

一、记录我在书中看到的有趣的观点
- Hadoop和传统关系型数据库的比较(P8 1.5 相对于其他系统的优势)
- 为什么不能通过给传统关系型数据库配备大容量硬盘的方式来进行大规模的数据分析?
这个问题的答案来自于计算机硬盘的发展趋势:寻址时间远远比不上传输速率的提升。寻址是将磁头移动到特定的硬盘位置进行读或者写操作,而传输速率取决于硬盘的带宽。而寻址就是导致磁盘操作延迟的主要原因。 当数据量很小时,传统的数据库依靠B树(一种数据结构,主要用于关系型数据库索引),可以实现快速的读取和更新;但是当数据量很大时,因为需要很多的“排序/合并”操作,传统的数据库系统就明显落后于MapReduce了。
- 2007年1月,数据库理论专家Dewitt和Stonebreaker发表《MapReduce:一个历史性的大倒退》,他们这么做的理由是什么?
简而言之,他们认为:1. MapReduce放弃了 很多那些经过历代数据库专家优化提出的高性能数据库技术,比如批量导入、索引、视图、更新、事物等;2. MapReduce是一个粗糙的实现,它没有索引,依靠蛮力作为处理选项;3. MapReduce并不稀奇,之前就已经有人在使用相似的概念并且做出产品来了。
- Hadoop和关系型数据库的另一个区别在于他们所操作的数据集的结构化程度。
结构化数据是指具有既定格式的实体化数据,比如XML文档或者满足特定预定义格式的数据表。这是RDBMS(关系型数据库)包含的技术。 半结构化数据比较松散,它可能有格式,但是经常被忽略,所以一般只能作为对数据结构的一般性指导。比如Excel电子表格,它在结构上是单元格组成的网格,但是你可以在单元格中保存任何格式的数据。 非结构化数据没有什么特别的内部结构,例如纯文本或者图像数据。 Hadoop对半结构化和非结构化数据非常有效,因为它是在处理数据时才对数据进行解释(所谓的“读时模式”)。这种模式在提供灵活的同时,避免了RDBMS在数据加载阶段带来的高开销,因为这在Hadoop中仅仅是一个简单的文件拷贝操作。(这也是为什么Hadoop可以进行高速流式读/写的原因) 关系型数据往往是规范的,,这主要是为了数据的完整性且不含冗余。但是规范性会给Hadoop处理带来麻烦,因为它使记录变成非本地操作,而Hadoop的核心假设之一偏偏就是可以进行(高速的)流读/写操作。(暂时还没理解这句话的意思)而WEB日志就是典型的非规范化数据,例如每次都要记录客户端主机的名字和IP,这会导致同一个客户端的全名可能出现多次。 MapReduce以及Hadoop中其他的处理模型都是可以随着数据规模现行伸缩的(可扩展性)。对数据分区后,函数原语(如map程序和reduce程序)能够在各个分区上面并行工作。这意味着,如果输入的数据量是原来的两倍,那么作业的运行时间也需要两倍。但是如果集群的规模扩展为原来的两倍,那么作业的速度依然可以变得和原来一样快。(分数不够,拿钱来凑...)但是SQL查询不具备这样的特性。 2. 高性能计算和Hadoop计算
- 什么是高性能计算(High Performance Computing,HPC)?
高性能计算相关的组织多年以来一直研究大规模的数据处理,主要使用类似于消息传递接口MPI的相关API。 从广义上讲,高性能计算采用的方法是将作业分散到集群的各台机器上,这些机器访问存储区域网络(SAN)组成的共享文件系统。这比较适合计算密集型的作业。但是如果节点需要访问的数据量更庞大,很多计算节点就会因为网络带宽的瓶颈而不得不闲下来等数据。 而对于Hadoop而言,它尽量在计算节点上存储数据,以实现数据的本地快速访问。这在Hadoop中称为数据本地化。意识到网络带宽是数据中心环境最珍贵的资源(到处复制数据很容易耗尽网络带宽)之后,Hadoop采用显式网络拓扑结构来保留网络带宽(将网络看成一棵树,两个节点之间的距离使他们到共同的祖先的距离综合)。 3. MapReduce数据流(P31 2.4 横向扩展) 首先定义一些术语:MapReduce作业(Job)是客户端需要执行的一个工作单元,它包括输入数据、MapReduce程序和配置信息。而Hadoop将作业分成若干任务(task)来执行,任务有两类:map任务和reduce任务。这些任务运行在集群的节点上,并通过Yarn调度。如果一个任务失败,它Yarn将在另外一个不同的节点上自动重新调度运行。Hadoop将MapReduce的输入数据划分成等长的数据块,称为“输入分片”,简称“分片”。
- 分片后的数据块的大小为什么不能超过HDFS的块大小?
这个数据块的大小应该不能超过HDFS的块大小,原因是:1. 数据本地化。Hadoop在存储有HDFS数据的节点上运行Map任务可以获得最佳性能,因为它无需使用宝贵的集群带宽资源;如果在本地找不到,Yarn就会调度同一个机架上的空闲slot来运行该任务,此时属于同机架内不同节点间调度,有时候还会跨机架调度,但是这种情况几乎见不到。2. 如果分片后的数据跨过了两个HDFS块,由于Hadoop的容灾机制,任何一个节点都不可能同时存储这两个数据块,因此难免会跨节点甚至是跨机架,效率会变得很低。
- map任务将其输出结果写入到本地硬盘,而不是HDFS,为什么?
因为map的输出是中间结果,这个中间结果还要经过reduce处理后才能产生最终结果。而且一旦map作业成功完成,这个中间结果就会被删除;一旦执行失败,就会被重新调度运行。如果把这个中间结果存储在HDFS上并实现备份,未免有点小题大做。
- reduce相关,以及如何确定reduce的数量? reduce的输出通常存储在HDFS中以实现可靠存储。具体做法是:对于reduce输出的每一个HDFS块,第一个副本存储在本地节点上,其他副本处于可靠性存储在其他机架上的节点中。 单个reduce任务的输入通常来自于集群中所有mapper的输出;如果有好多个reduce任务,那么每一个map任务就会针对map的输出进行分区(partition),一个map键对应一个reduce分区。之后进行shuffle(混洗)操作,将不同的map输出按照key分发到不同的reduce中去,结果是每一个reduce中的键值都是相同的。最后reduce会对输入的相同的键值进行merge操作,最后再输出以持久化。
- 什么是combiner函数?
集群的带宽资源很宝贵,因此尽量避免map任务和reduce任务之间的数据传输是有必要的。Hadoop允许用户针对map的输出指定一个combiner(就像map一样),combiner的输入来自map,输出作为reduce的输入。combiner属于优化方案,所以有没有combiner、或者调用多少次combiner,reduce输出的结果都应该是一样的。 简单理解,combiner相当于对map的输出结果进行一个类似于reduce的补充运算,以此来减少mapper和reducer之间的数据传输量。举一个例子,我们的目的是统计1950年全国最高气温,第一个map的输出为((1950,0),(1950,10),(1950,20)),第二个map的输出为((1950,25),(1950,20)),没有combiner的时候,reduce的输入为(1950,[0,10,20,25,20]),最后的输出为(1950,25)。当我们使用combiner之后,第一个map的输出为(1950,20),第二个map的输出为(1950,25),那么reduce的输入为(1950,[20,25]),最后还是输出(1950,25)。更简单的说,我们可以通过下面的表达式来说明这个计算过程: 没有使用combiner:max(0,10,20,25,20)=25。 没有使用combiner:max(max(0,10,20),max(25,20))=max(20,25)=25。 4. 使用自己喜欢的语言实现MapReduce程序(P37 2.5 HadoopStreaming)
- 其他语言如何调用Hadoop接口?
