

基础知识
监督学习
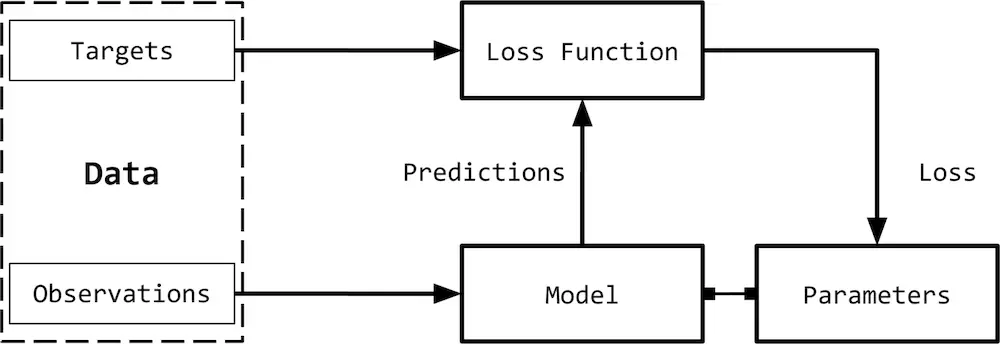
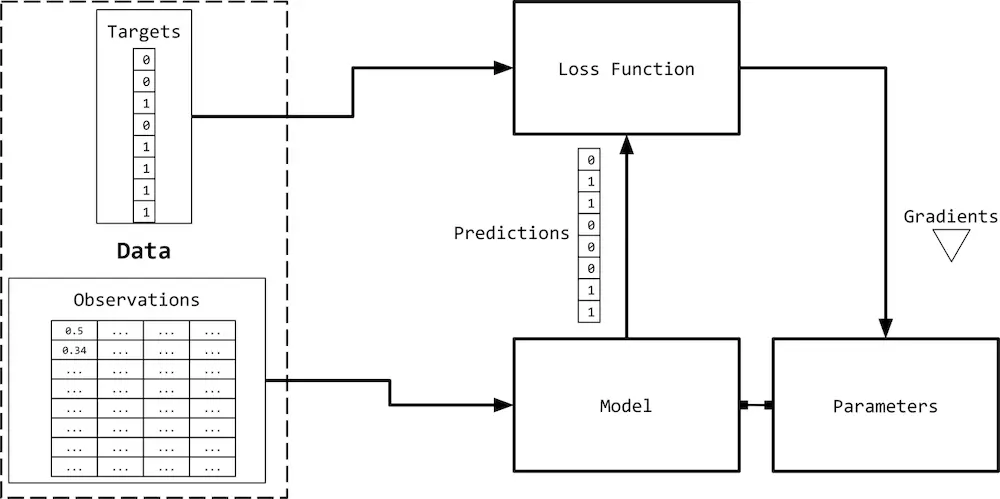
one-hot representation
词语表示
该单词对应所在元素为1,向量中其他元素均为0,向量的维度就等于词库中的单词数目

- 所有向量都是互相正交的,我们无法有效的表示两个向量间的相似度
- 向量维度过大。
词袋模型
词袋模型(Bag of Words,简称BoW)。词袋模型假设我们不考虑文本中词与词之间的上下文关系,仅仅只考虑所有词的权重。而权重与词在文本中出现的频率有关。
词袋模型首先会进行分词,在分词之后,通过统计每个词在文本中出现的次数,我们就可以得到该文本基于词的特征,如果将各个文本样本的这些词与对应的词频放在一起,就是我们常说的向量化。向量化完毕后一般也会使用TF-IDF进行特征的权重修正,再将特征进行标准化。 再进行一些其他的特征工程后,就可以将数据带入机器学习算法进行分类聚类了。
总结下词袋模型的三部曲:分词(tokenizing),统计修订词特征值(counting)与标准化(normalizing)。
与词袋模型非常类似的一个模型是词集模型(Set of Words,简称SoW),和词袋模型唯一的不同是它仅仅考虑词是否在文本中出现,而不考虑词频。也就是一个词在文本在文本中出现1次和多次特征处理是一样的。在大多数时候,我们使用词袋模型,后面的讨论也是以词袋模型为主。
当然,词袋模型有很大的局限性,因为它仅仅考虑了词频,没有考虑上下文的关系,因此会丢失一部分文本的语义。但是大多数时候,如果我们的目的是分类聚类,则词袋模型表现的很好。
下面使用sklearn的CountVectorizer分别实现词集模型和词袋模型。
词集模型代码
from sklearn.feature_extraction.text import CountVectorizer
import seaborn as sns
import matplotlib.pyplot as plt
corpus = ['Time flies flies like an arrow.',
'Fruit flies like a banana.']
vocab = set([word for sen in corpus for word in sen.split(" ")])
one_hot_vectorizer = CountVectorizer(binary=True)
one_hot = one_hot_vectorizer.fit_transform(corpus).toarray()
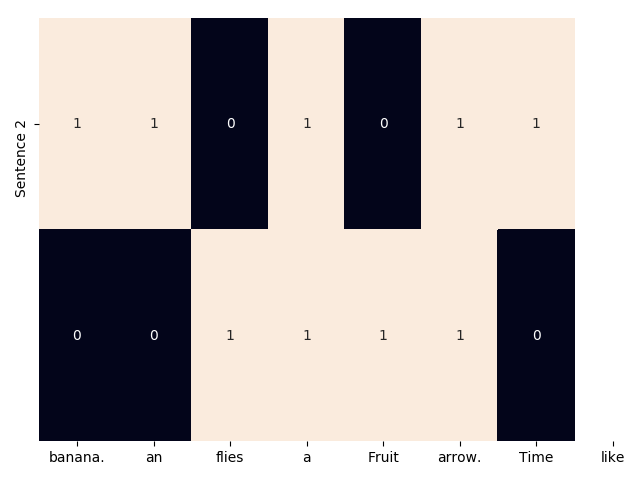
print(one_hot_vectorizer.vocabulary_)
print(one_hot)
sns.heatmap(one_hot, annot=True,cbar=False, xticklabels=vocab, yticklabels=['Sentence 2'])
plt.show()
输出结果:
{'time': 6, 'flies': 3, 'like': 5, 'an': 0, 'arrow': 1, 'fruit': 4, 'banana': 2}
[[1 1 0 1 0 1 1]
[0 0 1 1 1 1 0]]
词袋模型代码
如果设置为False,那么还会包含进词频信息,这就是词袋模型。输出如下:
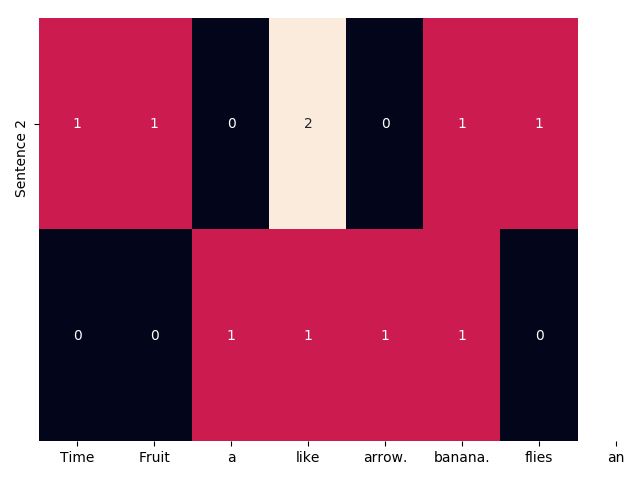
{'time': 6, 'flies': 3, 'like': 5, 'an': 0, 'arrow': 1, 'fruit': 4, 'banana': 2}
[[1 1 0 2 0 1 1]
[0 0 1 1 1 1 0]]
Hash Trick
在大规模的文本处理中,由于特征的维度对应分词词汇表的大小,所以维度可能非常恐怖,此时需要进行降维,不能直接用向量化方法。而最常用的文本降维方法是Hash Trick。
Hash Trick降维后的特征我们已经不知道它代表的特征名字和意义,所以Hash Trick的解释性不强。
TF-IDF
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF是词频(Term Frequency) 词频(TF)表示词条(关键字)在文本中出现的频率。这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。
IDF是逆向文件频率(Inverse Document Frequency) 逆向文件频率 (IDF) :总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。罕见词的IDF很高,高频词的IDF很低。
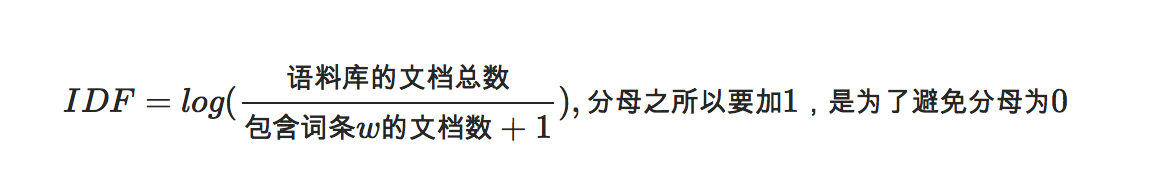
TF-IDF实际上是:TF * IDF
应用
- 关键字:计算出文章中每个词的TF-IDF值之后,进行排序,选取其中值最高的几个作为关键字。
- 文章的相似性: 计算出每篇文章的关键词,从中各选取相同个数的关键词,合并成一个集合,计算每篇文章对于这个集合中的词的词频,生成两篇文章各自的词频向量,进而通过欧氏距离或余弦距离求出两个向量的余弦相似度,值越大就表示越相似。
使用sklearn计算tfidf
from sklearn.feature_extraction.text import CountVectorizer,TfidfTransformer,TfidfVectorizer
from pprint import pprint
import seaborn as sns
from matplotlib.pylab import plt
corpus = ['Time flies flies like an arrow.',
'Fruit flies like a banana.']
