

主从搭建
首先需要准备两台MySQL实例,可以通过虚拟机,新建两台MySQL服务器,可以参考我之前的文章
配置my.cnf文件
# 主库上的my.cnf配置
log_bin=mysql_bin
server_id=1
# 从库上的my.cnf配置
log_bin=mysql_bin
server_id=2
relay_log=/var/lib/mysql/mysql-relay-bin
log_slave_update=1
read_only=1
上述的配置中,只有
server_id是必须的,其余可以选择添加
server_id必须是唯一的log_bin用于配置bin log文件名relay_log指定中转日志的位置与名称log_slave_update表示从库将从主库发过来的bin log记录在从库的bin logread_only配置从库只读(对root账户无效)
告诉从库如何连接到主库
通过
change master to语句设置
change master to master_host='#{master_host}',
master_user='#{master_user_name}',
master_password='#{master_user_password}',
master_log_file='#{bin_log_filename}',
master_log_pos=#{log_pos};
上述命令指定了主库的地址,用户名和密码,同时也指明了,同步bin log的时候,要从那个bin log文件的那个位置开始同步
- 想要查看主库上有啥
bin log文件,可以通过'show master status'命令- 想要查看
bin log文件中的内容,可以通过show binlog events [IN 'log_name'] [FROM pos] [LIMIT [offset,] row_count]命令
启动从库
通过start slave命令启动主从同步
检查主从同步状态
通过命令show slave status检查主从同步情况