Hadoop提供了MapReduce的API,允许编程人员使用其他的非Java语言来写自己的map函数和reduce函数。Hadoop Streaming 使用 Unix标准输入输出流作为Hadoop和应用程序之间的接口,所以,任何能进行Unix输入与输出的编程语言都能实现MapReduce程序。 map函数的输入来自标准输入,输出结果写到标准输出。map输出的键-值对是以一个制表符(\t)分割的行,并且是经过对键排序的。 reduce的输入来自于标准输入,输出结果写到标准输出(Hadoop可以接受此标准输出,并将其持久化)。reduce的输入与map的输出相同。 5. HDFS(P42 3.1 HDFS的设计)
- datanode和namenode namenode管理着文件系统的命名空间。它维护者文件系统树以及整棵树内的所有文件和目录。namenode 的本地磁盘上永久保存着:命名空间镜像文件 和 编辑日志文件。namenode的内存中保存着文件系统的元数据。 没有namenode,文件系统将无法使用。如果运行namenode的机器损坏,文件系统上的所有文件都将丢失,因为我们不知道如何根据datanode上的数据块来重建完整的文件。为此,我们需要进行容错操作——Hadoop HA(高可用)。 在HA模式中,配置了一对活动-备用namenode(active-standby namenode),当处于active的namenode出现故障,standby namenode会接管它的任务并开始服务来自于客户端的请求,不会有任何明显的中断。具体实现为:1. namenode之间通过高可用实现编辑日志的共享;2. datanode需要同时向两个namenode发送数据块处理报告,这是因为数据块的映射信息存储在内存中而不是本次磁盘中。
- HDFS文件写入的时候,需要进行存储的datanode通过管道连接起来,为什么Hadoop接口要在确认收到所有数据包的确认消息后才会将确认队列删除?datanode的副本该怎么存放?
刚开始我对这块也很好奇:为什么该接口不在确认存入第一个节点之后就返回结果,之后节点之间采用异步的方式将副本同步?后面我看到了这句话:只要写入了dfs.namenode.replication.min的副本数(默认为1),写操作就会成功,并且这个块可以在集群中异步复制,直到达到其目标副本数(dfs.replication的默认值为3)。 namenode选择在哪个datanode上存储副本,要从可靠性、写入带宽、读取带宽之间进行权衡。一般的做法是:第一个副本放在运行客户端的节点上(如果运行客户端的节点不是datanode,那么就随机选择一个不那么忙也不那么满的节点);第二个节点存放在与第一个节点不同的机架上的任意一个节点;第三个节点存放在与第二个节点相同机架的另一任意节点。 6. HDFS的I/O操作(P96 5.1)
- HDFS如何保证数据的完整性? 通过对写入的所有数据计算校验和,并在读取的时候验证校验和。
写数据时:由DataNode负责对所要存储的数据的验证操作。写数据的客户端将数据以及校验和发送给一系列DataNode组成的管线,管线中的最后一个DataNode负责校验操作。如果最后一个DataNode检测到错误,客户端就会收到一个IOException。 读数据时:由客户端进行验证操作。每一个DataNode都会保存一个用于验证的校验和日志,里面记录每一个数据块的最后一个验证时间。客户端收到数据之后进行验证,如果成功,则修改该日志;如果失败,会执行下面的操作:1. 向NameDode汇报出错的数据块block以及这个数据块所在的DataNode,同时抛出ChecksumException异常;2. NameNode将这个block标记为已损坏,这样它就不会再将同样的客户端请求发送到这个节点,同时尝试将这个block的一个副本复制到另外的DataNode,使得数据块的副本因子回到期望值;3. 将这个已经损坏的block删除。 - 序列化操作?
序列化是指将结构化对象转换为字节流以便在网络上传输或者写入到磁盘中进行永久存储的过程。反序列化是指将字节流转回结构化对象的逆过程。 序列化在分布式数据处理有两大应用场景:进程间通信和永久存储。 在Hadoop生态中,系统中多个节点上的进程之间的通信是通过**RPC(Remote Produce Call,远程过程调用)**实现的。RPC协议将消息序列化为二进制流之后发送到远端节点,远端节点接收到二进制流之后将其反序列化为原始消息。通常情况下,RPC序列化有以下特点:紧凑、快速、可扩展、支持互操作。Hadoop编程中使用Writable接口实现序列化。
二、一些细节
(一)、map
- map的阶段有哪些?
- read阶段:通过用户编写的RecordReader,从输入的InputSplit中解析出一个个key/value。
- map阶段:将解析出的kay/value交给用户编写的map函数处理,并产生新的key/value。
- collect阶段:map阶段处理完成后,会调用OutputCollect.collect()输出结果。在这个函数内部, 会将生成的key/value分片(调用partitioner),并将结果写入一个环形缓冲区中。
- spill阶段:缓冲区满后,map会将缓冲区中的文件刷写到本地磁盘,生成一个临时文件。需要注意的是,刷写之前,会先对数据进行一次本地排序(快排),并在必要的时候对数据进行合并(combiner)和压缩(IFile)。
- merge阶段:map对所有的临时文件进行一个合并,确保最终一个map会输出一个数据文件。
- mapper的数量由哪些因素决定?
具体由输入文件数目、输入文件大小、配置的参数决定的。 首先了解配置参数:
mapreduce.input.fileinputformat.split.minsize // 启动map的最小split size ,默认为0
mapreduce.input.fileinputformat.split.maxsize // 启动map的最大split size ,默认为256
dfs.block.size // Hadoop系统中的block块大小,默认为128M
splitsize = Math.max(minsize, Math.min(maxSize,blockSize))
例如:默认情况下,一个输入文件800M,那么mapper的数量应该为7个,其中6个大小为128M,1个大小为32M; 再例如:一个目录下有三个文件,大小分别为5M、10M和150M,那么这个时候会产生四个mapper,它们所处理的数据大小分别为5M、10M、128M和22M; 当然我们也能自定义mapper的数量。比如使上面的mapper数量变成2,一个处理大小为128M、另一个处理大小为37M(5 + 10 + 22),具体实现可以通过设置具体的参数。 2. 环形缓冲区细节:
map task的任务输出首先会进入到一个缓冲区内,这个缓冲区默认大小为100M,当缓冲区达到容量的80%的时候,一个单独的守护进程——spill(溢写)进程会将缓冲区的内容溢写(spill)到本地磁盘。溢写是一个单独的进程,不会影响map端的继续输出,但是当溢写的过程中写入速度过快导致缓冲区满,那么map的写操作就会被阻塞,直到溢写完成。 3. partition细节:
首先要知道的是,默认情况下,不管有多少个map任务,一个reduce任务只会产生一个输出文件。但是有时候我们需要将最终的输出数据分散到不同的文件中去,比如按照省份划分,将同一个省份的数据写入同一个文件中,最终有多个文件。而最终的数据来源于reduce,也就是说,如果要得到多个文件,意味着需要同样数量的reducer运行。而reduce的数据输入来自于map,也就是说,我们要实现多个reduce,得根据map的不同输出做手脚,将不同的map输出按照自定义规则分配给不同的reduce任务。而map任务划分数据的过程称为partition。 partition就是提前对输入进行处理,根据自定义的reduce进行分区,到了reduce处理的时候,只需要处理对应的分区数据就行了。 默认的partition方法如下所示:
public int getPartition(k Key, v Value, int numReduceTasks){
return (key.hashCode() & Inter.MAX_VALUE) % numReduceTasks;
}
前面括号内的结果表示将key的hash值变成一个非负值。numReduceTasks指的是reducer的数量,默认值是1。因为任何一个非负整数除以1的结果是0,也就是说,在默认情况下,getPartition方法的返回值总是1。也就是说,mapper的任务输出总是送给一个reducer,最终只能输出到一个文件中去。这里需要注意的是,如果numReduceTasks的数量为0,那么map会将结果直接刷写到HDFS上去作进一步处理。 当然我们可以重载此方法,进而实现自定义的partition。 对map输出的每一个键值对,系统都会通过这个方法给定一个partition。如果一个键值对的partition值为0,那么它将会交给第1个reducer去处理,partition值为1,会交给第二个reducer去处理。 4. sort和spill细节:
当溢写线程启动的时候,需要对缓冲区中80%的数据做排序。这里的排序是针对序列化的字节根据键值做排序,使用Hadoop自己定义的排序算法,具体实现细节为快速排序法(先按照分区编号partition进行排序,再按照key进行排序),这样的结果是,数据以分区聚集在一起,并且同一个分区中的数据按照key有序。 溢写的时候,按照分区编号由小到大依次将每个分区中的数据写入到任务工作目录的临时文件output/spillN.out(N表示当前溢写的次数)中。 如果设置了combiner,那么这个时候也会进行combiner操作。combiner会将形同key的key/value对的value按照设定的操作,比如加起来,减少溢写到磁盘的数据量。combiner会优化map的输出结果,但是不能对reduce的输出结果产生影响,在这个前提下,combiner是个好东西,会在模型中多次使用。 在优化的时候,为了尽量减少对磁盘文件的I/O操作,可以在这一步对spill的文件进行压缩,使其编程IFile格式,这也将有利于后面的merge操作,因为merge的时候需要根据spill后的文件大小进行排序操作。 5. merge细节:
每一次的spill都会产生一个spill文件,所以map task计算的时候会不断产生很多的spill文件,在map task结束之前会对这些spit文件进行合并形成一个已分区并且排序的输出文件(可以控制一次能够合并多少流,默认是10)0,最终的文件也只有一个,这个过程就是merge。 让每一个map task最终只生成一个数据文件,可以避免同时打开大量文件金额同时读取大量小文件产生的随机读取带来的开销。 每一个map task都有一个缓冲区,存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据以临时文件的形式存放到磁盘,当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉取数据。 merge采用多轮递归合并的方式,首先根据所有文件的大小建立小根堆,然后选取前十个元素,依次迭代读取spill下来的文件中的key-value,并将生成的文件又放回到原来的文件中,之后再次建立小根堆,再执行上面的操作。所以merge的过程可以看成建堆=>选取前十个元素迭代合并=>再建堆=>再合并……
(二)、shuffle
shuffle要做的事是怎么把map task的输出结果有效地传送到reduce端,或者可以这样理解,shuffle描述着数据从map task到reduce task输入的这段过程。 在map处理阶段结束后,会将多个文件合并成一个文件,这个文件中相同分区的数据放在一起,同一个分区中的数据按照key有序。在reduce阶段需要从多个map task中获取属于该reduce的分区的结果值,然后根据获取到的文件大小决定放在内存中还是刷写到磁盘中,也就是说,从每一个map中获取的数据是一段内存或者一个文件,然后对内存和文件进行和map阶段相似的merge操作,将结果中的每一行key/value执行reduce函数。
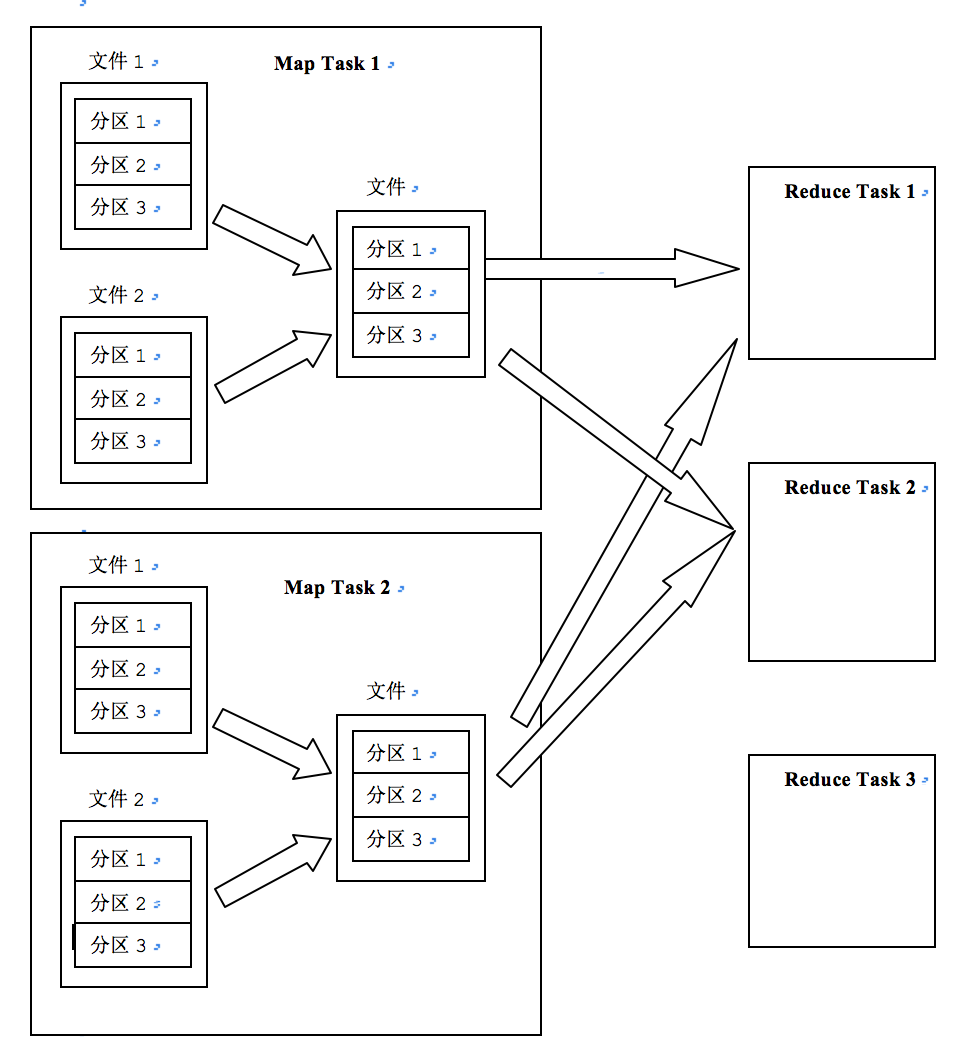
(三)、reduce
- reduce阶段:
- shuffle阶段:也称为copy阶段。reduce task从map task上远程拷贝自己的partition,如果这片数据大小超过一定阈值,那就写到磁盘上,否则直接放到内存中 。所以下面的merge操作会有内存到内存(不使用)、内存到磁盘、磁盘到磁盘的操作。
- merge阶段:根据MapReduce的定义,用户编写的reduce()函数的输入数据是按照key进行聚合的一组数据。为了将key相同的数据聚合在一起,Hadoop采用了基于排序的merge策略。由于每一个map task的结果已经是基于key局部有序的,因此,reduce task进行merge的时候只进行一次归并排序即可。
- reduce阶段:reduce task将每一组数据依次交给用户编写的reduce()函数处理(对每一个键调用reduce()函数)。
- write阶段:reduce()函数将计算结果持久化到HDFS上。
(四)、通过一个例子来了解MapReduce过程
我们的目的是统计两个文件中每个单词出现的总次数。 首先创建两个文件,作为我们的输入:
file 1:
His name is Tom
Tom comes from Yunge
file 2:
His name is Jerry
Jerry comes from Lingge
第一步,map
map,映射,也就是拆解的意思。 我们的输入是两个文件,在默认情况下,会产生两个split,也就是两个mapper:mapper1和mapper2。 接下来,这两个mapper会分别将文件内容分解为单词和1(注意,这里的1不是具体数量,只是数字1),其中单词是我们的主键也就是key,后面的数字就是对应的value。 那么每一个mapper对应的输出为: mapper1:
His 1
name 1
is 1
Tom 1
Tom 1
comes 1
from 1
Yunge 1
mapper2:
His 1
name 1
is 1
Jerry 1
Jerry 1
comes 1
from 1
Lingge 1
第二步,partition
partition,分区。为什么要分区?因为后面会有多个reducer,每一个reducer只干自己的事,这回=会让效率提升不少。partition就是提前对输入进行处理,根据自定义的reduce进行分区,到了reduce处理的时候,只需要处理对应的分区数据就行了。 那么如何分区呢?主要依据就是按照key将数据按照reduce分成对应数量的组,就像汇总硬币一样,一元的进入1号桶,5角的进入2号桶,一角的进入三号桶。这个很重要的一点是需要保证key的唯一性,因此最常见的方法就是使用hash函数。这里我们假设有两个reducer,我们将首字母对应的字母顺序进行除2取模,因此每一个mapper进行partition之后的结果如下:
mapper1:
partition 1:
His 1
is 1
comes 1
from 1
partition 2:
name 1
Tom 1
Tom 1
Yunge 1
mapper2:
partition 1:
His 1
is 1
Jerry 1
Jerry 1
comes 1
from 1
Lingge 1
partition 2:
name 1
其中partition 1是给reducer 1处理的,partition 2是给reducer 2处理的。 可以看到,partition只是按照key进行了简单的分区,并没有任何别的处理,并且每一个分区中的key不会出现在另一个分区里面。
第三步,sort
sort,排序。因为后面的reducer也会做排序,但是它只是做一个归并排序,要求每一个mapper的输出结果也是基于key有序的。这里我们根据首字母进行字典排序:
mapper1:
partition 1:
comes 1
from 1
His 1
is 1
partition 2:
name 1
Tom 1
Tom 1
Yunge 1
mapper2:
partition 1:
comes 1
from 1
His 1
is 1
Jerry 1
Jerry 1
Lingge 1
partition 2:
name 1
可以看到,每一个partition中的数据都按照key做了排序。
第四步,combine
combine可以理解成一个mini reducer,它发生在spill到本次磁盘过程之前,目的就是把送到reducer的数据实现进行一次计算,以减少文件大小、减少对网络带宽的消耗。但是要注意的是,combine操作是可选的,如果要加上,请务必保证经过combine之后的数据不会对最终的reduce结果产生影响。下面我们执行combine:
mapper1:
partition 1:
comes 1
from 1
His 1
is 1
partition 2:
name 1
Tom 2
Yunge 1
mapper2:
partition 1:
comes 1
from 1
His 1
is 1
Jerry 2
Lingge 1
partition 2:
name 1
因为最后reducer执行的操作是add,那么提前add和后面add的效果是一样的,因此这个combiner是有效的。可以看到,结果中,对重复的单词进行了简单的汇总。
第五步,copy
copy,也叫shuffle,就是reducer自己从mapper拉去数据。每一个reducer只拉取属于自己partition的数据,结果如下:
reducer 1:
partition 1:(来自mapper1)
comes 1
from 1
His 1
is 1
partition 1:(来自mapper2)
comes 1
from 1
His 1
is 1
Jerry 2
Lingge 1
reducer 2:
partition 2:(来自mapper1)
name 1
Tom 2
Yunge 1
partition 2:(来自mapper2)
name 1
可以看到,通过shuffle操作,相同partition的数据落到了同一个节点(reducer)上。
第六步,merge
merge,合并。将reducer得到的文件合并成同一个文件,需要注意的是,这个过程也包含了排序。结果如下:
reducer 1:
comes 1
comes 1
from 1
from 1
His 1
His 1
is 1
is 1
Jerry 2
Lingge 1
reducer2:
partition 2:
name 1
name 1
Tom 2
Yunge 1
第七步,reduce
reduce,归并。最终的一步,将相同的key的value加1。结果如下图:
reducer 1:
comes 2
from 2
His 2
is 2
Jerry 2
Lingge 1
reducer2:
partition 2:
name 1
Tom 2
Yunge 1
大功告成!我们统计了两个文件中每一个单词的数目,因为有两个reducer,因此输出结果会有两个文件,即part-000000和part-00001。
(五)、Yarn资源调度框架
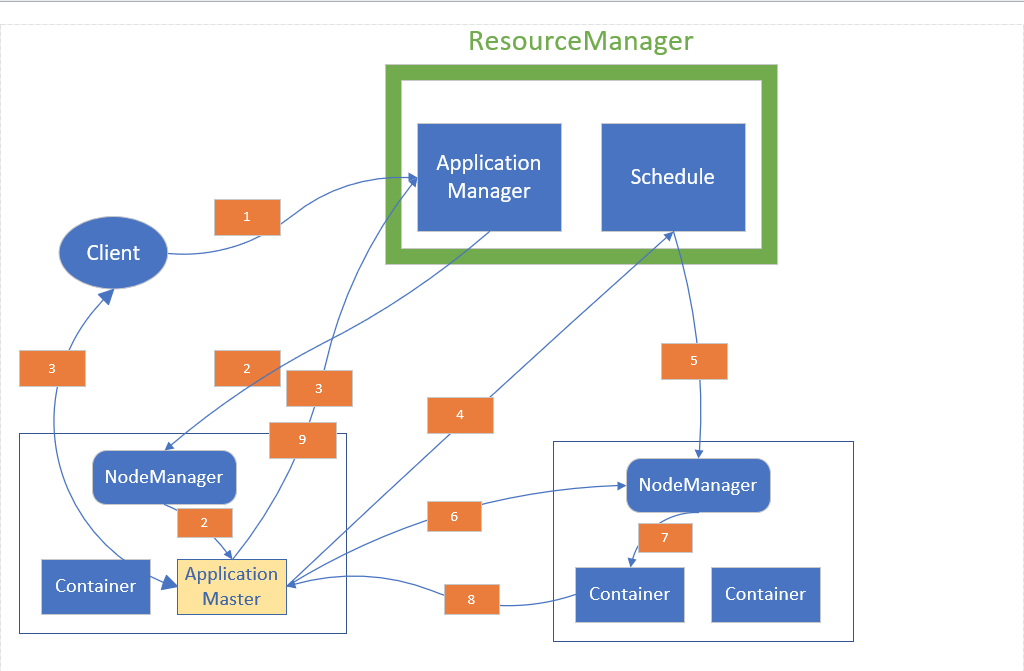
- 客户端向Yarn提交应用并请求获得一个ApplicationMaster实例;
- ApplicationManager找到一个可以运行Container的NodeManager,并在这个Container中启动一个ApplicationMaster实例;
- ApplicationMaster向ApplicationManager注册,注册之后客户端就可以通过查询ResourceManager从而获得自己提交应用的ApplicationMaster的详细信息,之后client就可以和ApplicationMaster直接通信了;
- ApplicationMaster向ResourceManager申请执行此次任务所需要的资源,ResourceManager拥有集群中所有NodeManager的Container(各个节点的资源)的信息,然后通过Scheduler进行调度;
- Scheduler将具体某个NodeManager上的Container的使用权交给这个ApplicationMaster;
- 一旦ApplicationMaster申请到资源之后,便会与该NodeManager通信,要求启动相应的Container执行任务;
- NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等),之后将任务命令写入脚本,并通过脚本启动相应的Container执行任务;
- 每一个任务通过RPC协议向ApplicationMaster汇报自己的状态和任务执行进度,以便让ApplicationMaster掌握每一个子任务的执行状态,一方面可以在任务失败之后重新启动任务,另一方面方便客户端通过ApplicationMaster掌握任务的执行情况;
- 应用程序的任务完成后,ApplicationMaster向ApplicationManager注销并且关闭自己,将用到的所有Container也一并归还系统。
每个组件功能详解:
- Yarn简介: Yarn(Yet Another Resource Negotiator)被称为新一代Hadoop集群的资源调度系统。Hadoop2.0对MapReduce框架进行了彻底的设计与重构,在2.0版本中,它将1.0中的JobTracker拆分成了两个独立的服务:一个全局资源管理器ResourceManager和一个针对局部应用的ApplicationMaster。前者负责整个系统的资源调配和管理,后者只针对某一个应用程序的资源管理。 在Hadoop2.0中,MapReduce中的一个Job变成了application,因为在hadoop2.0中,需要进行资源调度的应用不止MapReduce,还有Hadoop生态中的其他应用,比如storm、hive、Hbase、spark等,这些需要使用Hadoop的底层HDFS应用都需要进行统一的管理,也就是说,通过Yarn,各个应用就可以互不干扰的运行在同一个Hadoop系统中,共享整个集群资源。 需要注意的是,2.0中的MapReduce和第一代的MapReduce的编程接口、数据处理引擎(map task和reduce task)是完全一样的,可以认为MRv2重用了MRv1中的这些模块,不同的是资源管理和作业调度系统。MRv1中资源调度和作业管理均由JobTracker实现,集两个功能于一身;而在MRv2中,将这两部分分开了,其中作业管理由ApplicationMaster实现,而资源管理由新增的系统Yarn(ResourceManager)完成。由于Yarn具有通用性,因此Yarn也可以作为其他计算框架的资源管理系统,比如spark、storm。 Yarn总体上仍旧采用“主/从”架构,在整个集群中,ResourceManager为master,NodeManager为slave,ResourceManager负责对整个NodeManager上的资源进行统一的管理和调度。