one_hot_vectorizer = CountVectorizer()
one_hot = one_hot_vectorizer.fit_transform(corpus).toarray()
pprint(one_hot) #输出词频
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(one_hot)
vocab = one_hot_vectorizer.get_feature_names()
print(vocab) #打印词典
pprint(transformer.idf_ ) #输出逆文档频率
pprint(tfidf.toarray()) #输出TFIDF
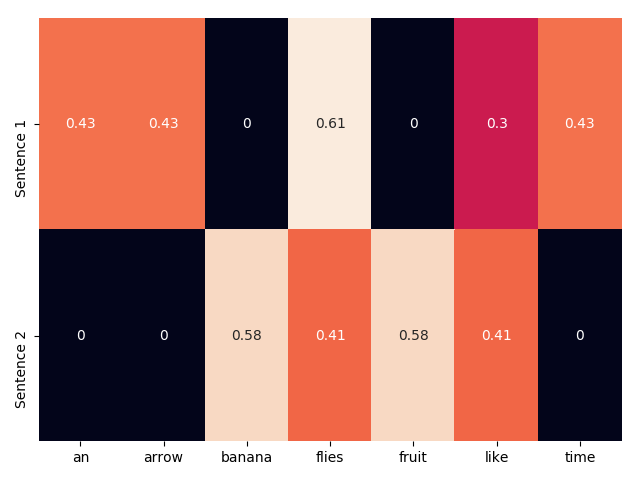
sns.heatmap(tfidf.toarray(), annot=True, cbar=False, xticklabels=vocab,
yticklabels= ['Sentence 1', 'Sentence 2'])
plt.show()
输出如下:
array([[1, 1, 0, 2, 0, 1, 1],
[0, 0, 1, 1, 1, 1, 0]], dtype=int64)
['an', 'arrow', 'banana', 'flies', 'fruit', 'like', 'time']
array([1.40546511, 1.40546511, 1.40546511, 1. , 1.40546511,
1. , 1.40546511])
array([[0.42519636, 0.42519636, 0. , 0.60506143, 0. ,
0.30253071, 0.42519636],
[0. , 0. , 0.57615236, 0.40993715, 0.57615236,
0.40993715, 0. ]])
简单验证
取文档1的词频表示为TF,计算IDF的公式是
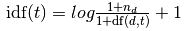
import numpy as np
tf = np.array([1, 1, 0, 2, 0, 1, 1])
x = np.array([1, 1, 1, 2, 1, 2, 1])
idf = np.log(3/(1+x))+1
print(idf)
tfidf = tf * idf
print(tfidf / np.linalg.norm(tfidf))
输出如下:
[1.40546511 1.40546511 1.40546511 1. 1.40546511 1.
1.40546511]
[0.42519636 0.42519636 0. 0.60506143 0. 0.30253071
0.42519636]
实际使用的时候也可以一步到位:
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf2 = TfidfVectorizer()
result = tfidf2.fit_transform(corpus)
print(result)
几个问题
- 为什么idf的大小总是有限的?
- 出现在所有文档中的词项的idf值是多少?
- 词项的tfidf权重能否超过1?
- idf的对数底数会对tfidf有什么影响?
- 假设idf以2为底,给出idf的一个简单近似。
向量空间模型(VSM)
