

来源:
《高性能mysql(第三版)》
假如有以下表:
create table test (
col1 int not null,
col2 int not null,
primary key(col1),
key(col2)
);
假设该表的主键值取值1-10000,按照随机顺序插入并使用OPTIMIZE TABLE 命令做了优化。也就是说,数据在磁盘上的存储方式已经最优,但是行的顺序是随机的,列col2的值1-100之间的随机值,所以有很多重复的值。
我们先介绍MyISAM的数据分布:
MyISAM按照数据插入的顺序存储在磁盘上,如下表:
| 行号 | col1 | col2 |
|---|---|---|
| 0 | 99 | 8 |
| 1 | 12 | 56 |
| 2 | 3000 | 62 |
....
| 行号 | col1 | col2 |
|---|---|---|
| 9997 | 18 | 8 |
| 9998 | 4700 | 13 |
| 9999 | 3 | 93 |
因为这里行是定长的,所以MyISAM可以从表的开始跳过所需的字节找到需要的行。(对于变长的行使用不同的策略,这里暂不介绍)
这种分布方式很容易创建索引,下图显示了表的主键分布:
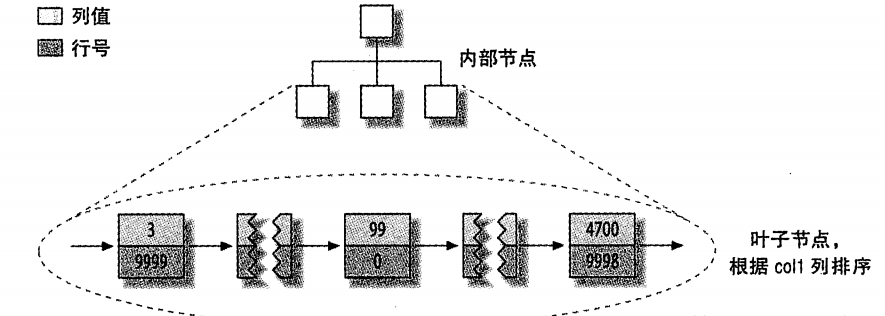
可以看到,叶子节点按照主键排序好了,而且还保存了行号。
那么MyISAM下,col2上的索引有什么不同呢?答案是完全一样的存储方式,只是把主键列换成col2列罢了。这里就不再赘述。
再来看InnoDB的数据分布:
下面是InnoDB的主键分布:
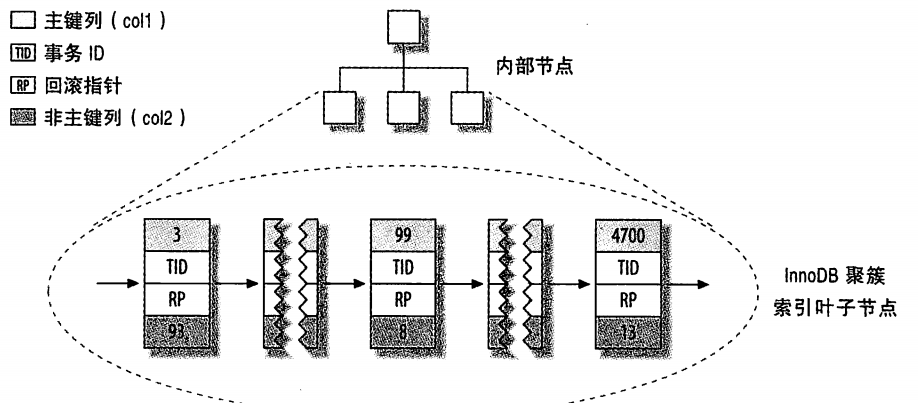
注意看,上图显示了整个表,而不是只有索引。
因为在InnoDB中,聚簇索引 "就是"表。所以不像MyISAM那样需要独立的行储存。
每个叶子节点都包含了主键值,事务id, 回滚指针(用于事务和mvvc),以及所有剩余的列(这个例子是col2)
除此以外,InnoDB的二级索引和聚簇索引很不同,和MyISAM的索引也不一样。如下图:
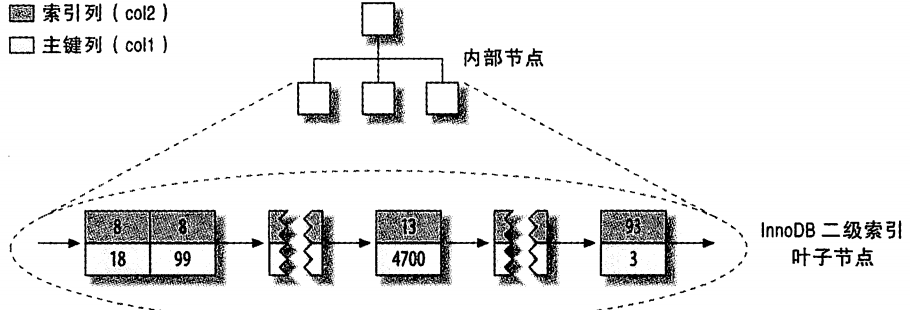
InnoDB的二级索引的叶子节点存储的不是行号,而是主键值。这样的策略减少了当出现行移动或者数据页分裂时二级索引的维护工作。使用主键值当工作指针会让二级索引占用更多的空间,换来的好处是,InnoDB在移动行时不必更新二级索引的这个“指针”。
上图我们省略了非叶子节点的细节,它包含了索引列和一个指向下一个节点的指针。
总结
- MyISAM的主键索引和二级索引存储方式一样,都是存放的索引列和行号。索引文件和数据文件分开的。
- InnoDB的主键索引包含了主键和其他全部列,以及其他信息(主键索引和数据文件是一起的);二级索引则是一个单独的文件,存放索引列和主键值。
