

大数据启蒙
分治思想
如何从1W个数中找到想要的那个数 线性表中
顺序查找时间复杂度为O(n) 如何把复杂度降低为O(4)? 哈希表,链长度为4 x.hashcode%2500不考虑倾斜问题。
如何从一个大文件(1T)中找到重复的两行 单机纯JavaSE
- 前提:生产上用的SSD 读取速度500MB/s 读一遍这个文件得2000s
- TIPS:内存速度是磁盘的10万倍
- 最笨的办法:拿出第一行来然后遍历其余所有行进行比对 最复杂的情况,最后两行重复
- 分治思想:readline().hashcode()%2500 结果分别放在一个一个的小文件中。最后会散列成2500个小文件(需要一次全量IO)。相同的行一定会被散列到同一个小文件中。这个小文件能一下load到内存中。再来一次全量IO,就能找出来重复行了。
如何进行全排序,1T的文件里
- hashcode不能用了,会改变数据的特征。
readLine if(x>0 && x<100)根据范围 散列成小文件。这时候这些小文件是内部无序外部有序的,来一次全量IO,把每个小文件进行排序就完成了全排序。- 上述方法 每次都有逻辑判断,有CPU运算过程。
- 对数据结构熟悉的话,第一次全量IO时,一次读取50MB到内存中进行一次排序然后扔到一个小文件,中得到的小文件们特点是内部有序外部无序,同时引出归并排序算法
如何将上面时间变为分钟、秒级
- 单机处理大数据的瓶颈在IO上
- 如果给2000台机器,1T文件分成2000份给这些机器,每台机器都处理500MB数据,并行计算。每台机器1s就能读500MB
- 每台readline.hashcode%2000 散列成2000个小文件
- 让每台机器的0号文件 1号文件...相遇,这牵扯到了网络IO。然后2000台每台上面都是1~2000号小文件 每个文件500MB ,并行计算 各自算自己的文件中的重复行。
- 坑:把1T文件散列到2000台 需要时间 而且是走网络IO。
- 移动数据的成本很高。将计算向数据移动。
- 分布式真的会快吗? 辩证!
结论
- 分而治之
- 并行计算
- 计算向数据移动
- 数据本地化读取
hadoop
时间简史
- 03年GFS论文
- 04年MapReduce论文
- 06年BigTable论文
- 05年Hadoop作为Lucene子项目
- hadoop.apache.org 顶级项目
大数据生态
- 之前都是批处理
- spark和flink 能流 能批
- 现在都开始批转流
hdfs
当时分布式文件系统那么多为什么还要开发hdfs
存储模型
- 文件线性按字节切分成block,只要是文件就是字节数组,块具有offset,id
- 文件与文件block大小可以不一样
- 一个文件除了最后一个block,其他的block大小一致
- block的大小根据硬件IO调整
- block被分散到集群的节点中
- block具有副本 副本没有主从, 副本不能在同一台上
- 副本满足可靠性和性能,副本数多 计算效率提高
- 文件上传指定block大小和副本数,上传之后只能修改副本数
- 一次写入多次读取,不支持修改。
- append数据
架构设计
- 主从架构 (和主备两回事儿)
- NN+DN,角色即jvm进程
- 文件数据和文件元数据
- NN负责存储和管理文件元数据(记账),维护了一个层次型的文件目录树
- DN存储文件数据(block) 并且提供block的读写
