

本文是《Mastering Python High Performance》的读书笔记。
作者(出版社)开源的代码地址:
《Mastering Python High Performance》一书大致分为两部分,第一部分讲了profile的方法论,介绍了cProfile和line_profile的使用。第二部分介绍了一些提高性能的方法。这篇文章只讲第二部分的第四章提到的一些方法。
我对本文中出现的一些例子做了一定修改。
0x01 Memoization
对于一些耗时、输入参数大致固定的函数,如果你能够保证一定的输出一定可以得到相同的结果,可以把结果保存起来,之后调用的时候就无需做重复计算。书中给出了一个修饰器:
class Memoized:
def __init__(self, fn):
self.fn = fn
self.results = {}
def __call__(self, *args, **kwargs):
key = ''.join([str(arg) for arg in args] + ["{}:{}".format(k, v) for k, v in kwargs.items()])
try:
return self.results[key]
except KeyError:
self.results[key] = self.fn(*args)
return self.results[key]
利用这个可以更快速地计算斐波那契数列:
@Memoized
def fib(n):
if n == 0: return 0
if n == 1:
return 1
else:
return fib(n - 1) + fib(n - 2)
测试一下性能:计算fib(40)。使用了Memoized修饰器地时候花了0.0005秒,不用的时候我的垃圾 macbook air 跑了106.4099秒,可见性能差距之大。

0x02 Defult Arguments
第二个(优化过的)factor参数会在函数创建时就被进行计算。
import math
def degree_sin(deg):
return math.sin(deg * math.pi / 180.0) * math.cos(deg * math.pi / 180.0)
def degree_sin_opt(deg, factor=math.pi / 180.0, sin=math.sin, cos=math.cos):
return sin(deg * factor) * cos(deg * factor)
每个函数执行1000次然后计算平均值,发现第二种地性能有了明显提升。原因在于第二种参数只需要在函数第一次创建的时候计算一次
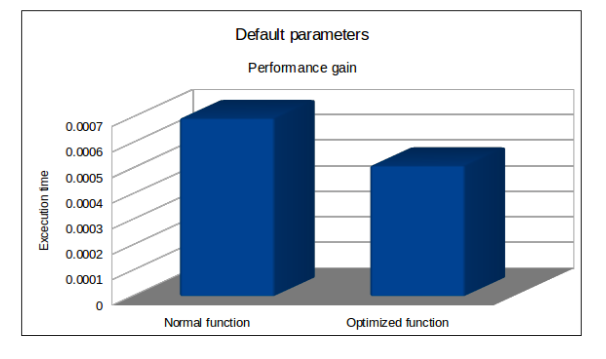
但是这种方法如果不做很好地文档说明的话,有可能会带来问题。除了能够代理显著的性能提升,不建议使用。
0x03 List comprehension & Generators
用列表生成器比 for 循环性能要高。
# 类别生成器
multiples_of_two = [x for x in range(100) if x % 2 == 0]
# for 循环
multiples_of_two = []
for x in range(100):
if x % 2 == 0:
multiples_of_two.append(x)
要搞清楚问什么,需要看看底层的 bytecodes,这里使用到了dis模块。同时,timeit.timeit() 方法默认执行 code 1000000次,你也可以通过 number指定运行次数。
import dis
import timeit
programs = dict(
comprehension_code="""
[x for x in range(100) if x % 2 == 0]
""",
forloop_code="""
multiples_of_two = []
for x in range(100):
if x % 2 == 0:
multiples_of_two.append(x)
"""
)
for program, code in programs.items():
dis.dis(code)
print("{} spent {} seconds".format(program, timeit.timeit(stmt=code)))
print()
你不需要完全看懂每一行 bytecode,简单来说,list comprehension有更少的 bytecode,同时用了优化过的LIST_APPEND指令,而 for 循环中用的是LOAD_ATTR, LOAD_NAME, CALL_FUNCTION这三条指令。
2 0 LOAD_CONST 0 (<code object <listcomp> at 0x102e5f420, file "<dis>", line 2>)
2 LOAD_CONST 1 ('<listcomp>')
4 MAKE_FUNCTION 0
6 LOAD_NAME 0 (range)
8 LOAD_CONST 2 (100)
10 CALL_FUNCTION 1
12 GET_ITER
14 CALL_FUNCTION 1
16 RETURN_VALUE
Disassembly of <code object <listcomp> at 0x102e5f420, file "<dis>", line 2>:
2 0 BUILD_LIST 0
2 LOAD_FAST 0 (.0)
>> 4 FOR_ITER 20 (to 26)
6 STORE_FAST 1 (x)
8 LOAD_FAST 1 (x)
10 LOAD_CONST 0 (2)
12 BINARY_MODULO
14 LOAD_CONST 1 (0)
16 COMPARE_OP 2 (==)
18 POP_JUMP_IF_FALSE 4
20 LOAD_FAST 1 (x)
22 LIST_APPEND 2
24 JUMP_ABSOLUTE 4
>> 26 RETURN_VALUE
comprehension_code spent 10.200395356 seconds
2 0 BUILD_LIST 0
2 STORE_NAME 0 (multiples_of_two)
3 4 SETUP_LOOP 38 (to 44)
6 LOAD_NAME 1 (range)
8 LOAD_CONST 0 (100)
10 CALL_FUNCTION 1
12 GET_ITER
>> 14 FOR_ITER 26 (to 42)
16 STORE_NAME 2 (x)
4 18 LOAD_NAME 2 (x)
20 LOAD_CONST 1 (2)
22 BINARY_MODULO
24 LOAD_CONST 2 (0)
26 COMPARE_OP 2 (==)
28 POP_JUMP_IF_FALSE 14
5 30 LOAD_NAME 0 (multiples_of_two)
32 LOAD_METHOD 3 (append)
34 LOAD_NAME 2 (x)
36 CALL_METHOD 1
38 POP_TOP
40 JUMP_ABSOLUTE 14
>> 42 POP_BLOCK
>> 44 LOAD_CONST 3 (None)
46 RETURN_VALUE
forloop_code spent 15.124301844 seconds
如果你不需要一次性全部生成所有的元素,只是想一个一个遍历,List comprehension可以进一步优化成 generators:
def gene_multiples_of_two(most):
x = 0
while x <= most:
if x % 2 == 0:
yield x
x += 1
0x04 ctypes
注意只有cpython可以用ctypes扩展,因为cpython是用 c 写的,但是其他的比如Jython、PyPy不行。你可以引入已经编译过的 c code。比如 Windows 的kernel32.dll,msvcrt.dll和Linux 的libc.so.6。
现在我们要找出一百万以内的所有质数,纯python的写法如下(这里不用关心质数判断函数的原理,如果你想了解,点这里):
from math import sqrt
from itertools import count, islice
def is_prime(n):
return n > 1 and all(n % i for i in islice(count(2), int(sqrt(n) - 1)))
[x for x in range(1000000) if is_prime(x)]
一共花了14秒。
用 c 写一个 Shared library:check_prime.c:
#include <stdio.h>
#include <math.h>
int check_prime(int a)
{
int c;
for ( c = 2 ; c <= sqrt(a) ; c++ ) {
if ( a%c == 0 )
return 0;
}
return 1;
}
gcc -shared -o check_prime.so -fPIC check_prime.c
在 Python 代码中引入:
check_primes_types = ctypes.CDLL('./check_prime.so').check_prime
[x for x in range(1000000) if check_primes_types(x)]
现在耗时2s,性能提升了7倍。
0x05 String concatenation
cpython 对于字符串的处理和其他语言不太一样,如果有两个变量a和b,值都是hello world,那么在内存中,他们实际上指向的是同一个东西,如果修改 b 的值,会将 b 指向另外一个字符串:
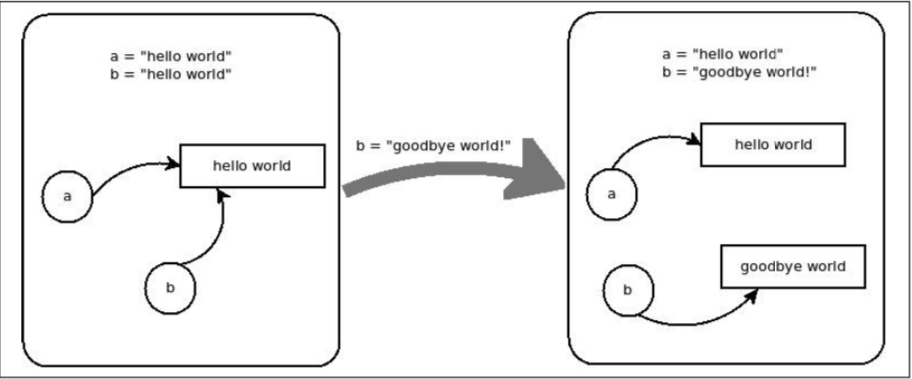
如果再把 a的值修改一下,内存中的hello world将会被 gc 掉。一开始 Python 的这种方式看起来很奇怪,但是这不是没有道理的:
That being said, immutable objects are not all that bad. They are actually good for performance if used right, since they can be used as dictionary keys, for instance, or even shared between different variable bindings (since the same block of memory is used every time you reference the same string). This means that the string hey there will be the same exact object every time you use that string, no matter what variable it is stored in (like we saw earlier).
字符串可以被用于字典的 keys。不同的变量可能会指向同一个字符串,所以这些内存就可以共享,从而在一定程度上节省了内存。
这样的设计对于我们开发者而言有什么影响呢?看下面这个例子。这个例子内存使用是有问题的,你看出来了吗?每次循环,都会创建一个新的字符串。
full_doc = ""
words = [str(x) for x in range(1000000)]
for word in words:
full_doc += word
用列表生成器会更加高效:
full_doc = "".join(world_list)
类似的还有:
document = title + introduction + main_piece + conclusion
会创建不必要的中间变量,用下面这种方法会好一点:
document = "%s%s%s%s" % (title, introduction, main_piece, conclusion)
0x06 并发
初学者往往对并发和并行两个概念搞不清,认为只有并行才能并发。这是一个很大的话题,同时我觉得《Mastering Python High Performance》这本书这部分讲得并没什么特别好的地方,可以看一下我前面写的几篇文章:
0x07 其他
- Membership testing : 能用字典就别用列表。
- 使用内置库:Python 自带的一般就是最优的,比如
map(operator.add, list1, list2会比map(lambda x, y: x+y, list1, list2)高效。 collections.deque,当需要频繁使用pop、insert的时候,deque会比list更加高效,因为deque有 O(1)的pop(0)、pop(-1)和append性能。- 使用 key 而不是比较函数进行排序:
l.sort(key=lambda a: a[1])
要比
l.sort(cmp=lambda a,b: cmp(a[1], b[1]))
更加高效。

如果你像我一样真正热爱计算机科学,喜欢研究底层逻辑,欢迎关注我的微信公众号:

