

概览
iOS 启动,会先在内存空间中开辟一块区域,然后将这块区域内部划分成如下部分。
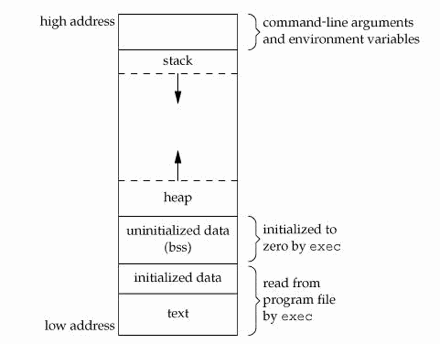
图中与我们相关性较大的是栈区和堆区。栈区一般是存放方法栈。堆区存放开发者创建的对象。通常我们说的内存管理,就是指的堆中的内存管理。
引用计数
iOS中采用引用计数的方式管理内存,每多一个强引用,引用计数就加一,销毁一个强引用,引用计数就减一。引用计数为0时,会触发dealloc方法,释放该对象。下面将要介绍的东西都是在引用技术基础上做的内存管理。
内存相关结构与操作
相关数据结构
引用计数涉及到的数据结构有isa指针,sidetables,sidetable,weaktable等。
isa指针中有几位是用来存储该对象被引用的次数的。但是因为位数有限,能表达的数量很有限,当不够表达时,isa中还有一位用来标记是否额外存储。如果标记是1,表示该对象的引用计数还存储在sidetables中。
sidetables由64个sidetable组成。通过hash算法定位。因为这些表是全局共享,会频繁的并发读写,如果只有一个表,多个线程同时操作时,要等很久。分表后可以大大减少多个线程同时操作一个表的情况,提高性能。
struct SideTable {
// 保证原子操作的自旋锁
spinlock_t slock;
// 引用计数的 hash 表
RefcountMap refcnts;
// weak 引用全局 hash 表
weak_table_t weak_table;
};
引用计数表以对象指针为key,以引用计数+两个标记位 为value。因为后两个标记位所以,当引用计数需要加减的时候,是从第三位开始。
weak表以对象指针为key,以引用地址的数组为key,没增加一个weak引用,就添加到这个数组中。
retain,relase等相关的操作都是针对这些结构的添加修改删除。
操作
retainCount
retainCount比较简单,根据对象地址找到sidetable,然后继续在RefCountmap中找到计数并返回
uintptr_t
objc_object::sidetable_retainCount()
{
SideTable& table = SideTables()[this];
size_t refcnt_result = 1;
table.lock();
RefcountMap::iterator it = table.refcnts.find(this);
if (it != table.refcnts.end()) {
// this is valid for SIDE_TABLE_RC_PINNED too
refcnt_result += it->second >> SIDE_TABLE_RC_SHIFT;
}
table.unlock();
return refcnt_result;
}
retain retain操作会对引用计数加1
id
objc_object::sidetable_retain()
{
#if SUPPORT_NONPOINTER_ISA
assert(!isa.nonpointer);
#endif
SideTable& table = SideTables()[this];
table.lock();
size_t& refcntStorage = table.refcnts[this];
if (! (refcntStorage & SIDE_TABLE_RC_PINNED)) {
refcntStorage += SIDE_TABLE_RC_ONE;
}
table.unlock();
return (id)this;
}
release 自动引用减一,减到0,会调用SEL_dealloc,触发dealloc。
uintptr_t
objc_object::sidetable_release(bool performDealloc)
{
#if SUPPORT_NONPOINTER_ISA
assert(!isa.nonpointer);
#endif
SideTable& table = SideTables()[this];
bool do_dealloc = false;
table.lock();
RefcountMap::iterator it = table.refcnts.find(this);
if (it == table.refcnts.end()) {
do_dealloc = true;
table.refcnts[this] = SIDE_TABLE_DEALLOCATING;
} else if (it->second < SIDE_TABLE_DEALLOCATING) {
// SIDE_TABLE_WEAKLY_REFERENCED may be set. Don't change it.