- DN和NN维持心跳,并汇报自己block的信息
- client和NN交互文件元数据,和DN交互block
角色功能
NameNode
- 完全基于内存存储(快速提供服务)
- 内存存储就牵扯到了 持久化。
- 副本放置策略
DataNode
- 基于本地磁盘存储block
- 保存block的校验和(客户端拿到block会算出校验和 和 DN的校验和比对)
- 与NN保持心跳,汇报block信息
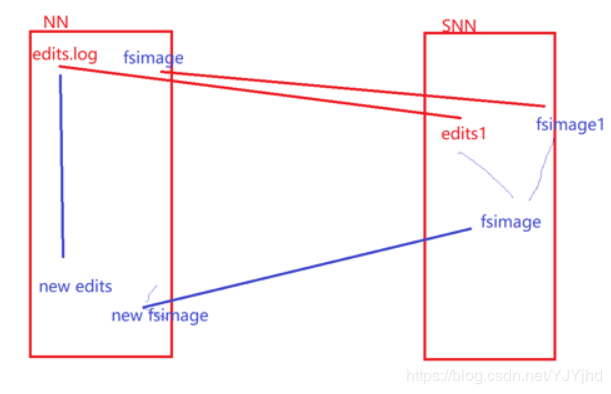
元数据持久化
世界上有两种方式:
- 日志:记录实时发生的操作。完整性比较好。加载恢复数据慢、占空间
- 镜像、快照、dump:间隔的,内存全量数据基于某一个时间点做的向磁盘的溢写。恢复速度快,但是因为是间隔的容易丢失一部分数据。
- hdfs:editslog 日志 fsimage 镜像,滚动更新
- 最近时点的fsimage + 增量的editslog
安全模式
说白了,NN启动的时候没有存储块的信息。安全模式就是DNS向NN汇报自己块信息的过程。
- 搭建HDFS会格式化,格式化会产生空的FsImage
- NN启动时,从硬盘中读取editslog和fsimage
- 将editslog作用到fsimage上
- 保存一个新的fsimage到本地磁盘上
- 删除旧的editlog,已经没用了。fsimage已经包含它了
- 文件的属性会持久化,但是块的信息不会持久化,说白了恢复的时候NN不知道块的信息。等DN和NN心跳 汇报块的信息。
- NN启动会进入安全模式,等待和DN的通信收集块的信息。
SNN(非HA模式下)
- SNN独立的节点,周期完成editslog向fsimage的合并
- fs.checkpoint.period 默认3600s 就是一小时合并一次fsimage合并
- fs.checkpoint.size 最大值64mb 就是editslog 到64mb开始想fsimage合并
副本放置策略
- 第一个 如果客户端上有DN 那就放本地的DN
- 第二个和第一个不同的机架
- 第三个和第二个相同机架
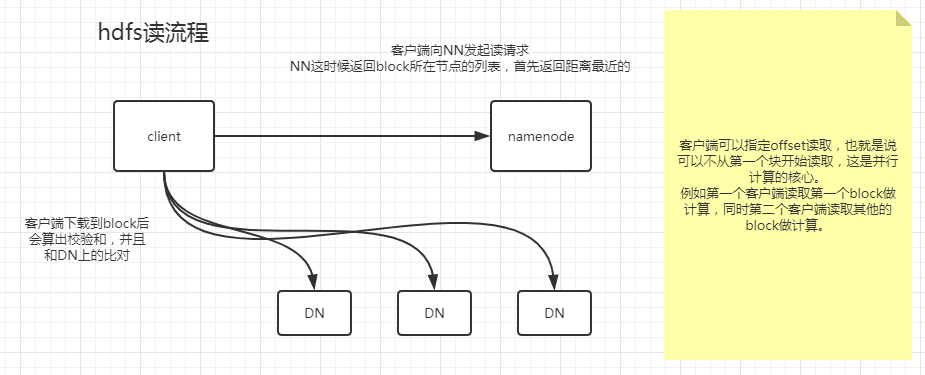
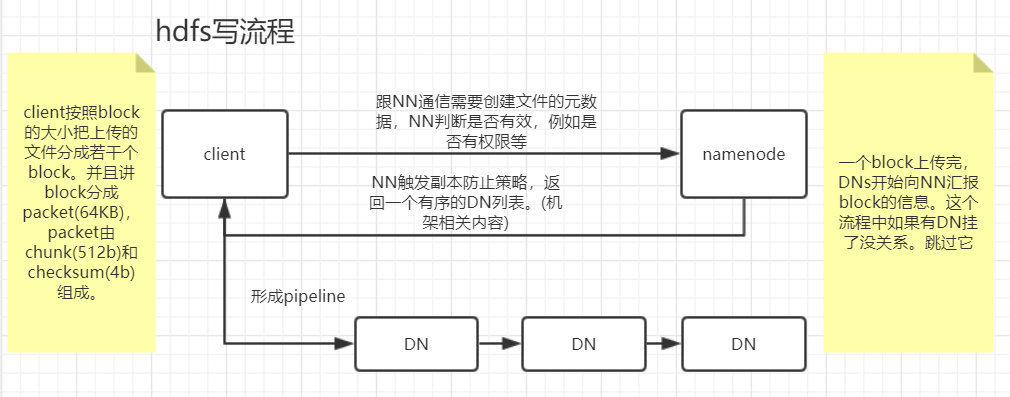
HDFS读写流程
流水线也是一种变种的并行
实践 2.6.5
基础设施
- 配置IP地址
- 改主机名
vim /etc/sysconfig/network,配置hosts解耦 - 关闭防火墙
service iptables stop开机也禁用防火墙chkconfig iptables off - 关闭selinux
vim /etc/selinux/config - 所有节点时间同步,ntp同步
vim /etc/ntp.confnpt1.aliyun.com开机启用chkconfig ntpd on - 用rpm装jdk 在
/usr/java有的软件找/usr/java/default配置JAVA_HOME & PATHsource一把 - 配置SSH免密,
ssh localhost跟自己也要免密,这个过程会生成一个.ssh目录。把公钥给别人 追加在别人的authorized_key /opt应用放这个目录- 配置一个
