本章内容
RDD是什么, 5大特性
- rdd 我自己来讲其实就是一种存储数据的结构而已, python有
DataFrame, spark有RDD, 全称Resilient Distributed Dataset弹性分布式数据集合, 不用管它如何存储, 只要熟悉他其实就像编程语言的可迭代对象(大部分认为是集合就ok)一样就好了 - 5大特性
- 一个分片的数据集
- 将运算搬运到分片上进行运算
- 可以rdd互相依赖(实际上就是rdd可以通过各种函数转换成rdd,但是注意是单向的无环转换, 也就是后面的DAG无环图)
- 可以对于[(key, value)]这种集合RDD进行自定义函数式的分片(注意是分片, 不是排序) 术语(partitioner)
- 对于多备份数据会有最优列表选择最优化的数据所在服务器进行计算(通俗讲就是哪个快,就会自动用哪个机器算这个数据)
RDD操作
- 创建rdd两种方式
- Parallelized Collections(并行化集合)
var data = Array(1, 2, 3, 4, 5)
var rddData = sc.parallelize(data)
这种方式有点蠢, 很少用,因为我们都大数据了, 你怎么给个大数据的集合让我转成rdd呢?
- External Datasets (外部数据集) -- 常用
var rdd = sc.textFile("hdfs://master:8020/input.txt")
这个就是加载
input.txt文件成为rdd 默认通过换行来分
- rdd 基本三种操作
- Transformations 转换 (只要记住这部分不会真的操作数据, 懒加载, 只是构建运算的流程图而已)

红色 为常用方法

- actions 行动 (这部分操作表明操作员需要获取结果了,开始运算)


- persistence 持久化 (这部分是主动操作的, 用来重复使用期间的rdd)

相关文档留意官网
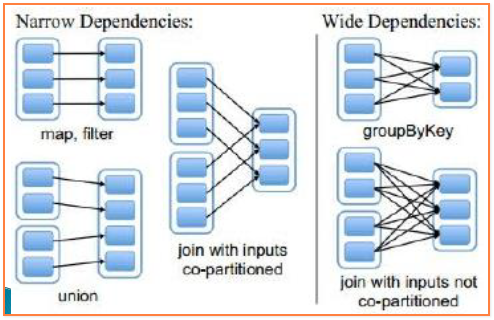
RDD依赖
- 两个分类:
- 宽依赖: 一个父rdd只转换成一个子rdd
如filter 、distinct 、subtract 、sample、union 、coalesce、map 、flatMap
- 窄依赖: 一个父rdd转换成多个子rdd
如reduce, groupByKey, reduceByKey, join等
RDD Shuffle洗牌
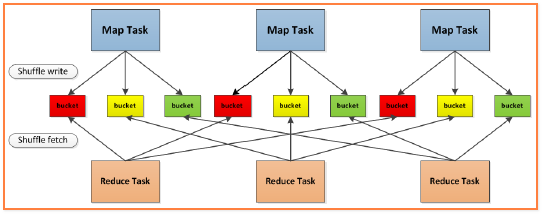
- 打乱重组的意思( 父rdd各自摊牌, 子rdd 各取所需)有点像窄依赖的样子
内核分析(讲得好, 工资高)
- 初始化sc 即 server context, 都喜欢这么叫, sc就是核心的用来操控集群的一个对象啦, 官方文档说的是: sc就是可以和集群的管理者进行操作的一个东西啦, 可以更好地让你理解如何去操作分布式存储数据. (其实无非就是使用哪个加载语句吗? 我见识薄浅, 不要打我狗头)
官方还强调, sc是储存在jvm之中的, 所以你必须记得给我手动关闭, 否则我小拳拳捶你胸口
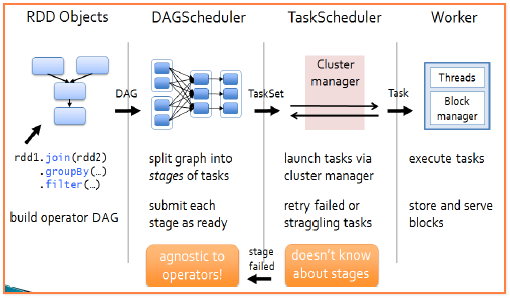
- 剩下的其实就是讲下面这张图啦, 我先给你示范一个满分100差不多得10分的讲解吧
a. 通过逻辑函数式使用, 在rdd之间构造一个单向无环图DAG,
b. DAGScheduler通过shuffle的计算进行分步, 会将先前的流程图分成几步, 再交给TaskScheduler进行执行,
c. TaskScheduler会和集群管理器进行沟通把计算程序分发到各个服务器上,
d. 集群管理器调用服务器上的worker进行执行完成计算结果