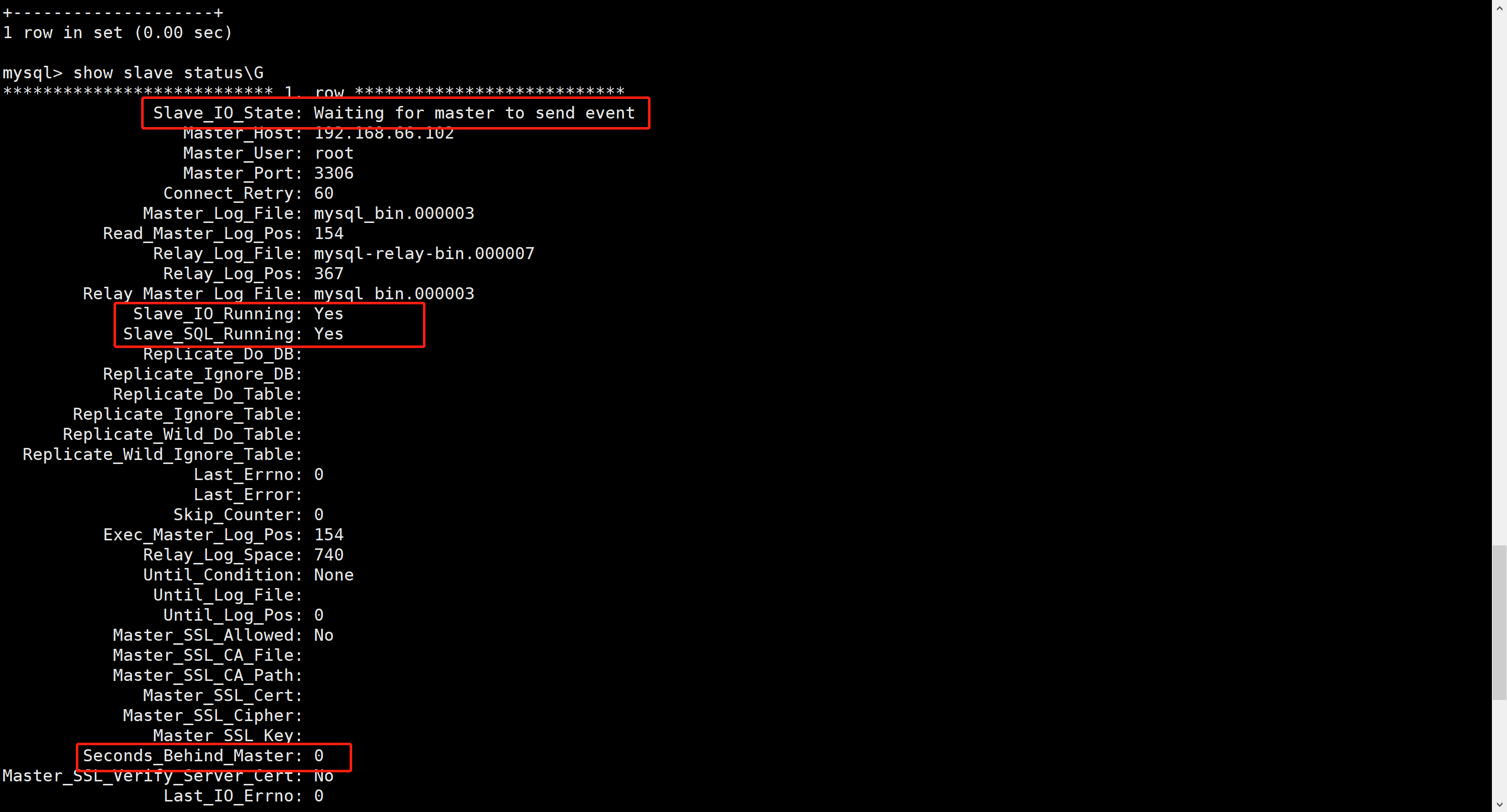
seconds_behind_master是指从库跟主库的延迟slave_io_running表示从库接收主库bin log的IO线程的状态slave_sql_running表示从库执行主库bin log的SQL线程的状态
主从同步执行流程
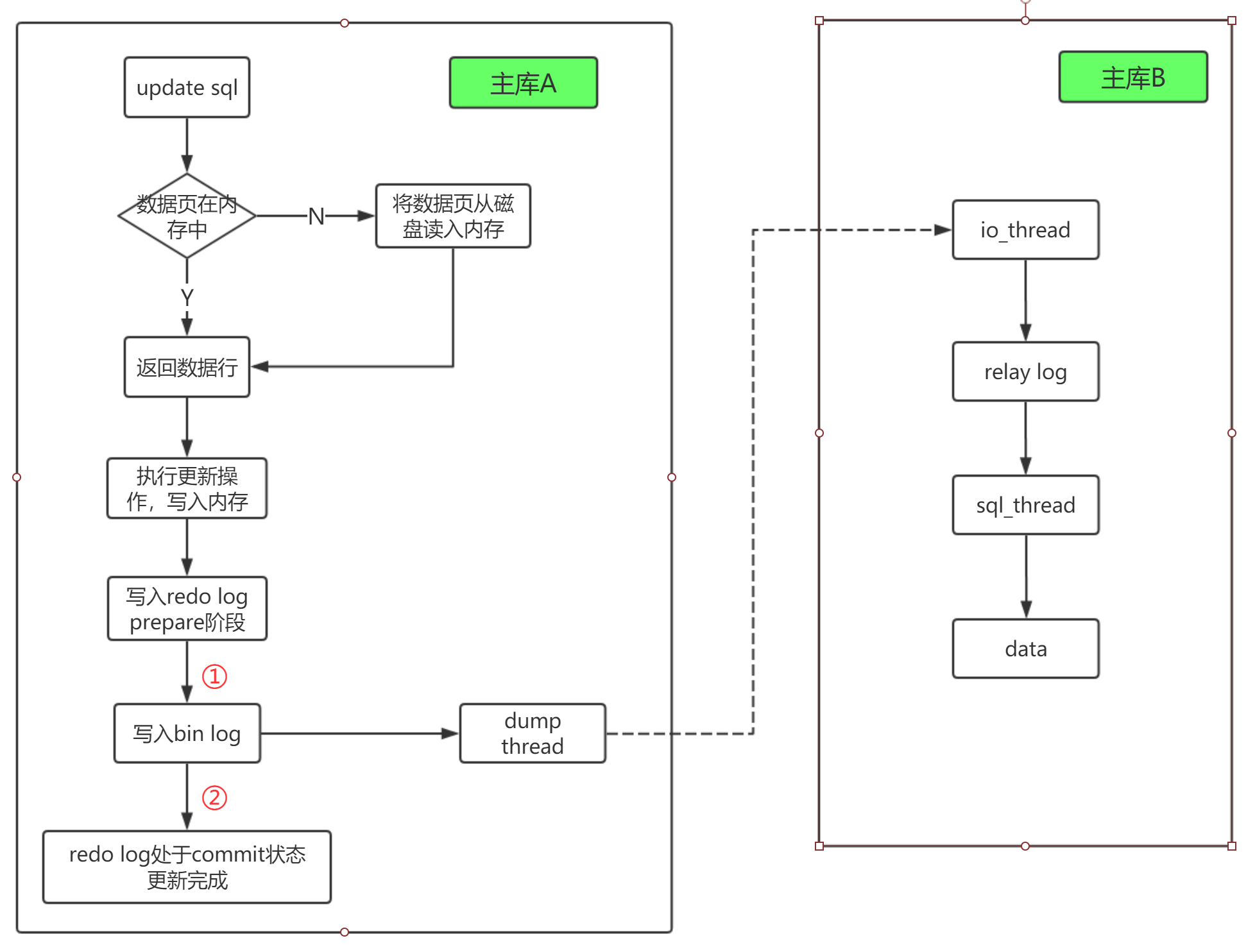
从库和主库之间维持一个长连接,在主库内部有个线程,专门服务于从库的长连接
bin log的同步过程
- 在从库上通过
change master的命令,设置主库的IP、端口、用户名、密码以及要同步bin log的文件名和起始点 - 在从库上执行start slave命令,此时从库启动两条线程,
io_thread和sql_thread,io_thread负责与主库建立连接 - 主库校验完用户名密码后,根据从库的要求,选择对应的
bin log,从指定的起始位置读取big log发送给从库 - 从库接收到
bin log之后,通过io_thread转为relay log(中转日志) sql_thread读取relay log并执行
bin log的三种格式
statement格式
statement格式的bin log记录的是SQL的原文(逻辑记录)
row格式
row格式的bin log记录的是真正修改的行的主键ID以及其他的字段信息(物理记录)
mixed格式
row格式 + statement格式
使用mixed格式的bin log的时候,MySQL会判断SQL是否可能会引起主备不一致,如果可能,则使用row,否则使用statement
mixed格式可以兼具statement格式和row格式的优点
statement格式和row格式的比较
- 使用statement格式可能存在主从不一致的风险
- row格式的bin log占用空间大
主从同步延迟分析
在从库上执行
show slave status命令,可以查询sends_behind_master,表示当前从库延迟了多少秒
