

让你听见你想要听见的,让你看见你想要看见的。Joi能满足你的一切幻想。 --《银翼杀手2049》
在这部电影中,用程序设定的虚拟人物,时时刻刻的与主角进行情感沟通,甚至产生了亲密的感情,或许这个在未来真的能够实现。现在转到现实中来,近两年AI的热度暴涨,其中自然语言处理也是研究的重点,现在显然已经有非常显著的效果。
情感在人类信息沟通的意义
情感对于人类的社交、表达、记忆、决策和感知上都有很重要的作用,有研究显示人类交流中的80%信息都是带有情感信息的。情感状态不同会影响人的思维和行动,特别是积极或消极所带来的影响有很大的不同。由于情感在人类沟通的重大意义,所以在设计人与计算机交流的时候也是必不可少的部分。通过和人的聊天,AI可用情感分析对实体进行高效率的自动化标注,学习到用户的性格变得更加智能。像微软的小冰,聊的越多越“懂”自己。
一般情况下,我们探讨的情感分析多指文本中的情感分析,也有更多维的情感分析,比如文字+图片+标签+语音+面部表情、肢体动作等等,就像前一段时间被授予合法公民身份的AI机器人索菲亚可以通过摄像声音和周围的环境来通过面部表情来传达情感。人类能表达的情感的信息量的大小和维度。比如面对面交流时,情感性的信息往往是从语音语调、面部表情、肢体等多个维度表达出来的。然而到了人机交互中,情感宽带的整个范式会发生较大的变化,如通过人机对话系统交流时,少了肢体这个维度,人类的情感带宽似乎瞬间骤降了。但实际上也增加了几个新的输出维度,如图片、表情包、回复时间的长短等。
情感分析之文本情感倾向分析
显然,面对多维更加智能的场景,目前的技术实现起来难度很大,但是针对大多数的文本语意的表达还是有比较成熟的解决方案,现在就来说一下深度学习在自然语言处理的表现吧。
深度学习在情感分析中的应用已经较为普遍了,如利用 LSTM 结合句法分析树、基于卷积神经网络和支持向量机等。一般情况下,对于各种方法的综合创新应用,能达到取长补短的效果,进而能够提高情感分析的准确率,另外还能从无标注的文本里学习到其中的隐藏特征,以实现端到端的分类。
关于更多的深度学习相比于词典以及传统的机器学习的方式的优势,大家可以自行查阅相关文章,这篇文章只将用深度学习来简单的训练一个样本,并预测任意一个句子的情感倾向。
情感分析工具keras,语言包括中文和英文
开始之前,你需要对深度学习原理有比较深刻的了解,lstm的原理,调参优化细节,keras基本知识的掌握。项目github地址戳这里。
1. 准备语料
本次收集的语料不是太多。中文大概2w多条(淘宝评论),英文1w多条(电影评论),以后有时间会继续补充语料。其中有5%作为验证集,10%为测试集合。文件已经切分好,但是因为需要训练所有数据集,所以这个提前切分到不同文件夹并没有什么作用(后面讲到会重新合并再切分)。
2.选择语言版本,分别设置训练集、测试集、验证集和维度
因为后面的程序要训练中文或英文,所以在这里提前选择语言版本和不同的语言版本训练相关的参数。
# 选择语言中文还是英文
languageType = ''
while (languageType != 'c' and languageType != 'e'):
languageType = input("Please enter a train type(chinese enter lower: c , english enter lower: e): ")
max_length = '' #一句话最大长度
load_path = '' #文件加载路径
language = '' #语言类型
tr_num = 17000 #训练集
va_num = 2000 #训练集
if languageType == 'c':
max_length = 100
load_path = 'data/chinese'
language = 'chinese'
tr_num = 17000
va_num = 2000
elif languageType == 'e':
max_length = 40
load_path = 'data/english'
language = 'english'
tr_num = 8000
va_num = 600
3.加载数据集
这里把中文和英文放在不同的文件夹下,利用 pandas中的read_csv()读取数据集合并到一起,如果这里本来就是一个整的数据集。则直接读取就好。
# 获取csv文件:内容放到数组里面 分别是训练集、验证集、测试集,最后合并到一起
def sst_binary(data_dir='data/chinese'):
tr_data = pd.read_csv(os.path.join(data_dir, 'train_binary_sent.csv'))
va_data = pd.read_csv(os.path.join(data_dir, 'valid_binary_sent.csv'))
te_data = pd.read_csv(os.path.join(data_dir, 'test_binary_sent.csv'))
all_data = tr_data.append(va_data).append(te_data)
return all_data
4.数据预处理
这一步是针对中文和英文的特点来处理掉对分析无用的词提升精度。比如停用词、标点符号、特殊字符、转义字符等等。因为语料比较少,这个程序还没有针对这一块做处理。
5.将词语转化为向量
这里是最核心的地方,深度学习在训练数据的时候要求输入的数据是一个向量,这样才能进行矩阵运算,也是多层感知器的输入。所以如果直接将一组句子是无法识别的。所以最重要的一步就是将词语转化为词向量,可是如何才能得到向量呢?
