

背景
c语言没有映射,redis有映射。java也有映射。很多语言都有映射。
数据结构
包含字段
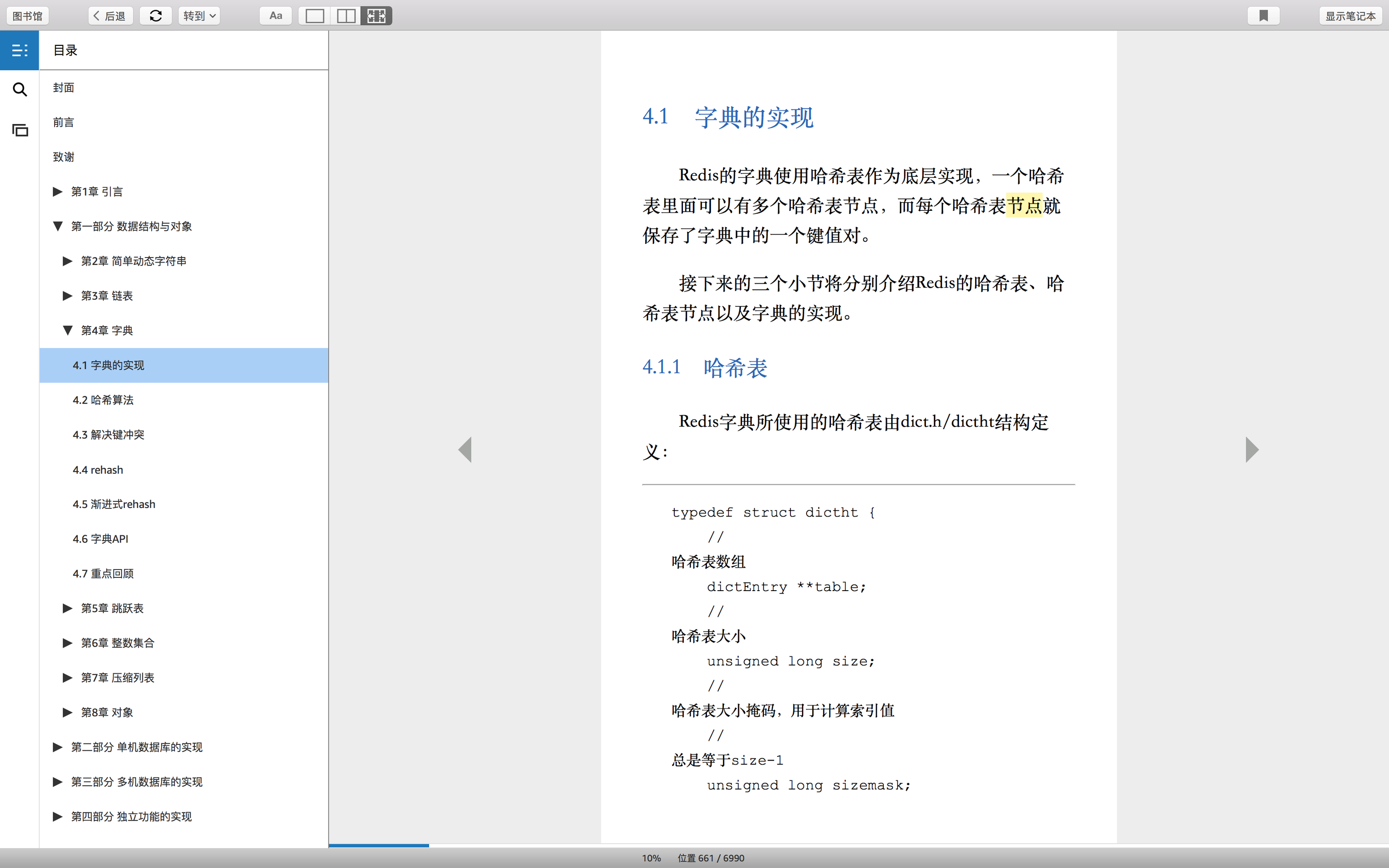
1.数据
2.大小
空的映射。空是指没有key/value。

数据是指针的指针(二维数组),数据结构的数据字段指向entry地址(一维数组),entry的每个元素指向key/value。