使用TF-IDF可以把文档表示成向量,其中每个分量表示一个词项,但是这种表示忽略了词语的相对顺序。把不同的文档用向量表示称为向量空间模型。 然后文档相似度可以用余弦相似度表示出来:
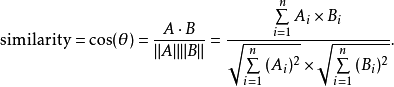
- 欧式距离
- 曼哈顿距离
Topk相似度计算和优化
主题模型
在传统信息检索领域里,实际上已经有了很多衡量文档相似性的方法,比如经典的VSM模型。然而这些方法往往基于一个基本假设:文档之间重复的词语越多越可能相似。这一点在实际中并不尽然。很多时候相关程度取决于背后的语义联系,而非表面的词语重复。 举个例子: 设有两个句子,我们想知道它们之间是否相关联:
第一个是:“乔布斯离我们而去了。”
第二个是:“苹果价格会不会降?”
这两个句子之间虽然没有任何公共词语,但仍然是很相关的。
主题模型,顾名思义,就是对文字中隐含主题的一种建模方法。主题就是词汇表上词语的条件概率分布 。与主题关系越密切的词语,它的条件概率越大,反之则越小。
主题模型就是用大量已知的“词语-文档”矩阵 ,通过一系列的训练,推理出右边的“词语-主题”矩阵Φ 和“主题-文档”矩阵Θ 。
主题模型的优点:
1)它可以衡量文档之间的语义相似性。对于一篇文档,我们求出来的主题分布可以看作是对它的一个抽象表示。对于概率分布,我们可以通过一些距离公式(比如KL距离)来计算出两篇文档的语义距离,从而得到它们之间的相似度。
2)它可以解决多义词的问题。回想最开始的例子,“苹果”可能是水果,也可能指苹果公司。通过我们求出来的“词语-主题”概率分布,我们就可以知道“苹果”都属于哪些主题,就可以通过主题的匹配来计算它与其他文字之间的相似度。
3)它可以排除文档中噪音的影响。一般来说,文档中的噪音往往处于次要主题中,我们可以把它们忽略掉,只保持文档中最主要的主题。
4)它是无监督的,完全自动化的。我们只需要提供训练文档,它就可以自动训练出各种概率,无需任何人工标注过程
5)它是跟语言无关的。任何语言只要能够对它进行分词,就可以进行训练,得到它的主题分布。
主题模型训练推理的方法主要有两种,一个是pLSA(Probabilistic Latent Semantic Analysis),另一个是LDA(Latent Dirichlet Allocation)。pLSA主要使用的是EM(期望最大化)算法;LDA采用的是Gibbs sampling方法。
pLSA
pLSA采用的方法叫做EM(期望最大化)算法,它包含两个不断迭代的过程:E(期望)过程和M(最大化)过程。
LDA
LDA 采用词袋模型。所谓词袋模型,是将一篇文档,我们仅考虑一个词汇是否出现,而不考虑其出现的顺序。在词袋模型中,“我喜欢你”和“你喜欢我”是等价的。与词袋模型相反的一个模型是n-gram,n-gram考虑了词汇出现的先后顺序。 LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,即认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
SVD
LSA
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
from sklearn.pipeline import Pipeline
documents = ["doc1.txt", "doc2.txt", "doc3.txt"]
