

理解条件随机场
其它机器学习、深度学习算法的全面系统讲解可以阅读《机器学习与应用》,清华大学出版社,雷明著,由SIGAI公众号作者倾力打造,自2019年1月出版以来已重印3次。
PDF全文链接:理解条件随机场
条件随机场是一种概率无向图模型,也是马尔可夫随机场的特例。本节首先介绍概率无向图的概念,然后在其基础上介绍马尔可夫随机场。
概率图模型
概率图模型是机器学习中的一类算法,它用图进行建模。学过离散数学或数据结构的同学对图的概念不会陌生。图的顶点为随机变量,边为变量之间的概率关系。如果是有向图,则称为概率有向图模型;如果图无向,则称为概率无向图模型。下图是一个简单的概率有向图,也称为贝叶斯网络
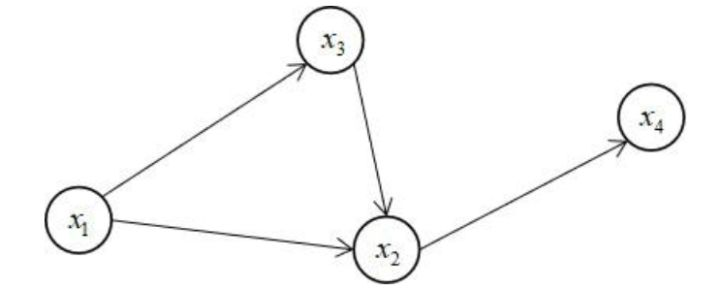
在上图中有4个顶点,对应于4个随机变量。边表示随机变量之间的条件概率,如果 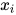 到
到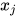 有一条边,则表示它们之间的条件概率为
有一条边,则表示它们之间的条件概率为 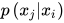 。以上图为例,所有随机变量的联合概率为
。以上图为例,所有随机变量的联合概率为
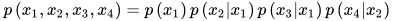
如果顶点 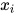 没有边射入,则在联合概率的乘积项中会出现
没有边射入,则在联合概率的乘积项中会出现 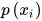 。如果从顶点
。如果从顶点 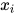 到
到 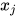 有边,则在乘积项中有
有边,则在乘积项中有 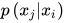 。之前介绍的隐马尔可夫模型就是一种有向图模型。
。之前介绍的隐马尔可夫模型就是一种有向图模型。
接下来定义团(clique)与最大团(maximal clique)的概念。如果一个无向图的所有顶点之间均有边连接,则称为团。以下图为例,子图 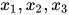 和
和 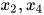 是整个图的两个团,而不是团,因为
是整个图的两个团,而不是团,因为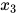 与
与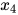 之间没有边连接。如果一个子图是团,再加入一个顶点之后不是团,则称为最大团。根据定义,
之间没有边连接。如果一个子图是团,再加入一个顶点之后不是团,则称为最大团。根据定义, 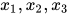 和
和 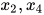 是最大团。而
是最大团。而 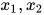 不是最大团,因为加入顶点
不是最大团,因为加入顶点 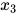 之后还是一个团。
之后还是一个团。
在概率无向图中边是无向的,联合概率的计算方式与有向图不同。以下图为例
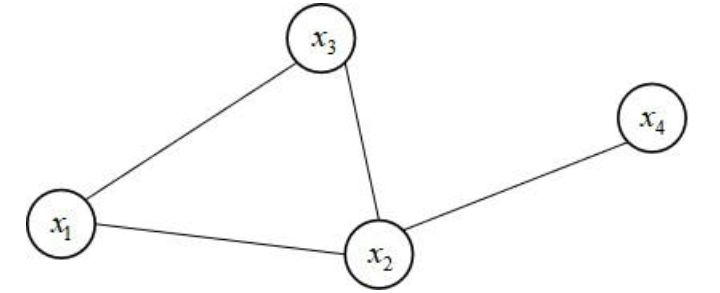
这里的边不是变量之间的条件概率。计算联合概率的方式是因子分解,计算公式为
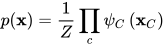
C为无向图的最大团,x为所有随机变量构成的向量, 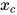 为团C中所有顶点对应的随机变量构成的向量,
为团C中所有顶点对应的随机变量构成的向量, 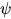 为势函数(也称为因子)。Z为归一化因子,用于保证上式计算出的是合法的概率值
为势函数(也称为因子)。Z为归一化因子,用于保证上式计算出的是合法的概率值
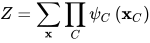
即对x所有可能的取值求和。势函数必须严格为正,一般使用指数函数
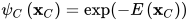
E(X)为任意函数,有时称为能量函数。上面这种形式的无向图模型也称为随机场。以上图21.2为例,所有变量的联合概率为
