

文章编写计划
待完成: 详细介绍用到的各个工具
作者: 祝星
适合阅读人群
文中的调优思路无论是php, java, 还是其他任何语言都是用. 如果你有php使用经验, 那肯定就更好了
业务背景
框架及相应环境
- laravel5.7, mysql5.7, redis5, nginx1.15
- centos 7.5 bbr
- docker, docker-compose
- 阿里云 4C和8G
问题背景
php已经开启opcache, laravel也运行了optimize命令进行优化, composer也进行过dump-autoload命令.
首先需要声明的是, 系统的环境中是一定有小问题的(没有问题也不可能能够提升如此大的性能), 但是这些问题, 如果不通过使用合适的工具, 可能一辈子也发现不出来.
本文关注的就是如何发现这些问题, 以及发现问题的思路.
我们首先找到系统中一个合适的API或函数, 用来放大问题.
这个api设计之初是给nginx负载均衡做健康检查的. 使用ab -n 100000 -c 1000 进行压测, 发现qps只能到140个每秒.
我们知道Laravel的性能是出了名的不好, 但是也不至于到这个程度, 从api的编写来看不应该这么低. 所以决定一探究竟.
public function getActivateStatus()
{
try {
$result = \DB::select('select 1');
$key = 1;
if ($result[0]->$key !== 1) {
throw new \Exception("mysql 检查失败");
}
} catch (\Exception $exception) {
\Log::critical("数据库连接失败: {$exception->getMessage()}", $exception->getTrace());
return \response(null, 500);
}
try {
Cache::getRedis()->connection()->exists("1");
} catch (\Exception $exception) {
\Log::critical("缓存连接失败: {$exception->getMessage()}", $exception->getTrace());
return \response(null, 500);
}
return \response(null, 204);
}
问题表现以及排查思路
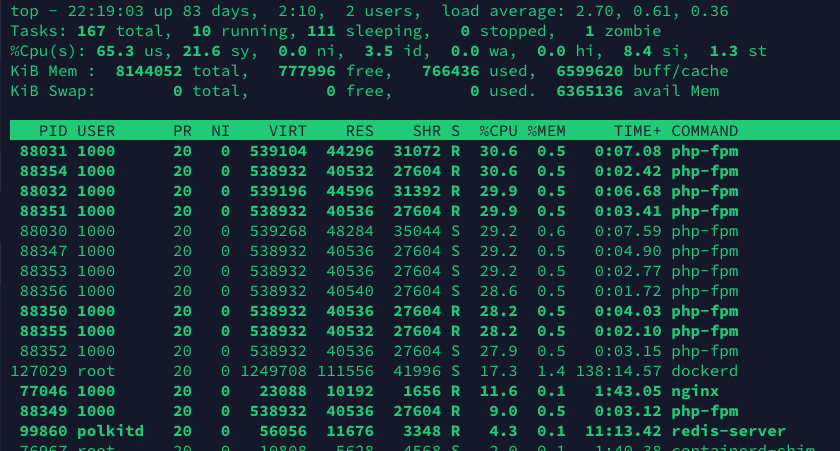
top
top命令发现系统CPU占用100% 其中用户态占80%, 内核态占20%, 看起来没什么大问题. 有一个地方看起来很奇怪, top命令的运行结果
%CPU -- CPU usage
The task's share of the elapsed CPU time since the last screen update, expressed as a percentage of total CPU time.
大致意思是这个占用是最后一次屏幕刷新的时候, 进程CPU的占用. 由于top命令收集信息的时候, 可能linux把这个进程强制调度了 ( 比如用于top收集进程信息 ), 所以在这一瞬间(屏幕刷新的这一瞬间)某些php-fpm进程处于sleep状态, 可以理解, 所以应该不是php-fpm的问题.