# raw documents to tf-idf matrix:
vectorizer = TfidfVectorizer(stop_words='english',
use_idf=True,
smooth_idf=True)
# SVD to reduce dimensionality:
svd_model = TruncatedSVD(n_components=100, // num dimensions
algorithm='randomized',
n_iter=10)
# pipeline of tf-idf + SVD, fit to and applied to documents:
svd_transformer = Pipeline([('tfidf', vectorizer),
('svd', svd_model)])
svd_matrix = svd_transformer.fit_transform(documents)
NMF
特征工程
特征工程主要包括分词,词形还原,去停止词等等。这部分中文和英文不一样。这里主要说中文的做法。
文本分类
分类指标
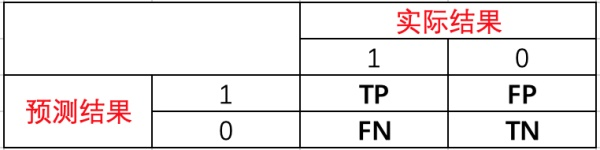
- TP:预测为1,实际为1,预测正确。
- FP:预测为1,实际为0,预测错误。
- FN:预测为0,实际为1,预测错误。
- TN:预测为0,实际为0,预测正确。
准确率
准确率(Accuracy)的定义,即预测正确的结果占总样本的百分比
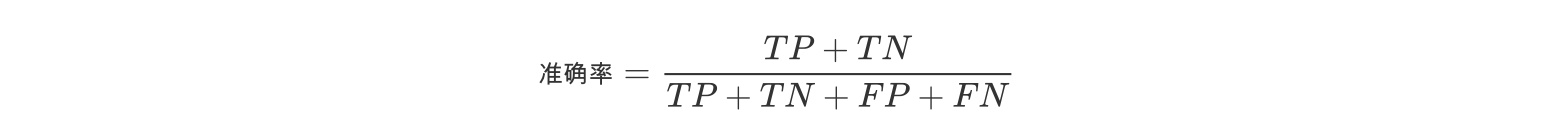
精确率
精确率(Precision)是针对预测结果而言的,其含义是在被所有预测为正的样本中实际为正样本的概率,表达式为
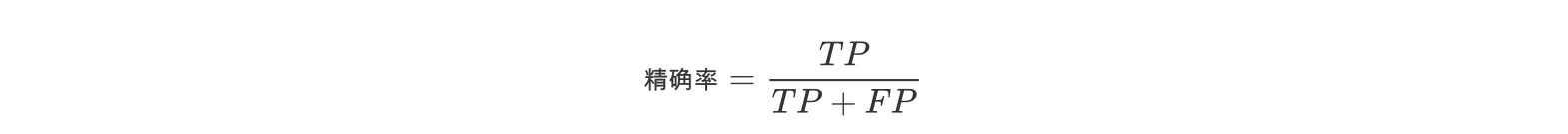
召回率
召回率(Recall)是针对原样本而言的,其含义是在实际为正的样本中被预测为正样本的概率,表达式为
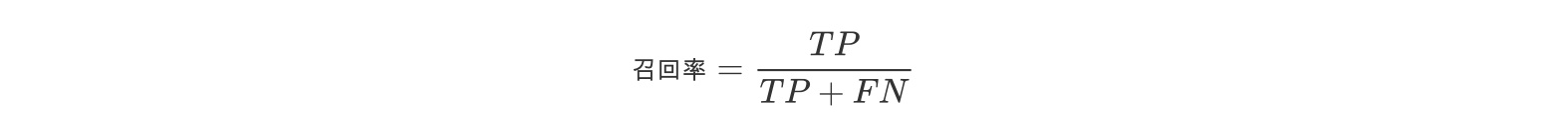
F1分数
F1分数(F1-Score)。F1分数同时考虑精确率和召回率,让两者同时达到最高,取得平衡。F1分数表达式为

Roc、AUC曲线
定义真正例率TPR和假正例率FPR为:
ROC曲线图如下所示,其中横坐标为假正率(FPR),纵坐标为真正率(TPR)。
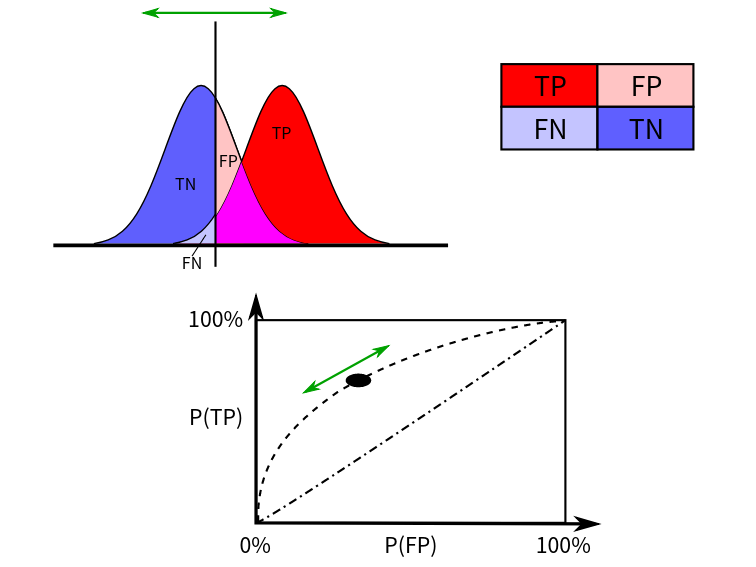
AUC(Area Under Curve)表示ROC中曲线下的面积,用于判断模型的优劣。如ROC曲线所示,连接对角线的面积刚好是0.5,对角线的含义也就是随机判断预测结果,正负样本覆盖应该都是50%。另外,ROC曲线越陡越好,所以理想值是1,即正方形。所以AUC的值一般是介于0.5和1之间的。
AUC的概率解释: 随机取一对正负样本,正样本得分大于负样本的概率。AUC对正负样本比例不敏感,因此常作为不平衡数据集的模型评价标准。
AUC评判标准可参考如下:
- 0.5-0.7:效果较低。
- 0.7-0.85:效果一般。
- 0.85-0.95:效果很好。
- 0.95-1:效果非常好。
Focal Loss
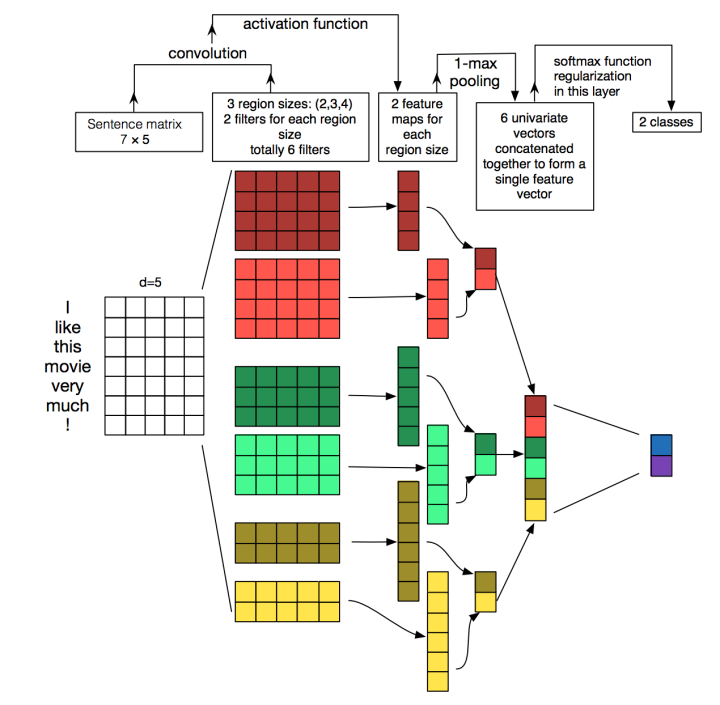
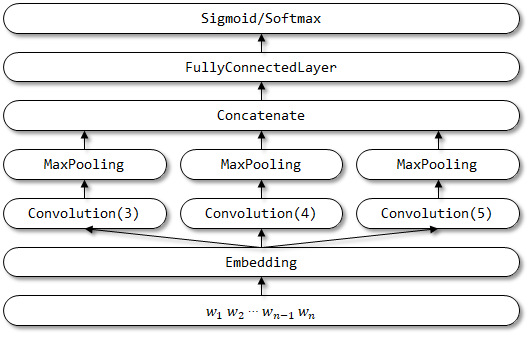
TextCNN
论文 Convolutional Neural Networks for Sentence Classification
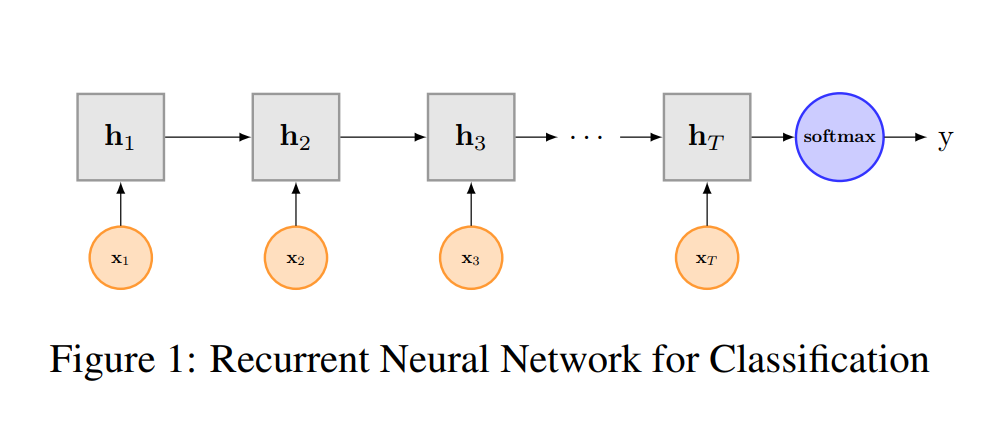
TextRNN
论文 Recurrent Neural Network for Text Classification with Multi-Task Learning
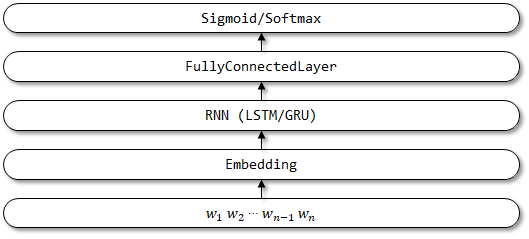
RCNN
论文 Recurrent Convolutional Neural Networks for Text Classification Keras实现
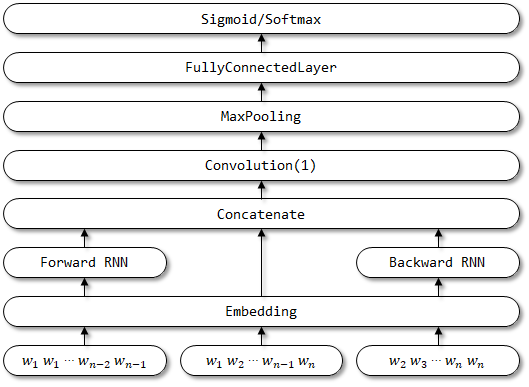
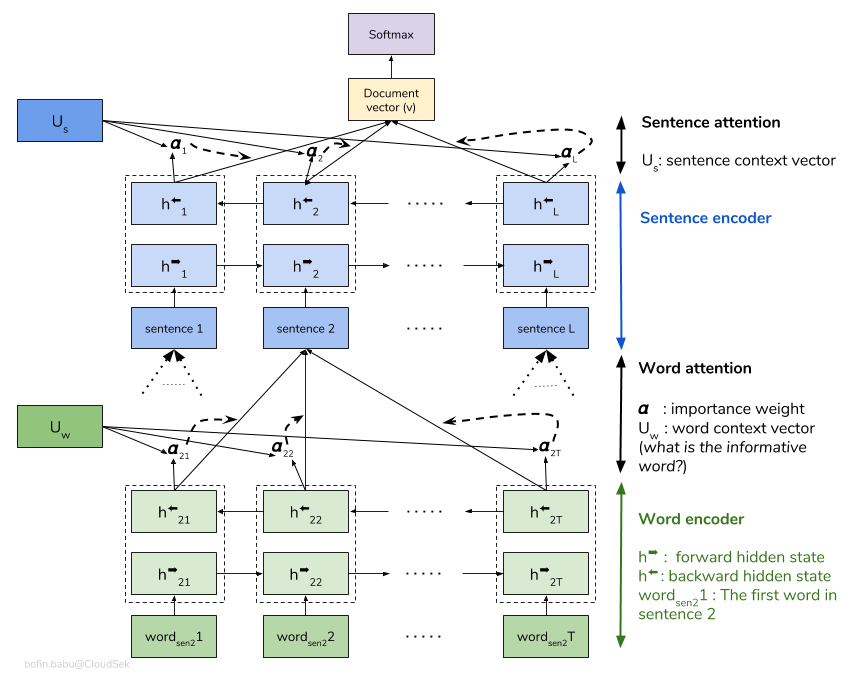
HAN
论文:Hierarchical Attention Networks for Document Classification
HAN 主要针对 document-level 的分类,先是对句子中的每一单词进行BiGRU编码,然后接上Attention,然后对句子级别进行BiGRU编码,然后接上Attention,最后进行分类。
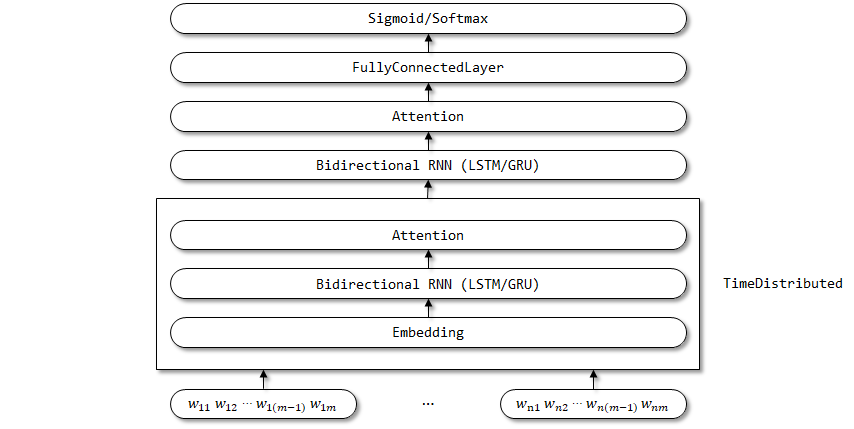
Keras实现
Sequence Labeling
HMM
条件随机场CRF
维特比解码
语言模型
给定词表 V,一个句子可以看做词的序列 (
). 将句子出现的概率记为
,这样一个联合概率分布就是语言模型。
语言的词表非常庞大,比如汉语的词表在10万量级。而上述联合分布有
种取值, 这样的模型大而稀疏,不便于计算。为了使语言模型更紧凑,可以引入马尔可夫假设。
Ngram语言模型
首先将联合分布分解为条件概率的连乘:
在这些条件概率里, 每一个词的概率需要考虑它前面的所有词. 而实际上, 相隔太远的两个词关联很弱. 马尔可夫假设是指,假定每个词出现的概率只跟它前面的少数几个词有关。
当 n=1, 一个一元模型(unigram model)即为 :
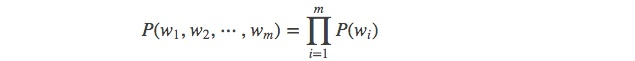
当 n=2, 一个二元模型(bigram model)即为 :
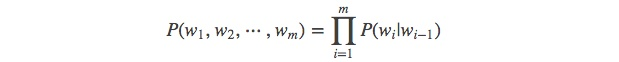
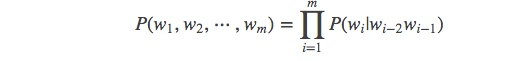
困惑度
通常使用困惑度(perplexity)来评价语言模型的好坏。困惑度(perplexity)的基本思想是:给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好,公式如下:
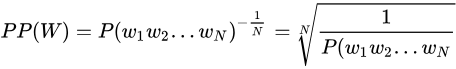
- 最佳情况下,模型总是把标签类别的概率预测为1,此时困惑度为1;
- 最坏情况下,模型总是把标签类别的概率预测为0,此时困惑度为正无穷;
- 基线情况下,模型总是预测所有类别的概率都相同,此时困惑度为类别个数。
显然,任何一个有效模型的困惑度必须小于类别个数。在语言模型中,困惑度必须小于词典大小vocab_size。
Seq2seq
Seq2Seq 模型顾名思义,输入一个序列,用一个 RNN (Encoder)编码成一个向量 u,再用另一个 RNN (Decoder)解码成一个序列输出,且输出序列的长度是可变的。
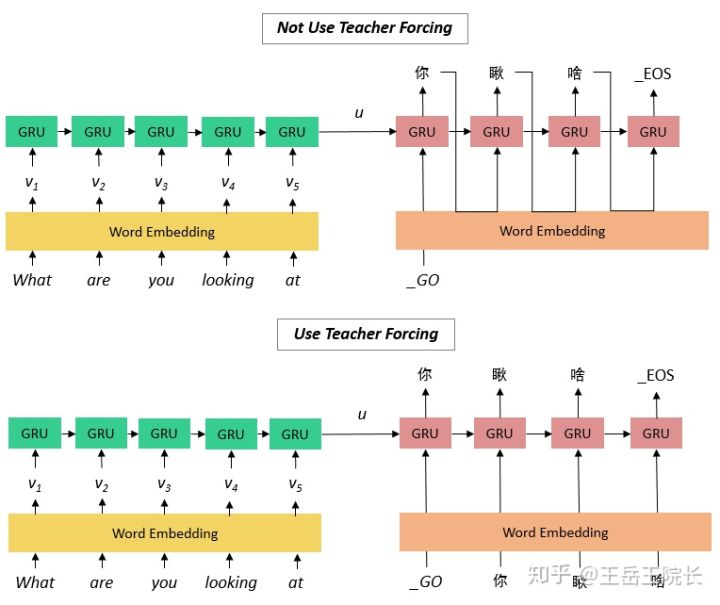