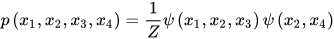
上式的两个乘积项对应于图的两个最大团。势函数的具体设计将后面介绍。
马尔可夫随机场
假设u和v是无向图中任意两个没有边连接的顶点,对应的随机变量为 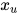 和
和 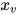 ,除去这两个顶点之外其他顶点构成的集合为O,对应的随机向量为
,除去这两个顶点之外其他顶点构成的集合为O,对应的随机向量为 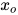 。如果在给定随机向量的条件下
。如果在给定随机向量的条件下 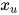 和
和 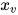 条件独立,即
条件独立,即
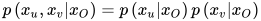
则称图满足成对马尔可夫性。
假设u是图的任意顶点,W是与u有边连接的顶点构成的集合,O是除u和W之外的顶点构成的集合,它们对应的随机变量为  ,
, 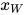 和
和 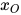 。如果在给定xW的条件下
。如果在给定xW的条件下 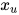 和
和 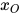 条件独立,即
条件独立,即
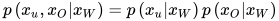
则称图满足局部马尔可夫性。
假设顶点子集A和B被C分隔,即子图A和C、B和C之间有边连接,但A和B之间没有边连接。它们对应的随机向量为 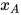 ,
, 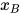 和
和 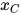 。如果在给定
。如果在给定 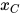 的条件下
的条件下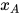 和
和 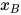 条件独立,即
条件独立,即
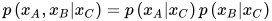
则称图满足全局马尔可夫性。一个重要结论是上面3种马尔可夫性是等价的。一个概率无向图模型如果满足上面定义的3种马尔可夫性,则称为马尔可夫随机场(Markov random field)。
条件随机场
下面以马尔可夫随机场为基础,介绍条件随机场,线性链条件随机场的概念。条件随机场是马尔可夫随机场的特例,而线性链条件随机场又是条件随机场的特例。
一般的条件随机场
条件随机场是马尔可夫随机场的特例,这种模型中有x和y两组随机向量。前者是观测序列,其值可见;后者是隐变量,也称为标签序列,其值不可见。如果给定x的条件下y是马尔可夫随机场,则称为条件随机场。
下面给出条件随机场的形式化定义。假设有无向图模型,其顶点对应的随机向量为y,对于图中任意顶点u,与该顶点有边连接的顶点集合为W,除u之外的顶点的集合为O。如果满足
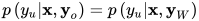
则称条件概率p(y丨x)为条件随机场。条件随机场中任意一个隐变量的条件概率与和该顶点没有边连接的顶点无关。条件随机场的条件概率可以按照下式计算
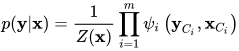
其中m为最大团的数量, 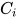 为第i个最大团,
为第i个最大团, 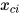 和
和 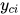 为该团的所有顶点对应的随机变量构成的向量,
为该团的所有顶点对应的随机变量构成的向量, 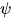 为势函数。Z(x)为归一化因子
为势函数。Z(x)为归一化因子
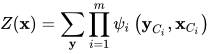
条件随机场只对p(y丨x)建模,而没有对p(x丨y)或p(x,y)建模,因此是一种判别模型。读者对此千万不要理解错。