- ResourceManager: ResourceManager是一个全局的资源管理器,负责对整个系统的资源进行管理和分配,它主要包含两个组件:Scheduler(调度器)和ApplicationManager(应用程序管理器)。 -- ApplicationManager: 负责管理整个系统中的所有应用程序实例,包括在应用程序提交之后与Scheduler协商启动ApplicationMaster、监控ApplicationMaster的运行状态并在失败时候重启它等等; -- Scheduler: 它是一个纯调度器,它只执行调度任务,不参与任何与具体应用程序相关的工作。它仅仅根据ApplicationMaster的具体需求进行集群资源的分配。此外,Scheduler是一个可插拔的组件,用户可以自定义。
- ApplicationMaster: 用户没提交一个应用程序,ApplicationManager会找到一个可以运行Container的NodeManager,并在这个Container中启动一个ApplicationMaster实例,之后这个实例会向ApplicationManager进行注册,将自己的更多信息告诉ApplicationManager,以便客户端能和ApplicationMaster直接通信获得任务运行的更多信息。ApplicationMaster会根据实际的任务需求向ResourceManager申请运行任务所需要的资源,之后Scheduler会根据请求分配具体的NodeManager上的Container给它管理。任务运行完成后,ApplicationMaster会向ApplicationManager申请注销并关闭自己,同时归还所占用的所有系统资源。
- NodeManager: NodeManager运行在集群中的slave节点上,每一个节点都会有自己的NodeManager。它是一个slave服务:负责接收ResourceManager的资源分配命令,将自己的某个具体Container分配给ApplicationMaster,管理每一个自己的Container的生命周期。同时它还负责监控并报告自己Container中的状态信息给ResourceManager,达到资源分配和监控的目的。
- Container: Container是Yarn框架中具体的计算单元,执行具体的计算任务。一个Container就是一组待分配的系统资源,这组资源包括:CPU、内存。因为一个Container指的是某个节点上具体的计算资源,那么Container中必定含有该计算资源的位置信息:位于哪个机架上的哪个NodeManager上面,所以我们请求某一个Container的时候,实际上是直接请求该台机器上的CPU和内存资源。在Yarn框架中,一个application必须运行在一个或者多个Container之中,ResourceManager只负责告诉ApplicationMaster哪个NodeManager上面的Container可以使用,ApplicationMaster还得自己去NodeManager上去请求具体的Container。
(六)、写一个Wordcount的MapReduce Java程序
0. 预览被统计的文件格式
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-dependency-plugin</artifactId>
<configuration>
<excludeTransitive>false</excludeTransitive>
<stripVersion>true</stripVersion>
<outputDirectory>./lib</outputDirectory>
</configuration>
</plugin>
</plugins>
</build>
2. 新建mapper内部类
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@java.lang.Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String words = value.toString(); // 传进来一行数据,先将其转换成string
String[] wordsArr = words.split(","); // 因为是csv文件,所以使用","作为列分隔符
context.write(new Text(wordsArr[0]), new LongWritable(1)); // 以省份作为键值,value固定为1
context.write(new Text(wordsArr[0] + "," + wordsArr[1]), new LongWritable(1)); // 以(省份,市)作为键值,value固定为1
}
}
2. 新建reducer内部类
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
/**
* 输入格式 : <word,[1,1,1,1]>
*/
Long sum = 0L;
for (LongWritable value : values
) {
sum += value.get(); // 实现value的累加
}
context.write(key, new LongWritable(sum)); // 将结果输出
}
}
3. 实现主方法
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1. 创建一个job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word-count");
// 2. 将类名打包成Jar包
job.setJarByClass(WordCount.class);
// 3. 输入文件地址
FileInputFormat.addInputPath(job, new Path(args[0]));
// 4. mapper处理逻辑
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 5. reducer处理逻辑
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 6. shuffle过程
// 暂不处理
// 7. 定义输出地址
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 8. 运行结果显示,如果成功就输出"成功",否则输出"失败"