训练阶段使用Teacher Forcing,防止上一时刻的错误传播到这一时刻。用了 Teacher Forcing 可以阻断错误积累,斧正模型训练,加快参数收敛。
模型训练好了,到了测试阶段,你是不能用 Teacher Forcing 的,因为测试阶段是看不到期望的输出序列的,所以必须等着上一时刻输出一个单词,下一时刻才能确定该输入什么。
Beam Search
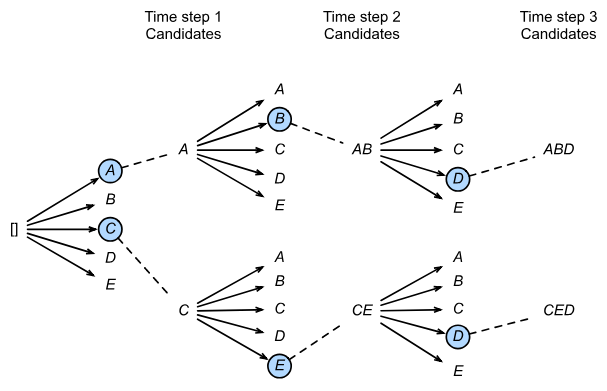
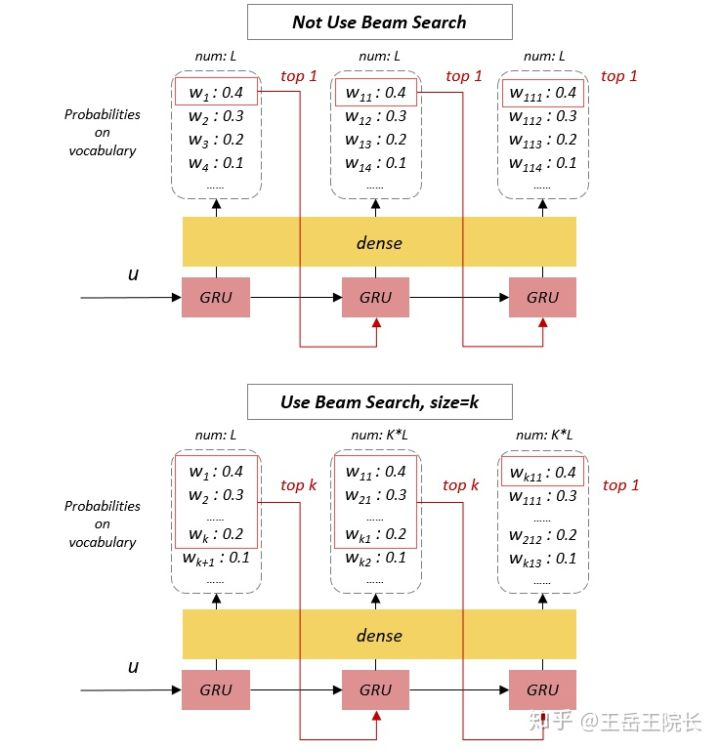
Beam Search是只在 test 阶段有用的设定。之前seq2seq 版本在输出序列时,仅在每个时刻选择概率 top 1 的单词作为这个时刻的输出单词(相当于局部最优解),然后把这些词串起来得到最终输出序列。实际上就是贪心策略。
但如果使用了 Beam Search,在每个时刻会选择 top K 的单词都作为这个时刻的输出,逐一作为下一时刻的输入参与下一时刻的预测,然后再从这 K*L(L为词表大小)个结果中选 top K 作为下个时刻的输出,以此类推。在最后一个时刻,选 top 1 作为最终输出。实际上就是剪枝后的深搜策略。
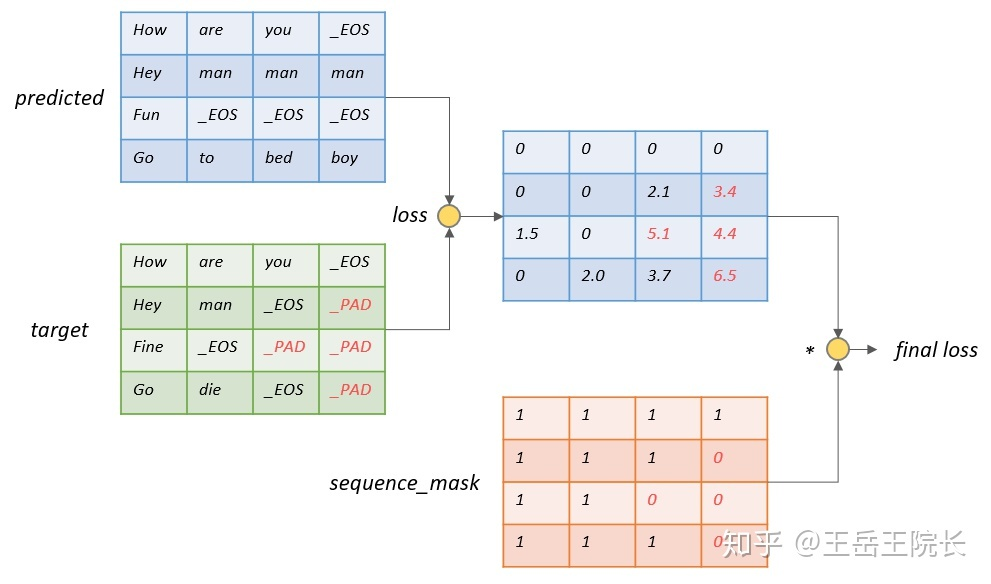
Sequence Loss
实际上“_PAD”上的 loss 计算是没有用的,因为“_PAD”本身没有意义,也不指望 decoder 去输出这个字符,只是占位用的,计算 loss 反而带来副作用,影响参数的优化。所以需要在 loss 上乘一个 mask 矩阵,这个矩阵可以把“_PAD”位置上的 loss 筛掉。
Attention
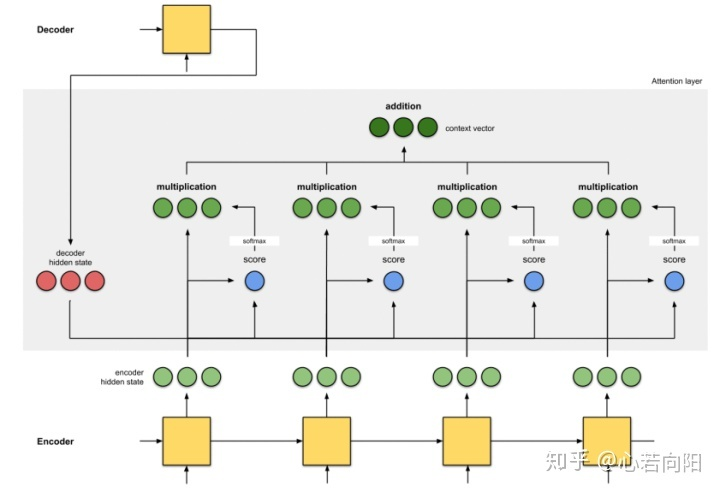
Seq2Seq中的Attention机制
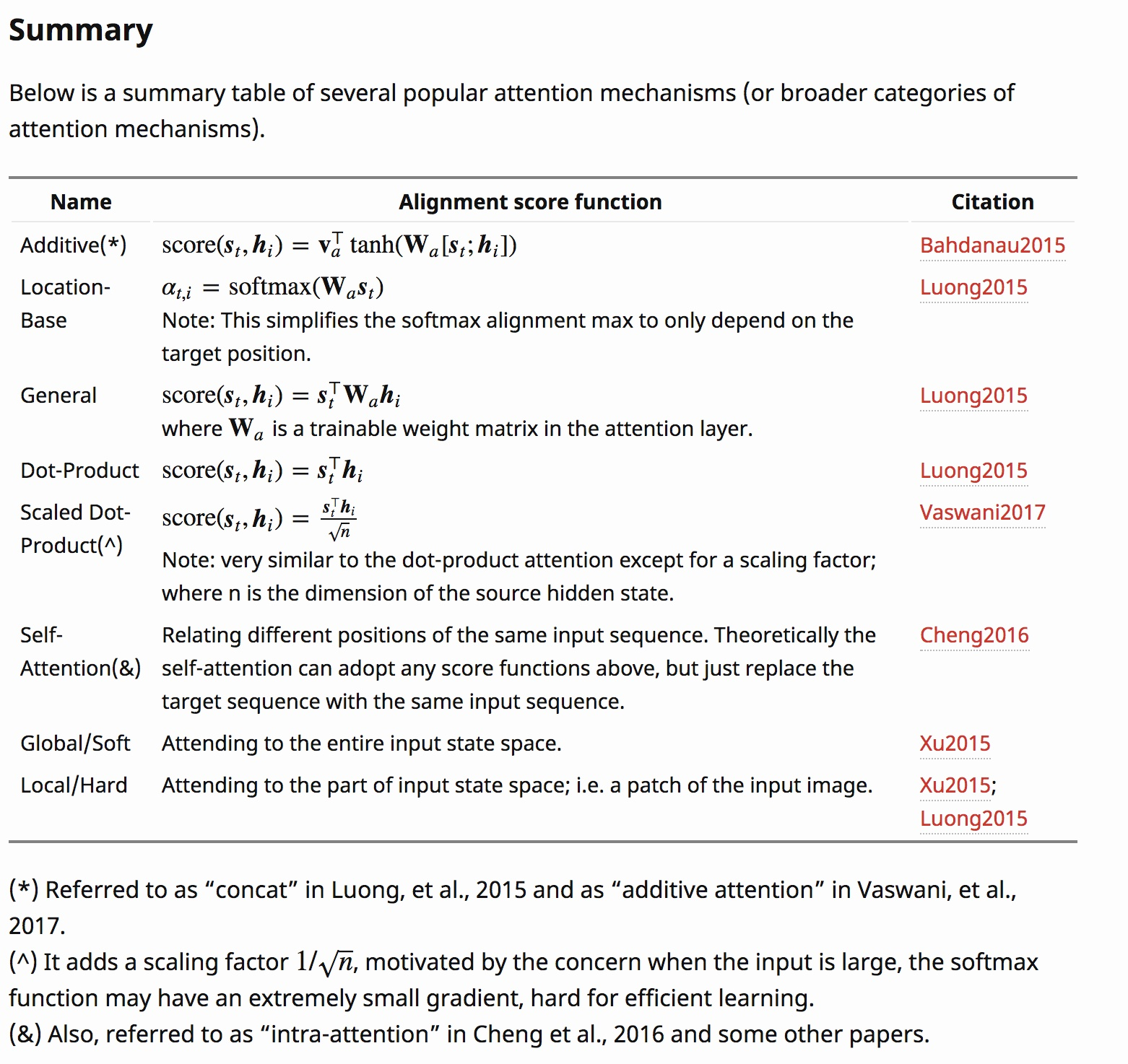
Transformer
这部分以李宏毅老师的课件为主进行说明。 首先让我们回顾一下传统的Seq2Seq模型。
- RNN:很难并行,存在长期依赖问题
- CNN:底层的CNN很难看到较远的信息。
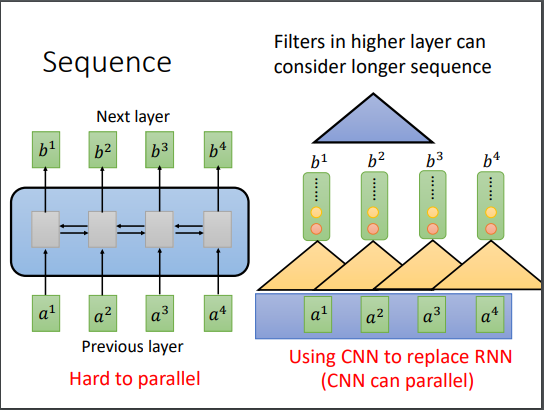
self-attention可以替换掉CNN和RNN,也是一种Seq模型。
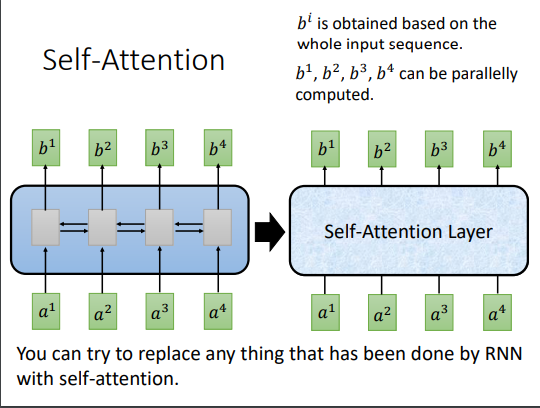
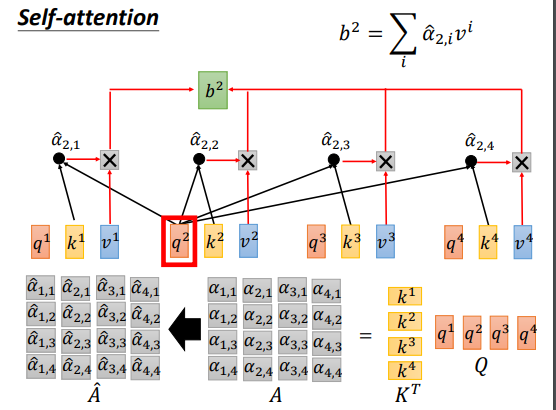
self attention的计算,输入x通过线性变换得到q,k,v。
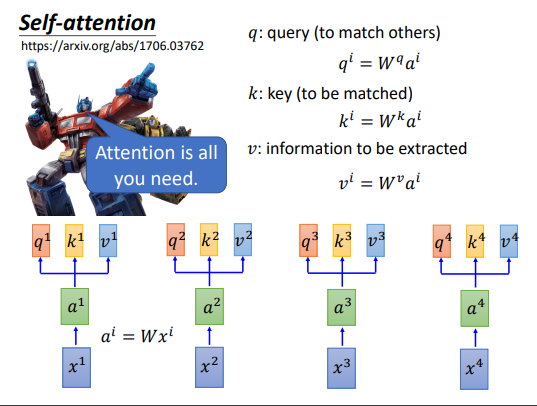
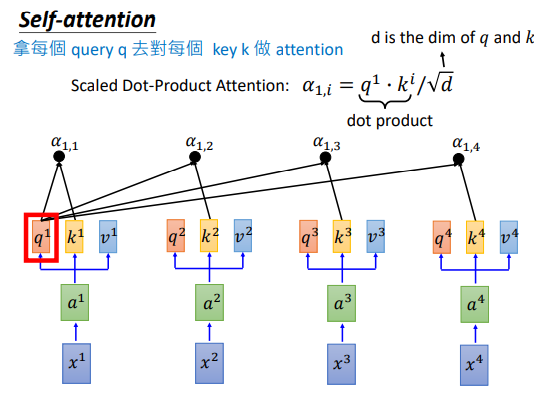
然后Q和K做点积得到Attention矩阵。
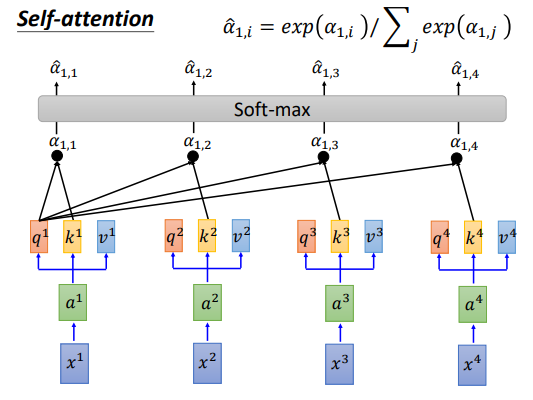
进行softmax归一化
然后计算Attention和V的乘积,得到输出。
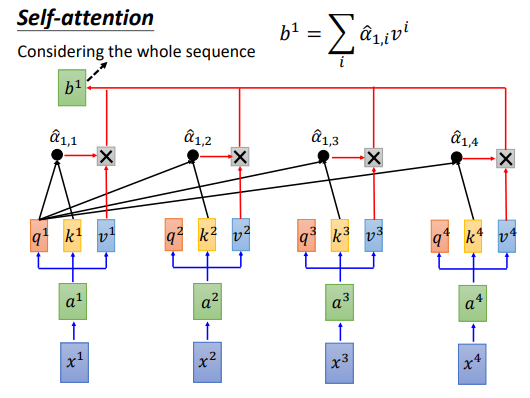
Attention过程的向量化
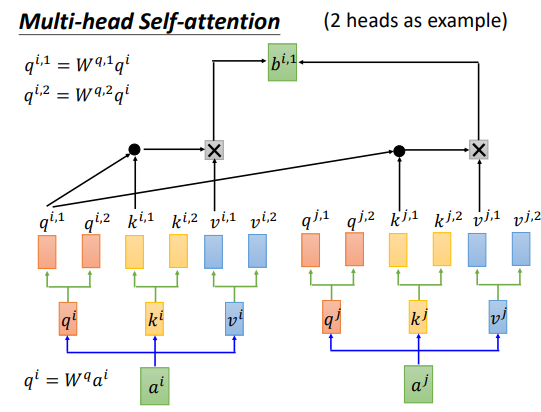
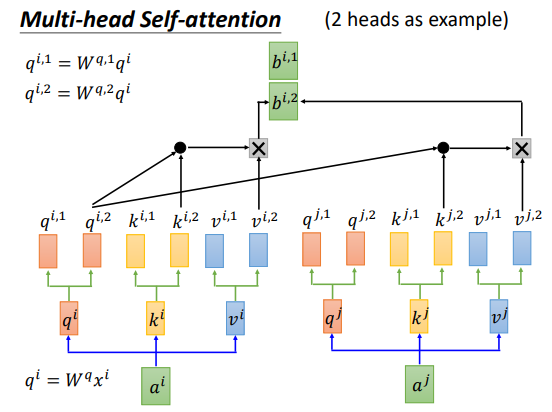
多头Attention,先分割输入,进行attention,然后cancat输出