do_dealloc = true;
it->second |= SIDE_TABLE_DEALLOCATING;
} else if (! (it->second & SIDE_TABLE_RC_PINNED)) {
it->second -= SIDE_TABLE_RC_ONE;
}
table.unlock();
if (do_dealloc && performDealloc) {
((void(*)(objc_object *, SEL))objc_msgSend)(this, SEL_dealloc);
}
return do_dealloc;
}
dealloc 注释有说明,如果没有额外处理,就直接free,不然先通过object_dispose处理若引用,关联属性等
inline void
objc_object::rootDealloc()
{
assert(!UseGC);
if (isTaggedPointer()) return;
//指针型isa && 没被弱引用&&没有关联属性&&没有c++创建&&没有用引用计数表
if (isa.indexed &&
!isa.weakly_referenced &&
!isa.has_assoc &&
!isa.has_cxx_dtor &&
!isa.has_sidetable_rc)
{
assert(!sidetable_present());
//直接释放
free(this);
}
else {
object_dispose((id)this);
}
}
dispose会调用destructInstance,这个方法如下,注释有说明
void *objc_destructInstance(id obj)
{
if (obj) {
// Read all of the flags at once for performance.
bool cxx = obj->hasCxxDtor();
bool assoc = !UseGC && obj->hasAssociatedObjects();
bool dealloc = !UseGC;
// This order is important.
//调用c++的销毁方法
if (cxx) object_cxxDestruct(obj);
//移除关联属性
if (assoc) _object_remove_assocations(obj);
//清理引用计数表和weak表
if (dealloc) obj->clearDeallocating();
}
return obj;
}
下面是clearDeallocating,主要是处理引用计数表和弱引用表
inline void
objc_object::clearDeallocating()
{
if (!isa.indexed) {
// Slow path for raw pointer isa.
//清理引用计数表
sidetable_clearDeallocating();
}
else if (isa.weakly_referenced || isa.has_sidetable_rc) {
// Slow path for non-pointer isa with weak refs and/or side table data.
clearDeallocating_slow();
}
assert(!sidetable_present());
}
autoreleasepool
大体思路
autoreleasepool通过AutoreleasePoolPage管理对象,每个线程有一个page,存储在TLS中。page内部以栈的方式组织,大小位4096字节,对应操作系统的内存页。每次添加对象就通过page的压栈存入,存满会创建一个新的page继续存储,page与page通过链表的方式存储。push操作会将一个哨兵(nil)压栈,并返回这个位置的地址。pop会查找这个地址,将栈顶到该位置的对象都release。多次的autoreleasepool,会有多个push,记录多个哨兵的位置,然后pop时pop到对应的位置。
autoreleasepool的实现
我们通常使用自动释放池就是使用@autoreleasepool{},这个block对应一个结构体
struct __AtAutoreleasePool {
__AtAutoreleasePool() {atautoreleasepoolobj = objc_autoreleasePoolPush();}
~__AtAutoreleasePool() {objc_autoreleasePoolPop(atautoreleasepoolobj);}
void * atautoreleasepoolobj;
};
这个结构题会在初始化的时候调用objc_autoreleasePoolPush,在析构时调用objc_autoreleasePoolPop。
我们在objc源码中找到这两个方法。
void *
objc_autoreleasePoolPush(void)
{
if (UseGC) return nil;
return AutoreleasePoolPage::push();
}
void
objc_autoreleasePoolPop(void *ctxt)
{
if (UseGC) return;
AutoreleasePoolPage::pop(ctxt);
}
这两个方法是AutoreleasePoolPage这个类来实现的。
直接从这两个方法看起
//添加哨兵POOL_SENTINEL(值为nil),处理page,返回哨兵对象的地址。
static inline void *push()
{
id *dest;
if (DebugPoolAllocation) {
// Each autorelease pool starts on a new pool page.