节点的数据结构
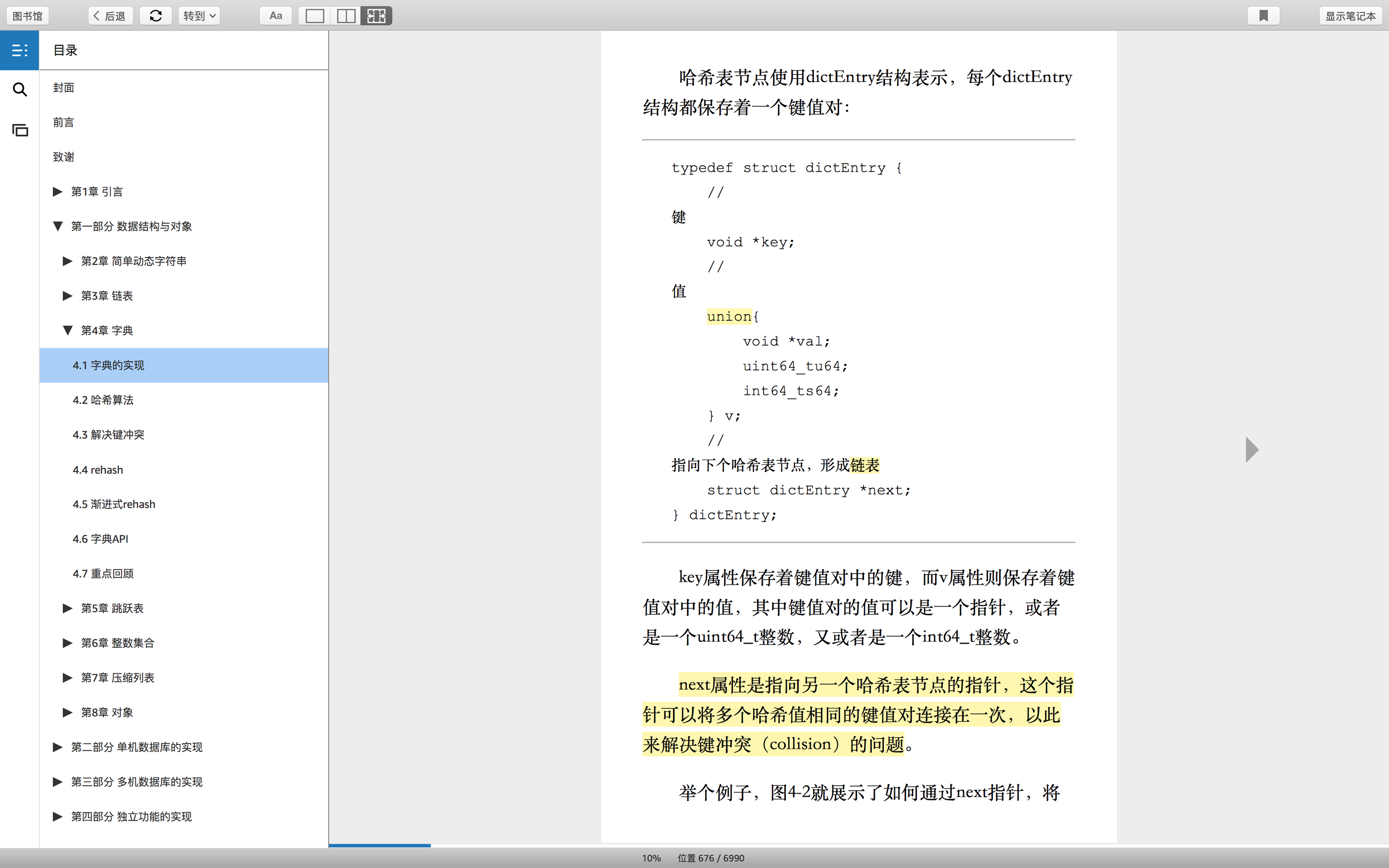
包含字段
1.key
2.value
3.指针
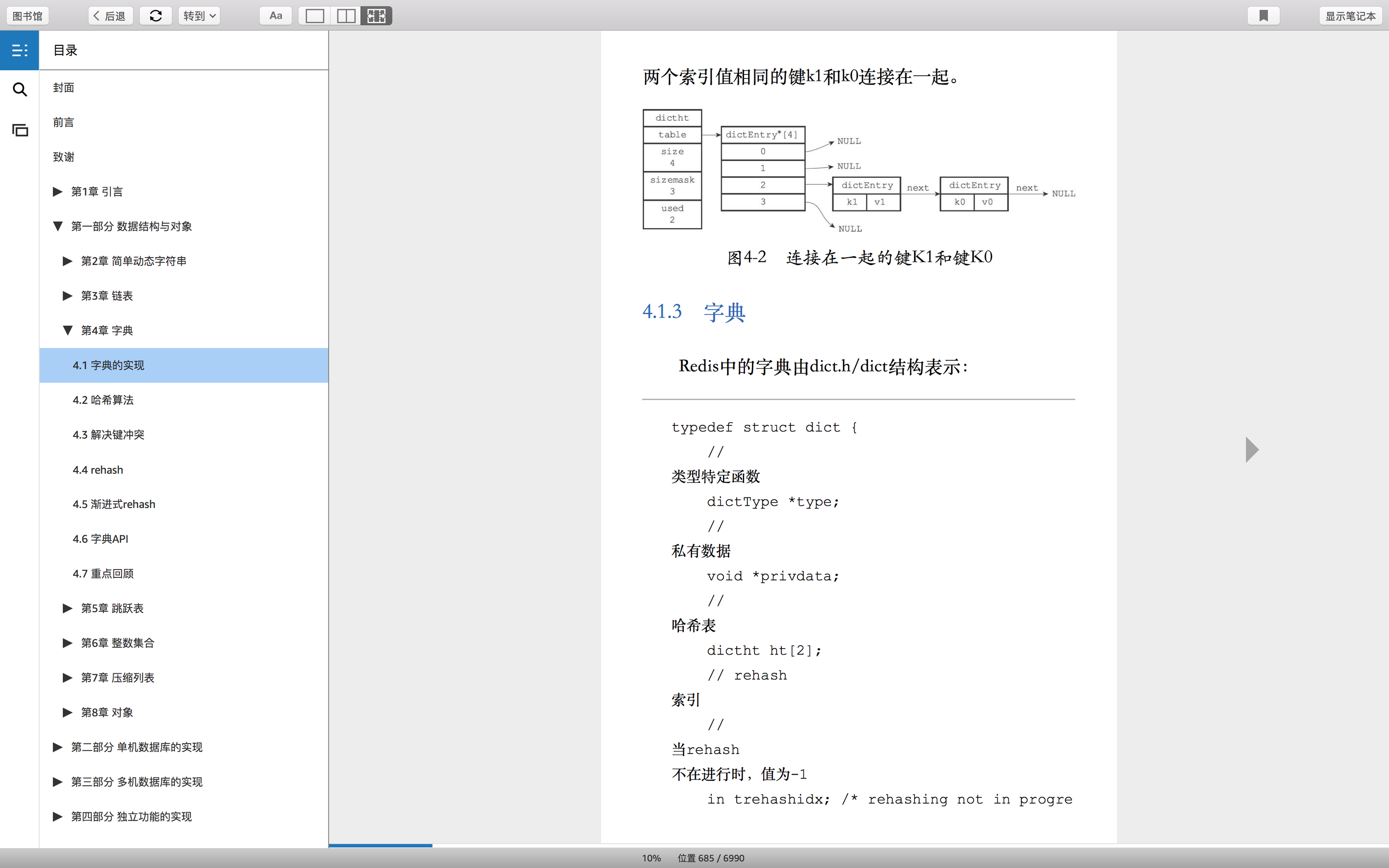
使用链表解决hash冲突,即key相同,value不同的情况