线性链条件随机场
一般的条件随机场需要枚举所有的最大团,不易计算,下面介绍它的一种特殊情况,称为线性链条件随机场(linear chain conditional random field),由Lafferty等人在2001年提出[2]。线性链条件随机场中的状态变量形成一个线性链,类似于数据结构中的链表结构,每个节点只与前一个节点(如果存在),后一个节点(如果存在)有关。即在时间序列中每个变量只和前一时刻、后一个时刻的变量有关
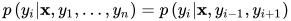
下图是一个简单的线性链条件随机场
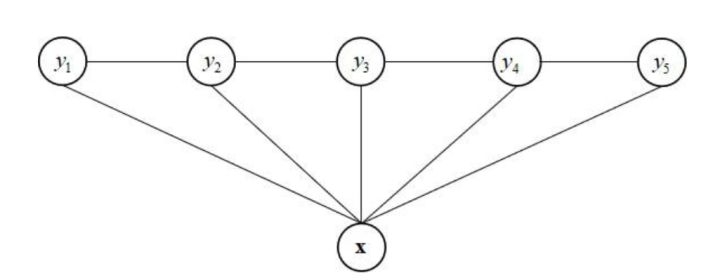
上图中观测变量序列为x,状态变量序列为  ,每一个隐变量和所有观测变量有概率依赖关系。除
,每一个隐变量和所有观测变量有概率依赖关系。除 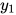 与
与 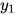 之外,每个状态变量只和它前一个时刻的状态量、后一时刻的状态变量有关,而与其他时刻的状态变量无关。
之外,每个状态变量只和它前一个时刻的状态量、后一时刻的状态变量有关,而与其他时刻的状态变量无关。
根据条件随机场的概率计算公式,已知观测序列x的条件下,状态变量的所有最大团为相邻两个状态变量{ 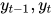 },如果势函数为
},如果势函数为
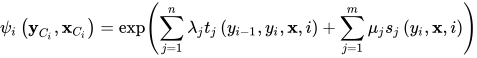
状态序列y的条件概率为
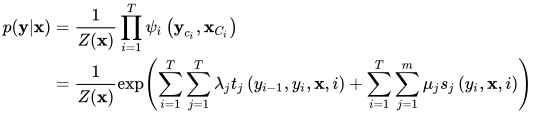
为了统一表述,与隐马尔可夫模型类似,增加了一个特殊的状态 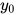 作为初始状态。Z(x)为归一化因子,是对标签序列所有可能取值求和
作为初始状态。Z(x)为归一化因子,是对标签序列所有可能取值求和
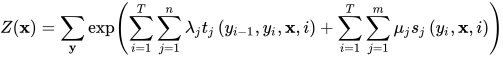
t和s为特征函数,前者是转移特征,类似于隐马尔可夫模型中的状态转移概率;后者是状态特征,类似于隐马尔可夫模型中的观测概率。它们根据具体的问题由人工设定。T是观测序列的长度,n和m为特征函数的数量,由人工设定λ和μ为特征函数的权重,为模型的参数,其值越大说明此特征越有用。需要注意的是λ和μ与序列的位置无关。
特征函数s的以观测序列x,第i个标签值 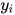 为输入,根据不同的输入值组合其输出值为1和0,此特征函数用于对输入变量和标签变量的概率依赖关系建模。特征函数t以观测序列x,第i个标签值
为输入,根据不同的输入值组合其输出值为1和0,此特征函数用于对输入变量和标签变量的概率依赖关系建模。特征函数t以观测序列x,第i个标签值 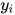 ,第i-1个标签值
,第i-1个标签值 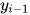 为输入,其输出值同样为1和0,该函数用于对输入变量与标签变量的概率关系、相邻标签变量之间的概率关系建模。
为输入,其输出值同样为1和0,该函数用于对输入变量与标签变量的概率关系、相邻标签变量之间的概率关系建模。
下面以中文分词问题为例,介绍条件随机场如何用于实际问题,这是典型的序列标注问题。中文分词即断句,是自然语言处理中的核心、基础问题。因为中文和英文不同,各个词之间没有空格隔开。对于下面的句子
我是中国人
正确的分词结果为
我 是 中国人
在这里观测序列是输入的语句,每个字为每个时刻的观测值。状态序列为分词的结果,每个时刻的状态值有如下几种情况
{B,M,E,S}
其中B表示当前字为一个词的开始,M表示当前字是一个词的中间位置,E表示当前字是一个词的结尾,S表示单字词。则上面这个句子的分词标注结果为
我/S 是/S 中/B 国/M 人/E
显然,得到了这个标注结果,我们就可以得到分词结果,做法很简单:
遇到S,则为一个单字词;遇到B,则为一个词的开始,直到遇到下一个E,则为一个词的结尾。
分词问题为给定观测序列x,计算出条件概率p{y丨x}最大的标记序列y,对应的就是分词的结果。
下面是中文分词问题状态转移特征函数的例子
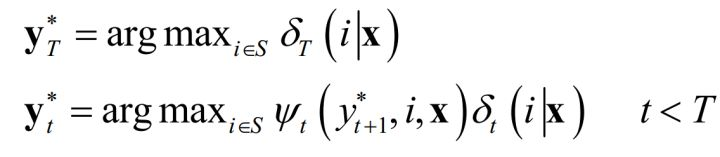
其含义是如果句子中的第i个汉字是“是”,第i-1个汉字的标记结果为E,第i个汉字的标记结果为B时函数返回1,否则返回0。
如果在训练文件中有句子“我是中国人”,则会生成下列状态特征函数(限于篇幅,只列出了一部分)
if (x_i = ‘我’ and y_i = B) return 1 else return 0