boolean result = job.waitForCompletion(true);
System.out.println(result ? "成功": "失败");
}
4. 整个WordCount.java完成代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCount {
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
LongWritable one = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String words = value.toString();
String[] wordArr = words.split(","); // 将每一行数据拆分成每个单词
// context.write(new Text(wordArr[0]), one); // 统计某个省的学校数量
context.write(new Text(wordArr[0] + "," + wordArr[1]), one); // 统计某个市的学校数量
}
}
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
/**
* 输入格式 : <word,[1,1,1,1]>
*/
Long sum = 0L;
for (LongWritable value : values
) {
sum += value.get(); // 实现value的累加
}
context.write(key, new LongWritable(sum)); // 将结果输出
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1. 创建一个job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word-count");
// 2. 将类名打包成Jar包
job.setJarByClass(WordCount.class);
// 3. 输入文件地址
FileInputFormat.addInputPath(job, new Path(args[0]));
// 4. mapper处理逻辑
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 5. reducer处理逻辑
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 6. shuffle过程
// 暂不处理
// 7. 定义输出地址
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 8. 运行结果显示,如果成功就输出"成功",否则输出"失败"
boolean result = job.waitForCompletion(true);
System.out.println(result ? 1 : 0);
}
}
5. 将代码打包成jar包
- 将以Extra开头的依赖都删除
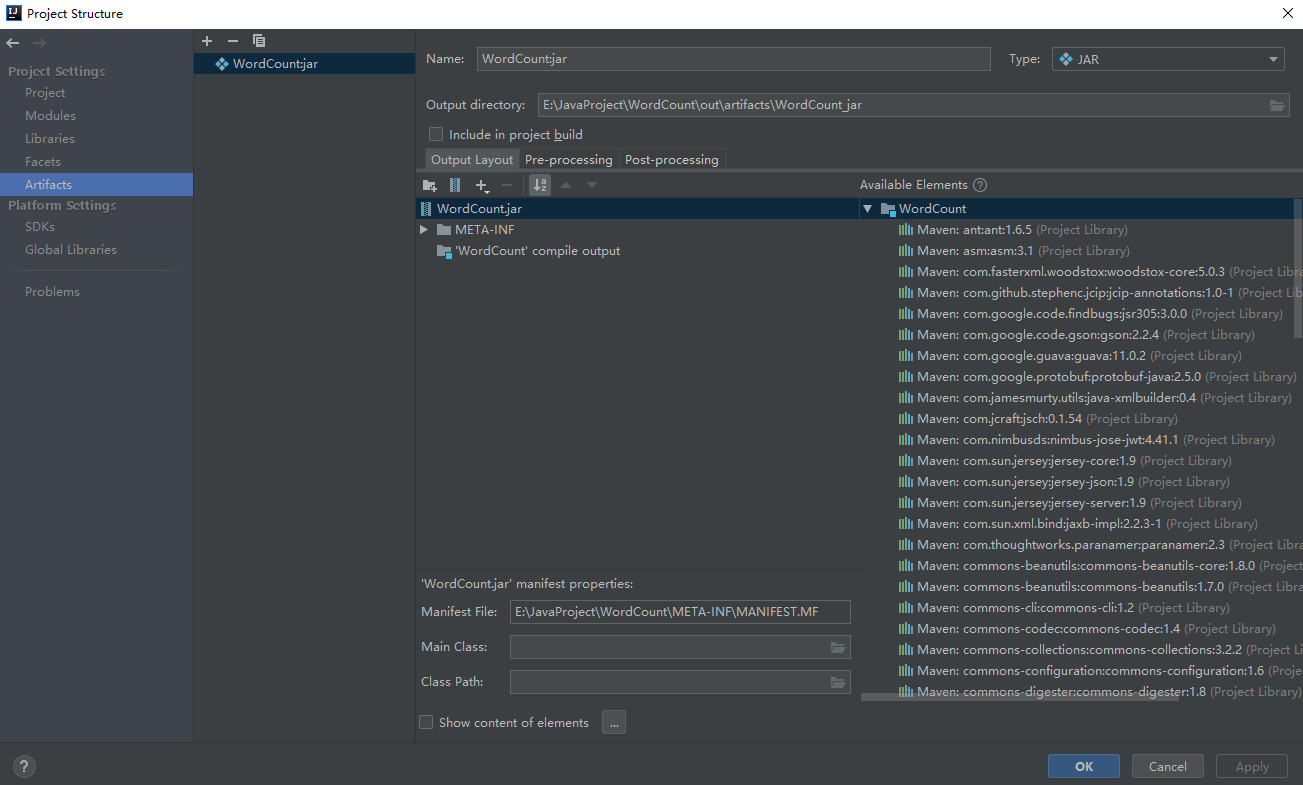
- 点击build->build artifacts->build,填写信息,就能得到包装好的jar包
- 将此jar包上传到集群,执行以下命令:
yarn jar ProvinceCount.jar WordCount hdfs://master:8020/test_data/senior_school_name.csv hdfs://master:8020/test_data/province_out/
# ProvinceCount.jar为jar包名称,WordCount为主类,hdfs://master:8020/test_data/senior_school_name.csv为输入文件(这里是HDFS上的文件),hdfs://master:8020/test_data/province_out/是结果输出文件夹
6. 执行结果: 你可以通过UI界面查看执行情况:
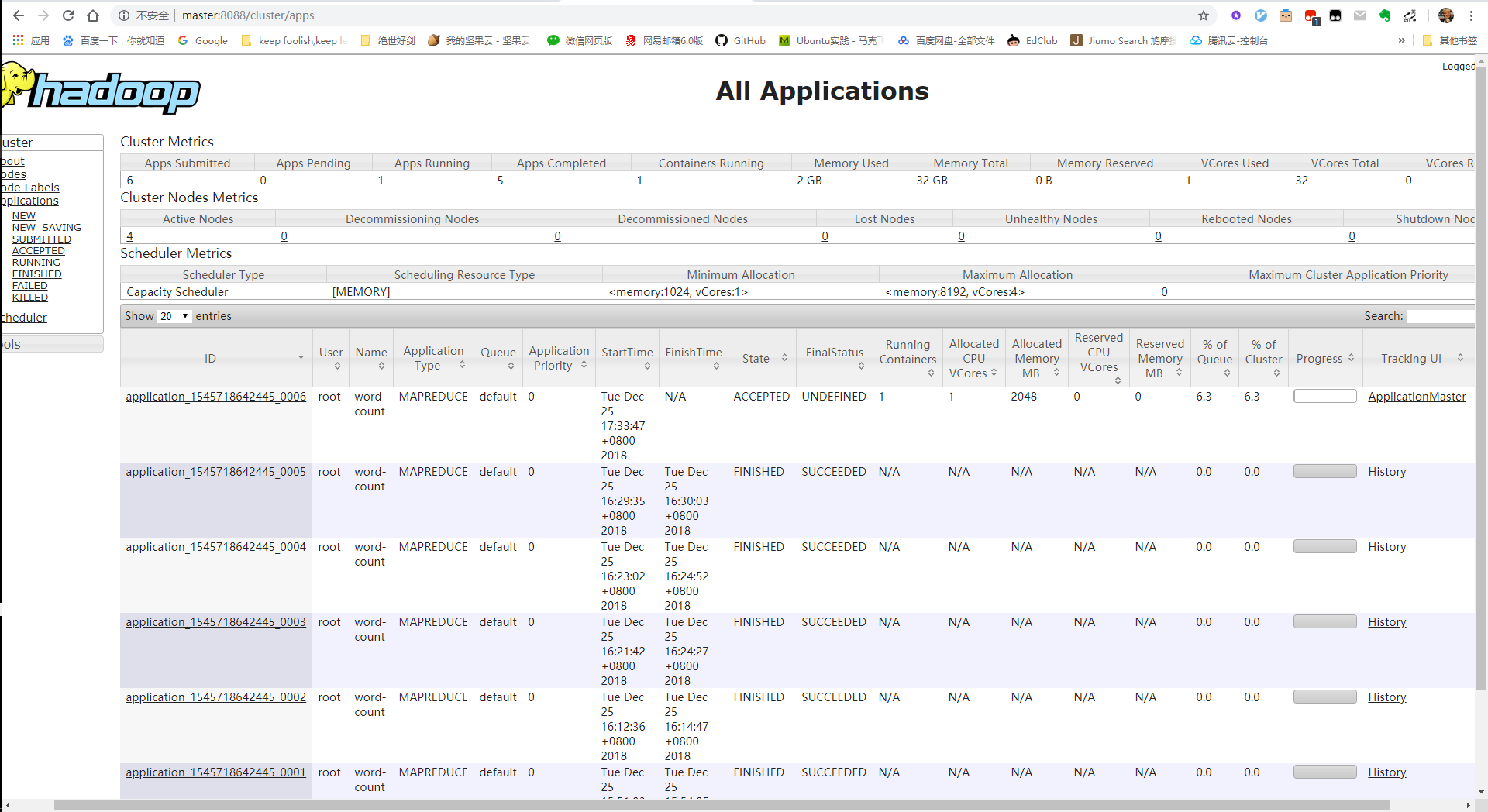
[root@master hadoop-2.9.2]# yarn jar ProvinceCount.jar WordCount hdfs://master:8020/test_data/senior_school_name.csv hdfs://master:8020/test_data/province_out/
18/12/25 04:33:36 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/12/25 04:33:37 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.111.132:8032
18/12/25 04:33:37 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/12/25 04:33:43 INFO input.FileInputFormat: Total input files to process : 1
18/12/25 04:33:45 INFO mapreduce.JobSubmitter: number of splits:1
18/12/25 04:33:45 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
18/12/25 04:33:47 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1545718642445_0006
18/12/25 04:33:47 INFO impl.YarnClientImpl: Submitted application application_1545718642445_0006
18/12/25 04:33:47 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1545718642445_0006/
18/12/25 04:33:47 INFO mapreduce.Job: Running job: job_1545718642445_0006
18/12/25 04:34:42 INFO mapreduce.Job: Job job_1545718642445_0006 running in uber mode : false
18/12/25 04:34:42 INFO mapreduce.Job: map 0% reduce 0%
18/12/25 04:36:12 INFO mapreduce.Job: map 100% reduce 0%
18/12/25 04:36:21 INFO mapreduce.Job: map 100% reduce 100%
18/12/25 04:36:22 INFO mapreduce.Job: Job job_1545718642445_0006 completed successfully
18/12/25 04:36:22 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=660893
FILE: Number of bytes written=1719115