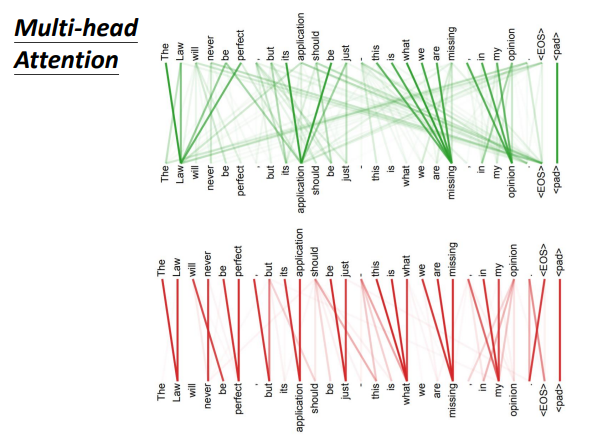
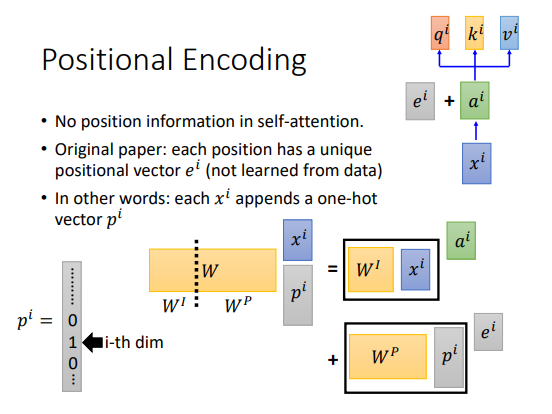
位置编码
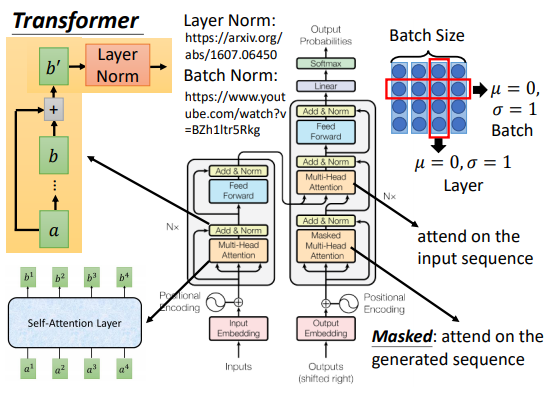
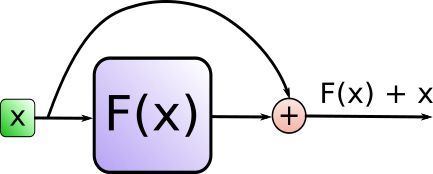
Layer Norm和残差连接
BERT
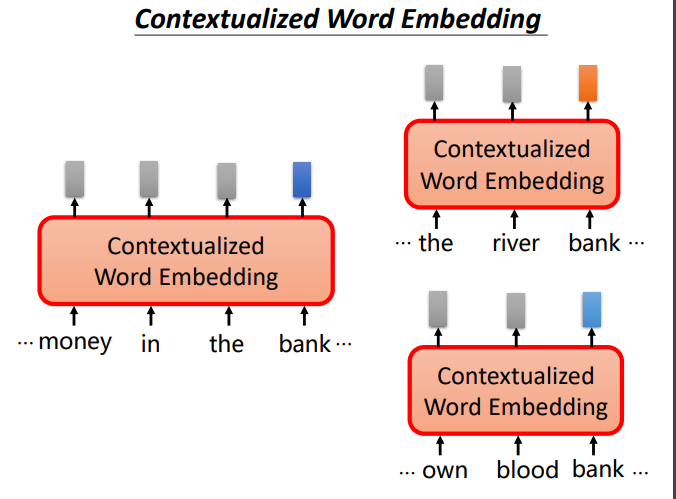
语境化词嵌入(动态词嵌入)
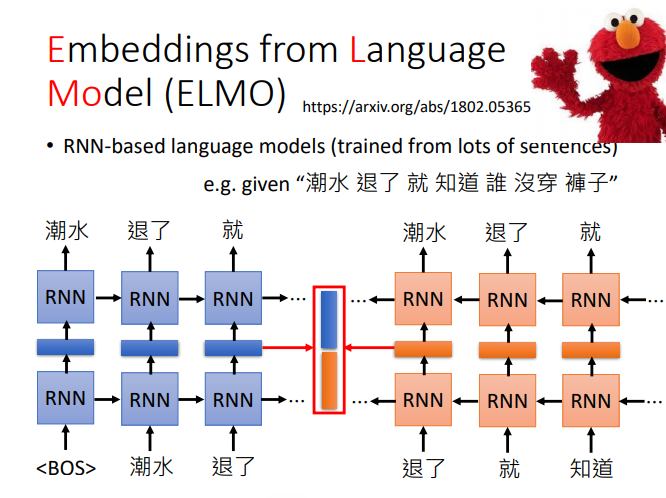
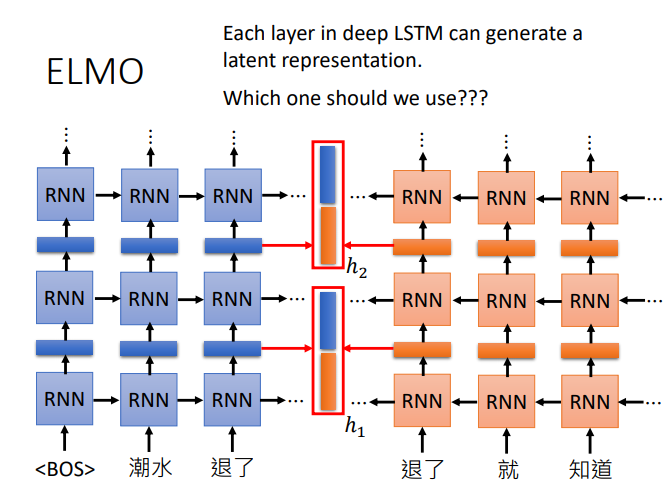
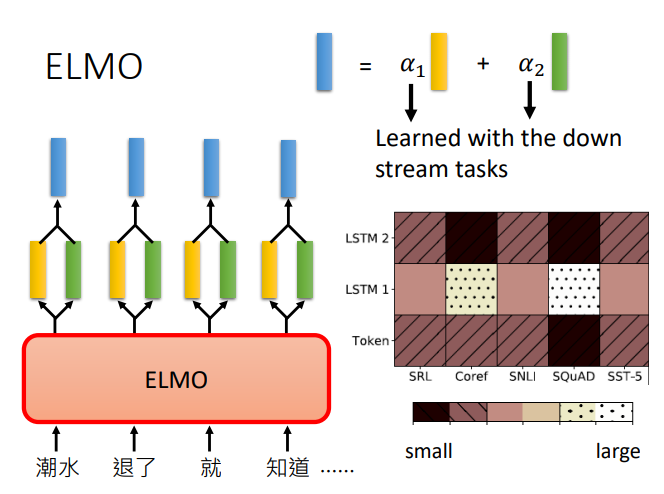
BERT
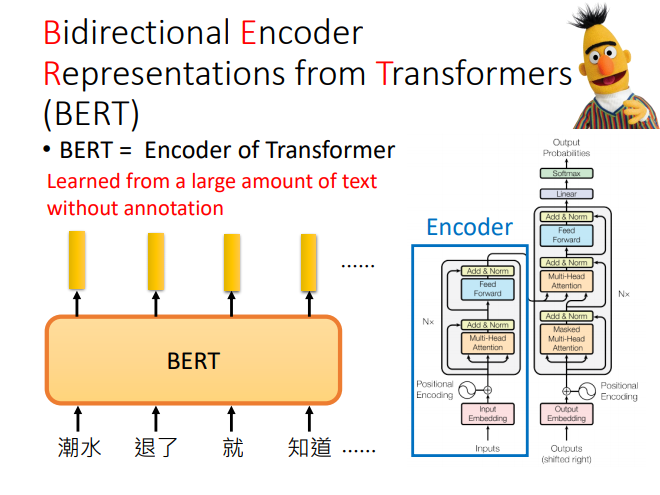
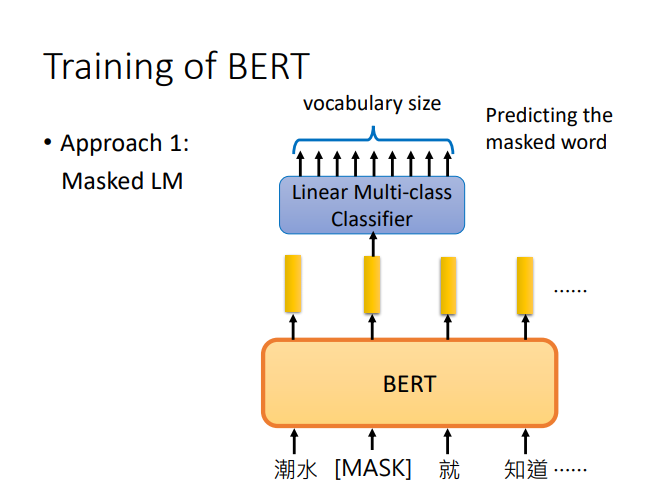
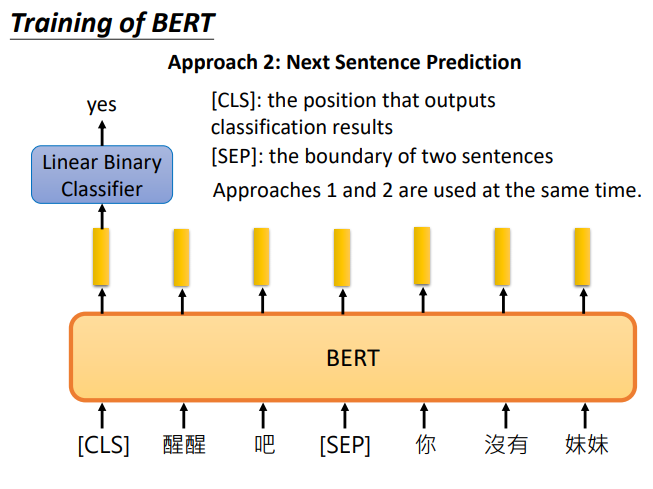
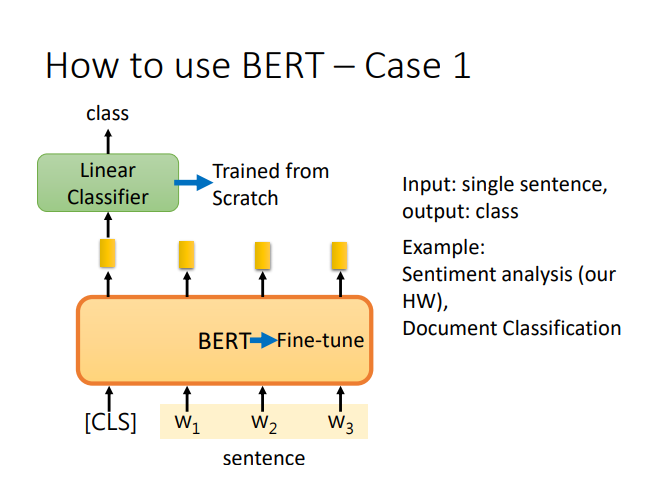
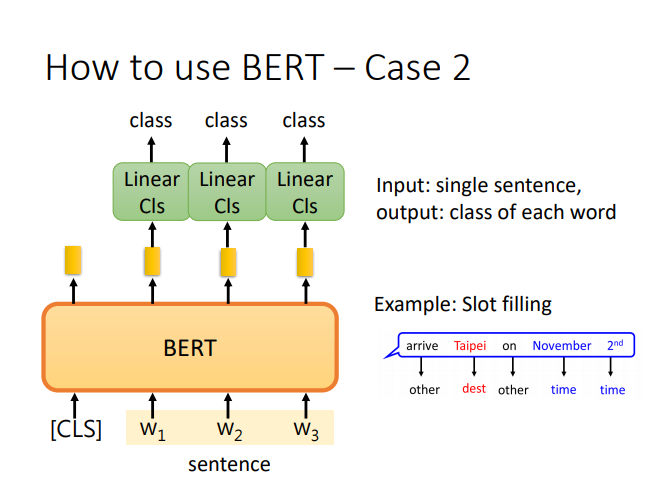
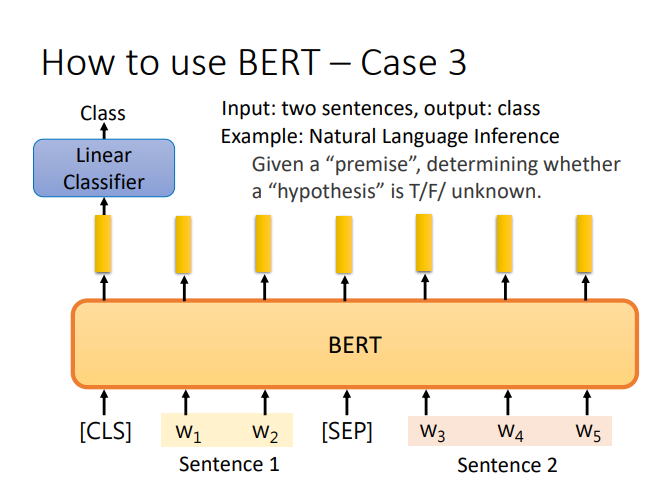

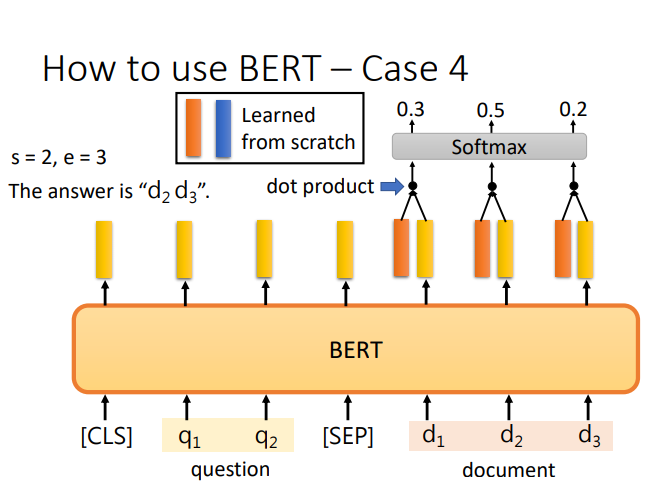
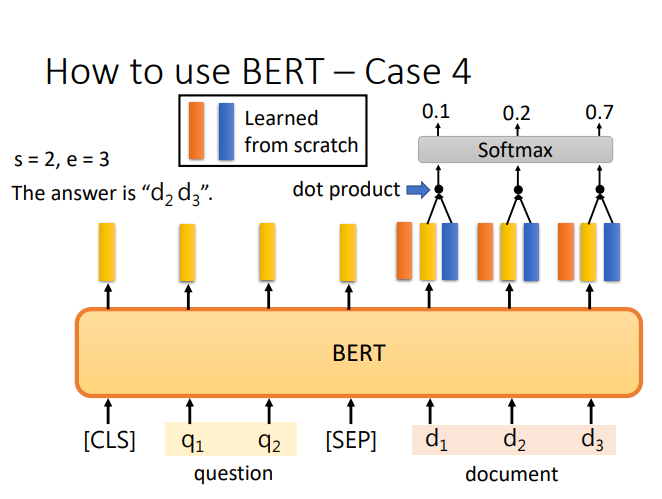

其他知识
-
判别式模型:KNN,SVM,决策树,感知机,线性判别分析(LDA),LR(线性回归,逻辑回归),神经网络,CRF(条件随机场),Boosting; 生成模型:朴素贝叶斯,HMM,GMM(高斯混合模型),主题文档生成模型(LDA),受限玻尔兹曼机
-
Python3中已经删除的raw_input函数。使用input函数用以获取用户输入。
-
不可变对象:数值,字符串,元组(tuple) 可变对象:列表,字典。不可变对象是指不可以被其引用所改变的对象。
-
bagging是将许多单独训练的学习机集成起来;dropout是将许多单独训练的子网络集成起来,某些权值是共享的。 boosting并不是单独训练的,而是按照有一定的顺序训练的,具有相互依赖关系。 stacking是通过两层学习机完成的学习。
-
Bagging和Boosting的区别: 1)样本选择上: Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。 Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。 2)样例权重: Bagging:使用均匀取样,每个样例的权重相等 Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。 3)预测函数: Bagging:所有预测函数的权重相等。 Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。 4)并行计算: Bagging:各个预测函数可以并行生成 Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果
QA
- Transfomer为什么需要位置编码?CNN需要吗?