if (x_i = ‘我’ and y_i = M) return 1 else return 0
if (x_i = ‘我’ and y_i = E) return 1 else return 0
if (x_i = ‘我’ and y_i = S) return 1 else return 0
if (x_i = ‘是’ and y_i = B) return 1 else return 0
if (x_i = ‘是’ and y_i = M) return 1 else return 0
if (x_i = ‘是’ and y_i = E) return 1 else return 0
if (x_i = ‘是’ and y_i = S) return 1 else return 0
其中x_i为公式中的xi,y_i为公式中的yi。如果字典中的字符数为D,标签的取值数为L,则上面这种状态特征函数的总数为D×L。另外还会生成下列状态转移特征函数(同样只列出了一部分)
if (x_i= ‘我’ and y_i_1 = B and y_i = B) return 1 else return 0
if (x_i= ‘我’ and y_i_1 = B and y_i = M) return 1 else return 0
if (x_i= ‘我’ and y_i_1 = B and y_i = E) return 1 else return 0
if (x_i= ‘我’ and y_i_1 = B and y_i = S) return 1 else return 0
其中y-i-1为公式中的 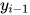 。对于这种情况,状态转移函数的总数为D×L×L。除了上面两种最简单的特征函数之外,在实现时还可以设计更复杂的特征函数,以对更长的上下文依赖进行建模。特征函数可以看作输入序列与标签位置关系的规则。
。对于这种情况,状态转移函数的总数为D×L×L。除了上面两种最简单的特征函数之外,在实现时还可以设计更复杂的特征函数,以对更长的上下文依赖进行建模。特征函数可以看作输入序列与标签位置关系的规则。
每一个特征函数都可以用来为一个标注序列评分,把集合中所有特征函数对同一个标签序列的评分综合起来,得到标签序列最终的评分值。
如果将两种特征函数合并,条件概率可以写成
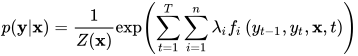
其中T为序列长度,n为特征函数的数量。归一化因子变为
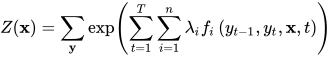
线性链条件随机场的因子分解为所有相邻两个状态变量,如下图所示
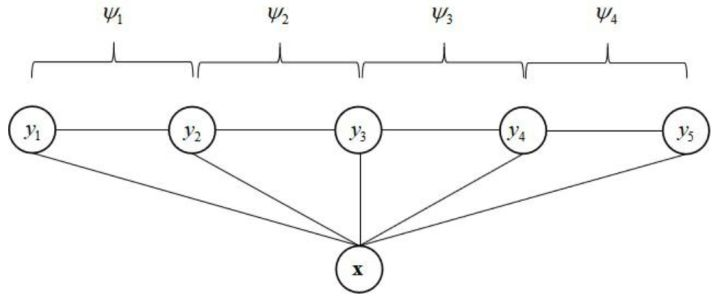
对上面的条件概率取对数,Z(x)是一个常数,因此条件随机场是一个对数线性模型
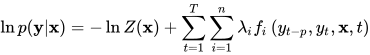
以中文分词为例,要建立条件随机场需要定义特征函数集。每个特征函数以整个句子x,当前位置i,位置i和i-1处的标签作为输入。模型训练完成之后,每一个特征函数有一个权重,对每一个标注序列l,对所有的特征函数加权求和,通过指数变换和归一化得到条件概率值。
推断算法
推断问题指给定模型的参数和观测序列x,计算条件随机场的各种概率值,分为两个问题。第一个推理问题是给定条件随机场的参数,以及观测序列x,找到条件概率最大的状态序列y,即求解如下极值问题
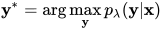
这类似于隐马尔可夫模型的解码问题。第二个问题是计算标签序列子集的边缘分布,如节点的边缘概率 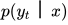 以及边的边缘概率
以及边的边缘概率 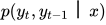 ,这些值将被训练算法使用。
,这些值将被训练算法使用。
首先考虑第二个问题。与隐马尔可夫模型面临的问题相同,如果直接计算 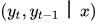 ,需要考虑状态序列除t和t-1时刻之外其他所有时刻所有可能的取值情况,计算量是指数级的。实现时采用递推计算的思路,定义函数
,需要考虑状态序列除t和t-1时刻之外其他所有时刻所有可能的取值情况,计算量是指数级的。实现时采用递推计算的思路,定义函数
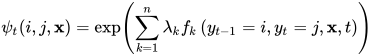
定义前向变量