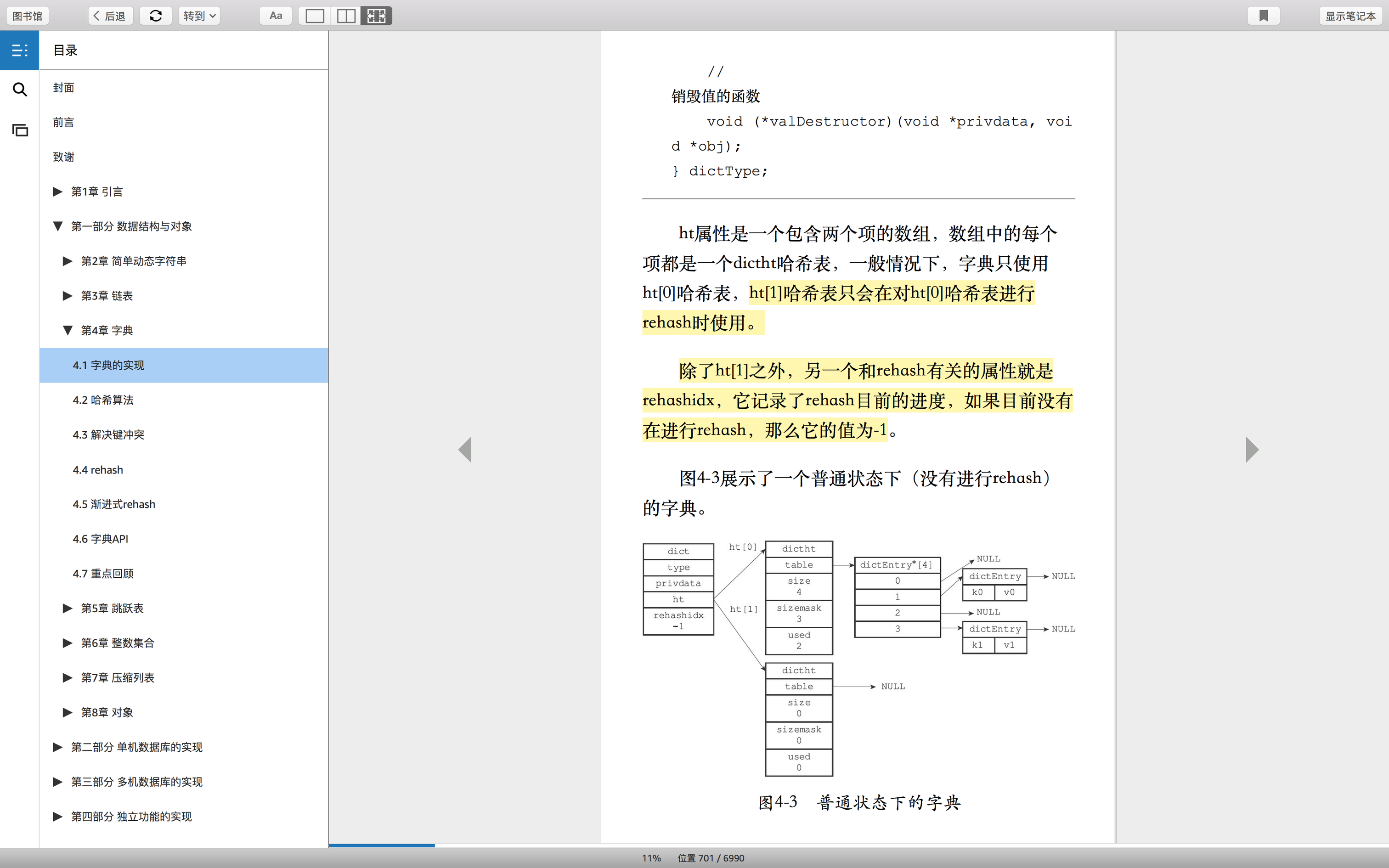
架构图
内部编码数据结构
1.压缩列表
2.hashtable
压缩列表是在1.元素数量百位数的时候(500)2.值的大小几十个字节的时候(50),这两种情况,是压缩列表。
其他是hashtable,就是普通的映射。
压缩列表和hashtable有什么区别
