

说明
打了删除线的,都是有问题的错误的描述。
背景
对于这类问题,发现还是最终要回归到经典书籍,即牛逼的unix网络编程 这样的书,不然看再看的文章和网络资料,都不一定能看得懂,因为网络资料和网友的理解不一定很全面,他们最原始的最源头的参考资料,也就是这么几本书。无非是,他们肯比较吃苦,把书多看了几遍,能用自己的语言表达出来,当然,可以肯定的是,只要是复述别人的话,肯定是有不少的漏洞的。后面的人,需要理解清楚,就惨了。最终,还是得,把经典书籍给捡起来,和他们一样,得多看几遍。
tcp协议的几张架构图和流程图
最关键的地方就是这里了。要深入的真正的理解为什么会发生拆包和粘包的情况。直接看unix网络编程这一本书就够了。
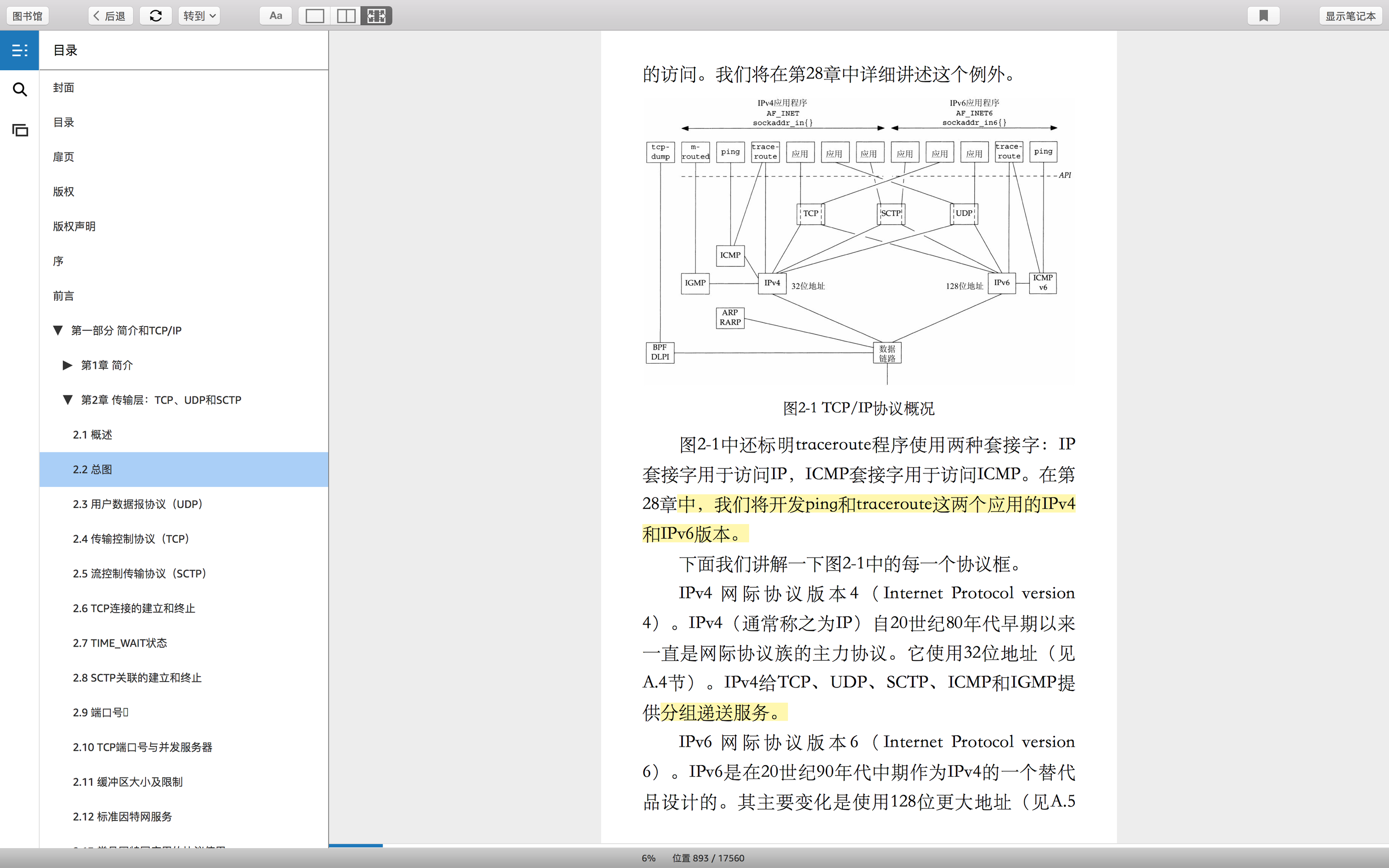
协议分层
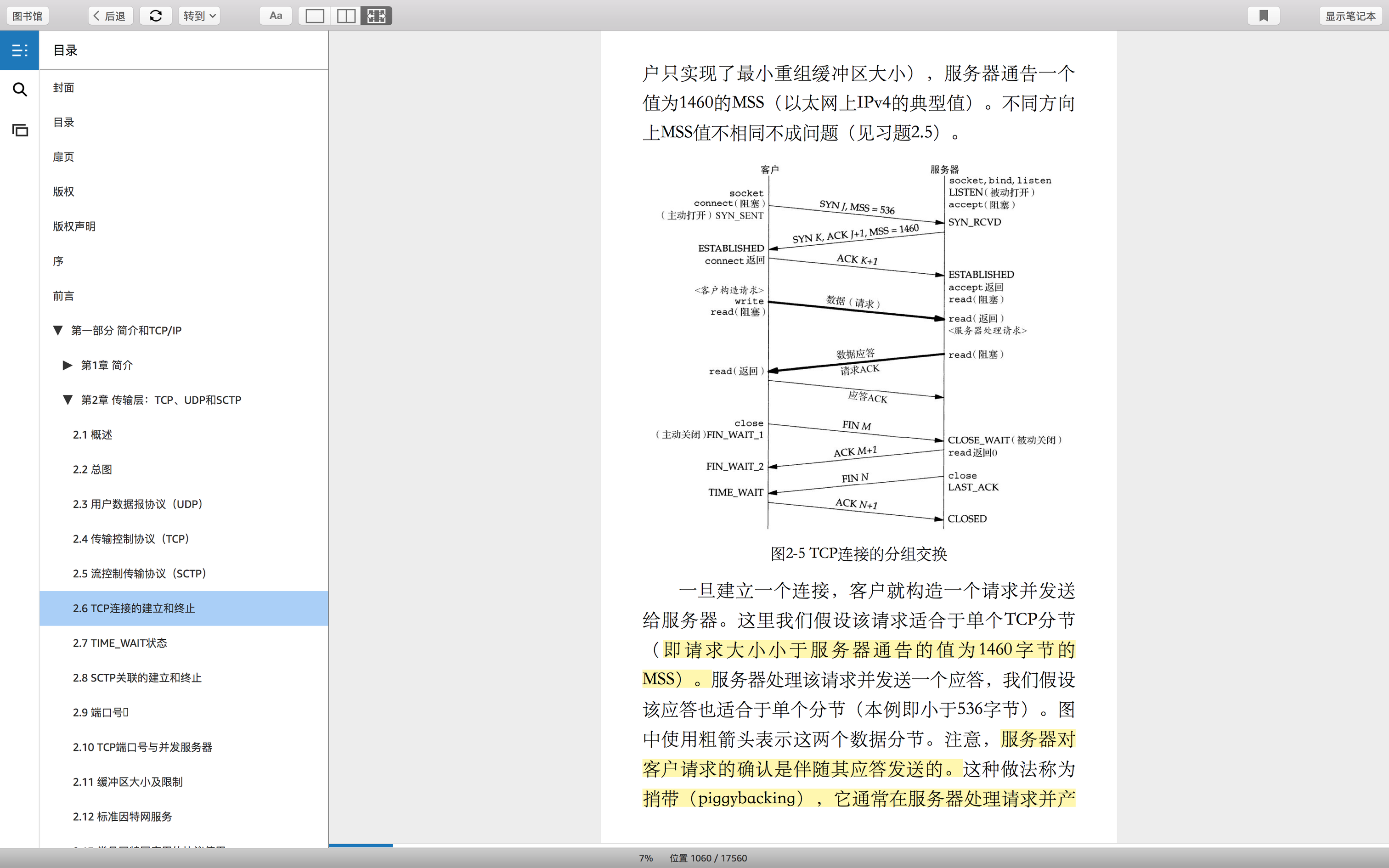
握手:需要三个分节
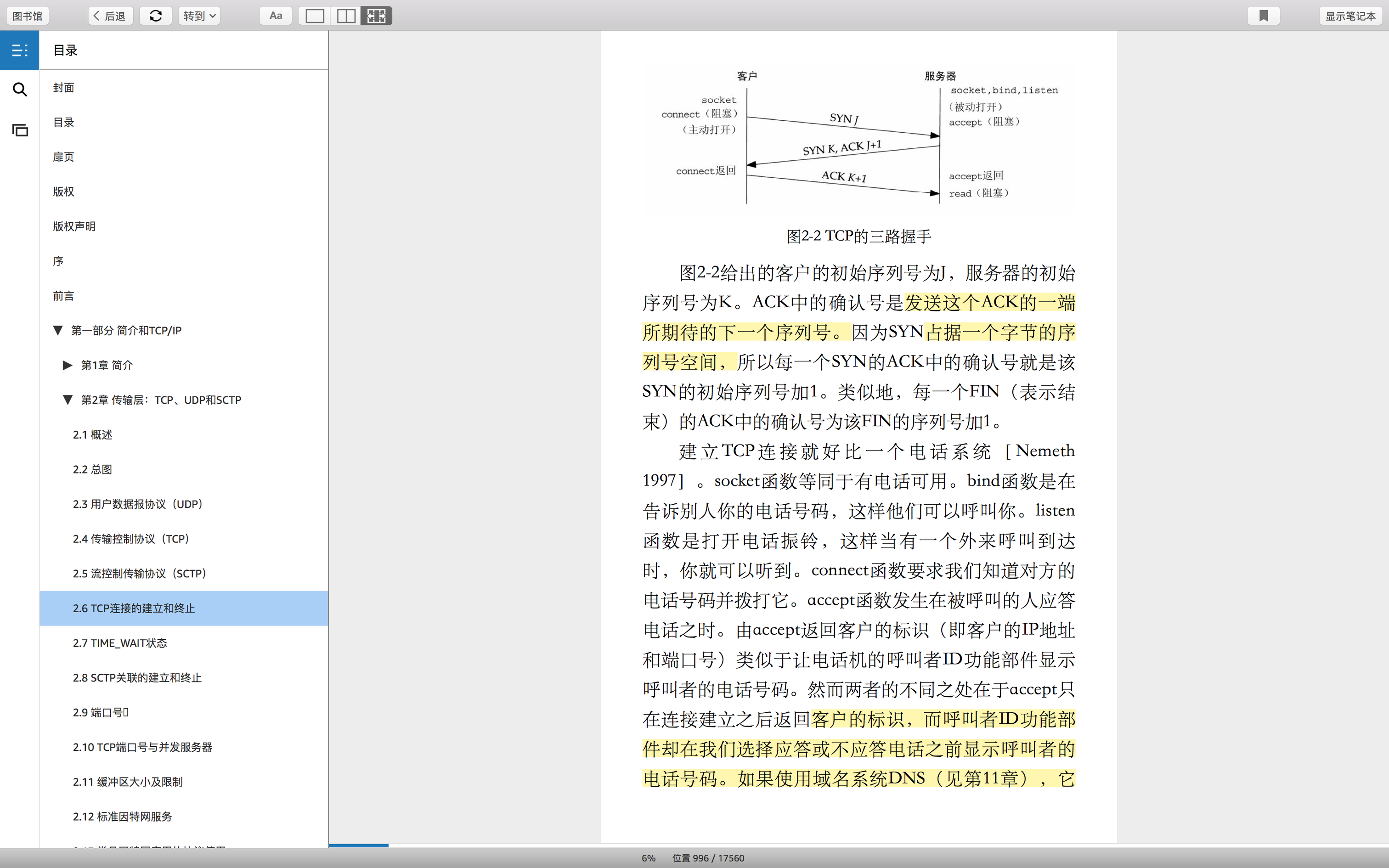
握到一半的时候,叫半连接。这个时候,还不能进行数据通信。只有等完全建立连接,即状态变为established的时候,才可以读写数据。
关闭:需要四个分节,因为确认分节和响应分节是分开的。具体原因是,因为响应分节超过1s,就先发确认分节。