如果不加位置信息,Transformer模型并没有捕捉顺序序列的能力,也就是说无论句子的结构怎么打乱,Transformer都会得到类似的结果。换句话说,Transformer只是一个功能更强大的词袋模型而已。RNN 因为是线性序列结构,所以很自然它天然就会把位置信息编码进去;CNN 的卷积核是能保留特征之间的相对位置的。
- Transfomer的残差结构有什么用?
- 为什么需要Multi-Head Attention?
如果把输入看成是多个维度信息的concat的话,Multi-Head Attention相当于n个不同的self-attention的集成(ensemble);如果把输入看成一个整体的话,则是对一个向量的不同部分施以不同的attention权重。
- self Attention的公式,为什么要除以d的开方?
防止其结果过大,会除以一个尺度标度
-
LSTM,GRU结构和参数计算
-
Dying Relu Dying Relu现象指的是,在使用Relu作为激活函数时,因为学习率较大或某些原因,导致某一层的bias学到较大的负值,使得该层在过完Relu激活函数后的输出始终是0。当进入到这一状态时,基本上没办法再回到正常状态。因为在回传时,值为0导致梯度也为0。
-
CRF和HMM?
-
L2正则和L1正则?L1为什么是稀疏的?
-
大数定律和中心极限定理?
大数定律讲的是样本均值收敛到总体均值,说白了就是期望。而中心极限定理告诉我们,当样本足够大时,样本均值的分布会慢慢变成正态分布。
- 矩阵求逆?
- SVD分解?
- 聚类的方法?
- 条件概率计算?
- 水塘抽样?
问题描述:当内存无法加载全部数据时,如何从包含未知大小的数据流中随机选取k个数据,并且要保证每个数据被抽取到的概率相等。
简单抽样算法就是从固定的n个元素里随机选出k个元素,这样每个元素被选的概率都是平等的k/n。简单抽样是最简单的抽样算法,同样也是使用最为普遍的算法。简单抽样有个前提就是必须提前知道目标总体的大小n。
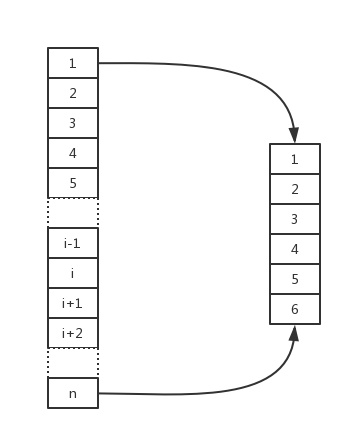
区别于简单抽样,水塘抽样是一种动态的抽样方法。具体证明和算法
- 树的合并
- 乘积最大的子串?
- Two Sum?
代码
- Keras Attention
from keras import backend as K
from keras.engine.topology import Layer
from keras import initializers, regularizers, constraints
from keras.layers.merge import _Merge
class Attention(Layer):
def __init__(self, step_dim,
W_regularizer=None, b_regularizer=None,
W_constraint=None, b_constraint=None,
bias=True, **kwargs):
"""
Keras Layer that implements an Attention mechanism for temporal data.
Supports Masking.
Follows the work of Raffel et al. [https://arxiv.org/abs/1512.08756]
# Input shape
3D tensor with shape: `(samples, steps, features)`.
# Output shape
2D tensor with shape: `(samples, features)`.
:param kwargs:
Just put it on top of an RNN Layer (GRU/LSTM/SimpleRNN) with return_sequences=True.
The dimensions are inferred based on the output shape of the RNN.
Example:
model.add(LSTM(64, return_sequences=True))
model.add(Attention())
"""
self.supports_masking = True
# self.init = initializations.get('glorot_uniform')
self.init = initializers.get('glorot_uniform')
self.W_regularizer = regularizers.get(W_regularizer)
self.b_regularizer = regularizers.get(b_regularizer)
self.W_constraint = constraints.get(W_constraint)
self.b_constraint = constraints.get(b_constraint)
self.bias = bias
self.step_dim = step_dim
self.features_dim = 0
super(Attention, self).__init__(**kwargs)
def build(self, input_shape):
assert len(input_shape) == 3
self.W = self.add_weight((input_shape[-1],),
initializer=self.init,
name='{}_W'.format(self.name),
regularizer=self.W_regularizer,
constraint=self.W_constraint)
self.features_dim = input_shape[-1]
if self.bias:
self.b = self.add_weight((input_shape[1],),
initializer='zero',
name='{}_b'.format(self.name),
regularizer=self.b_regularizer,
constraint=self.b_constraint)
else:
self.b = None
self.built = True
def compute_mask(self, input, input_mask=None):
# do not pass the mask to the next layers
return None
def call(self, x, mask=None):
input_shape = K.int_shape(x)
features_dim = self.features_dim
# step_dim = self.step_dim
step_dim = input_shape[1]
eij = K.reshape(K.dot(K.reshape(x, (-1, features_dim)), K.reshape(self.W, (features_dim, 1))), (-1, step_dim))
if self.bias:
eij += self.b[:input_shape[1]]
eij = K.tanh(eij)
a = K.exp(eij)
# apply mask after the exp. will be re-normalized next
if mask is not None:
# Cast the mask to floatX to avoid float64 upcasting in theano
a *= K.cast(mask, K.floatx())
# in some cases especially in the early stages of training the sum may be almost zero
# and this results in NaN's. A workaround is to add a very small positive number ε to the sum.
a /= K.cast(K.sum(a, axis=1, keepdims=True) + K.epsilon(), K.floatx())
a = K.expand_dims(a)
weighted_input = x * a
# print weigthted_input.shape
return K.sum(weighted_input, axis=1)
def compute_output_shape(self, input_shape):
# return input_shape[0], input_shape[-1]
return input_shape[0], self.features_dim
# end Attention
- Attention RNN Model
import keras
from keras import Model
from keras.layers import *
import Attention
class TextClassifier():
def model(self, embeddings_matrix, maxlen, word_index, num_class):
inp = Input(shape=(maxlen,))
encode = Bidirectional(CuDNNGRU(128, return_sequences=True))
encode2 = Bidirectional(CuDNNGRU(128, return_sequences=True))
attention = Attention(maxlen)
x_4 = Embedding(len(word_index) + 1,
embeddings_matrix.shape[1],
weights=[embeddings_matrix],
input_length=maxlen,
trainable=True)(inp)
x_3 = SpatialDropout1D(0.2)(x_4)
x_3 = encode(x_3)
x_3 = Dropout(0.2)(x_3)
x_3 = encode2(x_3)
x_3 = Dropout(0.2)(x_3)
avg_pool_3 = GlobalAveragePooling1D()(x_3)
max_pool_3 = GlobalMaxPooling1D()(x_3)
attention_3 = attention(x_3)
x = keras.layers.concatenate([avg_pool_3, max_pool_3, attention_3], name="fc")
x = Dense(num_class, activation="sigmoid")(x)
adam = keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08,amsgrad=True)
model = Model(inputs=inp, outputs=x)
model.compile(
loss='categorical_crossentropy',
optimizer=adam)
return model