dest = autoreleaseNewPage(POOL_SENTINEL);
} else {
dest = autoreleaseFast(POOL_SENTINEL);
}
assert(*dest == POOL_SENTINEL);
return dest;
}
下面看下怎么处理的poolpage
static inline id *autoreleaseFast(id obj)
{
AutoreleasePoolPage *page = hotPage();
if (page && !page->full()) {
return page->add(obj);
} else if (page) {
return autoreleaseFullPage(obj, page);
} else {
return autoreleaseNoPage(obj);
}
}
拿到当前page,如果能拿到并且,page没有存满,就将obj存入 如果page是满的,就走autoreleaseFullPage 如果没拿到page,走autoreleaseNoPage方法
接着看下hotPage()是怎么处理的。
static inline AutoreleasePoolPage *hotPage()
{
AutoreleasePoolPage *result = (AutoreleasePoolPage *)
tls_get_direct(key);
if (result) result->fastcheck();
return result;
}
这个page是放到线程的存储空间的,所以poolpage是线程相关的,一个线程,一个page链。
没有page时,第一次创建成功会将hotpage存起来,会存到线程中。
static inline void setHotPage(AutoreleasePoolPage *page)
{
if (page) page->fastcheck();
tls_set_direct(key, (void *)page);
}
至此push就差不多了,总结下push都干了什么
- 从线程的存储空间中拿到当前页(hotpage),没有的话,就创建一个放进去
- 查看page有没有满,没满就将传入的哨兵存入。
- page满了,向链中寻找最后一个节点,创建一个新的page,parent设置为这个节点,将这个节点设置为hotpage。
接下来看看pop
static inline void pop(void *token)
{
AutoreleasePoolPage *page;
id *stop;
//token是一个地址,要pop到这个地址为止。
//找到这个地址所在的page
page = pageForPointer(token);
stop = (id *)token;
//释放对象到指定的地址
page->releaseUntil(stop);
//移除空的page
// memory: delete empty children
if (DebugPoolAllocation && page->empty()) {
// special case: delete everything during page-per-pool debugging
AutoreleasePoolPage *parent = page->parent;
page->kill();
//重置hotpage
setHotPage(parent);
} else if (DebugMissingPools && page->empty() && !page->parent) {
// special case: delete everything for pop(top)
// when debugging missing autorelease pools
//删光了,就没了
page->kill();
setHotPage(nil);
}
else if (page->child) {
//如果当前page已经用了超过一半了,就保留一个空的page
// hysteresis: keep one empty child if page is more than half full
if (page->lessThanHalfFull()) {
page->child->kill();
}
else if (page->child->child) {
page->child->child->kill();
}
}
}
pop操作和push是成对操作,push操作记录的位置,接下来会用来pop。
runtime对autorelease返回值的优化
问题1:为什么要做这个优化?
答: 当返回值被返回之后,紧接着就需要被 retain 的时候,没有必要进行 autorelease + retain,直接什么都不要做就好了。
问题2:如何做的优化?
基本思路:
在返回值身上调用objc_autoreleaseReturnValue方法时,runtime在TLS中做一个标记,然后直接返回这个object(不调用autorelease);同时,在外部接收这个返回值的objc_retainAutoreleasedReturnValue里,发现TLS中有标记,那么直接返回这个object(不调用retain)。
于是乎,调用方和被调方利用TLS做中转,很有默契的免去了对返回值的内存管理。
具体做法:
优化主要是通过两个方法进行实现objc_autoreleaseReturnValue和objc_retainAutoreleasedReturnValue
看第一个方法前,先看个枚举
enum ReturnDisposition : bool {
ReturnAtPlus0 = false, ReturnAtPlus1 = true
};
objc_autoreleaseReturnValue
方法的实现如下,通过注释进行了解释
// Prepare a value at +1 for return through a +0 autoreleasing convention.
id objc_autoreleaseReturnValue(id obj)
{
//可被优化的场景下,直接返回obj
if (prepareOptimizedReturn(ReturnAtPlus1)) return obj;
//否则还是使用autorelease
return objc_autorelease(obj);
}
对可优化场景的判断,在prepareOptimizedReturn方法中,参数我们根据上边的枚举已经得知
ReturnAtPlus1是true,看下这个方法的实现,用注释做了说明。
static ALWAYS_INLINE bool
prepareOptimizedReturn(ReturnDisposition disposition)
{
//如果调用方符合优化条件,就返回true,表示这次调用可以被优化
if (callerAcceptsOptimizedReturn(__builtin_return_address(0))) {
//设置dispostion,为后续的objc_retainAutoreleasedReturnValue准备
if (disposition) setReturnDisposition(disposition);
return true;
}
//不符合条件,不做优化
return false;
}
setReturnDisposition是在TLS中存入标记,后续的objc_retainAutoreleasedReturnValue会从TLS中读取来判断,之前是否已经做过了优化。这里比较复杂的方法是callerAcceptsOptimizedReturn判断调用方是否接受一个优化的结果。方法的实现比较难以理解,但是注释说明的比较清楚。
Callee looks for
mov rax, rdifollowed by a call or jump instruction to objc_retainAutoreleasedReturnValue or objc_unsafeClaimAutoreleasedReturnValue.