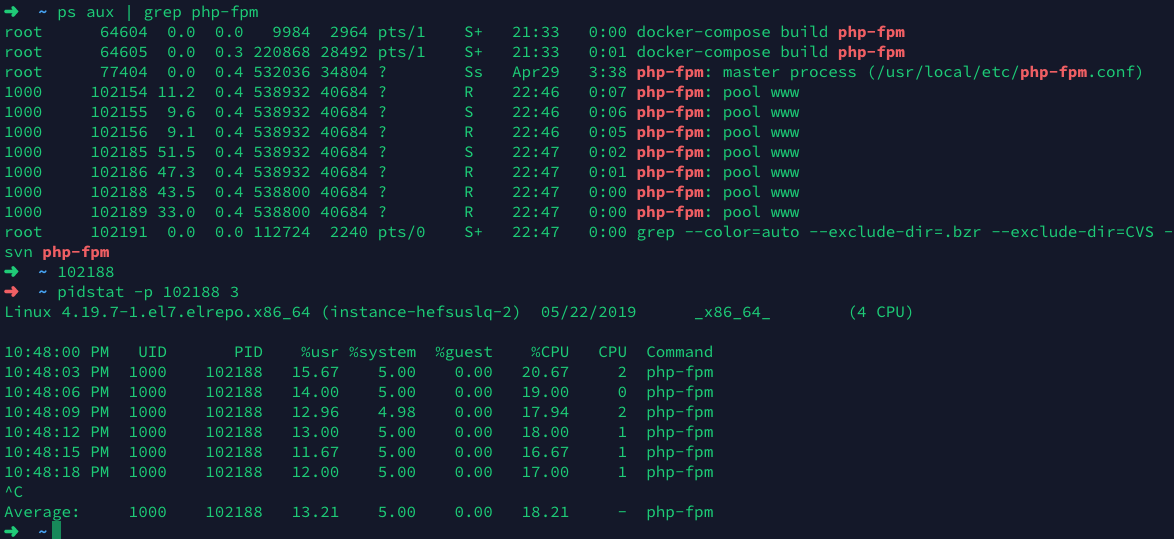
pidstat
首先选出一个php-fpm进程, 然后使用pidstat查看进程详细的运行情况
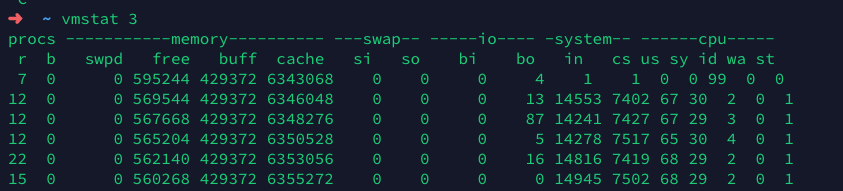
vmstat
保持压测压力, 运行vmstate查看, 除了context switch (上下文切换)有点高之外, 并没有看到太多异常. 由于我们使用的docker, redis, mysql都运行在同一台机器上, 7000左右的CS还是一个合理的范围, 但是这个IN(中断)就有点太高了, 达到了1.4万左右. 一定有什么东西触发了中断.
不管是vmstat还是pidstat都只是新能探测工具, 我们无法看到具体的中断是由谁发出的. 我们通过/proc/interrupts 这个只读文件中读取系统的中断信息, 获取到底是什么导致的中断升高. 通过watch -d命令, 判断变化最频繁的中断.
watch -d cat /proc/interrupts
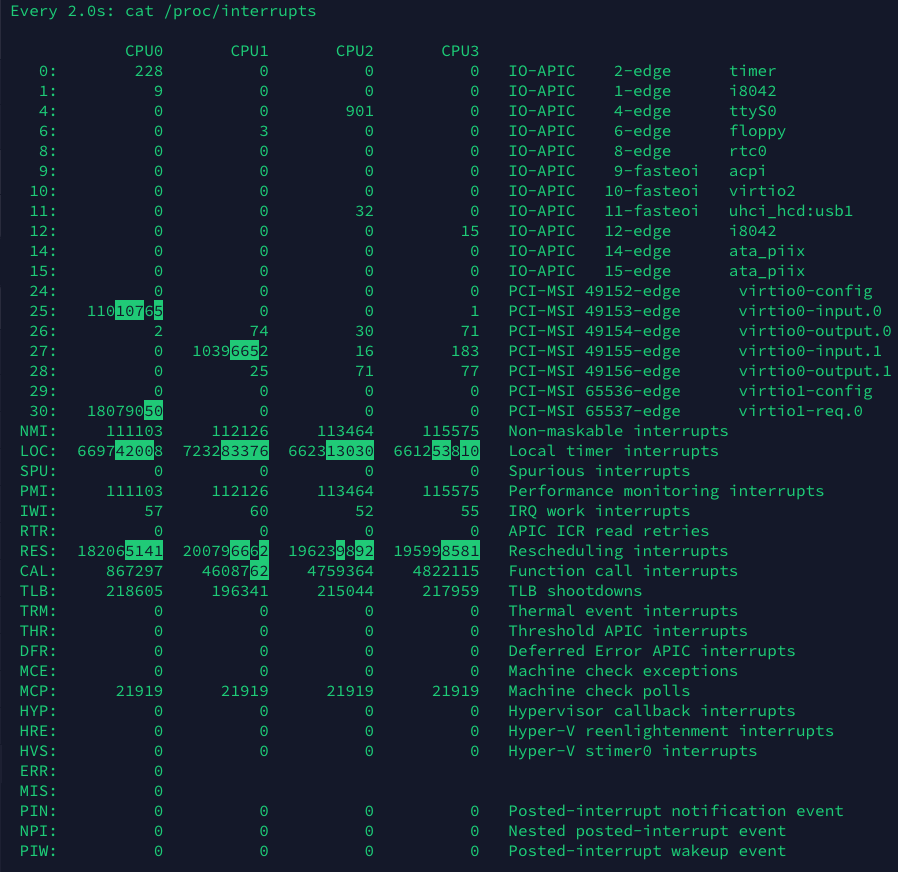
我们发现其中Rescheduling interrupts变化的最快, 这个是重调度中断(RES),这个中断类型表示,唤醒空闲状态的CPU 来调度新的任务运行。这是多处理器系统(SMP)中,调度器用来分散任务到不同 CPU的机制,通常也被称为处理器间中断(Inter-Processor Interrupts,IPI)。 结合vmstat中的命令, 我们可以确定造成qps不高的原因之一是过多的进程争抢CPU导致的, 我们现在还不能确定具体是什么, 所以还需要进一步的排查.
strace
strace可以查看系统调用, 我们知道, 当使用系统调用的时候, 系统陷入内核态, 这个过程是会产生软中断的, 通过查看php-fpm的系统调用, 验证我们的猜想

opcache.validate_timestamps="60"
opcache.revalidate_freq="0"
再次执行ab命令进行压测
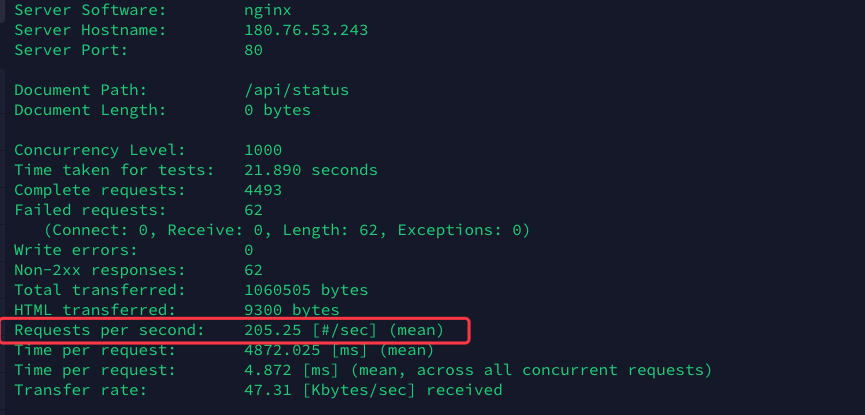
perf
现在任然不满足这个性能, 希望在更多地方找到突破口. 通过
perf record -g
perf report -g
看到系统的分析报告
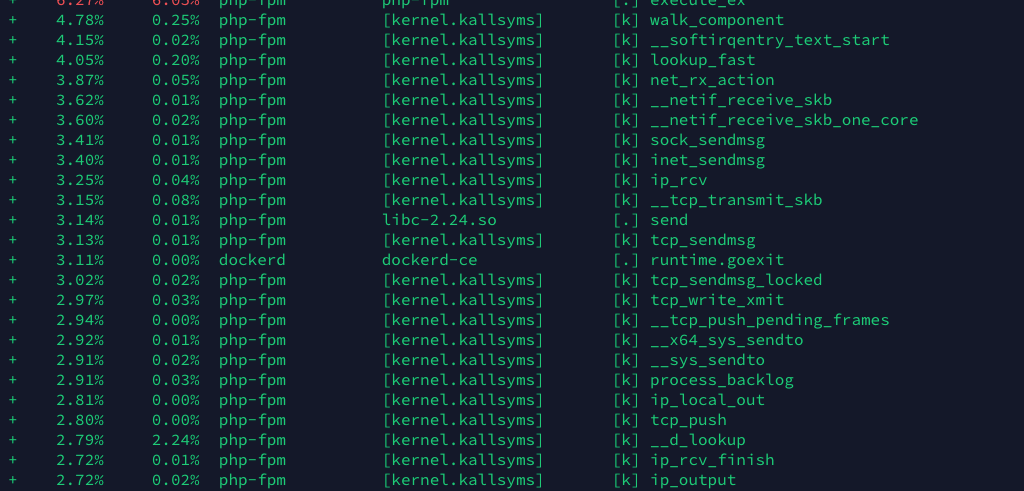
- 与mysql, redis重复大量的建立TCP连接, 消耗资源
- 大量请求带来的tcp连接
