

出品 | 滴滴技术
作者 | 谢梁

前言:韦伯-费纳希定律(Weber-Fechner Law)是心理学里面非常重要的定律,用来描述心理量与物理量之间的关系,在行为经济学里面则引出了价值函数曲线的概念,可以从效用层面用来刻画用户对不用体验的反应程度。
—————
这篇文章由三个部分组成:
第一部分简要介绍韦伯--费希纳定律的内容及其应用;
第二部分介绍由此引伸出来的价值函数曲线概念;
第三部分则介绍这些概念在实践中的应用及数据科学在其中发挥的作用。
▍一、韦伯-费希纳定律
韦伯--费希纳定律是由费希纳总结而成的描述心里感知与物理量变化之间关系的定律,分别由韦伯定律和费希纳定律两条定律组成。
韦伯定律是指物理量的变化必须达到一定比例,才能引起心理感觉的差异,而这一比例是个常数,用公式表示:Δr(物理量差异)/r(物理量)=k(常数),由德国生理学家E.H. 韦伯发现,并有他的学生G.T 费希纳在数学上予以精确定义。这里的Δr(物理量差异)也称为“最小感觉差”(JND,Just Noticeable Difference),而常数k则被称为韦伯比例。韦伯定律的提出,为我们提供了一个比较辨别能力的重要指标。
比如,如果要比较不同个体某一个感知能力的分辨率(即辨别能力)而所用的标准刺激又不相同时,就不能用差别阈限的绝对值进行比较,而要用韦伯比例来比较。比如听力的辨别能力等。
费希纳进一步发展了韦伯的理论。他想要刻画在连续变化意义上的最小感觉差,即用最小可觉差(连续的差别阈限)作为可感觉的最小物理量变动计量单位,即每增加一个差别阈限,心理量增加一个单位,从而刻画心理量与物理量之间的关系。
费希纳定律认为感知(视觉,听觉,触觉等等)所获得的心理量与对应物理量强度的常用对数成正比,而不是直接与物理量的绝对强度成正比。这一发现也创立了心理物理学科学。此处我们略去费希纳定律的数学描述。费希纳定律最常见的一个应用是在对声响的刻画上。声音响度的度量单位是“贝尔”(Bl),而我们常用的使用度量数为“分贝”(dB),即“贝尔”的1/10。高声说话的响度为6.5dB, 而树叶的沙沙声的响度为1dB,两者感受相差6.5倍,但是两者的强度相差10的(6.5-1)次方倍,大概是316000倍!
▍二、前景理论
韦伯—费希纳定律帮助卡尼曼(Kahneman)和特韦斯基(Tversky)在1979年提出了行为经济学里著名的前景理论(Prospect Theory),特韦斯基等人并由此获得了2002年诺贝尔经济学奖。
前景理论是说当人们在决策的时候,一般采取两个步骤:
1. 首先会形成一个参考点(这被称为编辑阶段),
2. 然后根据当前结果相对于参考点的差异来进行决策(这被称为评估阶段)。
参考点的形成根据前景理论遵循“小数定理”和“易得信息偏差”,即人们会根据少量、容易获取的(高频)信息来形成自己参考点;而在评估阶段人们是根据物理量相对于参考点的变动而不是物理量的绝对值来进行决策,即费希纳定律描述的心理量和物理量的关系。当相对于参照系,物理量负向变动时候,心理量的变动是大于当物理量正向变动引起的心理感知的,这个发现即是基于前景理论的“损失规避”行为模式,也就是收益和损失对于个人感知是不对称的,通常100块钱的损失要200块钱的收益来弥补这个道理。
▍三、数据科学应用
我们现在了解了一些常见的行为模式,那么对于我们的应用有什么借鉴意义呢?数据科学在其中能起到什么作用呢?这个我通过两个例子来讲解。
▍应用一:费希纳定律的应用
去年,某部门想要研究什么样的策略才能在降低切单率的情况下同时提高ROI。为了研究这个问题,我们针对某城市在2018年4月的切单情况与订单距离之间的关系进行了分析,得到如下的关系图:
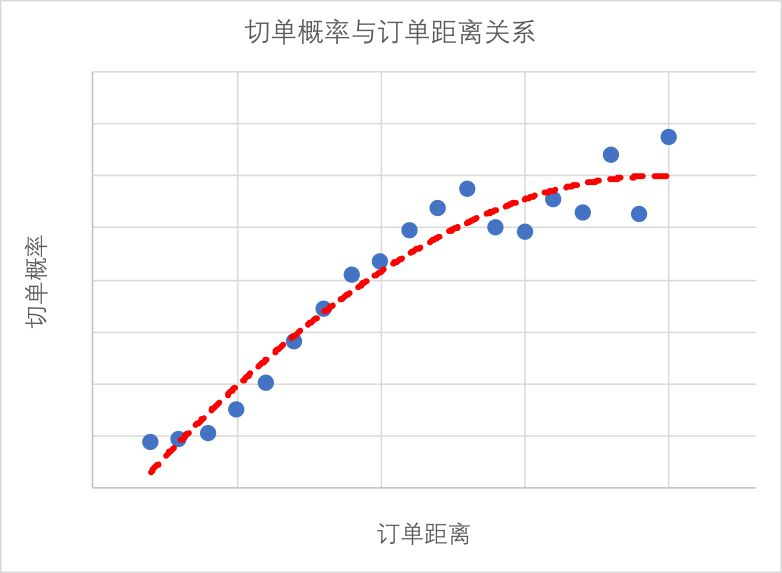
虽然是一个很简单的单变量关系图,但是该图完美契合费希纳定律:
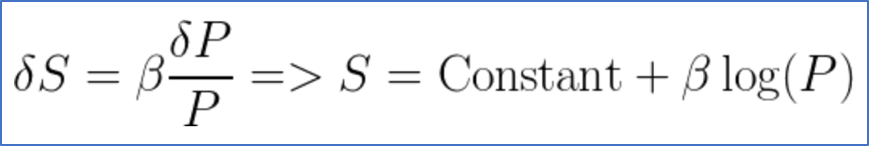
根据费希纳定律,在初始的物理量给定的情况下,感知量的绝对变动与物理量的相对变动是一个固定比率关系。通过积分运算后,得到如上面公式描述的感知量与物理量的对数之间呈线性关系,与我们的实证数据表现出的关系非常契合。
通过将订单距离映射为一个我们业务上有具体抓手的另外一个指标X的对数,将切单率映射为一个隐变量代表司机对分成的感受,超过一定阈值就会切单,这样就可以建立起一个logistic回归模型,而系数beta则反映了X指标的弹性这个经济学概念。回归分析拟合得到这个弹性系数之后即可用于敏感性分析,获得不同距离下滴滴应该采用什么样的策略才能既降低切单率又保持较好的ROI。
▍应用二:前景理论中参考系的获取
我们在前面介绍了由韦伯-费希纳定律发展而来的前景理论,而前景理论中一个人的决策依赖于通过信息获取得到的参考点。由于参考点的不同,用户对我们的策略或者运作手段的反映会不一样。这在进行负向监控的时候非常重要,可以引导数据分析师专注于需要重点监控和优化的地方。