![\alpha_{t}(i | \mathbf{x})=\sum_{\mathbf{y}_{[1,+1]}} \psi_{t}\left(y_{t-1}, i, \mathbf{x}\right) \prod_{t=1}^{t-1}\psi_{t}\left(y_{t-1}, y_{t}, \mathbf{x}\right)](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/6/13/16b4cc62e36fb882~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
它表示t时刻取值为i,1到t-1时刻取值任意的状态序列出现的概率。这里的求和符号表示对状态序列中1到t-1时刻所有可能的取值情况求和。求和项表示从1到t-1时刻按照某种取值,t时刻取值为i的状态序列的概率。前向变量的初始值为
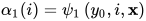
根据定义,前向变量满足下面的递推公式
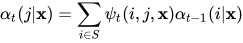
其中S为标记变量的取值集合。根据前向变量可以计算出归一化因子的值
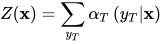
类似的定义后向变量
![\beta_{t}(i | \mathbf{x})=\sum_{\mathbf{y}_{[t+1, T]}} \psi_{t}\left(i, y_{t+1}, \mathbf{x}\right) \prod_{t=t+1}^{T}\psi_{i}\left(y_{i}, y_{t+1}, \mathbf{x}\right)](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/6/13/16b4cc62ea3181a1~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
它表示t时刻值为i,t+1到T时刻取值为任意的状态序列出现的概率。根据定义可以得到下面的递推公式
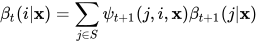
初始值为根据前向变量和后向变量可以方便的计算出下面的边缘概率值,根据前向变量、后向变量的定义有
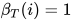
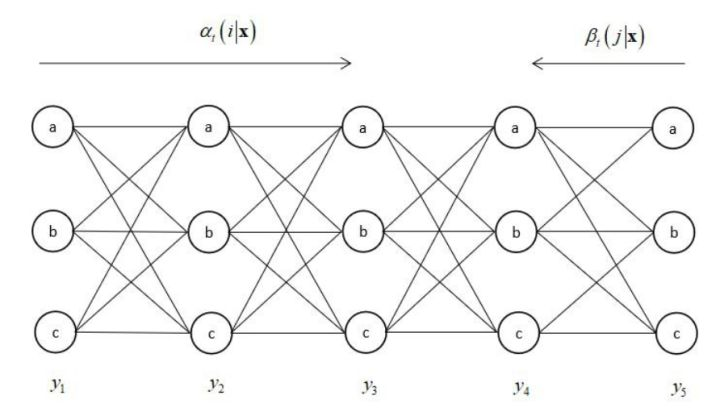
现时先计算各个时刻的前向变量和后向变量值,然后按照上面的公式计算出条件概率值。这一过程如下图所示
类似的有
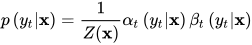
对于解码问题,定义变量下面的递推变量
![\delta_{t}(i | \mathbf{x})=\max _{\mathbf{y}_{[ 1,t-1]}} p\left(y_{1}, \ldots, y_{t-1}, y_{t}=i | \mathbf{x}\right)](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/6/13/16b4cc62e73d70ad~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
根据定义可以建立递推公式
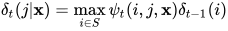
根据这一递推公式可以找到条件概率最大的标记序列。解码问题的最优解可以按照下面的公式计算
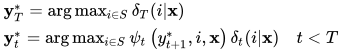
具体流程类似于求解隐马尔可夫模型解码问题的维特比算法,不再重复讲述。
训练算法
条件随机场在训练时确定参数λ的值。给定训练样本集D={?x\_{i}?,?y\_{i}?,i=1,...N,每个样本是由观测序列?x\_{i}?与状态序列?y\_{i}?构成的。训练时的目标是最大化此训练集的条件概率值,这通过最大似然估计实现。
训练算法采用最大似然估计,使得一组样本的条件概率的乘积最大化,求解下面的对数似然函数的极大值
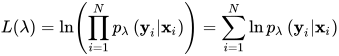
将条件概率的计算公式代入目标函数可以得到
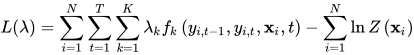
这个问题是凸优化问题(求凹函数的极大值,对于凸优化,SIGAI之前的公众号文章《理解凸优化》有详细的讲解),因此可以保证得到全局最优解。为防止过拟合,可以为目标函数加上正则化项。如果使用L2正则化项,目标函数为
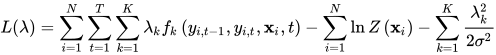
加上正则项后还是凸优化问题。σ为人工设定的常数。如果采用L1正则化项,目标函数为
α是人工设定的常数。如果使用L2正则化,目标函数对参数的偏导数为
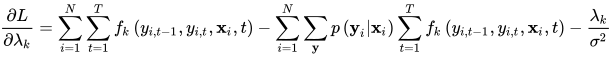
