

昨天的博客我解释了HASHMAP(JDK1.7)在PUT的时候会发生冲突,而解决冲突的方式就是使用链表,那么我们假设HASHMAP存储结构如下图:
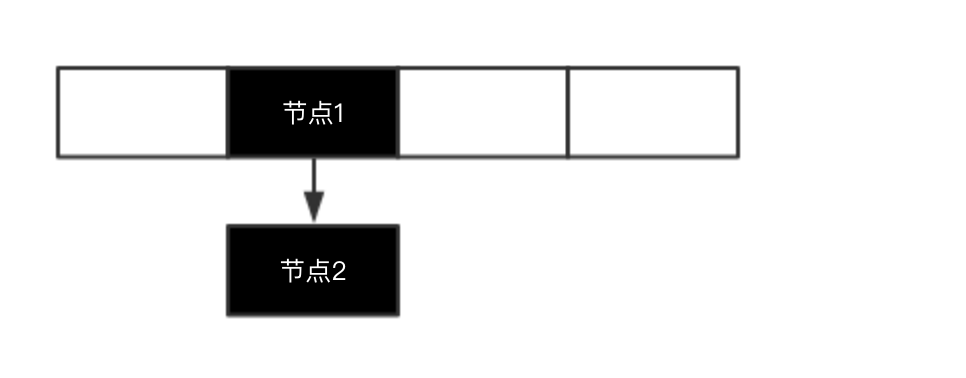
那么节点1和节点2组成了一个链表,那么现在如果再来PUT一个节点3,假设节点3也需要插在这个链表中,我们考虑链表的插入效率,将节点3插在链表的头部是最快的,那么就会如下图:
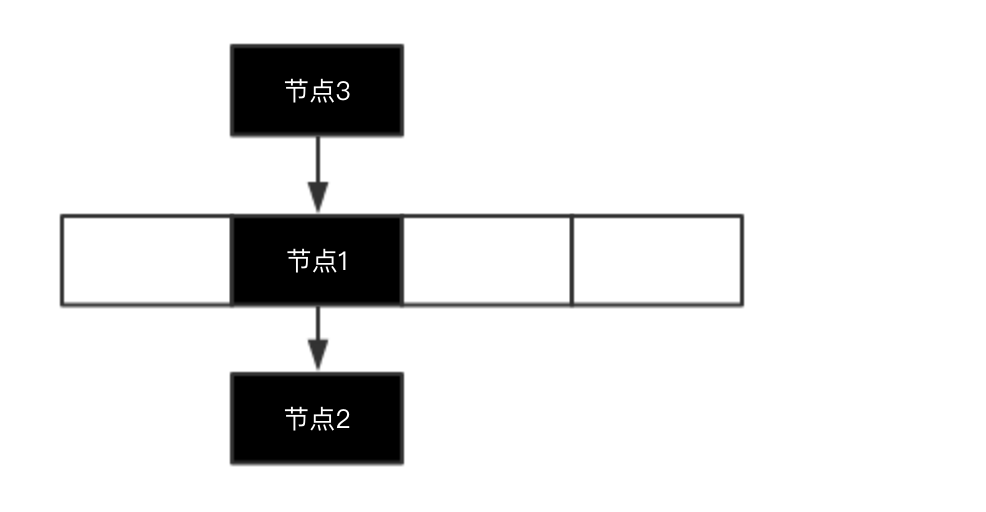
那么按照上图这种插入办法,会出现一个问题:
- 当我们需要get(节点2)时,我们先将节点2的key进行哈希然后算出下标,拿到下标后可以定位到数组中的节点1,但是发现节点1不等于节点2,所以不是最终的结果,但是节点1存在下一个节点,所以可以顺着向下的指针找到节点2。
- 那么当我们需要get(节点3)时呢,我们发现是找不到节点3的,所以当我们把节点简单的插在链表的头部是不行的。
那HashMap是怎么实现的呢?HashMap确实是将节点插在链表的头部,但是在插完之后HashMap会将整个链表向下移动一位,移动完之后就会变成:
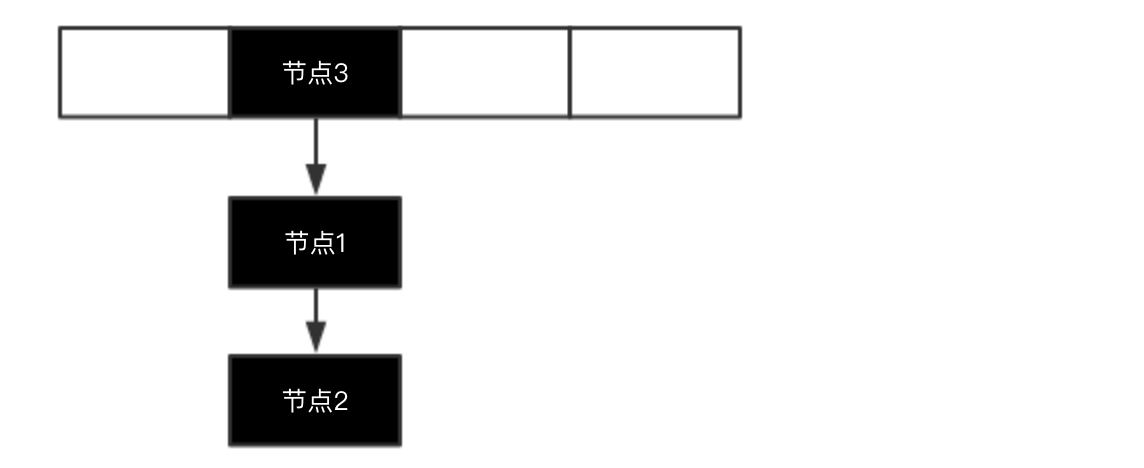
那么现在PUT的时候插入一个元素的思路就是:将新节点插在链表的头部,此时新节点就是当前这个链表的头节点,接下来把头节点移动到数组位置即可。
当我们在使用HashMap的时候,还可能会出现下面的使用方式:
HashMap<String, String> hashMap = new HashMap<>();
hashMap.put("1", "2");
String value = hashMap.put("1", "3");
System.out.println(value);
第三行代码也是PUT,而这个时候在HashMap里会将value覆盖,也就是key="1"对应的value最终为"3",而第三行代码返回的value将会是2。
我们现在来考虑这个PUT它是如何实现的,其实很简单,第三行代码的逻辑也是先对"1"计算哈希值以及对应的数组下标,有了数组下标之后就可以找到对应的位置的链表,而在将新节点插入到链表之前,还需要判断一下当前新节点的key值是不是已经在这个链表上存在,所以需要先去遍历当前这个位置的链表,在遍历的过程中如果找到了相同的key则会进行value的覆盖,并且返回oldvalue。
好,写到这里其实对于HashMap的PUT的主要逻辑也差不多了,总结一下:
- PUT(key,value)
- int hashcode = key.hashCode();
- int index = hashcode & (数组长度-1)
- 遍历index位置的链表,如果存在相同的key,则进行value覆盖,并且返回之前的value值
- 将key,value封装为节点对象(Entry)
- 将节点插在index位置上的链表的头部
- 将链表头节点移动到数组上
这是最核心的7步,然后在这个过程中还有很重要的一步就是扩容,而扩容是发生在插入节点之前的,也就是步骤4和5之间的。
那么关于JDK1.7里HashMap的扩容时会出现“死锁”问题的,我们下篇文章继续。
相信大家不喜欢在小小的手机屏幕上还看到一大块的代码,阅读体验不好,所以我写作的风格会文字偏多一点。如果觉得有所收获就给个小小的赞吧。
