

引言:
“为啥我的程序卡住了,它在做啥?”
“磁盘卡死了,啥程序占用的?”
“该不该换成ssd?”
我们常遇到各种性能问题, 该如何定位问题,解决问题。
本文主要介绍系统性能的度量指标,分析思路,及相关工具集。
目录:
•系统性能指标和观测方法
•常用命令及平台-分析系统负载
•动态追踪-了解程序在做什么
•实战案例
性能问题是充满挑战的:
性能是主观的
磁盘平均io响应时间是10ms, 好或坏?
取决于业务需求及程序热点
系统是复杂的
子系统相互关联,甚至有连锁故障
运行环境不一(硬件/软件)
可能多问题并存
量化数据
控制变量法
观测视角
资源分析(自下而上)
从系统的资源指标开始
更通用,适合资源被打满的情况
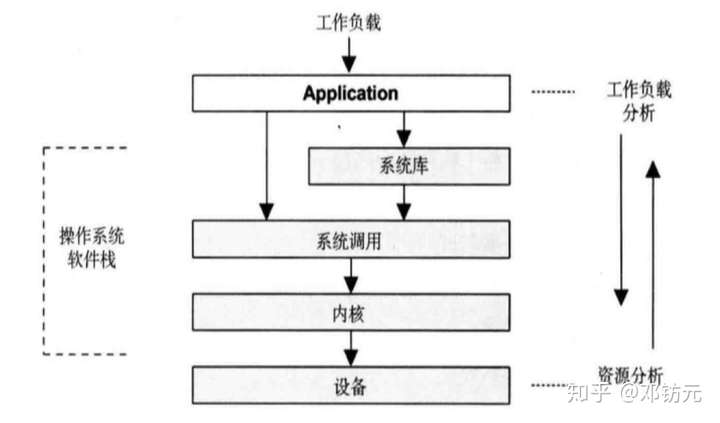
工作负载分析(自上而下)
从应用的metrics和stack开始
贴近代码逻辑,适合并发锁问题
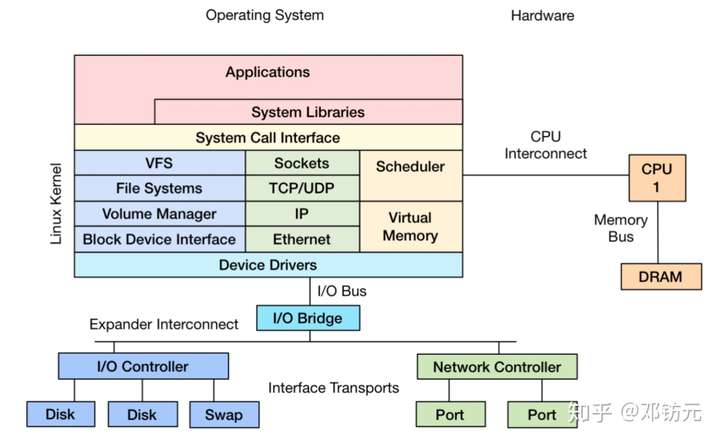
系统资源有哪些
硬件资源
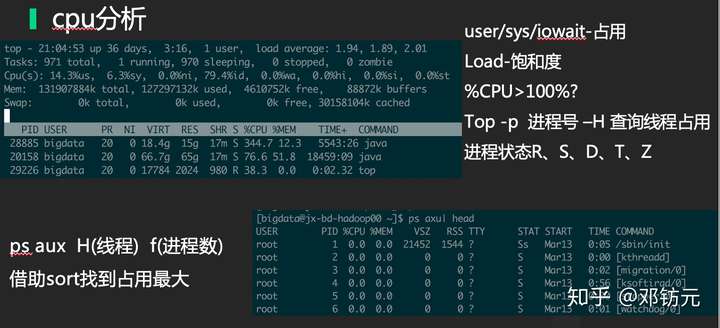
•CPU
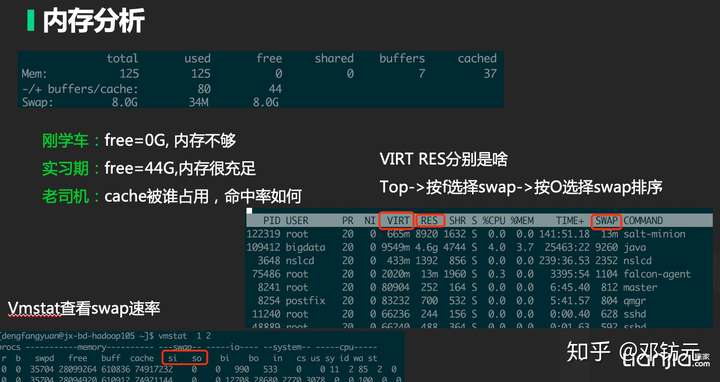
•内存
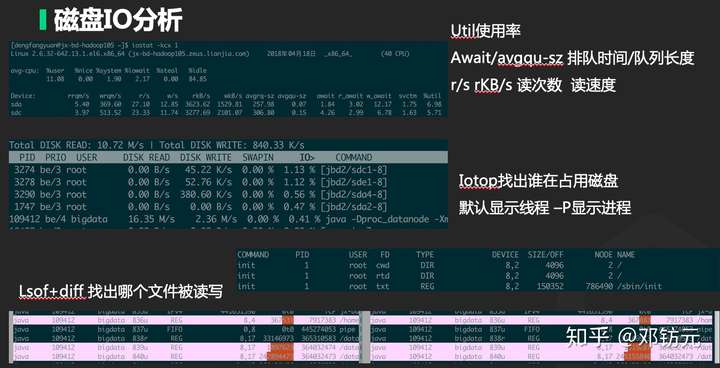
•磁盘
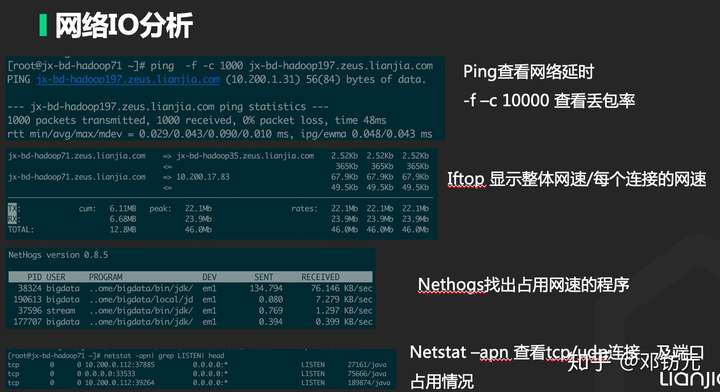
•网络
软件资源
•软件锁
•线程池/连接池
观测方法-USE方法
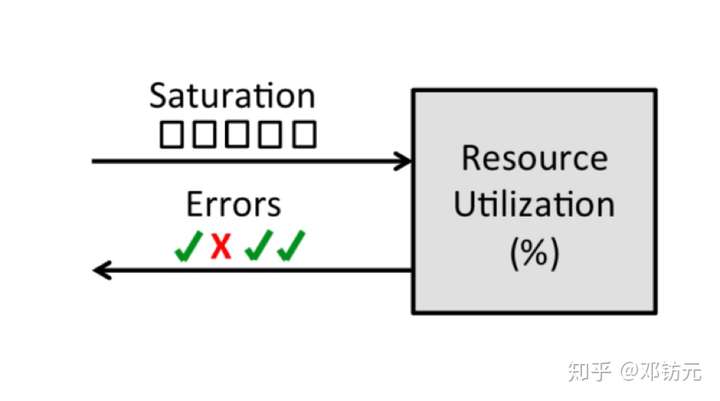
使用率( Utilization )
设备繁忙程度
工作时间/观测时间
饱和度( Saturation )
队列长度,排队时间
超出设备处理能力的程度
错误率( Errors )
设备出错率
分析方法:
问题
为什么A主机到B主机网络延迟很大?(事实:A和B在不同机架)
假设
A和B机架的交换机有故障
预测
