

最近在用蓝奏云,这款云盘无限速并且操作分享简单,自认为挺好的一个云盘,所以研究了如何通过蓝奏云分享链接获取文件最终地址。你可能问爬取直链有什么用,我说一下我的需求,我的服务器学生机带宽是1m,很小。我运营着自己的app,我想要为用户提供升级更新,如果把最新安装包放在我服务器上,1m就是128k/s,下载一个10m的安装包都要好长时间,但是如果我们将安装包放在云盘上,每次用户请求更新,我们只需要即时获取安装包在蓝奏云的真实地址返回给用户,这样用户直接从获取蓝奏云获取apk文件,下载速度比直接从自身1m带宽服务器快多了。所以,蓝奏云可以作为我们存放共享资源文件的地方。
- 直接以我云盘上存放的一首歌为例子,讲解如何爬取蓝奏云直链。这个音乐分享地址为https://www.lanzous.com/i3xcmaf
- 先贴完整代码
#coding=utf-8
from bs4 import BeautifulSoup
import requests
import re
import json
#蓝奏云分享文件链接地址
url = 'https://www.lanzous.com/i3xcmaf'
#header头,注意那个referer必须要与上面文件分享地址url相同
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.3',
'referer': url
}
# 获取分享页面html文件
res = requests.get(url,headers=headers)