目标函数前半部分的导数容易计算,是λ的线性函数。下面计算lnZ(xi)的导数,根据链式法则有
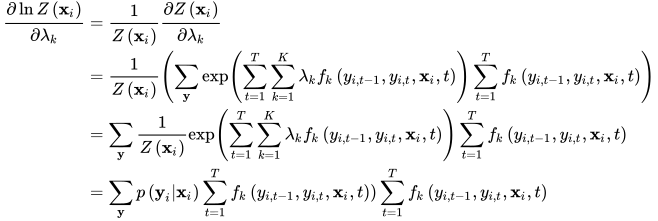
导数计算公式中的第一项是训练样本集对单个特征?f\_{k}?的数学期望
![\mathrm{E}_{1}\left[f_{k}\right]=\sum_{i=1}^{N} \sum_{t=1}^{T} f_{k}\left(y_{i, t-1}, y_{i, t}, \mathbf{x}_{i}, t\right)](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/6/13/16b4cc62e7bd2034~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
其值容易计算。第二项是训练样本集对条件随机场所定义的概率分布的数学期望
![\mathrm{E}_{2}\left[f_{k}\right]=\sum_{i=1}^{N} \sum_{\mathbf{y}} p\left(\mathbf{y}_{i} | \mathbf{x}_{i}\right) \sum_{t=1}^{T} f_{k}\left(y_{i, t-1}, y_{i, t}, \mathbf{x}_{i}, t\right)](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/6/13/16b4cc62ed98bbae~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
此值的计算要对标签序列y的所有取值情况进行求和,直接计算的成本太高,可以借助21.3节的算法高效的实现。利用之前定义的前向变量和后向变量,其计算公式为
![\mathrm{E}_{2}\left[f_{l}\right]=\sum_{i=1}^{N} \frac{1}{Z\left(\mathbf{x}_{i}\right)} \sum_{t=1}^{T} \sum_{j \in S, k \in S} f_{l}(j, k, \mathbf{x}, t) \alpha_{t}\left(j | \mathbf{x}_{i}\right) \psi_{t}\left(j, k, \mathbf{x}_{i}\right) \beta_{t+1}\left(k | \mathbf{x}_{i}\right)](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/6/13/16b4cc62eaff6585~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
实际应用中特征函数、观测值的取值数量可能非常大,梯度下降法、牛顿法求解速度太慢,一般采用L-BFGS算法,其原理在《机器学学习与应用》一书中有详细的讲解。
应用
条件随机场在很多序列标注问题上得到了应用。在自然语言处理中,被用于解决中文分词[3],词性标注[4]等问题。除了单独使用,还可以与深度神经网络如卷积神经网络、循环神经网络整合,完成图像分割、词性标注等任务。
参考文献
[1] Charles A Sutton, Andrew Mccallum. An Introduction to Conditional Random Fields. Machine Learning, 2012.
[2] John D Lafferty, Andrew Mccallum, Fernando Pereira. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. international conference on machine learning, 2001.
[3] Fuchun Peng, Fangfang Feng, Andrew Mccallum. Chinese segmentation and new word detection using conditional random fields. international conference on computational linguistics, 2004.
[4] Miikka Silfverberg, Teemu Ruokolainen, Krister Linden, Mikko Kurimo. Part-of-Speech Tagging using Conditional Random Fields: Exploiting Sub-Label Dependencies for Improved Accuracy. meeting of the association for computational linguistics, 2014.