压缩列表就是采用1.起始位置2.偏移量的思想,把数据连续存放在内存,没有指针。指针浪费内存,一个指针,它本身就占4个字节。hashtable数据结构的节点包含了多个指针,这些就是节约下来的内存。
压缩列表如何实现映射?
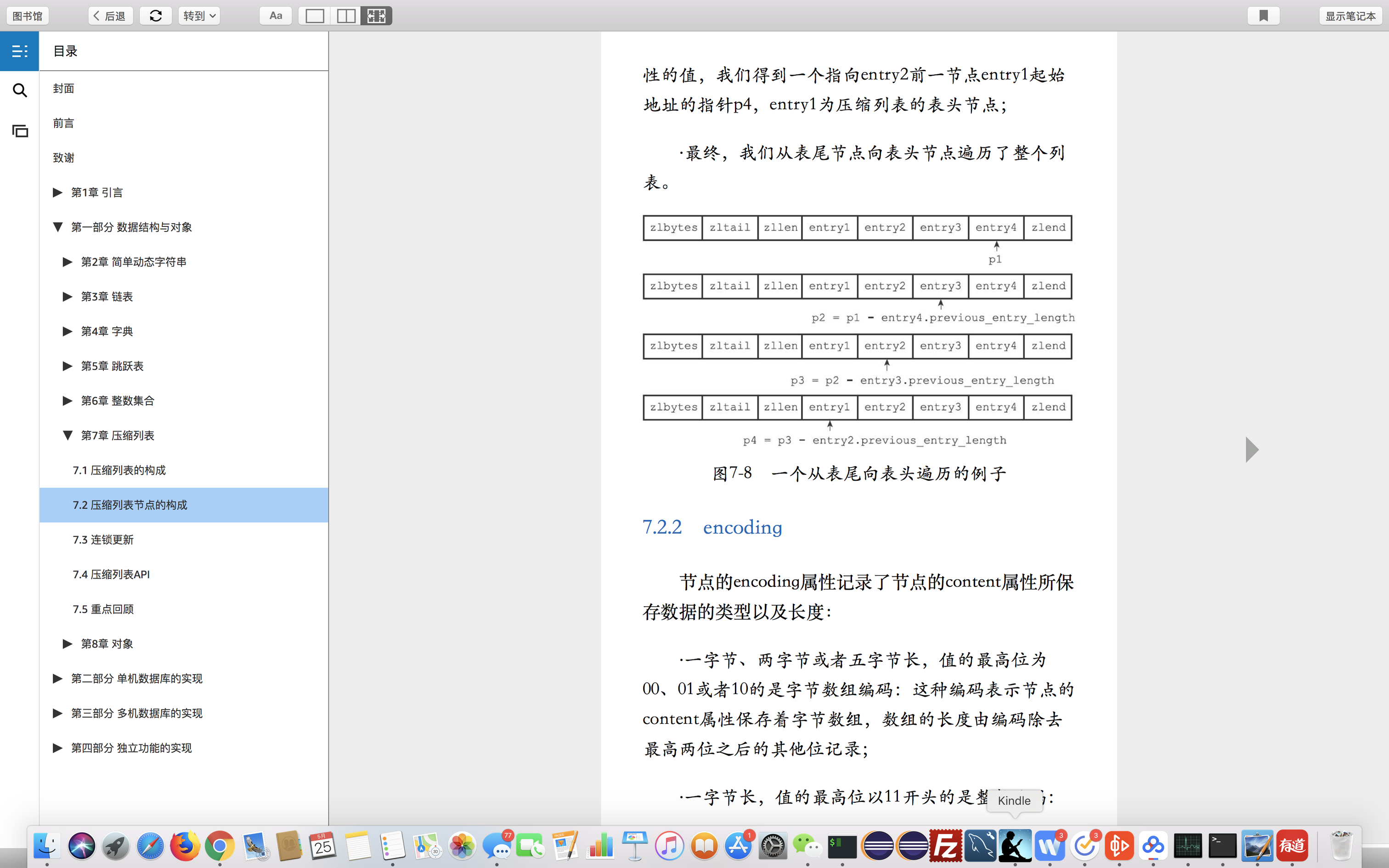
压缩列表ziplist
数据结构
1.数据
2.大小