接收方为上述的两种情况时,调用方就符合优化条件。这个条件其实是判断,是否MRC和ARC混编,如果调用方和被调方一个使用MRC一个使用ARC,就不能做这个优化了。
objc_retainAutoreleasedReturnValue
这个方法相对简单,就是判断之前是否已经做了优化(通过TLS中的RETURN_DISPOSITION_KEY)
// Accept a value returned through a +0 autoreleasing convention for use at +1.
id objc_retainAutoreleasedReturnValue(id obj)
{ //从TLS中获取RETURN_DISPOSITION_KEY对应的值,为true,就直接返回obj。
//读取完之后,重置为false
if (acceptOptimizedReturn() == ReturnAtPlus1) return obj;
//没有优化,就走正常的retain流程
return objc_retain(obj);
}
这两个方法成对使用,就可以省去将对象添加到autoreleasepool中的操作。
一个对象的内存布局
内存分配
alloc init分别做了些什么事?
一个类的alloc方法,会向堆申请一块区域,用来存储对象中的变量。接下来看看对象中的变量组成。
OC类会被转成struct来表示,一个NSObject转成struct是下面这个样子
struct NSObject_IMPL {
Class isa;
};
typedef struct objc_class *Class;
Class是一个别名,它其实是 object_class指针。
一个自定义类的表示如下:
@interface Student : NSObject{
@public
int _no;
int _age;
}
@end
struct Student_IMPL {
struct NSObject_IMPL NSObject_IVARS;
int _no;
int _age;
};
所以子类的实例变量中的第一个是父类struct表示。那么一个类分配的内存,是父类变量的内存,加上本类变量需要的内存。最顶部的NSObject中只有一个isa指针,而指针的大小与操作系统的位数有关,64位,指针也是64位,8个字节。32位,指针也是32位,4个字节。以64位系统为例,NSObject的对象会占用8个字节。Student会占用16个字节。
内存对齐
一个对象占用的内存,并不是所有变量相加出来的结果。中间会有一些空位补0,来对齐。目的是为了提高内存的访问效率以及平台移植。
struct StructOne {
char a; //1字节
double b; //8字节
int c; //4字节
short d; //2字节
} MyStruct1;
struct StructTwo {
double b; //8字节
char a; //1字节
short d; //2字节
int c; //4字节
} MyStruct2;
NSLog(@"%lu---%lu--", sizeof(MyStruct1), sizeof(MyStruct2));
//24,16
两个结构体中的组成一样,内存占用却不一样。先看下原则
内存对齐原则:
- 对于结构体的各个成员,第一个成员的偏移量是0,排列在后面的成员其当前偏移量必须是当前成员类型的整数倍
- 结构体内所有数据成员各自内存对齐后,结构体本身还要进行一次内存对齐,保证整个结构体占用内存大小是结构体内最大数据成员的最小整数倍
- 如程序中有#pragma pack(n)预编译指令,则所有成员对齐以n字节为准(即偏移量是n的整数倍),不再考虑当前类型以及最大结构体内类型
在不设置pragma pack的情况下,我们用前两条原则,对上面两个结构体进行分析。 StructOne
- a字段从0起,占一个字节,offset1
- b字段不能从2起,按照原则1,要从8开始,占8个字节,offset 16
- c字段从16起,没有问题,占4个字节,offset 20
- d字段从20起,没有问题,占2个字节,offset 22
- 根据原则2,structOne的占位应该是double类型的整数倍,22最近的8的倍数,即24。
补充: NSNumber,NSDate 使用taggedPointer技术,将指针与值保存在一起。看似对象,其实是基础类型。存在栈中,不会放到堆上。
参考文档:
