

kafka是大家比较常用的消息中间件,本文主要介绍kafka基本组件及其相关原理
基本架构
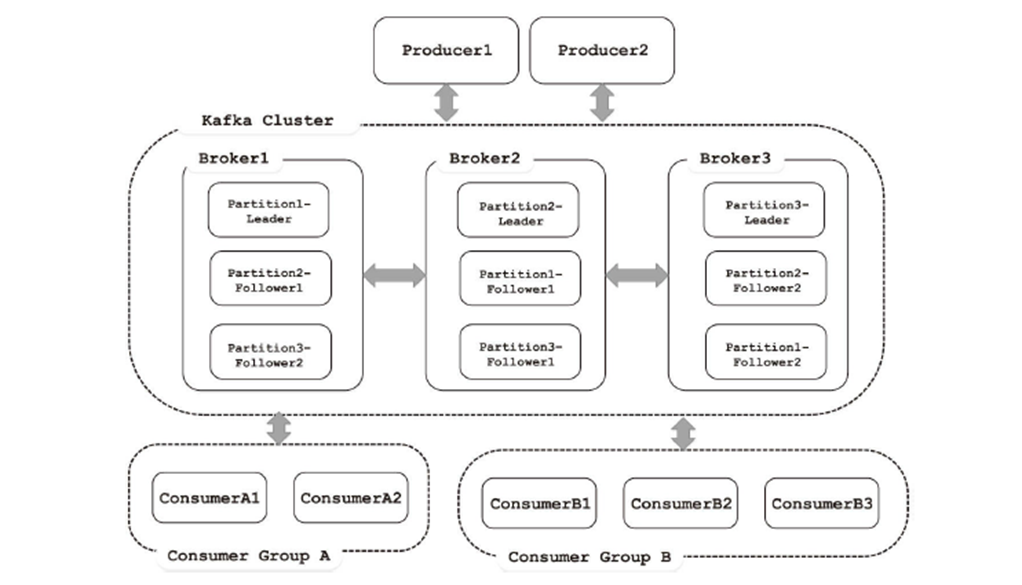
- Broker:消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群
- Topic:Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic
- Producer:消息生产者,向Broker发送消息的客户端
- Consumer:消息消费者,从Broker读取消息的客户端
- ConsumerGroup:每个Consumer属于一个特定的Consumer Group,一条消息可以发送到多个不同的Consumer Group,但是一个Consumer Group中只能有一个Consumer能够消费该消息
- Partition:物理上的概念,一个topic可以分为多个partition,每个partition内部是有序的
偏移量
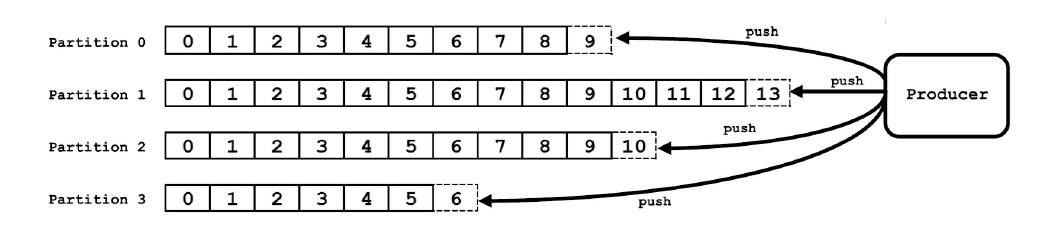
Kafka通过offset保证消息在分区内的顺序,offset的顺序性不跨分区。Kafka0.10以后,使用一个专门的topic __consumer_offset保存offset。__consumer_offset日志留存方式为compact,也就是说,该topic会对key相同的消息进行整理
__consumer_offset内保存三类消息:
- Consumer group组元数据消息
- Consumer group位移消息
- Tombstone消息
kafka log
存储
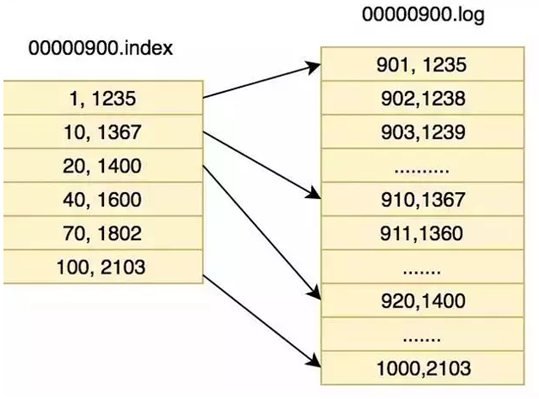
每个Partition其实都会对应一个日志目录:{topicName}-{partitionid}/,在目录下面会对应多个日志分段(LogSegment)。LogSegment文件由两部分组成,分别为“.index”文件和“.log”文件
发送
使用page cache顺序读文件,操作系统可以预读数据到 page cache。同时,使用mmap直接将日志文件映射到虚拟地址空间
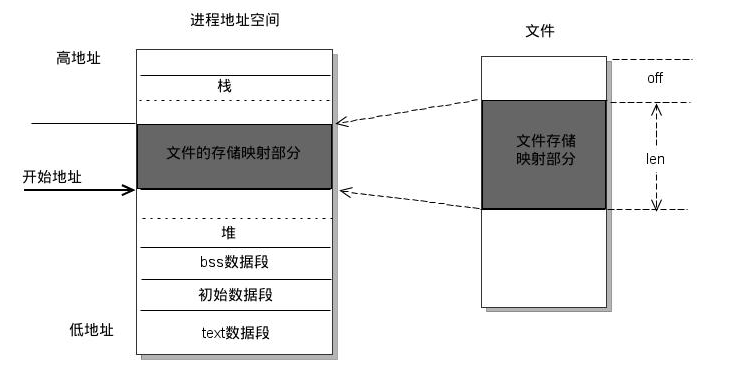
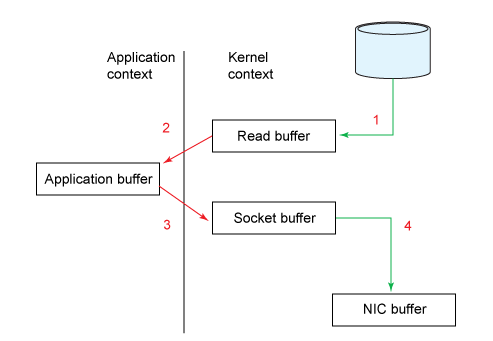
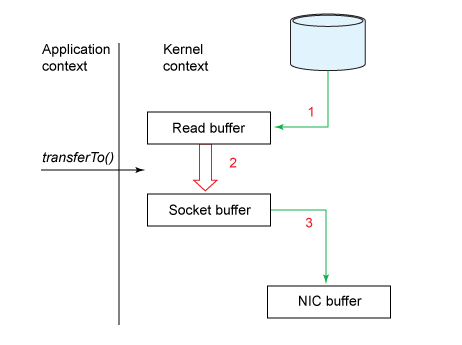
零拷贝:消息数据直接从 page cache 发送到网络 通常的文件读取需要经历下图的流程,有两次用户态与内核态之间内存的拷贝
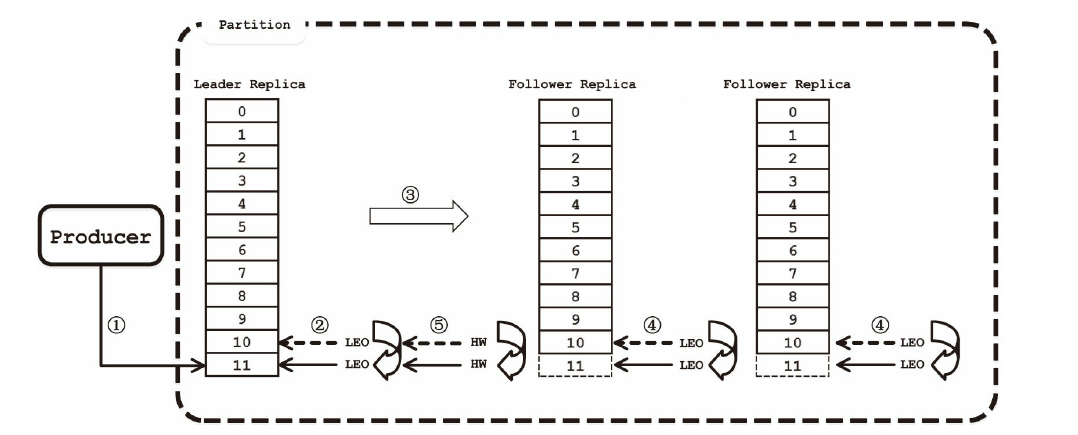
副本
-
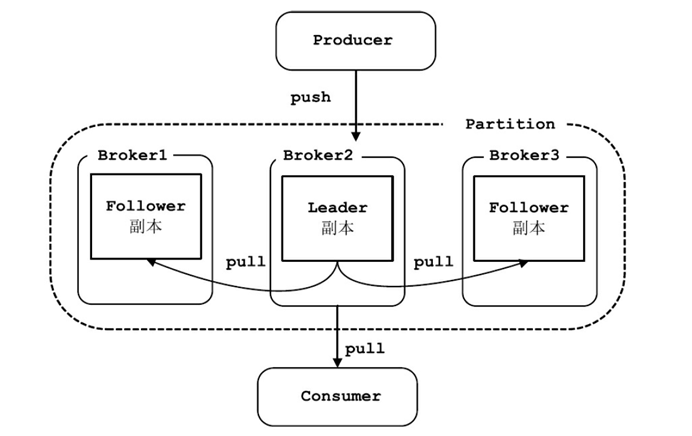
每一个分区都存在一个ISR(in-sync replicas)
-
ISR集合中的每一个副本都与leader保持同步状态,不在里面的保持不了同步状态
-
只有ISR中的副本才有资格被选为leader
-
Producer写入的消息只有被ISR中的副本都接收到,才被视为"已提交"
-
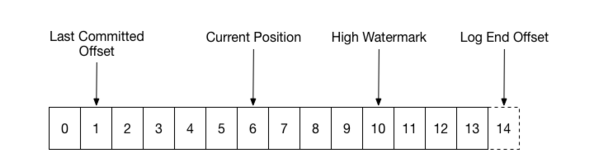
Log End Offset:Producer 写入到 Kafka 中的最新一条数据的 offset
-
High Watermark:已经成功备份到其他 replicas 中的最新一条数据的 offset,也就是说 Log End Offset 与 High Watermark 之间的数据已经写入到该 partition 的 leader 中,但是还未成功备份到其他的 replicas 中
副本同步流程:
Controller
Controller类似于集群的master,主要管理如下几块:
- Broker 的上线、下线处理
- topic 的分区扩容,处理分区副本的分配、leader 选举
Controller通过broker抢占zk临时节点选举出来,且controller与所有broker建立长连接
Controller管理partition leader选举,主要有以下几种方式:
| 选举方式 | 说明 |
|---|---|
| OfflinePartitionLeaderSelector | leader 掉线时触发 |
| ReassignedPartitionLeaderSelector | 分区的副本重新分配数据同步完成后触发的 |
| PreferredReplicaPartitionLeaderSelector | 最优 leader 选举,手动触发或自动 leader 均衡调度时触发 |
| ControlledShutdownLeaderSelector | broker 发送 ShutDown 请求主动关闭服务时触发 |
消息幂等
问题:
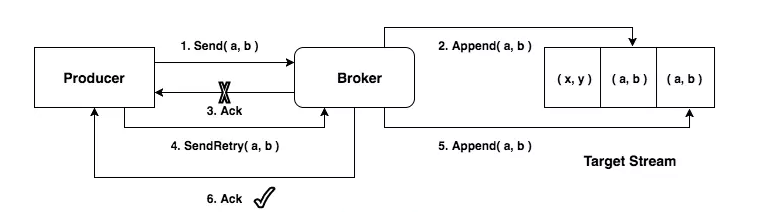
- 在 0.11.0 之前,producer保证at least once
- at least once可能带来重复数据 网络请求延迟等导致的重试操作,在发送请求重试时 Server 端并不知道这条请求是否已经处理(没有记录之前的状态信息),所以就会有可能导致数据请求的重复发送,这是 Kafka 自身的机制(异常时请求重试机制)导致的数据重复
解决方案:
- PID(Producer ID),用来标识每个 producer client
- sequence numbers,client 发送的每条消息都会带相应的 sequence number,Server 端就是根据这个值来判断数据是否重复
Rebalance
kafka rebalance发生的5种情况:
- 有新的消费者加入Consumer Group。
- 有消费者宕机下线。消费者并不一定需要真正下线,例如遇到长时间的GC、网络延迟导致消费者长时间未向GroupCoordinator发送HeartbeatRequest时,GroupCoordinator会认为消费者下线。
- 有消费者主动退出Consumer Group。
- Consumer Group订阅的任一Topic出现分区数量的变化。
- 消费者调用unsubscrible()取消对某Topic的订阅。
kafka通过GroupCoordinator管理rebalance操作
- GroupCoordinator是KafkaServer中用于管理Consumer Group的组件
- GroupCoordinator在ZooKeeper上添加Watcher
- 获取GroupCoordinator:消费者会向Kafka集群中的任一Broker发送ConsumerMetadataRequest
- 消费者连接到GroupCoordinator并周期性地发送HeartbeatRequest
- 如果HeartbeatResponse中带有IllegalGeneration异常,说明GroupCoordinator发起了Rebalance操作,此时进入rebalance环节 Rebalance分为两个流程。
Join Group:
- Consumer首先向GroupCoordinator发送JoinGroupRequest请求,其中包含消费者的相关信息
- GroupCoordinator从中选取一个消费者成为Group Leader,封装成JoinGroupResponse返回给每个消费者
- 只有Group Leader收到的JoinGroupResponse中封装了所有消费者的信息, Group Leader根据消费者的信息以及选定的分区分配策略进行分区分配。
Sync Group:
- 每个消费者会发送SyncGroupRequest到GroupCoordinator,但是只有Group Leader的SyncGroupRequest请求包含了分区的分配结果
- GroupCoordinator根据Group Leader的分区分配结果,形成SyncGroupResponse返回给所有Consumer
- 消费者收到SyncGroupResponse后进行解析,即可获取分配给自身的partition