比如交易引擎曾经上线一个实验策略,该策略相对于原有策略可以明显改善乘客体验。但是随后在一些城市这个策略并不受高服务分司机的欢迎,原因是由于实验策略在实施中出现了与服务分解耦的现象,因此高服务分司机的感知变差了,具体表现为分到单的量少了。
但是这个问题不能简单的只从不同服务分司机的分单分布差异上来分析,因为这样只是以一个很炫酷的方式表现一个已知的事实。作为数据科学家,我们需要以事实为准绳,以理论为依据,不仅仅是表现数据,而是要为策略部门提供具体优化建议。
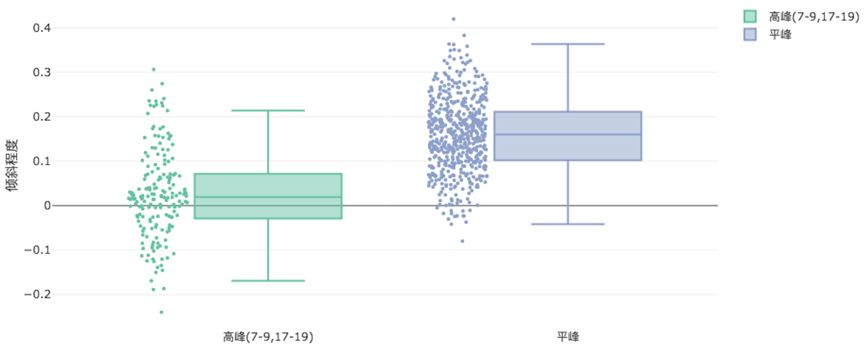
通过使用分布偏度(skewness)来度量分单策略的倾斜度,我们发现服务分的事实解耦主要来自于平峰期订单,分布偏度量化了该倾斜的力度,如下图所示。该倾斜力度也形成了司机的参考系,即司机已经觉得平峰期高服务多拿单(可以是某一个待估计的参数,但是对于该分析不需要)是理所应得的。
另一方面,新分单策略的倾斜力度情况如下图所示:
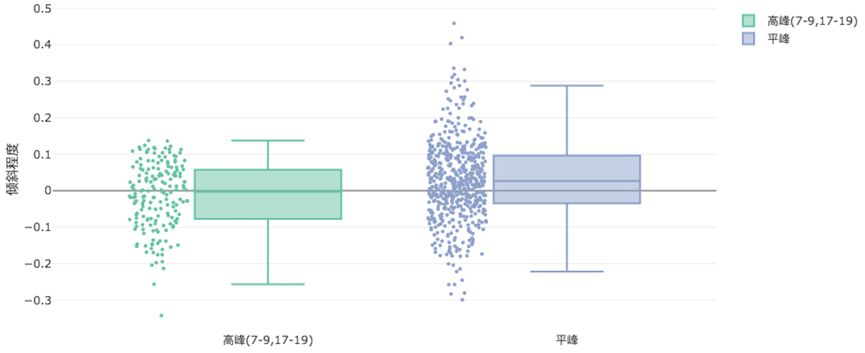
我们发现高峰期服务分倾斜几乎没有变化,而平峰期的倾斜力度则相对下降了60%,因此司机在平峰期会感受非常明显,从而直接反映到司机感知的监测指标上。后期进行了持续迭代,从调研的结果来看,改进的效果得到了司机和乘客的认可。
通过这个分析,我们发现需要在设计新策略的时候对现有用户的心智参考系进行充分的分析和量化,从而能够在博弈的框架下全面考量新策略的影响,保证司机和乘客的体验变动尽量平滑。
▍四、总结
通过该文,我们简要引入了一些“数据理论”之外的概念和理论。我们发现这些概念和理论本身是数据分析的普世结果,同时与我们自己的数据和业务相结合,能有效指导数据分析,引导分析结果的落地。
这里我们也欢迎大家与我们一起探讨如何更好地将多学科理论结合应用数据科学并应用到实际业务中。


负责供需策略、实验设计以及AI应用的数据分析。在加入滴滴之前,曾任微软云计算核心存储工程的首席数据科学家,负责大规模机器学习在云存储的应用。并拥有纽约州立大学宾汉顿分校经济学博士学位。
同时,滴滴数据科学部正在热招数据科学家、数据分析师、数据开发架构师等职位,欢迎对数据科学有着浓厚兴趣和建树的同学投递。
简历投递邮箱:yangliulynn@didiglobal.com
具体职位信息可参考:http://talent.didiglobal.com/
