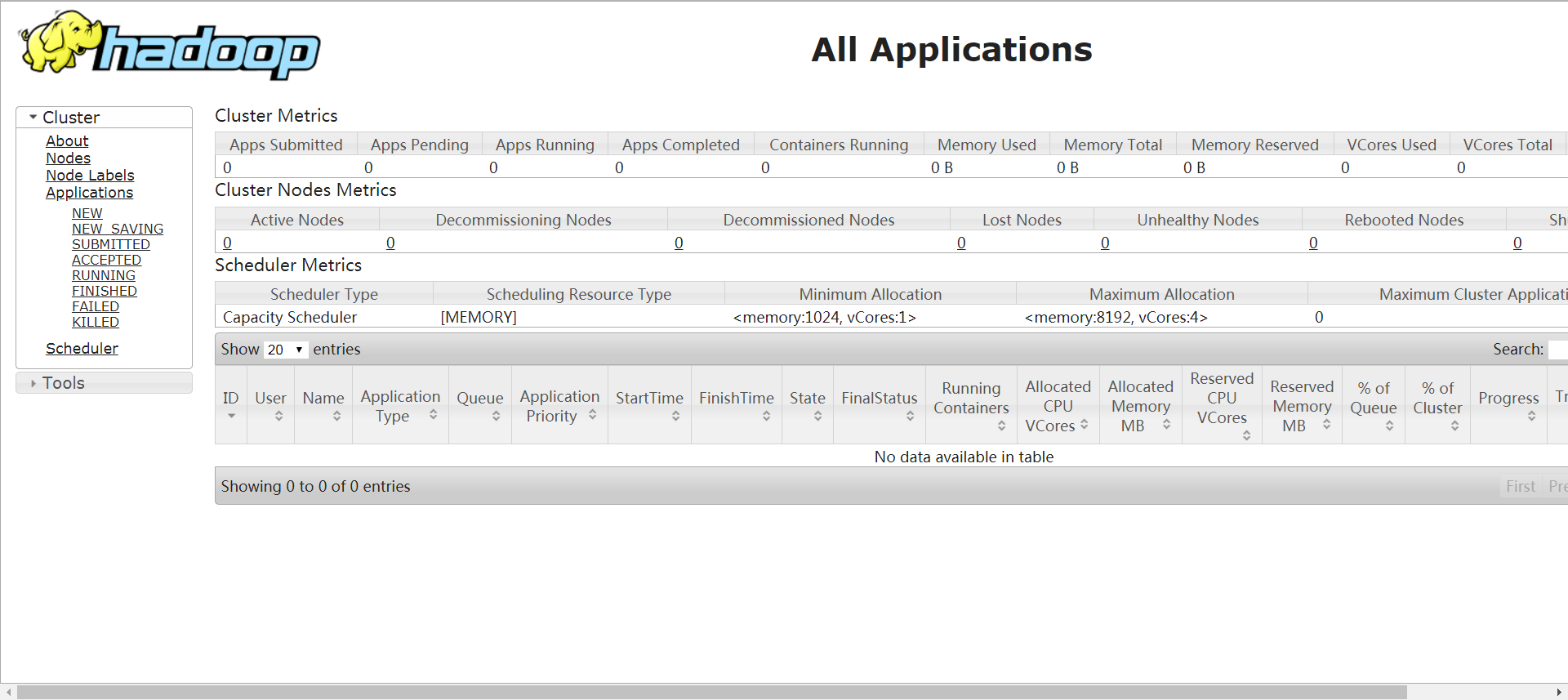
3.确认最终结果