# 引入BeautifulSoup库对html进行处理,获取iframe中的出现的js文件
soup = BeautifulSoup(res.text,'html.parser')
url2 = 'https://www.lanzous.com/'+soup.find('iframe')['src']
res2 = requests.get(url2,headers=headers)
# 正则提取请求三个参数
a = re.findall(r'var a = \'([\w]+?)\';',res2.text)
params = re.findall(r'var [\w]{6} = \'([\w]+?)\';',res2.text)
# 请求下载地址
url3 = 'https://www.lanzous.com/ajaxm.php'
data = {
'action':'down_process',
'file_id':params[0],
't':params[1],
'k':params[2],
}
res3 = requests.post(url3,headers=headers,data=data)
res3 = json.loads(res3.content)
# 请求最终重定向地址
url4 = res3['dom']+'/file/'+res3['url']
headers2 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
}
res4 = requests.head(url4, headers=headers2)
print res4.headers['Location']
- 先打开我们例子中的分享链接
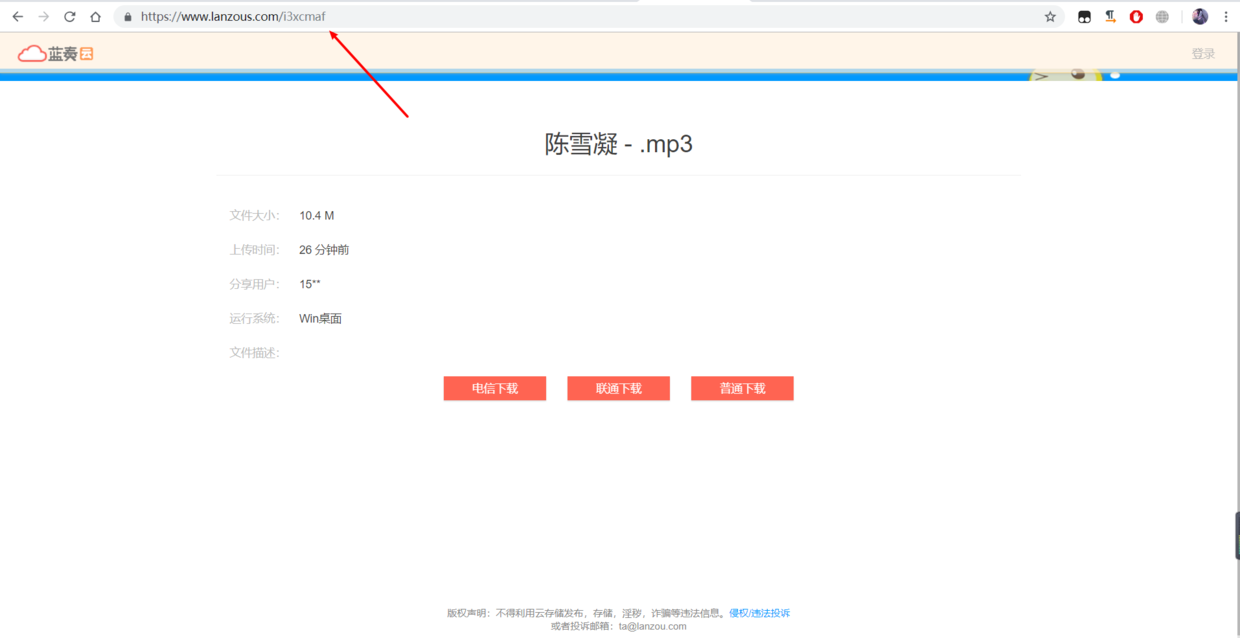
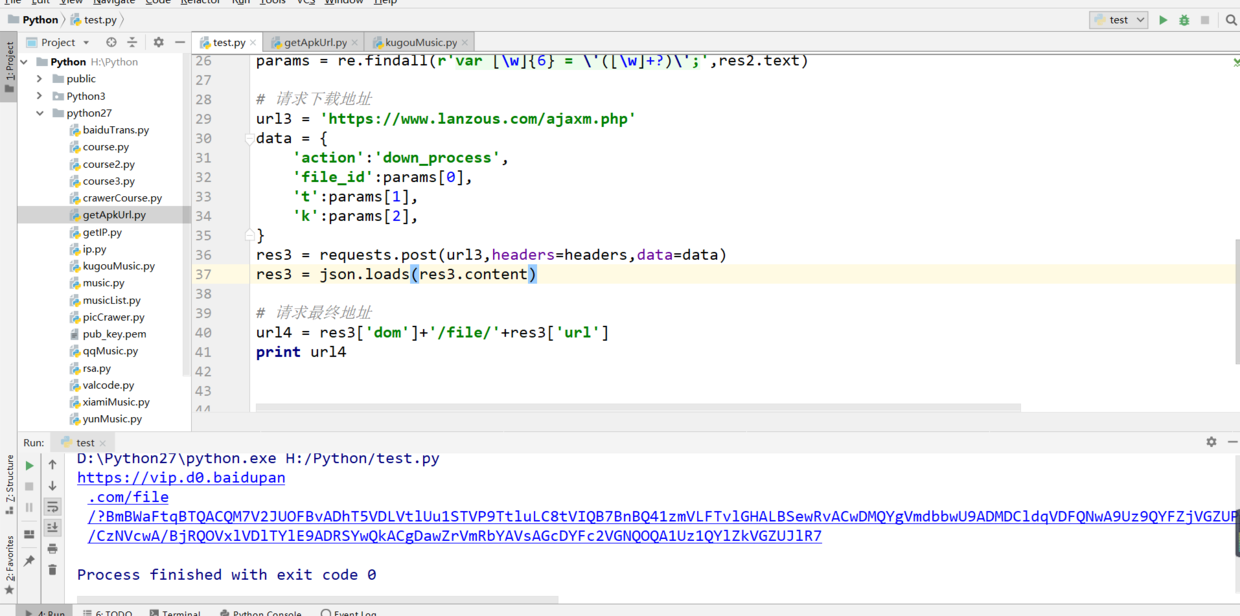
4.先来看看目前蓝奏云真实地址是什么格式,直接选中电信下载右键,复制链接,其格式类似https://vip.d0.baidupan.com/file/?UzVSbA4/BDUFDAU9UWRdMVRrVGxf6QqRB4hWuQXCAapUsVWFC8tSJgR/C30LuFzmUbQO4wXTALBReFU+VXkDMVN1UmMOOgQ8BTYFDFFsXThUM1RpXzMKOgcyVmQFbAE1VHJVZAslUjsEYwttC2dcZFE+DjMFbwA0UXBVI1V5Az9TYVI1DmIEaQV8BWNRMV1zVDxUZl8vCmoHNFY1BWwBNFRlVTQLYVIwBGMLbQtuXDxROA4+BT4ANlFuVWdVawM3U2RSNQ42BDMFYAUxUT1dOFQ9VGVfNAomB21WIAVqASZUIVVxCzNSdAQ7CzkLYlxlUTwOPwVpADRRYFV1VX0Da1M+UmAONQRtBWIFZlEwXWpUPFRoXzkKOgc5VmEFdwEmVCFVcgtrUjcEfA==,类似这种,前面是文件服务器域名,后面跟着看着像base64格式的字符串。(拿这个链接复制到浏览器地址栏,回车就会创建下载任务,但其实这还不是最终地址,如果直接请求这个,得到的只是html文件,它重定向后才是真实文件地址,这点大坑,后面具体介绍)
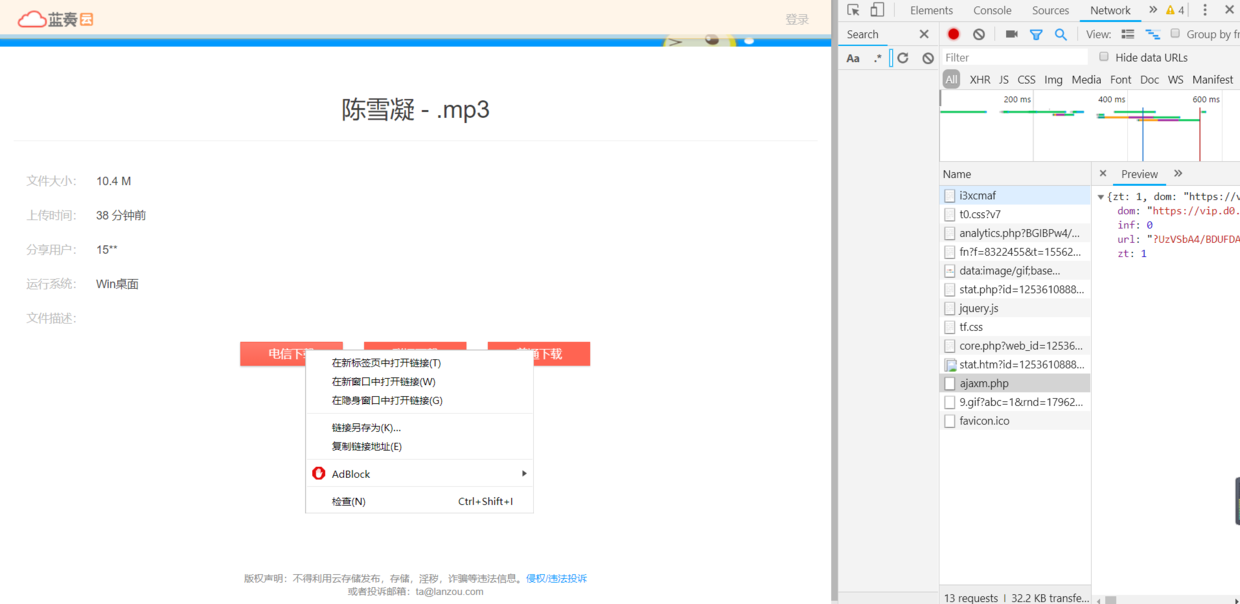
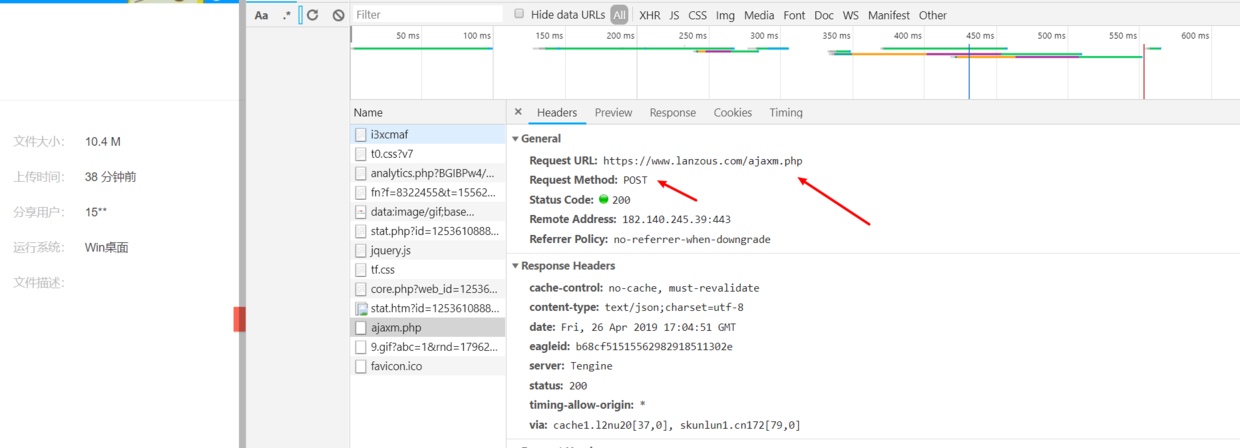
- F12进入开发者模式,刷新网页,列表会发现一个ajaxm.php文件,右面preview看见具体返回的响应内容,dom,url和刚才上一步猜的真实地址格式正好相符,拼接一下就是地址。
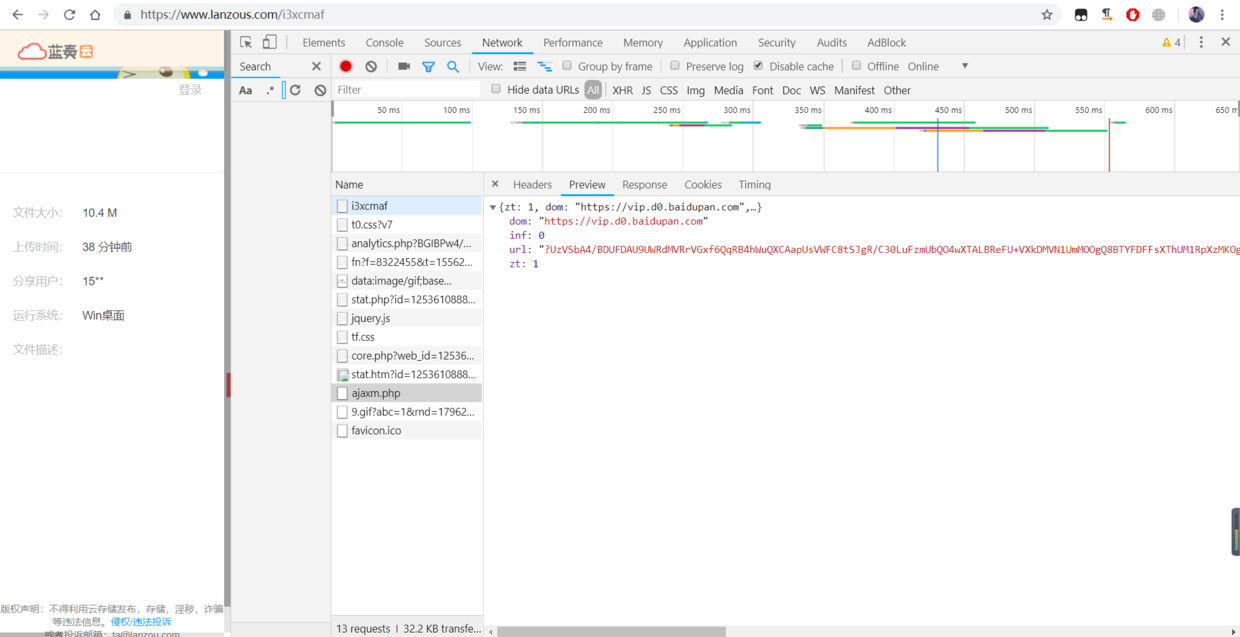
- 切换headers,看到这是一个post请求,看一下下面的请求参数,我们只要搞到这几个参数怎么生成的,就能构造post请求,拼接返回内容中的dom和url形成下载地址。
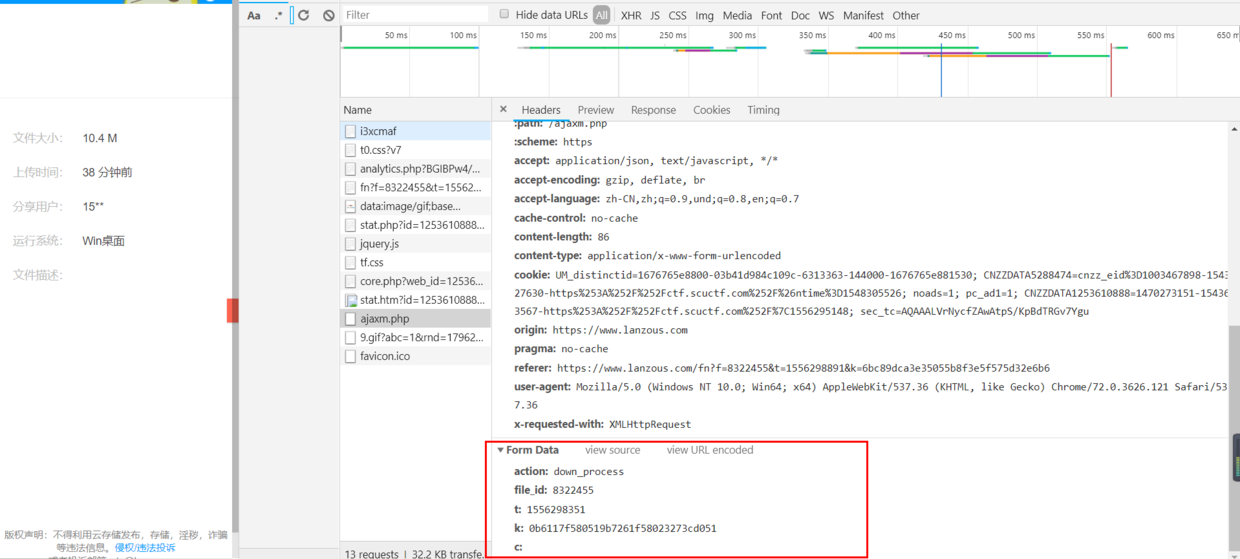
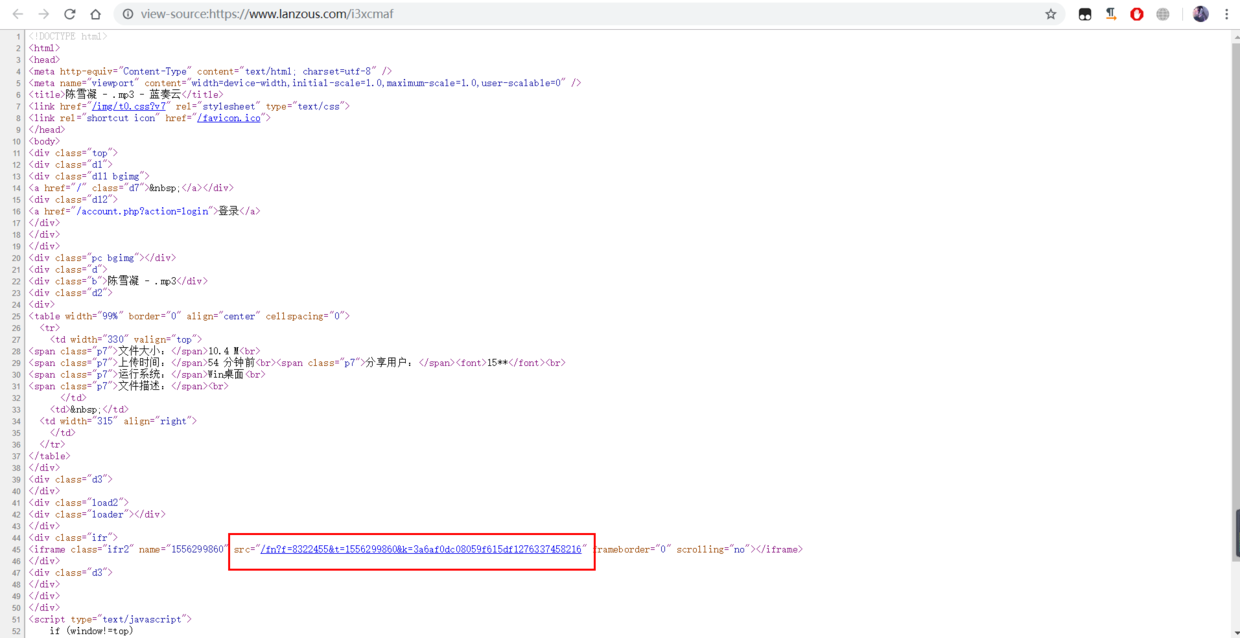
7.这几个参数是如何生成的,右键看一下分享链接网站源代码,其中箭头标注的这个就是那个三个框 电信下载 联通下载 普通下载 页面

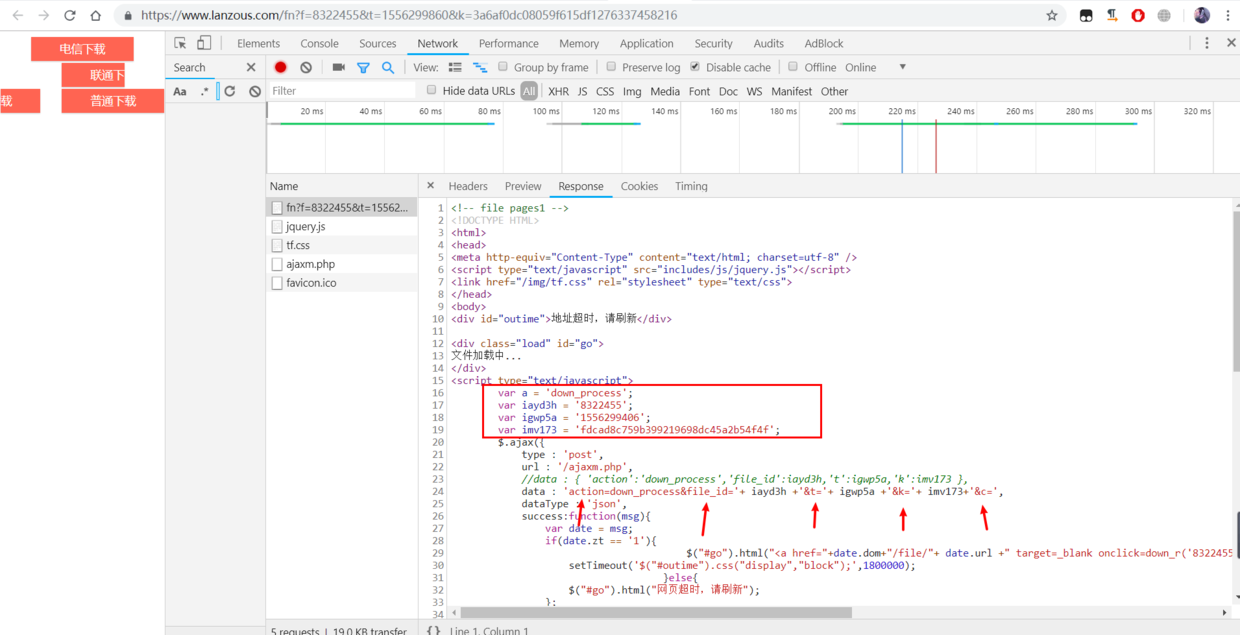
#coding=utf-8
from bs4 import BeautifulSoup
import requests
import re
import json
#蓝奏云分享文件链接地址
url = 'https://www.lanzous.com/i3xcmaf'
#header头,注意那个referer必须要与上面文件分享地址url相同
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.3',
'referer': url
}
# 获取分享页面html文件
res = requests.get(url,headers=headers)
# 引入BeautifulSoup库对html进行处理,获取iframe中的出现的js文件
soup = BeautifulSoup(res.text,'html.parser')
url2 = 'https://www.lanzous.com/'+soup.find('iframe')['src']
res2 = requests.get(url2,headers=headers)
# 正则提取请求三个参数
a = re.findall(r'var a = \'([\w]+?)\';',res2.text)
params = re.findall(r'var [\w]{6} = \'([\w]+?)\';',res2.text)
# 请求下载地址
url3 = 'https://www.lanzous.com/ajaxm.php'
data = {
'action':'down_process',
'file_id':params[0],
't':params[1],
'k':params[2],
}
res3 = requests.post(url3,headers=headers,data=data)
res3 = json.loads(res3.content)
# 请求最终地址
url4 = res3['dom']+'/file/'+res3['url']
print url4
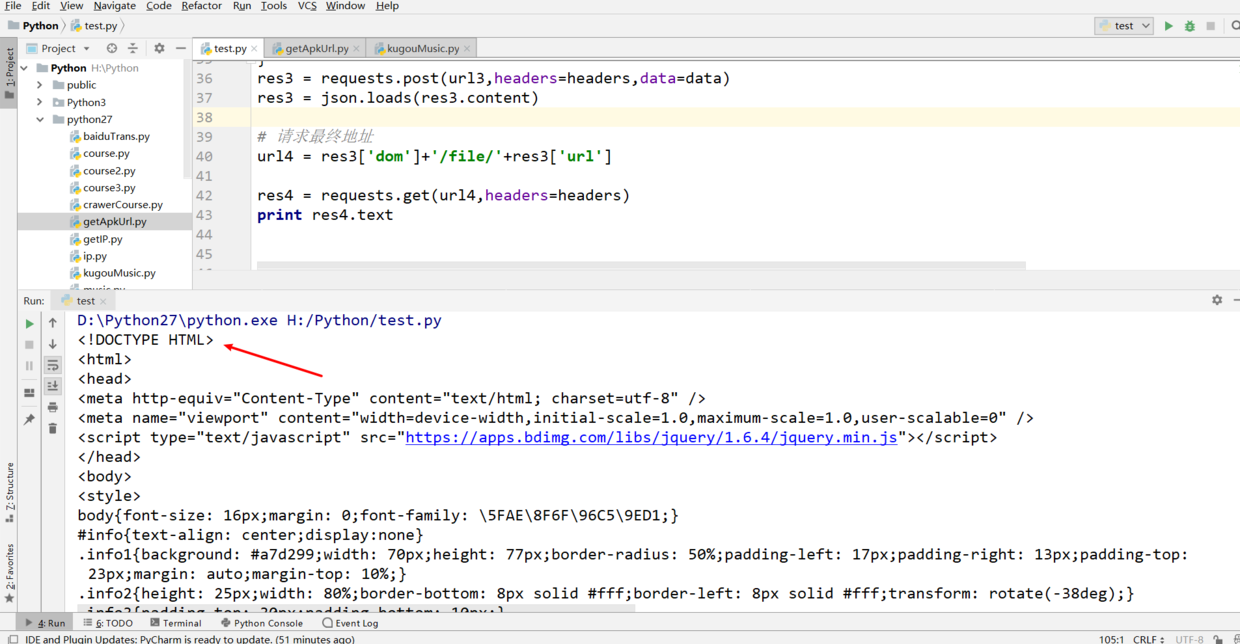
- 这点坑我很久,我看了一下浏览器那个ajax请求,状态码是302重定向,我试了好久还是返回html,我最后干脆将浏览器的headers头全部加进去了,发现重定向成功了,返回的就是音乐文件,里面二进制乱码。我headers头一个个删除看哪条信息是有用的,最后发现Accept-Language必须要有,这点好坑的

- 知道了这个,我们拿到那个下载地址,然后再重定向一下就可以了,注意获取重定向地址不必进行get请求,因为这回请求整个文件,直接request.head()进行请求,然后打印res.headers['Location']就是重定向信息,这样请求只是请求头信息,不必请求整个文件。
- 最后贴上完整代码
#coding=utf-8
from bs4 import BeautifulSoup
import requests
import re
import json
#蓝奏云分享文件链接地址
url = 'https://www.lanzous.com/i3xcmaf'
#header头,注意那个referer必须要与上面文件分享地址url相同
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.3',
'referer': url
}
# 获取分享页面html文件
res = requests.get(url,headers=headers)
# 引入BeautifulSoup库对html进行处理,获取iframe中的出现的js文件
soup = BeautifulSoup(res.text,'html.parser')
url2 = 'https://www.lanzous.com/'+soup.find('iframe')['src']
res2 = requests.get(url2,headers=headers)
# 正则提取请求三个参数
a = re.findall(r'var a = \'([\w]+?)\';',res2.text)
params = re.findall(r'var [\w]{6} = \'([\w]+?)\';',res2.text)
# 请求下载地址
url3 = 'https://www.lanzous.com/ajaxm.php'
data = {
'action':'down_process',
'file_id':params[0],
't':params[1],
'k':params[2],
}
res3 = requests.post(url3,headers=headers,data=data)
res3 = json.loads(res3.content)
# 请求最终重定向地址
url4 = res3['dom']+'/file/'+res3['url']
headers2 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
}
res4 = requests.head(url4, headers=headers2)
print res4.headers['Location']