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1536880
HDFS: Number of bytes written=362
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=84094
Total time spent by all reduces in occupied slots (ms)=6551
Total time spent by all map tasks (ms)=84094
Total time spent by all reduce tasks (ms)=6551
Total vcore-milliseconds taken by all map tasks=84094
Total vcore-milliseconds taken by all reduce tasks=6551
Total megabyte-milliseconds taken by all map tasks=86112256
Total megabyte-milliseconds taken by all reduce tasks=6708224
Map-Reduce Framework
Map input records=38356
Map output records=38356
Map output bytes=584175
Map output materialized bytes=660893
Input split bytes=116
Combine input records=0
Combine output records=0
Reduce input groups=31
Reduce shuffle bytes=660893
Reduce input records=38356
Reduce output records=31
Spilled Records=76712
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=1346
CPU time spent (ms)=12980
Physical memory (bytes) snapshot=332660736
Virtual memory (bytes) snapshot=4213764096
Total committed heap usage (bytes)=137498624
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1536764
File Output Format Counters
Bytes Written=362
成功
[root@master hadoop-2.9.2]#
查看HDFS文件系统中是否有文件输出:
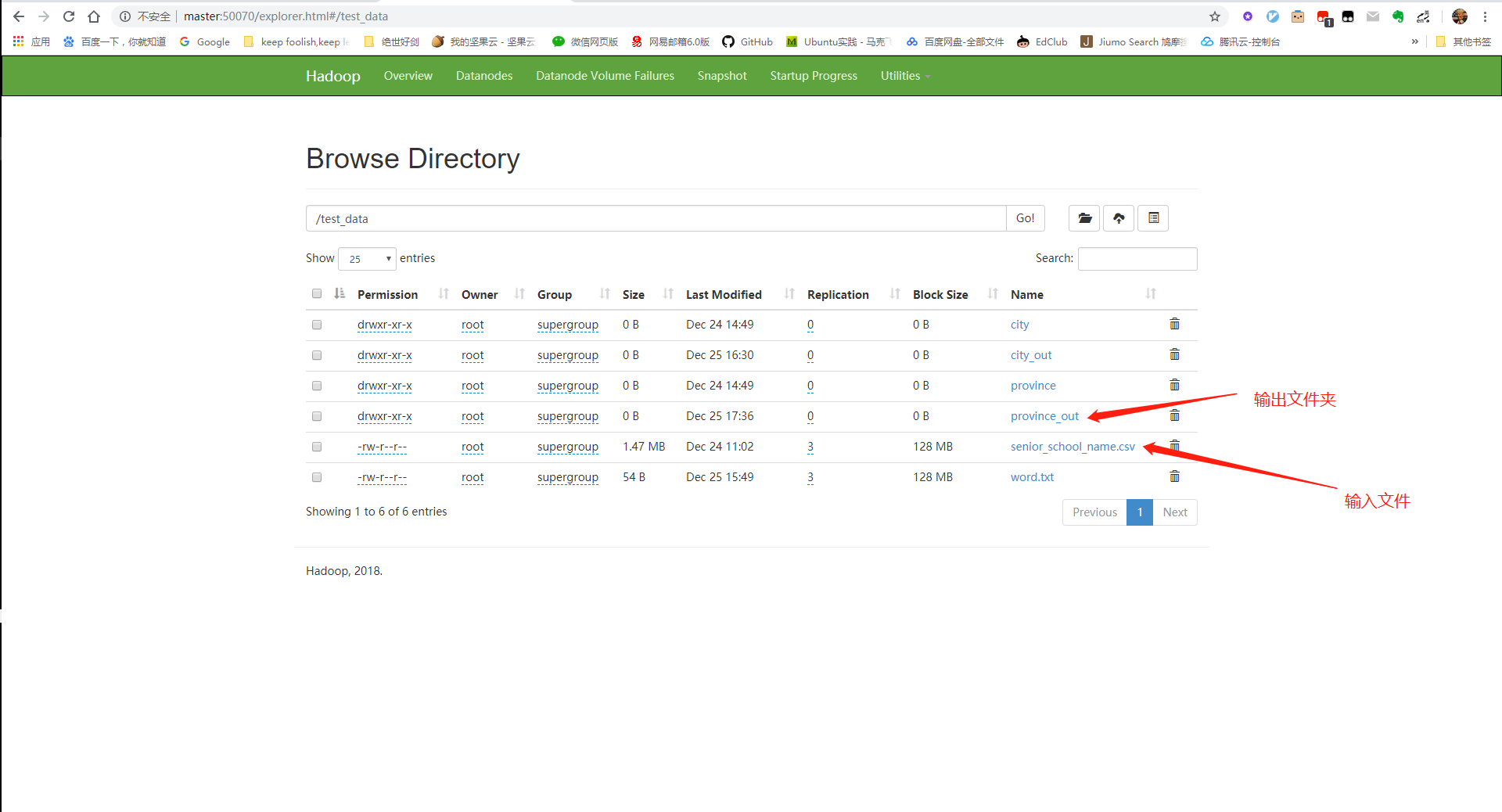
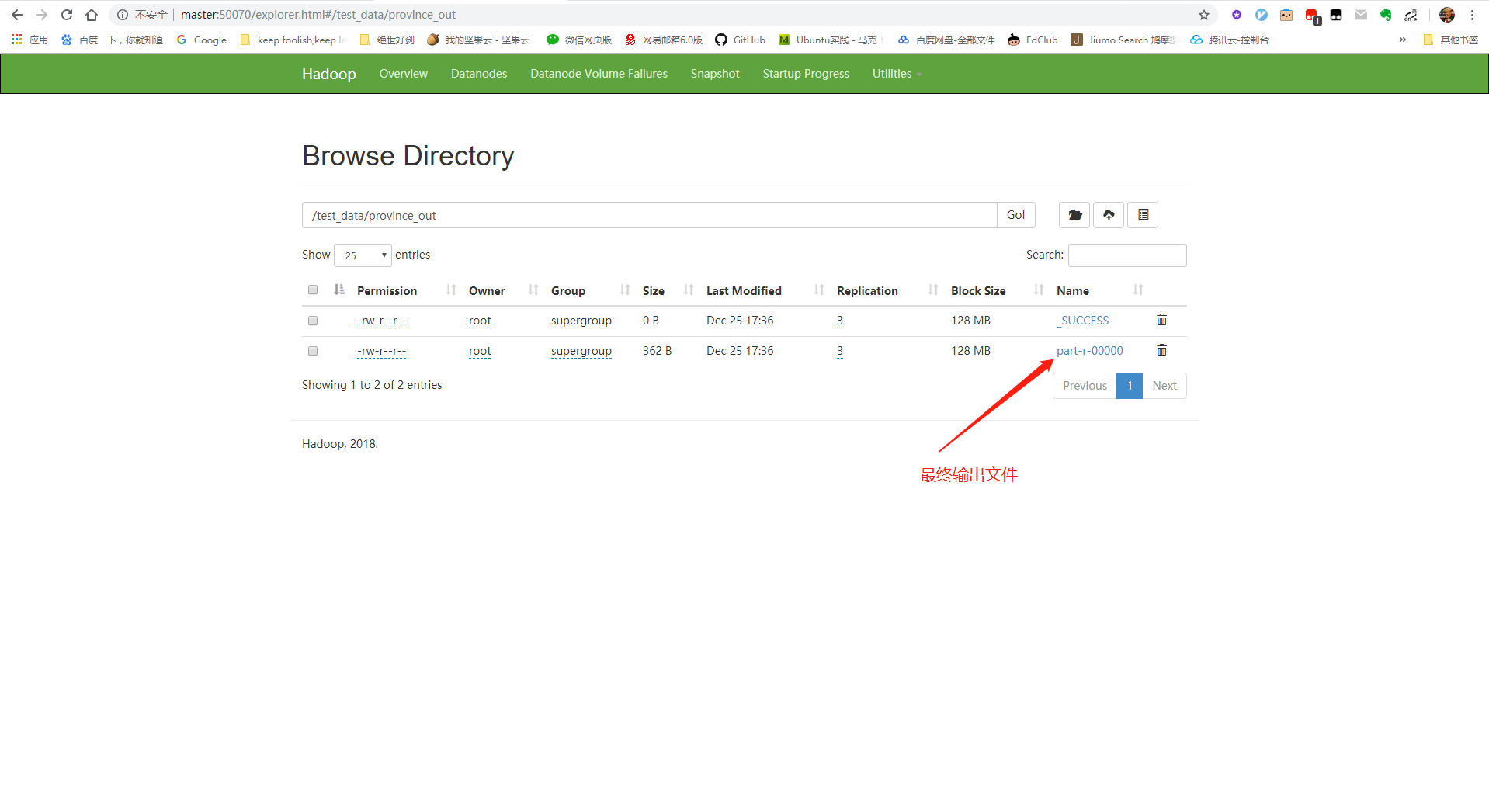
# 在集群shell中输入:
hdfs dfs -text /test_data/province_out/part-r-00000
# 结果如下:
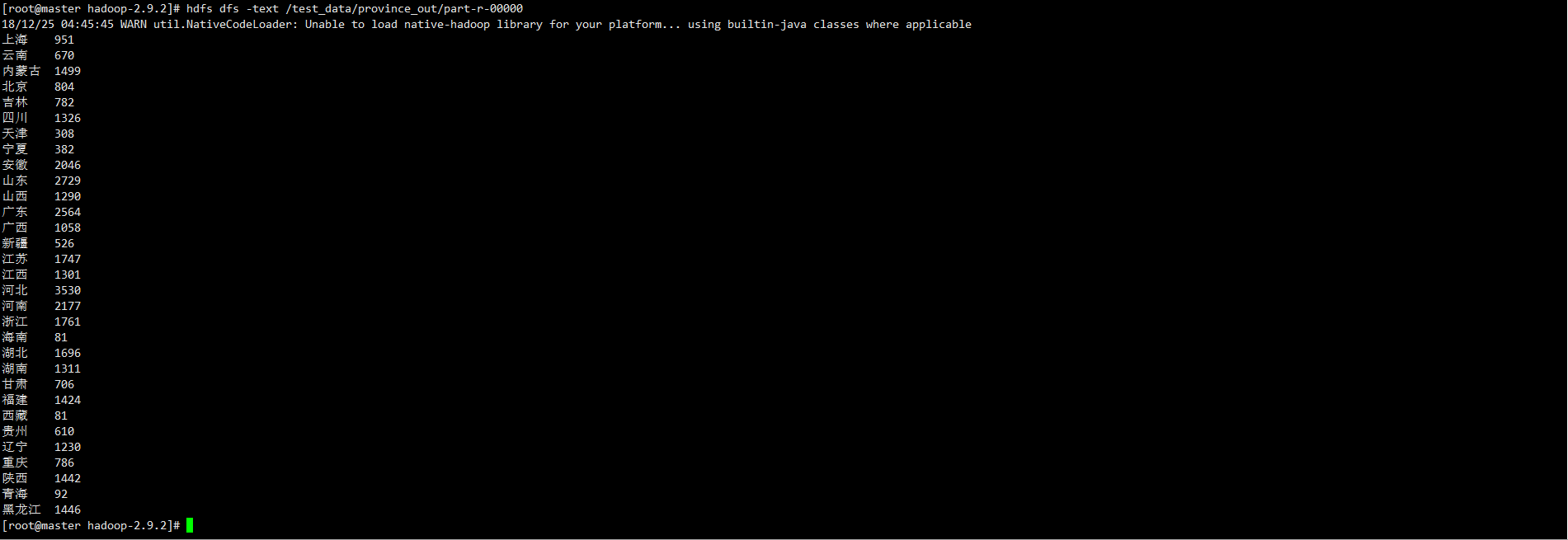
(七)、NameNode和SecondaryNameNode细节:
NameNode:
- NameNode概述: NameNode维护了文件和数据块之间的映射关系和数据块和数据节点之间的映射关系,即一个文件由哪些数据块组成、这些数据块存放在哪些节点上。真正的数据都存放在DataNode上。 NameNode如何存储这些信息呢?它主要维护两个文件:fsimage系统快照文件,和editlog操作日志文件。
- fsimage: 在HDFS启动的时候会加载fsimage上的信息,是整个集群的快照,包括目录的修改时间、权限信息,和文件的数据块描述、修改时间、被访问时间信息等。fsimage保存了最新的元数据检查点,怎么理解呢?fsimage就是整个集群资源的缩略图,集群中所有的资源都通过它的描述展示出来,如果因为某些原因,导致新增了一个block,但是没有通过fsimage和下面要说的editlog同步,那么这个block就永远不会被使用了。
- editlog: editlog在NameNode启动的情况下对HDFS上进行的各种元数据操作进行记录。客户端对HDFS所有的更新操作,比如移动数据、删除操作等,都会记录在editlog中。
SecondaryNameNode
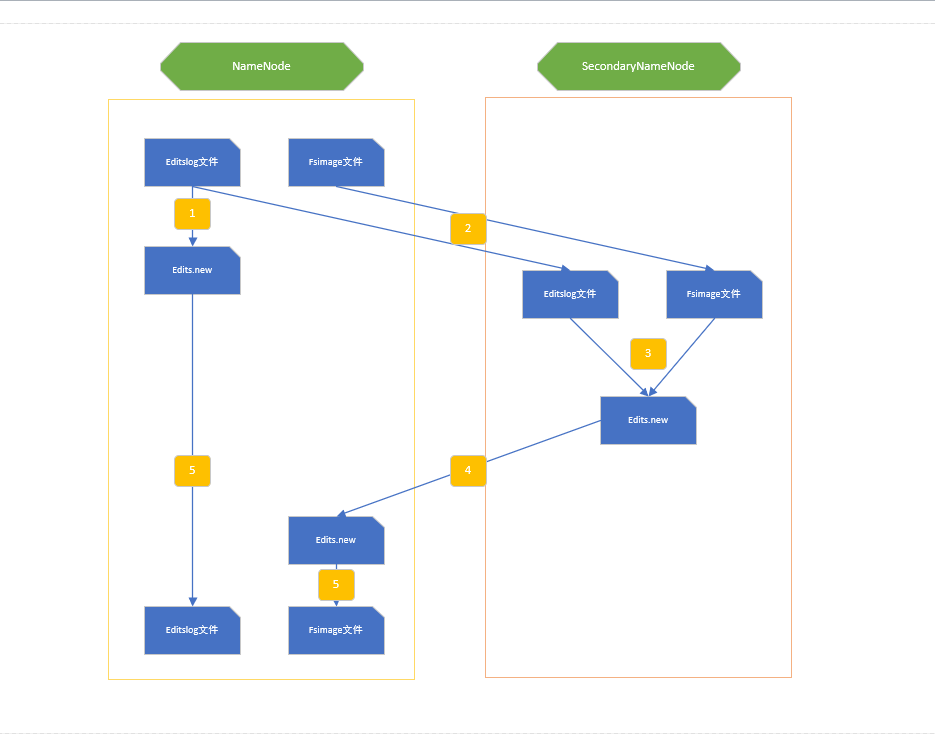
- SecondaryNameNode存在的意义: 刚才提到了editlog,如果持续的进行HDFS的更新操作,那么时间久了如果不将editlog和fsiamge进行合并,editlog会变得非常大;如果经常合并,这会消耗大量的系统资源,会导致NameNode在合并期间几乎不可用。但是不管怎么样,合并是必须的,不能在NameNode上进行合格合并操作,那么可以在别的机器上进行,只要将合并后的fsimage文件传回来就行了,这就是SecondaryNameNode存在的意义。
- SecondaryNameNode合并过程:
(八)、使用zookeeper配置高可用(HA)Hadoop集群:
# 资源说明:
# 1. 三台服务器,分别为master1,master2,slave1
# 2. 使用master1和master2作为HA中的namenode,只有slave1一个datanode
hdfs-site.xml配置
<property>
<name>dfs.nameservices</name>
<value>haojiCluster</value>
<description>集群服务ID</description>
</property>
<property>
<name>dfs.ha.namenodes.haojiCluster</name>
<value>master1,master2</value>
<description>集群服务ID内含有的namenode</description>
</property>
<property>
<name>dfs.namenode.rpc-address.haojiCluster.master1</name>
<value>master1:8020</value>
<description>datanode和namenode RPC通信地址1</description>
</property>
<property>
<name>dfs.namenode.rpc-address.haojiCluster.master2</name>
<value>master2:8020</value>
<description>datanode和namenode RPC通信地址1</description>
</property>
<property>
<name>dfs.namenode.http-address.haojiCluster.master1</name>
<value>master1:50070</value>
<description>访问namenode的http地址(比如ui界面)</description>
</property>
<property>
<name>dfs.namenode.http-address.haojiCluster.master2</name>