HADOOP_HOME vi /$HADOOP_HOME/etc/hadoop-env.sh把jdk换成绝对路径vi /$HADOOP_HOME/etc/core-site.xml配置namenode的地址和端口9000vi /$HADOOP_HOME/etc/hdfs-site.xml配置副本数vi /$HADOOP_HOME/etc/slaves里面配置DNs都是谁dfs.namenode.name.dirNN的持久化目录,hdfs格式化初始化这个目录,并且初始化fsimage,里面有VERSION记录的集群信息dfs.datanode.data.dirDN的block实际存放的目录dfs.namenode.secondary.http-address配置SNN的地址端口号默认是50090dfs.namenode.checkpoint.dir配置SNN的目录。结合他的职责就是负责滚动更新fsimage- SNN只需要从NN拿最新的fsimage和增量的edits_log 然后开始滚动更新
hdfs dfs -mkdir /bigdata在hdfs创建一个目录/user/root家目录hdfs dfs -put xxx上传一个文件的时候,50090界面上会显示一个xxxCOPYING- 在DN的目录中能看到block 以及校验和
hdfs dfs -D dfs.blocksize=1048576 -put xxx上传的时候指定块的大小 为1MB 验证确实是按照字节来切块的
伪分布式,所有角色在一台机器不同的进程 DN SNN NN都在一台
sbin一些服务命令bin功能命令- 根据官网
start-dfs.sh需要配置免密。 - ssh远程执行命令的时候并不会加载远程的环境变量,也就是说拿不到环境变量中的
JAVA_HOME - Hadoop-env.sh
- 第一步,格式化文件系统
hdfs namenode -format生成一个空的fsimage 也就是初始化
完全分布式
NN -> core.site.xml
DN -> slaves
SNN -> hdfs-site.xml
- 准备好4台机器 互信 基础设施找运维
- SSH 免密是为了启动脚本。随便挑一台就能行。 后面HA还会涉及到免密另个一事儿
- 脚本会加载
$HADOOP_HOME/etc/hadoop他只会去加载Hadoop这个文件夹 所以 可以备份一个之前伪分布式的配置 - 格式化新集群,格式化只跟namenode有关和SNN没关系。
- 集群重启的时候NN会合并一次fsimage,不重启就不管了 SNN负责
主从结构 1.单点故障 2.基于内存压力过大
- 单点故障解决方案:HA 多个NN 主备切换,2.x一主一备 3.x一主三备
- 压力过大:联邦机制,多个NN管理不同的元数据
- NN中元数据有两个来源:一个是客户端产生的,例如mkdir。另一个是DN向他汇报的
- 强一致性破坏可用性!
- paxos算法,过半通过中和了一致性和可用性。(QJM 和zk)
- JNs是一个主从结构,NNactive把数据给JNs NN备就从JNs中同步数据。JNs相对可靠的集群。
- 自动化的HA 用到zookeeper
- 两个namenode上还有一个进程 ZKFC,这个人有三只手
- 第一只手:会和NN有心跳 看是否活着
- 第二支手:和ZK集群连着,两个ZKFC去抢锁,抢到了那么它身上的NN就是active的。如果NN进程挂了,那ZKFC会把锁删除掉。牵扯出了ZK的事件机制,锁被删除了会触发一个callback这个回调调的是ZKFC中的一个方法会再去抢锁!