3.指向尾节点的指针
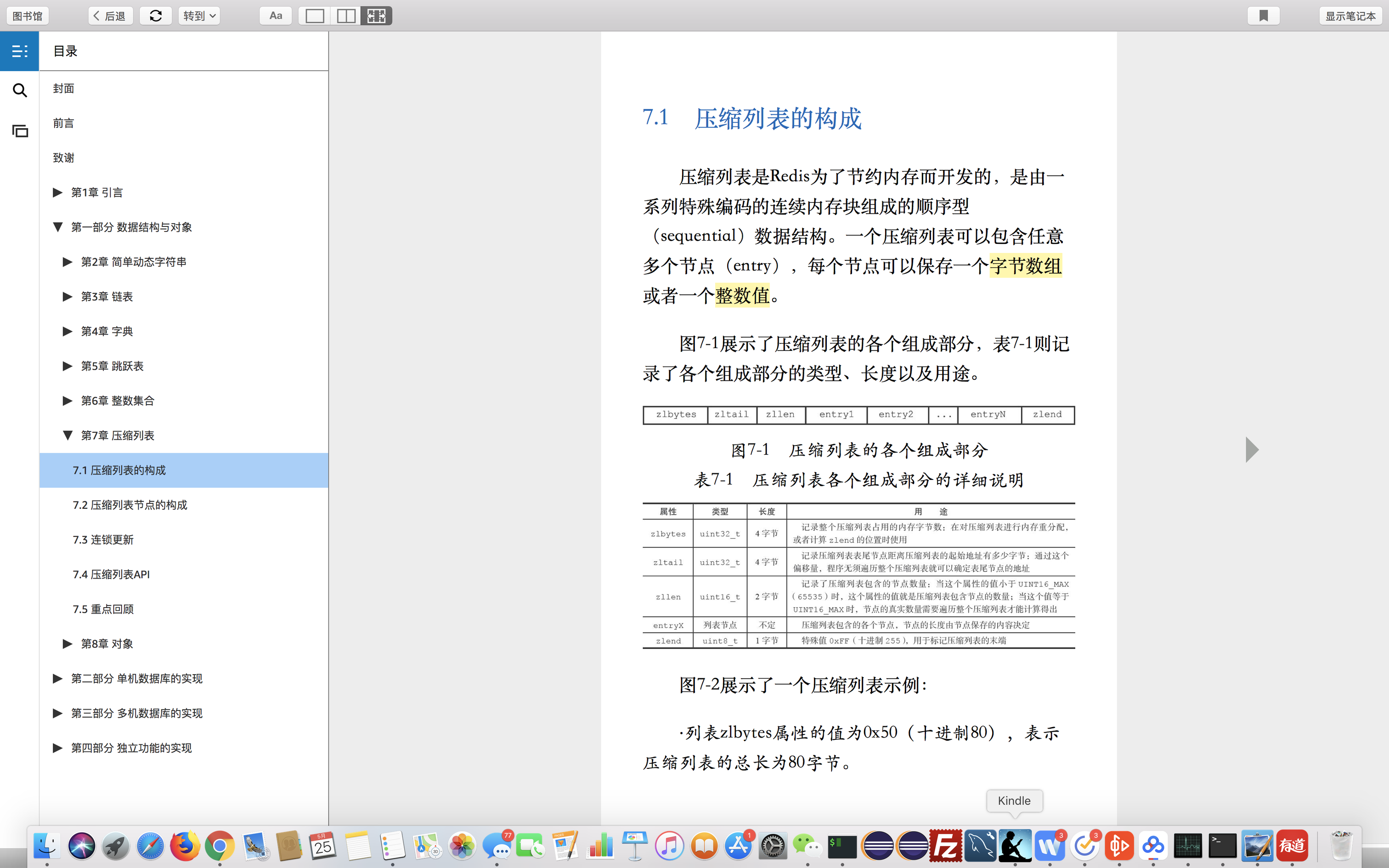
节点的数据结构
1.数据
2.前置元素大小
前一个元素的大小
3.数据的数据类型
不同数据类型占不同的字节数量
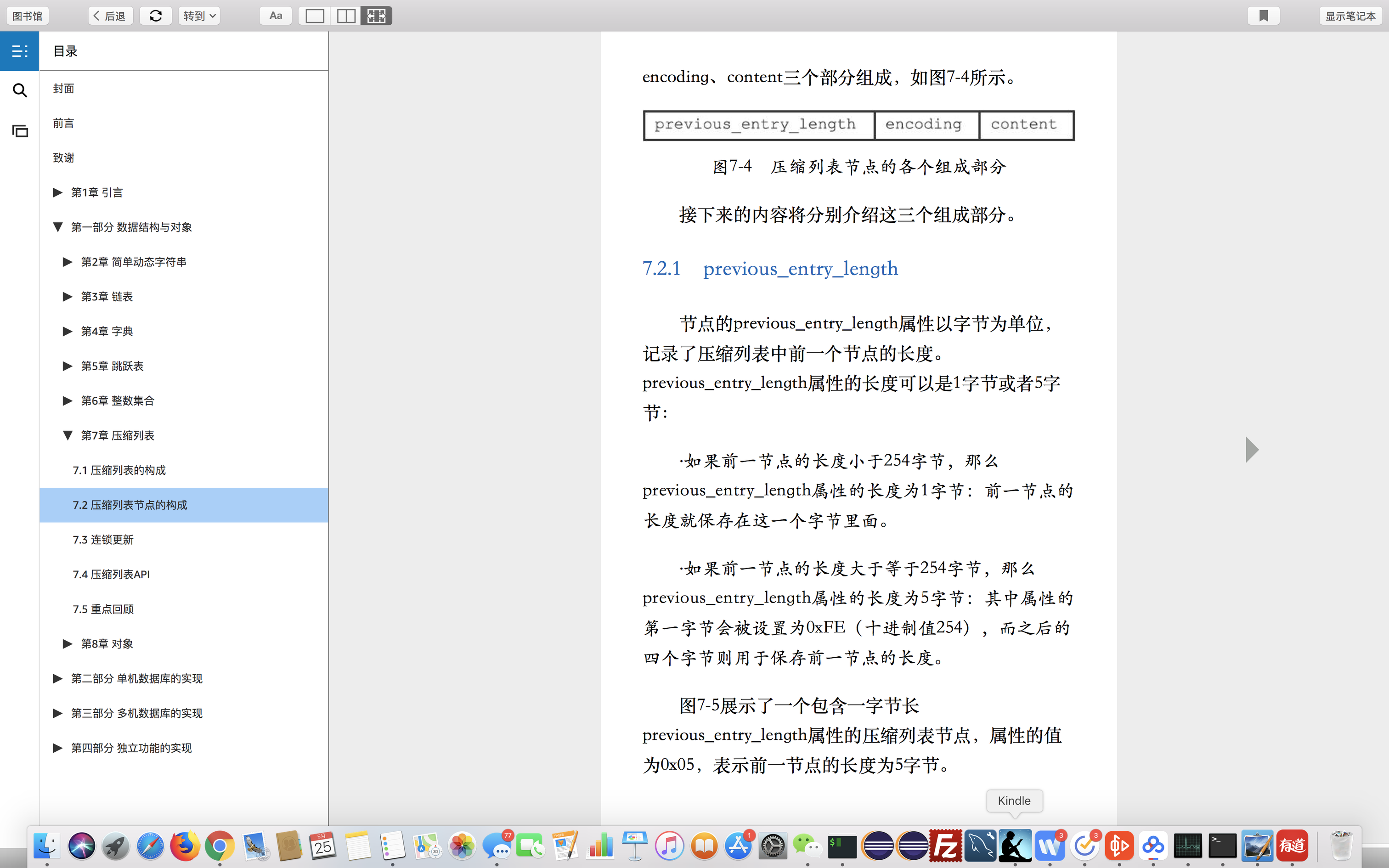
数据实际存放的例子