<value>master2:50070</value>
<description>访问namenode的http地址(比如ui界面)</description>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master1:8485;master2:8485;slave1:8485/haojiCluster</value>
<description>配置journalnode集群的访问地址</description>
</property>
<property>
<name>dfs.client.failover.proxy.provider.haojiCluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description>配置dfs客户端,用来判断哪个namenode处于活跃状态</description>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<description>为了防止脑裂现象,需要配置一个解决方案,让备用的那个namenode能够通过这个方式去杀掉那个进程,比如ssh</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>~/.ssh/id_rsa</value>
<description>既然需要ssh,那么就需要ssh免密登录</description>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop-2.9.2/journal_data</value>
<description>journal节点目录</description>
</property>
<property>
<name>dfs.replicatio</name>
<value>3</value>
<description>集群副本数</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:////usr/local/hadoop-2.9.2/hdfs/name</value>
<description>hadoop的name目录路径</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:////usr/local/hadoop-2.9.2/hdfs/data</value>
<description>hadoop的data目录路径</description>
</property>
<property>
<name>dfs.namenode.servicerpc-address</name>
<value>master1:10000</value>
<description>hadoop的name目录路径</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
<description>指定在namenode和DataNode之间是否开启webHDFS功能</description>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>通过UI操作hdfs时是否需要权限认证</description>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
<description>自动failover启动</description>
</property>
core-site.xml
<property>
<name>ha.zookeeper.quorum</name>
<value>master1:2181,master2:2181,slave1:2181</value>
<description>zookeeper集群访问地址</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://haojiCluster</value>
<description>集群对外访问ID,客户端拿着这个ID去访问zookeeper集群查出处于活跃状态的namenode的ip和端口,再进行连接</description>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>30000</value>
<description>zkfc超过这个时间连不上zookeeper就会自动退出,默认5s</description>
</property>
<property>
<name>ipc.client.connect.max.retries</name>
<value>20</value>
<description>Indicates the number of retries a clientwill make to establisha server connection.</description>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>5000</value>
<description>Indicates the number of milliseconds aclient will wait for before retrying to establish a server connection.</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.9.2/tmp</value>
<description></description>
</property>
将这个文件复制到其他集群 具体操作
cd /usr/local/hadoop-2.9.2
# 0. 所有节点上启动journal node
sbin/hadoop-daemon.sh start journalnode
# 1. master1上初始化namenode
bin/hdfs namenode -format
# 2. 在master1上启动namenode
sbin/hadoop-daemon.sh start namenode
# 3. master2上初始化另一个namenode
bin/hdfs namenode -bootstrapStandby
# 4. master2上启动namenode
sbin/hadoop-daemon.sh start namenode
# 5. 启动zk集群
$ZOOKEEPER_HOME/bin/zkServer.sh start
# 6. 在任何一个能连接上zk的机器上格式化zk(创建hadoop-ha znode节点)
bin/hdfs zkfc -formatZK
# 7. 在两个namenode上启动zkfc
sbin/hadoop-daemon.sh --script bin/hdfs start zkfc
打开每一个namenode的UI界面,可以发现至少有一个namenode处于active状态,另外的处于standby状态。需要注意的是,处于standby的节点,没有open权限,也就是说不能查看集群上的具体文件结构。 这个时候已经启动了HA集群,可以做个实验:将master1直接kill -9,然后发现master1的namenode进程退出,而master2的状态由standby变成active。