先说第一个, 经过检查, 发现数据库连接使用了php-fpm的连接池, 但是redis连接没有, redis用的predis, 这个是一个纯PHP实现, 性能不高, 换成了phpredis:
打开laravel的config/database.php文件, 修改redis的driver为phpredis, 确保本机已安装php的redis扩展. 另外由于Laravel自己封装了一个Redis门面, 而恰好redis扩展带来的对象名也叫Redis. 所以需要修改Laravel的Redis门面为其他名字, 如RedisL5.
再次进行压测
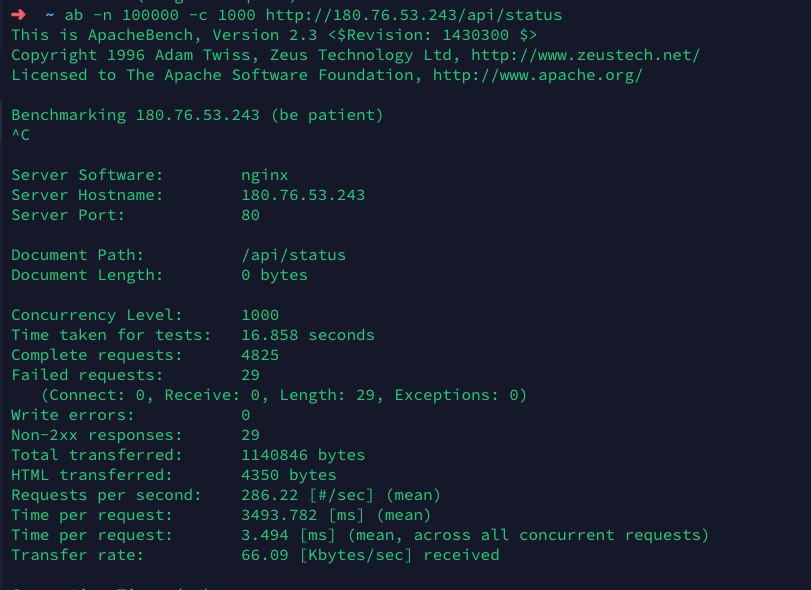
总结
我们通过top, 发现系统CPU占用高, 且发现确实是php-fpm进程占用了CPU资源, 判断系统瓶颈来自于PHP.
接着我们通过pidstat, vmstat发现压测过程中, 出现了大量的系统中断, 并通过 watch -d cat /proc/interrupts 发现主要的中断来自于重调度中断(RES)
通过strace查看具体的系统调用, 发现大量的系统调用来自于stat, 猜测可能是opcache频繁的检查时间戳, 判断文件修改. 通过修改配置项, 达到了46%的性能提升
最后再通过perf, 查看函数调用栈, 分析得到, 可能是大量的与redis的TCP连接带来不必要的资源消耗. 通过安装redis扩展, 以及使用phpredis来驱动Laravel的redis缓存, 提升性能, 达到了又一次近50%的性能提升.
最终我们完成了我们的性能提升104%的目标