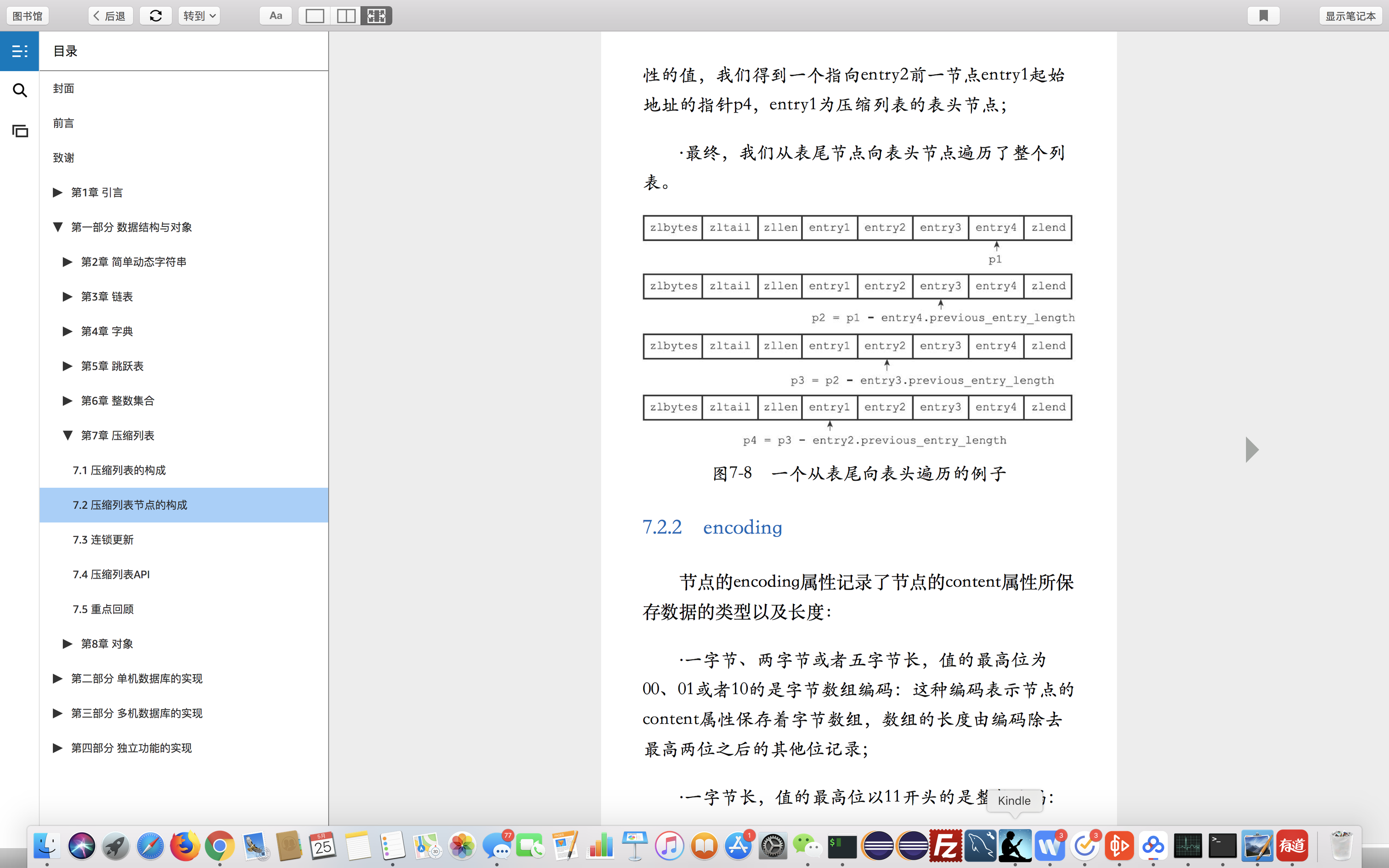
遍历
1.首先定位到尾节点
2.根据前置元素大小,从尾部往头部遍历
3.遍历完成
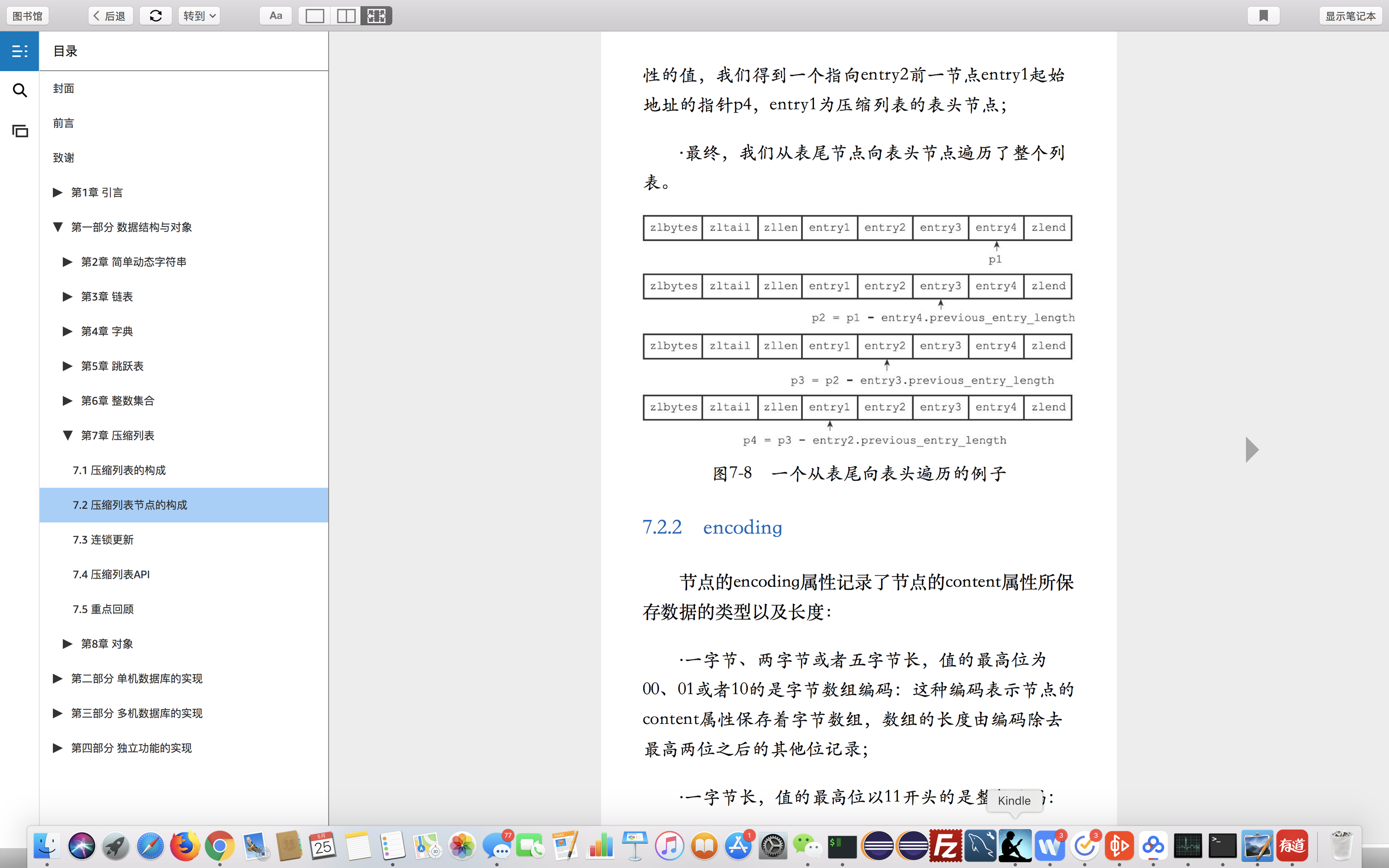
总结
1.首先,压缩列表的数据有一个特别的字段,就是前置元素的大小,作用是定位当前节点的前一个节点。
一般来说,当前节点包含的字段是1.数据2.当前节点的大小。但是压缩列表是1.数据2.前置节点的大小。只是不同的实现方式而已,但凡是基于1.数据2.大小的这种思想实现的数据结构,它的内存都是连续年初,这也是为什么要使用这种数据结构的原因,目的就是为了节约内存,也就是所谓的紧凑的连续的内存。
2.其次,遍历的时候,是从尾部往头部遍历。不过,遍历的方式,从尾部往头部和从头部往尾部差别不大,主要看你想用哪种方式实现罢了。
3.不管是压缩列表ziplist,还是整数集合intset,都只适合少量的数据,或者,数据是整数,这样的情况,因为连续内存遍历数据的速度是N,所以不适合大量的数据。
总结
只要是映射,都是先hash(key)得到索引,然后把数据放到数组的对应索引里。也就是说,底层还是数组。
参考
黄建宏