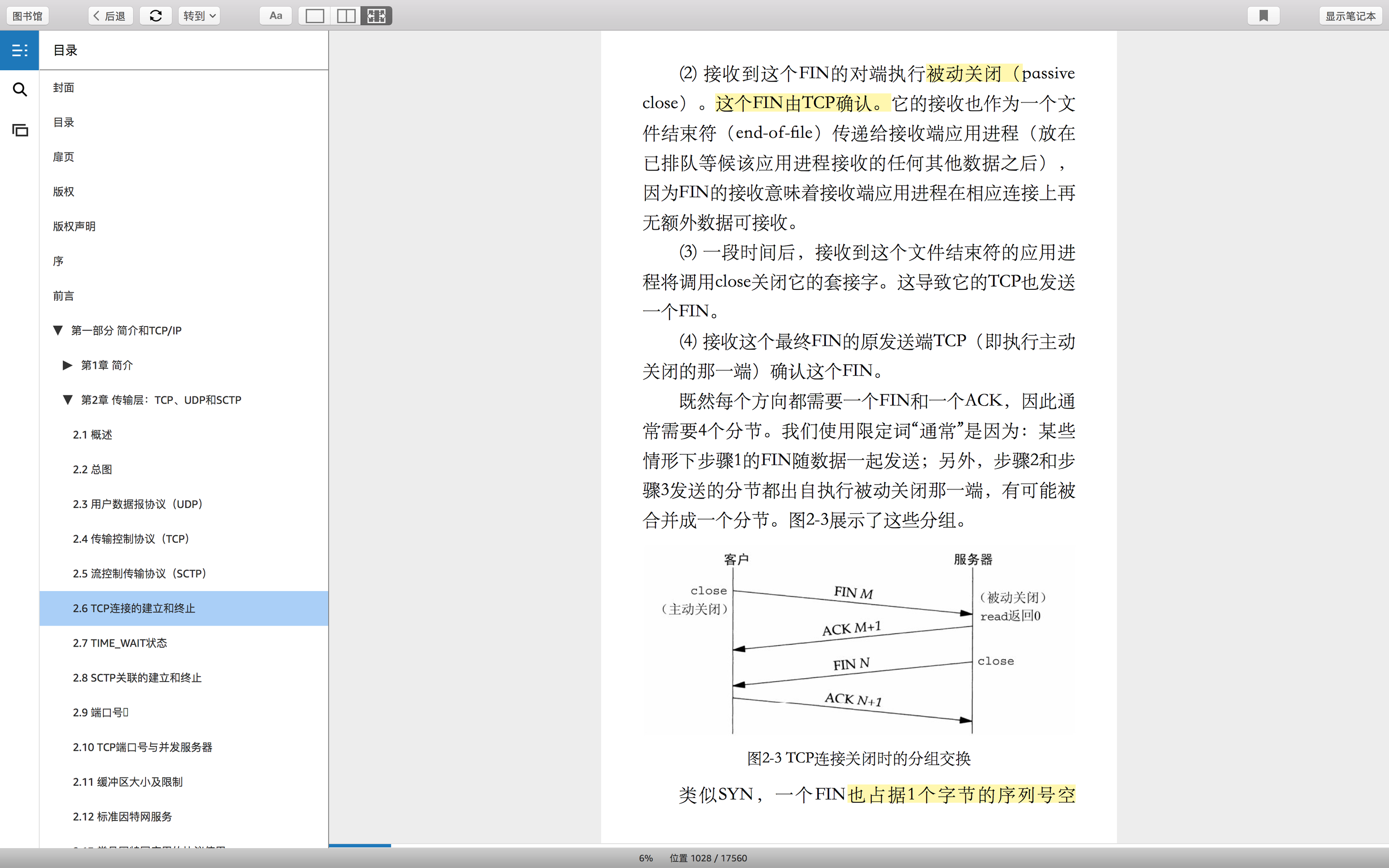
关到一半的时候,叫半关闭。这个时候,仍然可以进行通信。因为有可能,路由在路上的数据还没有到达目的地。
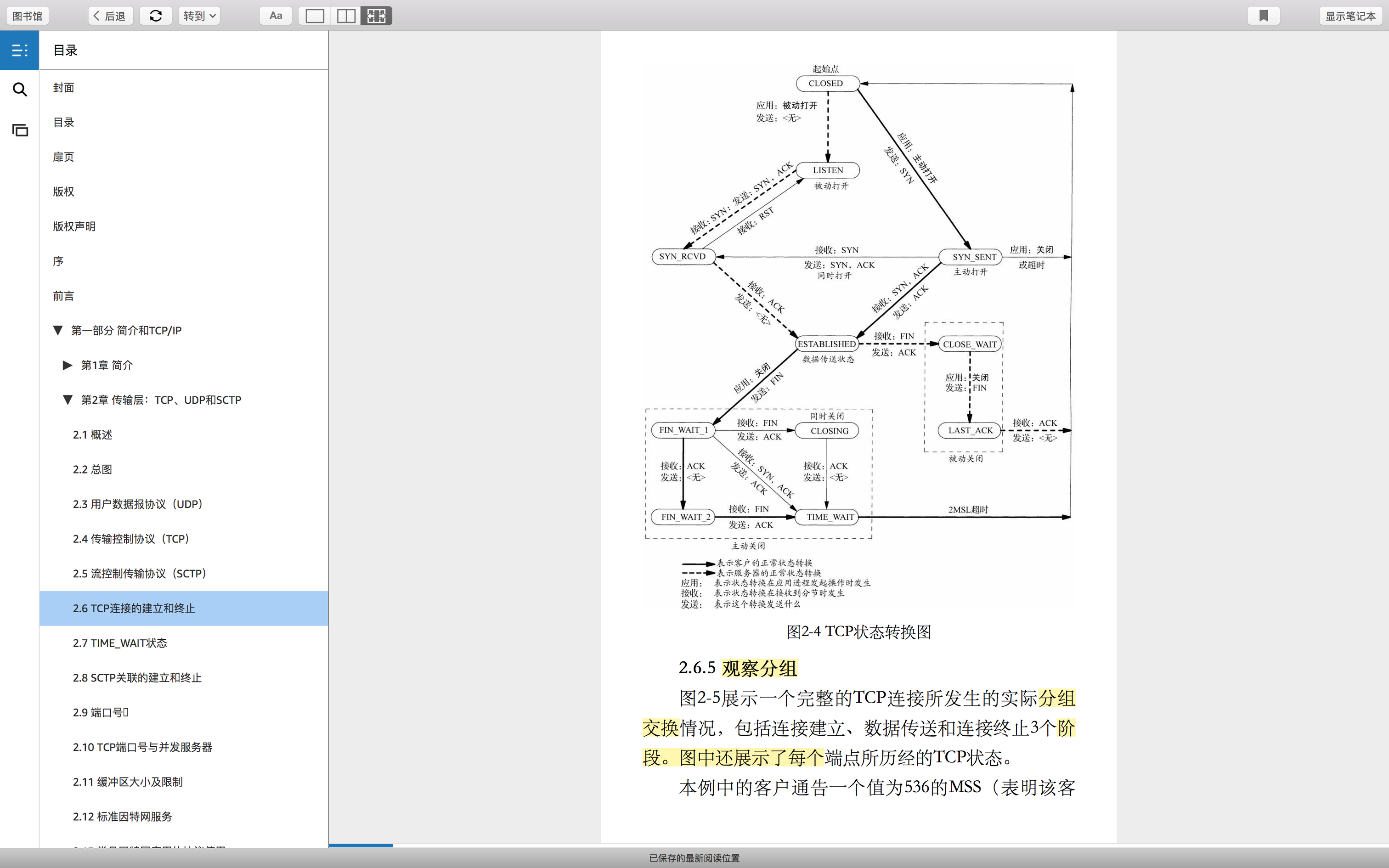
tcp socket 11种状态-状态转换图
握手连接、读写数据、关闭的完整流程
tcp socket在内核里的缓冲区内存
操作分节和确认分节
不管是什么操作,比如握手操作或者关闭操作,都有一个专门的分节来表示它们。而每个操作分节都需要确认,所以也就有了确认分节,确认分节的内容是ACK操作分节的序号+1。例如,ACK M+1。操作分节的序号,指的是,当前数据的分节序号,就是一个编号而已。
一些概念
数据按是否完整,分为两块(或者说,有两种叫法)
1.数据报文
要发送的完整数据
2.数据包
数据子包 分节 数据报,反正,不管什么叫法,就是只是完整数据的一部分。
而且,分节,在每一层都有可能往下拆分为多个子分节。也就是说,只有应用层的数据才是完整的数据报文,其他的层,包括传输层tcp 网络层ip 数据链路层,都是子分节。
另外,不同层,对分节的叫法,也不一样,但其实,本质上都是分节,即代表的是不完整的子数据:
1.tcp
分节
2.ip
数据报datagram
3.数据链路层
帧frame
为什么会发生拆包和粘包?