- 第三只手:备用的NN的ZKFC抢到锁之后,把手伸向了另一个NN 看是否真的挂掉了。 这是为了防止脑裂
- 如果NN没有挂 而是它的ZKFC挂了:
- 牵扯到ZK的知识,ZKFC在ZK上创建了一个锁,这个锁是临时锁,如果ZKFC挂了 通信断了,那么ZK上的锁就被删了,同时出发另一个ZKFC的回调,那边就拿到锁了。
- 极端现象,抢到锁的ZKFC不能和对方的NN通信了,无法判断那个NN是否真的挂了,出现尴尬现象。触发概率极低。找运维。
- JNs得最少3台,JNs里是edit log
- DNs需要同时向两个NN汇报block信息。
- HA模式下,standbyNN 完成合并fsimage
- 官网HA文档
2.x HA实践
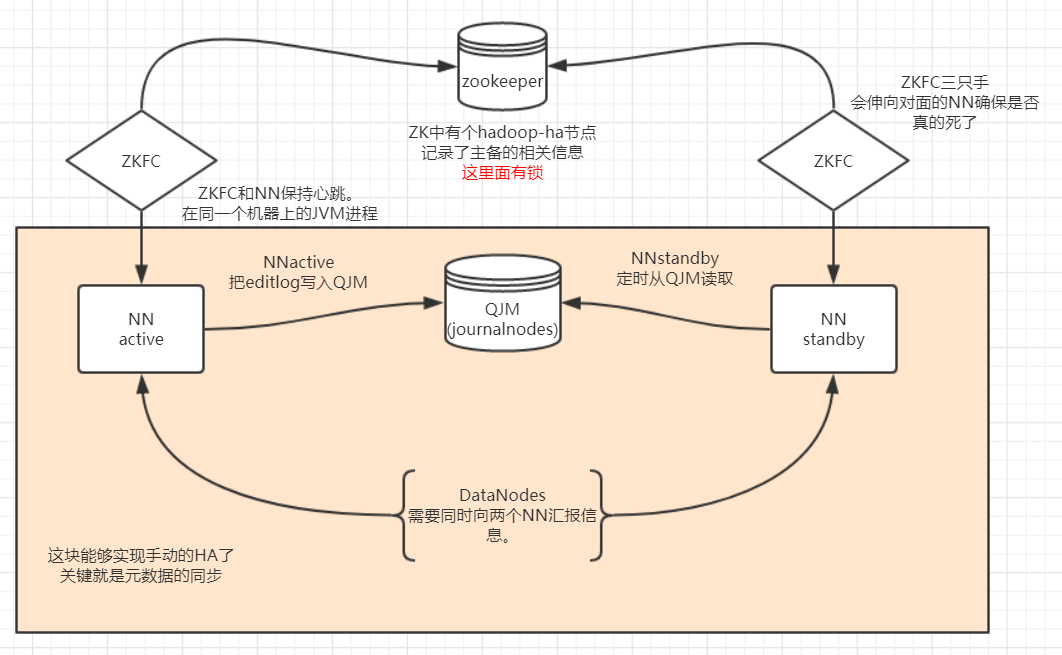
- 两个namenode之间需要免密。原因:namenode同机器上的ZKFC进程第三只手要够得到对面的检查对面的namenode进程状态。
zookeeper
简单使用。
- 安装ZK
cp zoo_sample.cfg zoo.cfg然后基于zoo.cfg修改- 修改zk dataDir
- 增加
server.1=node1:2888:3888一个端口是他们通信的 另一个端口是选举用的(不一定准确) - 在
dataDir下放myid - 配置ZK环境变量,当启动数过半就能选出leader了。
zkServer.sh start
core-site.xml
配置NN的逻辑名。配置ZK信息
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- the node map to the logic name -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:50070</value>
</property>
<!-- journalNode NN连接JNs -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/jn</value>
</property>
<!--角色切换的代理类和实现的方法 用的ssh免密-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--自动化 zkfc-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--副本数-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/data</value>
</property>
</configuration>
hdfs的权限
- hdfs没有任何API去创建用户。
- hdfs使用操作系统上的用户。也可以对接第三方例如ldap
- Linux的超级管理员是root,HDFS的超级管理员是启动NN的那个用户 可以是dog
- root向管理员的家目录放文件 提示没有权限
[root@node1 ~]# hdfs dfs -put data.txt /user/god
put: Permission denied: user=root, access=WRITE, inode="/user/god":god:supergroup:drwxr-xr-x
hdfs javaAPI
用JAVA API来操作hdfs。有一些非常重要的操作例如seek。看MR源码的时候里面有很多这些API。
hdfs client
- 权限:
- Windows开发机的用户名
- 环境变量
HADOOP_USER_NAME - 代码中指出(我用这个)
- maven 构建项目common、hdfs依赖
计算向数据移动的核心,读文件可以用seek 随意读。
@Test
public void blocks() throws Exception {
Path path = new Path("/user/god/data.txt");
// 拿到文件的元数据 文件有多大,有几个副本
//FileStatus{path=hdfs://mycluster/user/god/data.txt; isDirectory=false; length=1888895; replication=2; blocksize=1048576; modification_time=1562256283621; access_time=1563345477080; owner=god; group=supergroup; permission=rw-r--r--; isSymlink=false}
FileStatus fileStatus = fs.getFileStatus(path);
// 拿出所有块的信息。换言之,可以拿任何块的信息!
BlockLocation[] blockLocations = fs.getFileBlockLocations(fileStatus, 0, fileStatus.getLen());
for(BlockLocation blk : blockLocations){
System.out.println(blk);
blk.getHosts();
blk.getOffset();
}
// 并行计算的原因
// 0, 1048576, node2, node3
// 1048576, 840319, node3, node4
// 用户和程序是面向文件的,不是面向块的
// 面向文件打开输入流
FSDataInputStream open = fs.open(path);
// 核心! 读取自己要计算的块
open.seek(1048576);
}
MapReduce
见MapReduce专栏