senconds_behind_master的计算方式
通过bin log上记录的时间(在主库执行)减去从库取出bin log执行事务的时间,两者的差值即为senconds_behind_master
当主库和从库的的系统时间设置不一致的时候,从库在计算senconds_behind_master的时候会自动扣掉系统时间产生的差值
主从延迟的最直接表现是,从库消费relay log的速度比主库生产bin log的速度要慢
主从延迟的原因
- 从库所在机器的性能要比主库所在机器的性能差
- 从库压力大,查询耗费大量CPU资源,影响同步速度(最常见,接触的比较多)
- 主库存在大事务,或大表DDL(最常见,接触的比较多)
- 从库的并行复制能力较弱,导致主从延迟
主从切换策略
可靠性优先策略
- 当从库
seconds_behind_master小于某个值的时候,将主库设置成只读,直到从库的seconds_behind_master变成0 - 将从库改成可读写状态,设置readonly = false,将业务写请求转移到从库(新的主库)
可用性优先策略
- 不等主从数据完全同步,就直接进行主从切换
- 可能会出现数据不一致的问题
双M结构的循环复制问题
双M结构是指数据库A、B总是互为主从关系
A生成的big log发送给B
B通过sql_thread执行完relay log后得到数据,同时生成bin log
如果此时进行主从切换,A作为B的从库,那么B生成的bin log会再次发送给A
那么在A、B之间会不断地循环执行bin log
MySQL在bin log中记录了第一次执行时所在实例的server id来解决循环复制问题
- 主库从库的
server id必须是不同的,否则不能设定为主从 - 从库接收到来自主库的
bin log后,生成的bin log中的server id与原bin log中的server id一致 - 每个库在收到从自己主库发送过来的