这里用到的是词嵌入的方法,大概步骤是:
- 中文最小统计粒度是词,所以要先切词(
jieba)将一句话按照词语切分开来而非字。 - 将所有词放在一起,统计每个词出现的次数按照重大到小的排序,然后加上索引。
- 将句子中的词语全部替换成相应的索引,这样一个句子中的每个词语就用一个数字去表示了。
- 调用keras model第一层
Embedding(),该层会利用词嵌入将句子数字数组转化为词向量。
需要注意的是,jieba分词虽然是分中文的,但是也可以处理英文(英文是按照空格切分的),这样可以得到比较统一的数组shape。
#定义模型
class Model(object):
def __init__(self, sentence_max_length=100):
sentence_max_length = sentence_max_length #截断词数 cut texts after this number of words (among top max_features most common words)
sentence_drop_length = 5 #出现次数少于该值的词扔掉。这是最简单的降维方法
#将每个句子里的词转化成词频索引值
def transform(data):
#如果是中文调用结巴分词
xs = data['sentence'].apply(lambda s: list(jieba.cut(s)))
#将所有词放到一个数组中
word_all = []
for i in xs:
word_all.extend(i)
#统计词频并排序建索引
global word_frequency, word_set
word_frequency = pd.Series(word_all).value_counts() #统计词频,从大到小排序
word_frequency = word_frequency[word_frequency >=
sentence_drop_length] #出现次数小于5的丢弃
word_frequency[:] = list(range(
1,
len(word_frequency) + 1)) #将词频排序的结果加索引
word_frequency[''] = 0 #添加空字符串用来补全,之前丢弃的后面的找不到的会用0代替
word_set = set(
word_frequency.index) #经过处理之后的所有词的数组集合,并且去掉可能存在的重复元素
#将词语替换成按照所有训练集词频排序后的索引
xt = xs.apply(lambda s: word2num(s, sentence_max_length))
xt = np.array(list(xt))
yt = np.array(list(data['label'])).reshape(
(-1, 1)) #此处用来调整标签形状n行1列 (-1是模糊控制即有不定多少行,1是1列)
#当前训练集合词的索引长度
wi = len(word_frequency)
return xt, yt, wi
self.transform = transform
6.keras 训练数据集
这一部分就交给keras处理了,具体用法可以参见keras中文文档,可以自定义一些参数,比如训练轮数、激活函数、加入验证集等等。当然核心的还是lstm了,相对于RNN,在训练长文本有更好的效果。训练完了之后可以选择保存模型。方便下次直接调用。