1.拆分
是因为数据太大
2.合并
是因为数据太小
具体细节
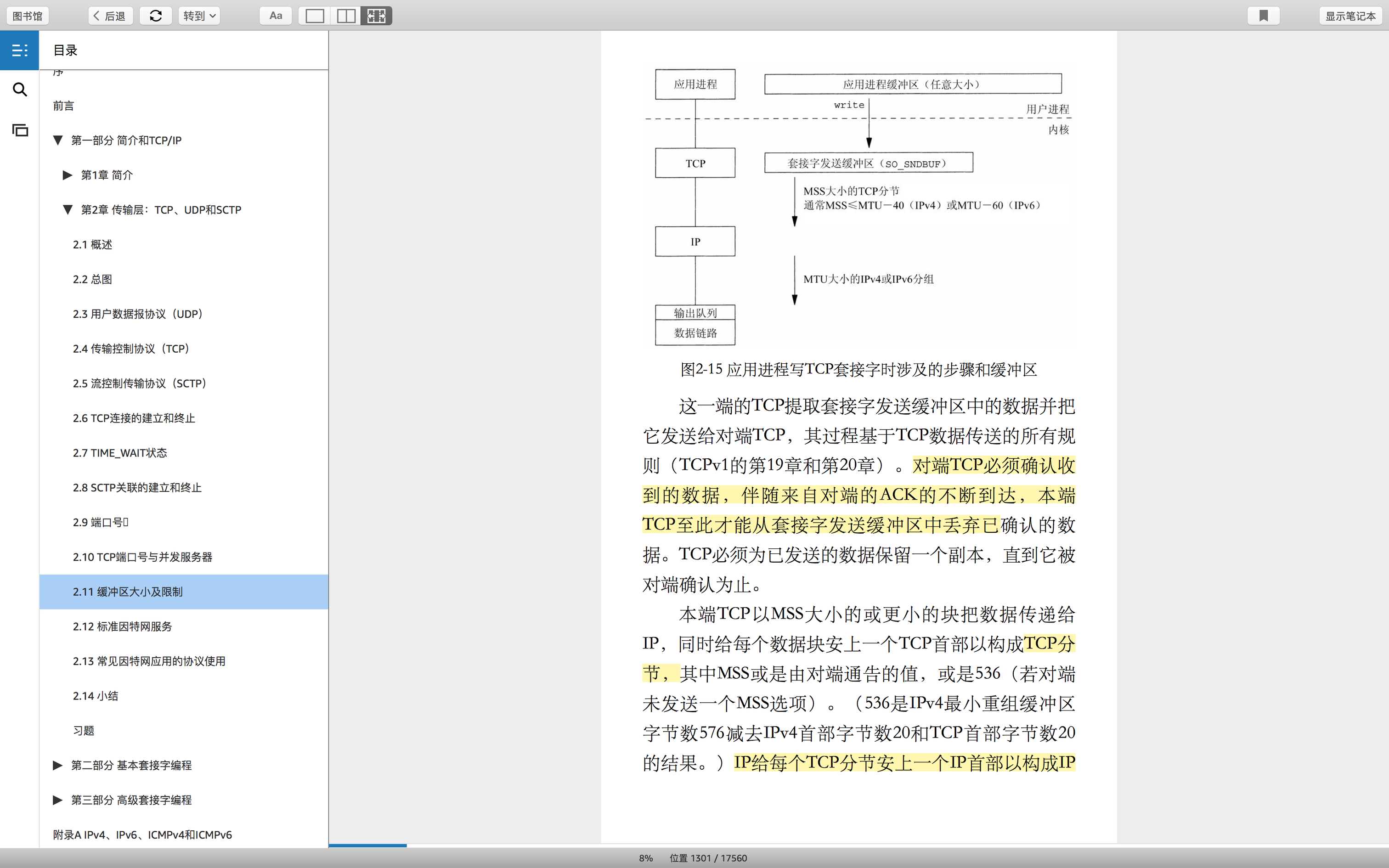
tcp socket 内核缓冲区:包含发送缓冲区和接受缓冲区,客户端和服务器都有两个缓冲区
1.什么时候发生拆包?
数据比缓冲区大。就会被拆成多个独立的分节。
2.什么时候发生粘包?
数据比缓冲区小,就有可能把多个数据拼接为一个分节。
但是,网络协议的目的,总体上来说,是要避免减少拆包和粘包的情况,因为拆包和粘包之后,在路由到目的地的时候顺序不一致,接受度要重新还原顺序。这是浪费。
而且,在网络协议的每一层,都有可能发生拆包和粘包。
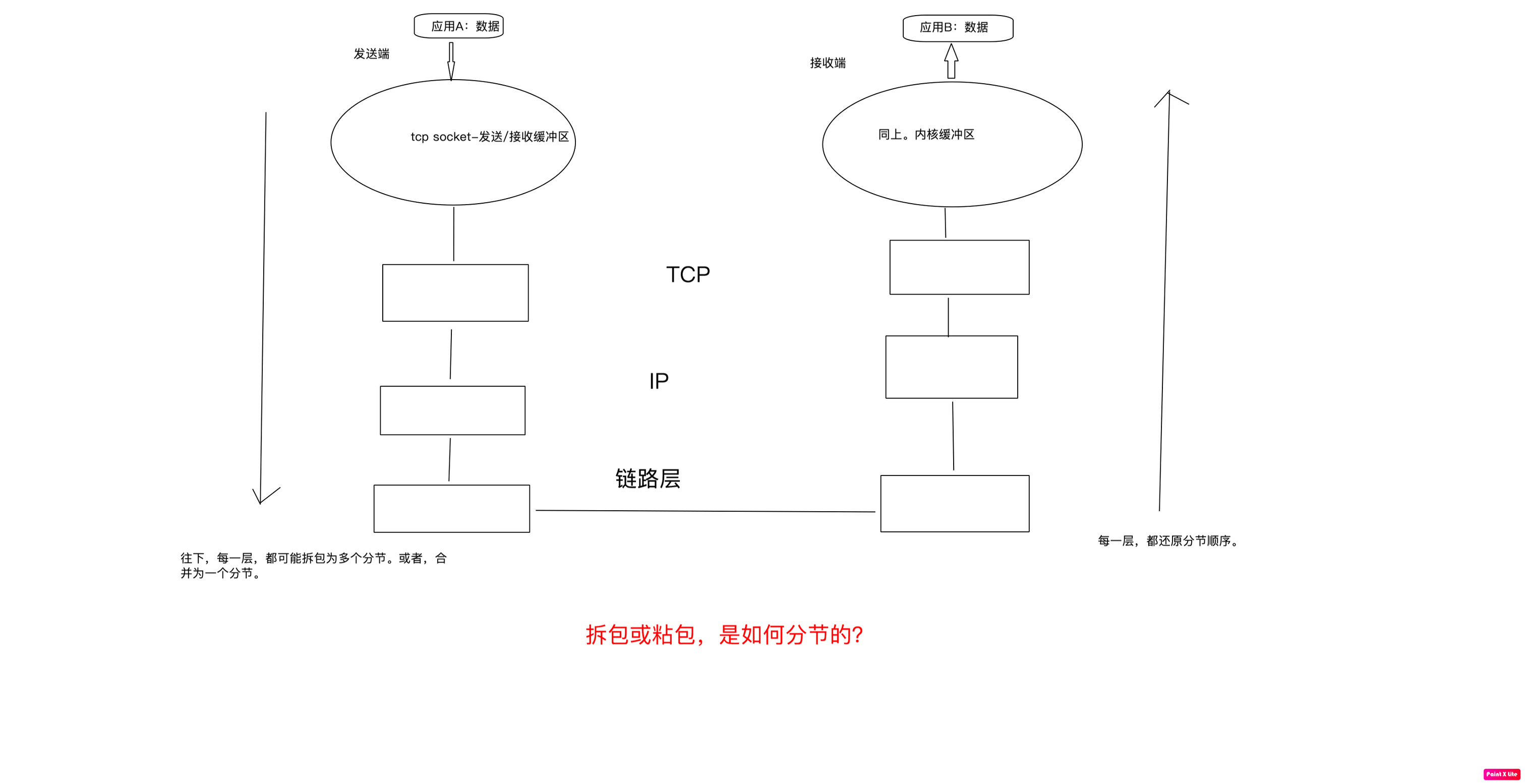
数据包的路由
中间经历很多路由器
错误的理解
TCP协议层已经解决粘包 拆包问题,为什么还要应用层去解决呢
TCP协议层标记了数据包的顺序,但是接受方收到后如何排序?数据不是以流的形式存在吗?总数据长度固定,这个可以区别不同的请求数据。但是接收方怎么解决同一次请求的不同数据包排序的问题?
数据包的顺序不需要应用层解决,因为tcp协议层和操作系统内核已解决。
本质是要识别某一次数据的总长度和先后顺序
1.总长度确定
2.先后顺序编号 //这个是TCP网络协议层已经解决的,不需要应用层解决
所有的解决方法都是围绕以上两个问题,然后解决以上两个问题。
总结
上面的理解都是有问题的,错误的。
首先,关于顺序编号,有两种1.每个数据包(即分节)都有编号 2.分节里的每个字节,都有编号。不过,不管是哪一种编号,目的都是为了在接收端重新排序还原数据原始顺序。
其次,没有什么总长度,只有每个数据包的长度。当然,每一层的数据包都有可能被拆分成多个分节(即子包),所以,每个数据包的长度只是知道它自己(即当前数据包)的长度,而不知道要发送的整个数据的总长度。所以,这个时候,才需要我们应用层去解决拆包和粘包的问题,说白了,就是要找到两次数据的边界在哪里,比如,我聊天的时候发送了两次数据(两条消息),所谓的拆包和粘包,就是要解决如何区别这两个数据的问题。当然,短数据,一般就一个数据包。
最佳实践
应用层才需要解决拆包 粘包的问题,不过,我们具体开发程序的时候,一般使用netty这样的通信框架,也就是说,netty这样的通信框架,已经帮助我们处理了拆包 粘包的问题。netty这样的通信框架,处理的就是传输层tcp socket的拆包 粘包问题。
具体如何处理?
netty有不同的解决方案类,这些解决方案类,每个都是对应一个解决方案。具体的解决方案,就是:
1.分隔符标志
使用分隔符,区分数据
2.总长度
使用总长度,区分数据。注意,这里的总长度,是应用层协议的数据的总长度,而不是传输层的总长度,服务器端和客户端两边就通过应用层协议的报文的数据结构的总长度字段,来区分数据。
粘包和拆包的解决方法有什么不同吗?
这他妈都是问题啊,一堆问题,说明你根本没有理解清楚。只是知道一点理论。这不是学习的好方法啊。
不管是拆包,还是粘包,本质上要解决的问题是,区分两次发送的数据。具体的办法是,
1.要么使用分隔符区分
2.要么使用总长度
使用分隔符,比如,http,使用换行符。
总长度,比如,netty。
一般的应用层协议都是使用总长度。
http协议
请求行
头部字段
内容
以上三项是通过换行符分离。如果包含了换行符,那么转义字符。
netty是如何解决粘包 拆包
之前有总结过。解决方案是不同的解决方案有不同的类。
细节。参考那篇笔记。
原理肯定是和前面提到的原理一样。
time_wait状态
客户端主动关闭时的最后一个状态
TCP状态有11种
客户端和服务器,都有11种状态。
状态转换图
总共好几张图,很重要,很经典
接受端-内核缓冲区:已使用和未使用
接受端-内核缓冲区,包含了已使用和未使用这些数据,并且会把这些数据发送给发送端。而这就是所谓的窗口大小,知道了接受端的剩余大小,发送端就可以控制发送速度和发送数据的流量大小。
规范RFC
网络和协议这一块,所有的官方标准和规范,就是RFC文档。
UDP
User datagram protocol用户数据报文协议。
和TCP最大的区别就是,不可靠。
为什么要分层?
为何要分层?分层的本质?每一层的本质?
每一层解决一个问题,不分层也可以,但是,这样的话,就是一个层解决所有问题。
这就MVC框架一样,每一层解决不同的问题。
比如,IP网络层,包含了源IP和目的IP,主要作用是找到对方机器,把数据路由过去。
而,TCP传输层,是确保数据传输过程当中的可靠性。具体来说就是1.接受者必须收到数据2.数据不能丢失,否则服务器重发3.数据不能重复,否则客户端去重。
为什么连接是三次,关闭是四次?
因为连接的时候,服务器的确认和同步一起发送。
而,关闭,服务器是分开发送。即先发送确认,再发送关闭。
为什么连接和关闭,服务器端,一个可以一起发送,一个只能分开?这个是根据响应时间来确定的。即,如果响应(不管是连接-同步Syn,还是关闭-FIN,还是读写数据-响应,这三种情况其实本质上都是响应)的时间是毫秒级别200ms,那么一起发送,如果是秒级别1s,那么分两次发送,先发送确认,后发送响应。
连接的syn分节,是不带数据的,只包含头部字段。
谁先关闭?
一般都是客户端主动关闭。早期http1.0是短连接,所以是服务器主动关闭,后期1.1是长连接,客户端先关闭。
TCP的底层知识
TCP协议是可靠的协议,主要确保几点:
1.数据有序
编号。
每个分节编号(比如,12345)。
每个字节编号(比如,第一个分节1~1000,第二个分节1000~2000)。
编号的目的是,由发送端编号,接受端收到数据之后,如果乱序,那么重新还原顺序。
2.数据不能丢失
丢失是指接受端没有收到,发送端要重发。具体实现原理是?接受端是否接受到数据,需要发送确认给发送端。
3.数据不能重复
接受端,如果收到重复分节数据,那么抛弃重复数据,因为数据分节有编号。
应用层协议
正因为非应用层的协议,确保了数据有序,现在剩下来的唯一要解决的问题,就是怎么区分不同的数据。
因为数据是流,TCP协议的socket是基于字节流来通信的。
怎么区分?
首先要确认一点的是,必须由应用层协议来解决。
其次,就是具体的解决方法的问题,一般有两种方法:
1.分隔符
2.应用层协议的数据报文的数据结构,有一个数据报文的总长度字段
---附加---
什么是粘包 拆包
2个数据包变成一个包 是粘包
2个包变成了3个包 是拆包
解释
首先,要明白两个概念
1.报文/消息/文件
当前这一次发送的完整内容
2.数据包
一个大的报文1如果一次发送不完 会被拆分为多个小的数据包1数据包2
其次,还要知道tcp协议里包含了缓冲区这个东西 发送数据的流程是:
用户进程——操作系统内核的缓冲区——网络——目标机器
在用户进程——内核的缓冲区
这一步(这一步是完整报文),数据的流程是这样的,
1.先把数据复制到缓冲区
2.缓冲区的数据什么时候到网络 看情况。所以在缓冲区——网络这一步(这一步是数据包-完整报文的一部分),每个数据包的内容会出现以下几种情况:
1.报文1
2.报文2
3.报文1的部分数据 + 报文2 //3 4是拆包,就是有一个报文的数据被拆分成了两部分
4.报文2的部分数据 + 报文1
5.报文1 + 报文2 //5是粘包 就是两个报文在一个数据包里
为什么会出现粘包和拆包的情况?
发生TCP粘包、拆包主要是由于下面一些原因:
应用程序写入的数据大于套接字缓冲区大小,这将会发生拆包。
应用程序写入数据小于套接字缓冲区大小,网卡将应用多次写入的数据发送到网络上,这将会发生粘包。
进行MSS(最大报文长度)大小的TCP分段,当TCP报文长度-TCP头部长度>MSS的时候将发生拆包。
接收方法不及时读取套接字缓冲区数据,这将发生粘包。
……
总结
关键在一点
1.缓冲区的数据什么时候到网络 不确定 要看情况
另外
2.缓冲区的大小很大程度上决定了什么时候缓冲区数据到网络
底层原理
之所以会发生所谓粘包 拆包的原因是因为tcp协议这一层的数据是字节流,接受数据方不知道数据什么时候该结束。
粘包与拆包是由于TCP协议是字节流协议,没有记录边界所导致的。 所以如何确定一个完整的业务包就由应用层来处理了。 (这就是分包机制,本质上就是要在应用层维护消息与消息的边界。) 分包机制一般有两个通用的解决方法:
1,特殊字符控制,例如FTP协议。
2,在包头首都添加数据包的长度,例如HTTP协议。
作者:祖春雷 链接:www.zhihu.com/question/37… 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
为什么是应用层解决拆包 粘包?tcp层协议不是有报文长度字段吗?
解决方法
只能在上层/应用层协议(即应用层)解决这个问题。几种方法
1.换行符
2.头部和数据部分
头部的长度字段规定报文长度
3.固定长度
netty怎么解决?
以上三种方法 netty都有对应的类。
换行符-需要处理包含换行符的情况
转义字符? 转义为什么能解决问题? java转义字符?
报文到底是什么
要发送的完整内容
报文和数据包的区别
1.报文是完整的信息 即你要发送的内容 比如 聊天文字 文件 http请求消息/响应消息
2.如果是短消息 比如聊天文字 一个数据包就够了 这个时候数据包就是报文 基于udp报文协议
如果是大数据 比如文件 一个数据包不够 就多个数据包 这个时候一个完整报文分为多个数据包 基于tcp数据包协议
blog.51cto.com/91xueit/135…
不同协议层的叫法可能不一样
总结一下。frame对应mac,packet对应ip,datagram对应udp,segment对应tcp,message对应app。希望对大家有用。
blog.csdn.net/wang7dao/ar…
http协议的报文
1.请求
请求行
请求头部字段 //包含请求体的长度字段
内容
2.响应
同上
字节序号
字节流的字节可能乱序 接受方通过字节序号还原发送顺序。
为什么会乱序
因为两个电脑之间传输数据 中间经过很多的路由器路由转发 不同的报文走的可能是不同的路径 到达目标ip的时间先后顺序可能不一样
是字节序号还是数据包序号
都有编号。
不管是哪一种序号 编号的目的都是为了解决接收方还原数据顺序的目的。
接收方具体是如何实现还原的?
通告/窗口大小
就是tcp缓冲区剩余内存大小
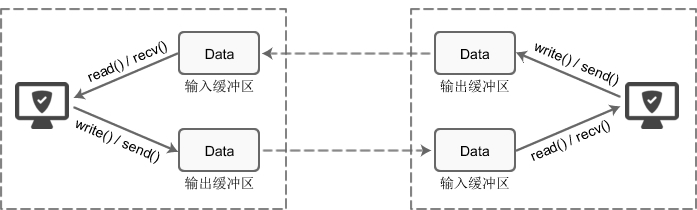
tcp缓冲区是什么?
分类
有发送缓冲区和接收方缓冲区
是什么
两个套接字 各自都有写和读缓冲区。
套接字的缓冲区是基于tcp协议的缓冲区,二者一一对应
套接字编程时 有发送缓冲区和接受缓冲区字段可以设置值的大小
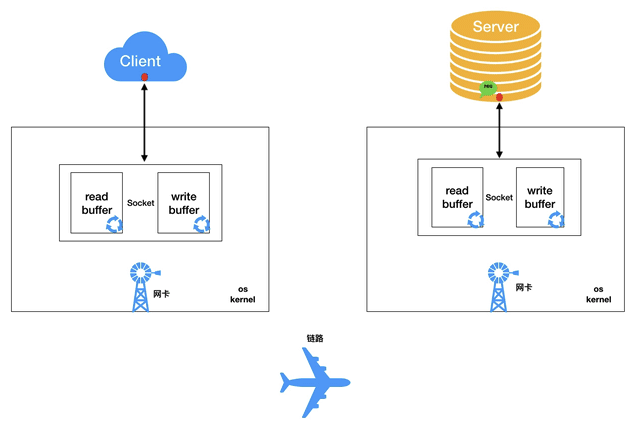
我们平时用到的套接字其实只是一个引用(一个对象ID),这个套接字对象实际上是放在操作系统内核中。这个套接字对象内部有两个重要的缓冲结构,一个是读缓冲(read buffer),一个是写缓冲(write buffer),它们都是有限大小的数组结构。
当我们对客户端的socket写入字节数组时(序列化后的请求消息对象req),是将字节数组拷贝到内核区套接字对象的write buffer中,内核网络模块会有单独的线程负责不停地将write buffer的数据拷贝到网卡硬件,网卡硬件再将数据送到网线,经过一些列路由器交换机,最终送达服务器的网卡硬件中。
同样,服务器内核的网络模块也会有单独的线程不停地将收到的数据拷贝到套接字的read buffer中等待用户层来读取。最终服务器的用户进程通过socket引用的read方法将read buffer中的数据拷贝到用户程序内存中进行反序列化成请求对象进行处理。然后服务器将处理后的响应对象走一个相反的流程发送给客户端,这里就不再具体描述。
作者:老錢 链接:juejin.cn/post/684490… 来源:掘金 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
注:核心流程:用户态——内核态:缓冲区。 所谓的套接字/tcp 缓冲区就是内核态的缓冲区,这个缓冲区在内存,所有缓冲区都是在内存。
用户进程的缓冲区和操作系统内核tcp/套接字的缓冲区?
udp有没有缓冲区?
没有
作用
1.工作流程
数据先到操作系统内核缓冲区,内核有专门线程处理缓冲区的数据用于读写。
2.具体细节
缓冲区满了 一次性读写?不是。看情况。具体见下文。
3.缓冲区本质的作用 或者说好处
缓冲区与窗口大小
二者一样
缓冲区的数据何时被处理 即被发送到网络?
TCP协议独立于 write()/send() 函数,数据有可能刚被写入缓冲区就发送到网络,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。
缓冲区的特性
这些I/O缓冲区特性可整理如下:
I/O缓冲区在每个TCP套接字中单独存在;
I/O缓冲区在创建套接字时自动生成;
即使关闭套接字也会继续传送输出缓冲区中遗留的数据;
关闭套接字将丢失输入缓冲区中的数据。
tcp默认是阻塞的
比如
1.服务器
阻塞接受客户端连接
2.客户端
同上
参考
unix网络编程