bin log后,先判断server id,如果相同,则表示bin log是自己生成的,那么会直接丢弃这个bin log
从库并行复制策略
在MySQL5.6版本以前,MySQL只支持单线程复制,在主库高并发的情况下,会出现主从延迟严重的问题
单线程复制是指从库
sql_thread执行relay log生成数据的过程是单线程的
从库并行复制的流程
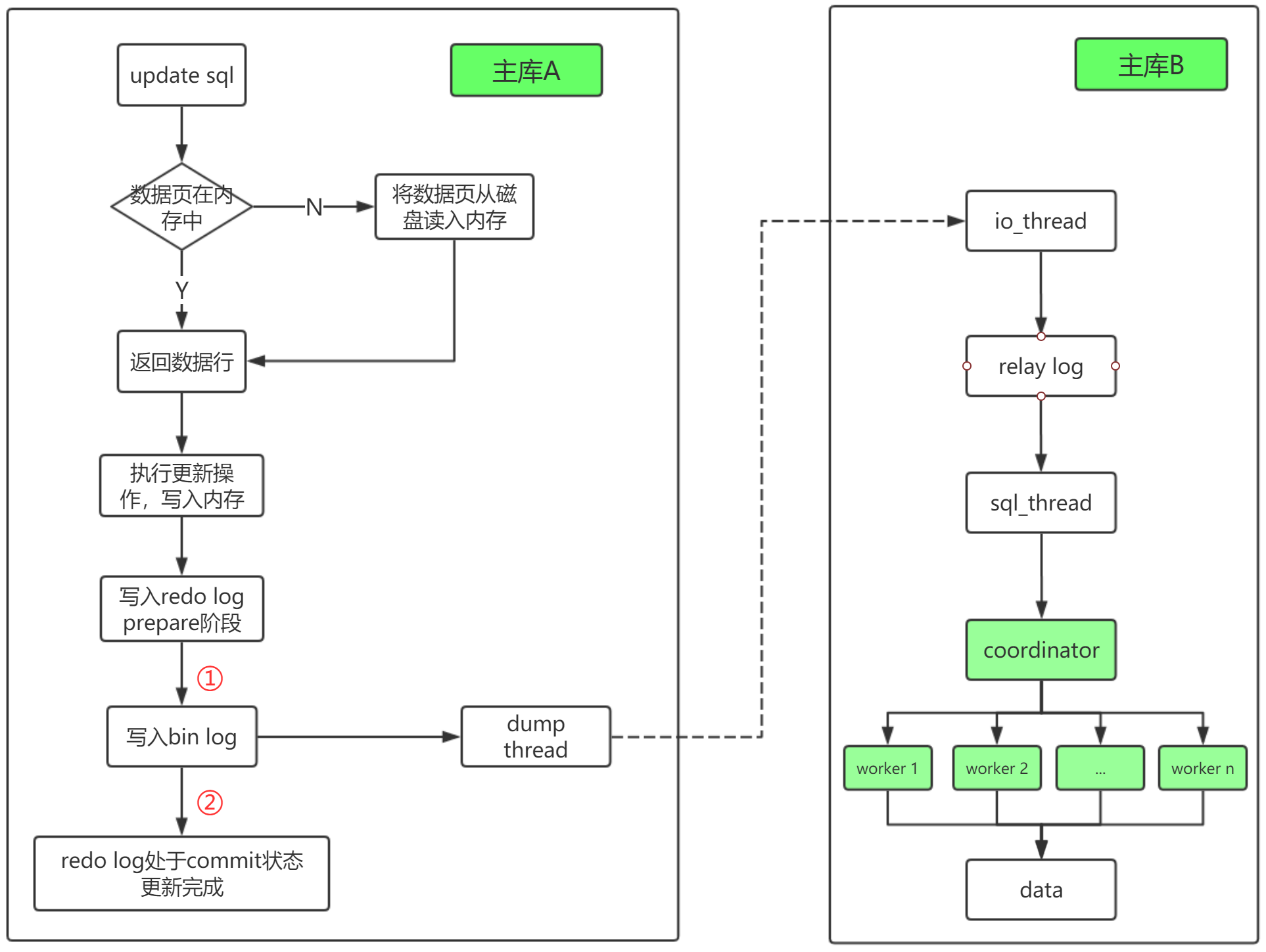
coordinator就是原来的sql_thread,但是它不再直接更新数据,只负责读取relay log和分发事务- 真正更新日志的,是worker线程,worker线程的数量通过参数
slave_parallel_workers决定 corrdinator在分发事务的时候需要满足两个基本要求- 不能造成更新覆盖,要求更新同一行的两个事务必须被分发到同一个worker中
- 同一个事务不能被拆开,必须放到同一个worker中
并行复制的策略
按库分发策略
MySQL5.6版本的并行复制策略
不要求bin log格式为statement
按表分发策略
如果两个事务更新不同的表,它们可以并行
每个事务在分发的时候,跟所有worker的冲突关系包括三种情况:
- 跟所有worker都不冲突,coordinator线程会把事务分配给最空闲的worker
- 跟多个worker冲突,coordinator线程会进入等待状态,直到和这个事务存在冲突关系的worker只剩下一个
- 只跟一个worker有冲突,coordinator线程会把事务分配给这个存在冲突关系的worker
按表分发策略在多表负载均衡的场景里应用效果很好,但是碰到热点表,所有的更新事务都涉及某一个表的时候,所有事务都会被分配到同一个worker中,此时就变成了单线程复制
按行分发策略
可以解决热点表的并行复制问题
- 如果两个事务没有更新相同的行,它们在备库上可以并行执行,此时要求
bin log的格式必须是row - 基于行的分发策略需要考虑唯一索引的问题
- 按行分发策略在决定线程分发的时候,需要消耗更多的计算资源