#将词转化为数字向量 即一个句子里的每个词都有用上面生成的索引值代替
def word2num(s, sentence_max_length):
s = [i for i in s if i in word_set]
s = s[:sentence_max_length] + [''] * max(0, sentence_max_length - len(s))
return list(word_frequency[s])
# krea 训练数据集
def model_train(x, y, wi, language, sentence_max_length=100, tr_num=17000, va_num=2000):
global model
model = Sequential()
model.add(Embedding(wi, 256, input_length=sentence_max_length))
model.add(LSTM(128))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(
loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(
x[:tr_num],
y[:tr_num],
batch_size=128,
nb_epoch=30,
validation_data=(x[tr_num:tr_num + va_num], y[tr_num:tr_num + va_num]))
score = model.evaluate(
x[tr_num + va_num:], y[tr_num + va_num:], batch_size=128)
model.save('model_' + language + '.h5')
return score[1]
#加载已经训练好的模型
def model_load(language):
global model
model = load_model('model_' + language + '.h5')
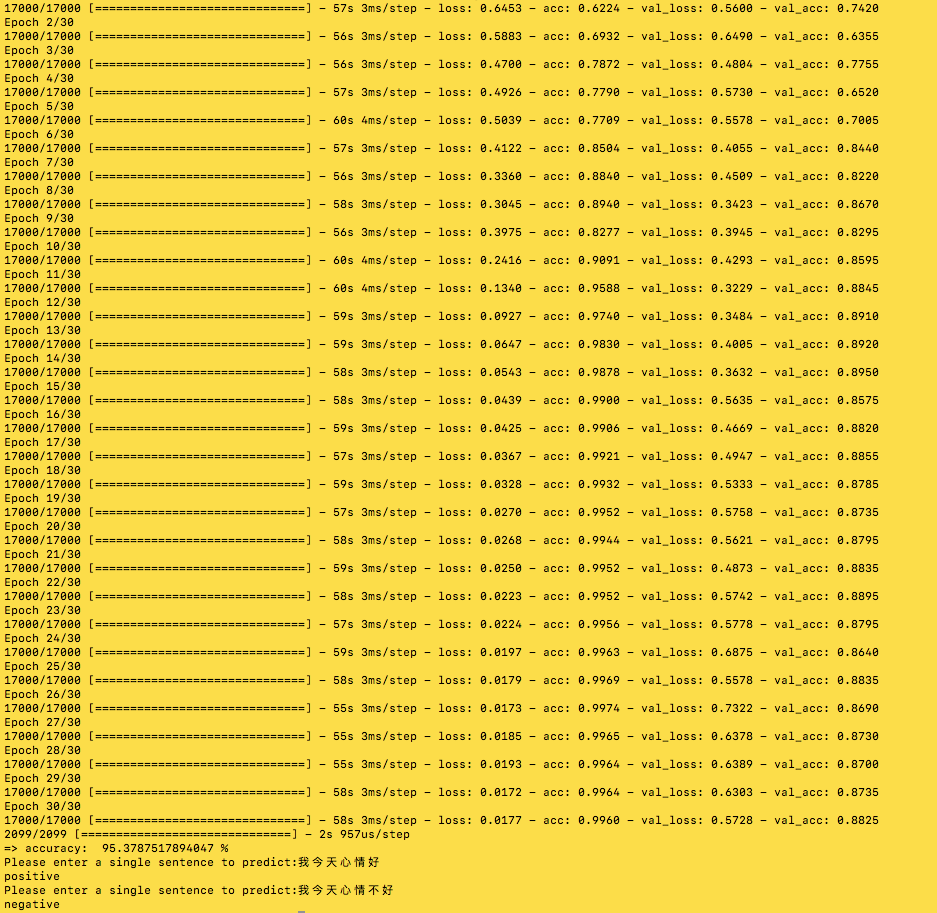

7.预测单个句子
预测单个句子依然需要将这个句子分词,然后将词转化为数字,所以还是用到训练模型时用到的处理方式。
#单个句子的预测函数
def model_predict(s, sentence_max_length=100):
s = np.array(word2num(list(jieba.cut(s)), sentence_max_length))
s = s.reshape((1, s.shape[0]))
return model.predict_classes(s, verbose=0)[0][0]
好了,大功告成,我们已经可以直接测试训练的结果了。
总结
现在,我们已经能够利用keras里的lstm对文本进行预测情感倾向了。但是这里完美还是有很大距离,需要不断的调参来提高准确度。能够提升的地方比如加大训练集数量、对数据预处理、调整训练次数等等。当然还有更酷的方案比如双向lstm这样的训练方式,综合对比,或许都是改良的途径。
目前一套模型同时解决中文和英文的例子还是非常少,毕竟语言的差异还是非常大,接下来会继续对其中进行一些探索,这个也是我对自然语言处理中的情感分析一点小小的尝试。
Github地址:github.com/Elliottssu/…
转载著名出处