A/B机架内互联通畅,A到另一机架的主机C通畅,A/B各机架各换一台机器互联延迟
实验
分别测试以上场景
分析
结果与预测相同,说明问题出在A和B的交换机有故障
常用命令及平台-分析系统负载
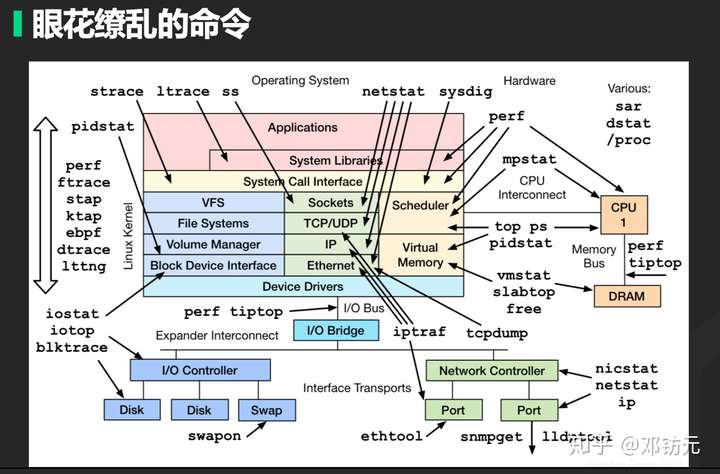
动态追踪-了解程序在做什么
动态追踪定义
无需修改程序源代码,活体分析
可实时跟踪程序状态,用于统计及分析
可以动态注入探针
本章主要介绍通用工具,及java相关工具


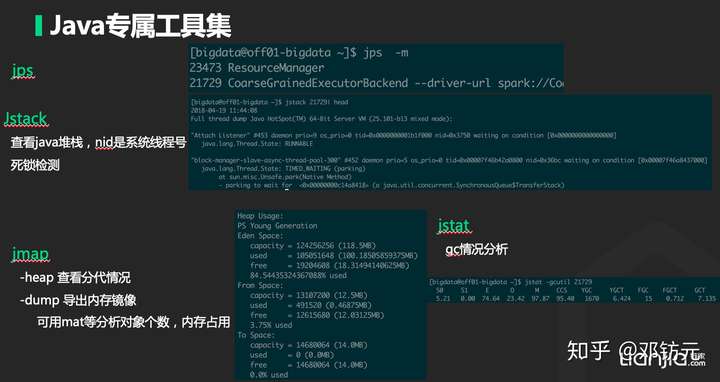
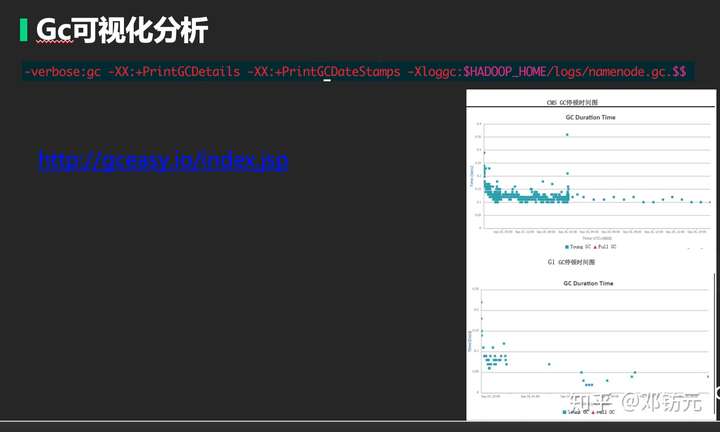
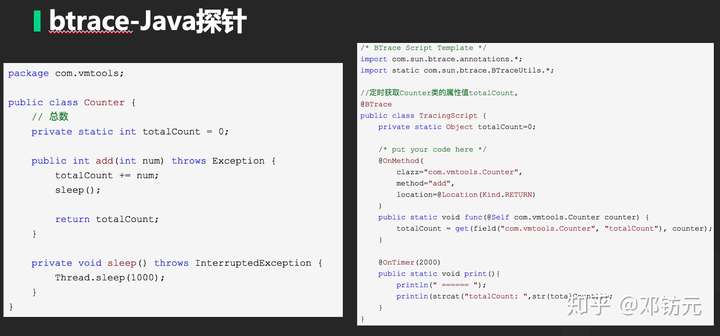
实战案例:
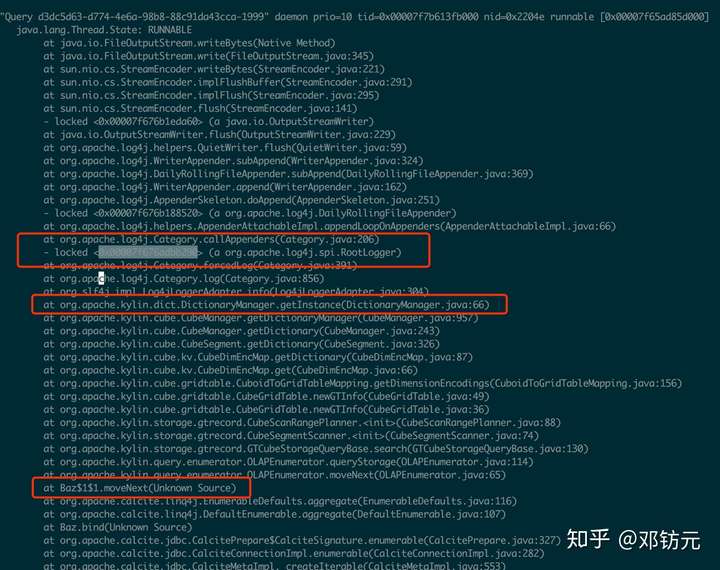
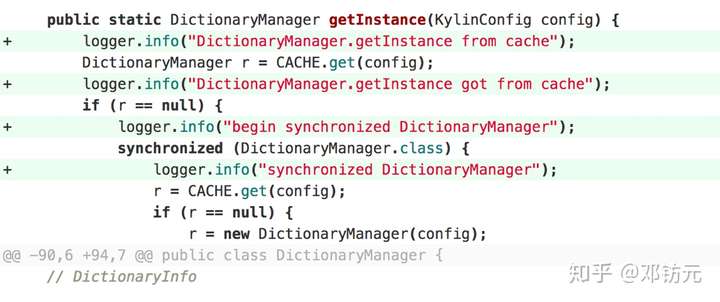
某查询服务日志锁问题
1.问题:
某查询服务上线新版后,查询时间从0.1s,变成几十秒,严重影响线上查询
2.排查:
依赖的底层存储hbase响应正常
机器的cpu,mem等参数均正常(可能是软件资源锁问题,着重排查)
本次上线代码主要加日志,回滚版本后正常(代码某处导致)
3.试验:
部署一台新版代码的服务,并引线上流量
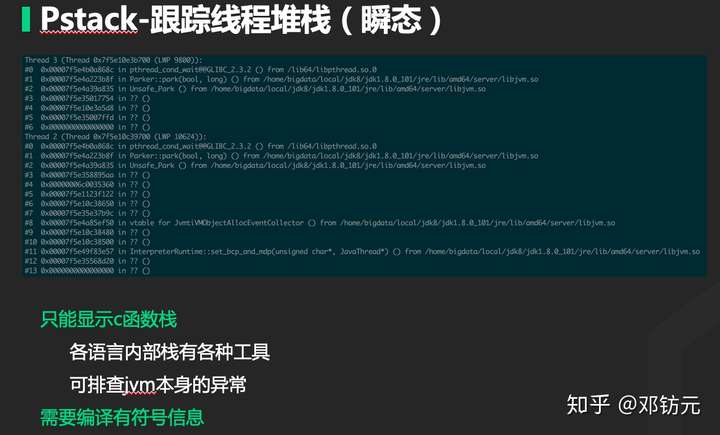
使用jstack分析
Kylin服务cpu占用过大问题
1.问题:
kylin是一个开源分析服务,试用发现并发在几十就上不去
2.排查:
cpu在查询时占用很高,2000%,均是user态(代码本身导致)
jstack分析(逻辑较为复杂,肉眼较难分辨)
3.试验:
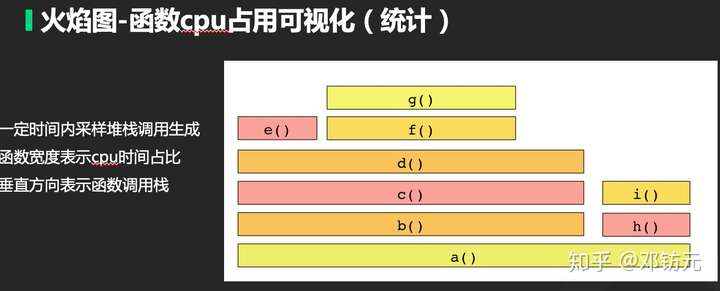
使用火焰图采样,查找代码热点
4.措施
修改加密验证方式为md5
性能提升5倍
修改前后的火焰图如下:


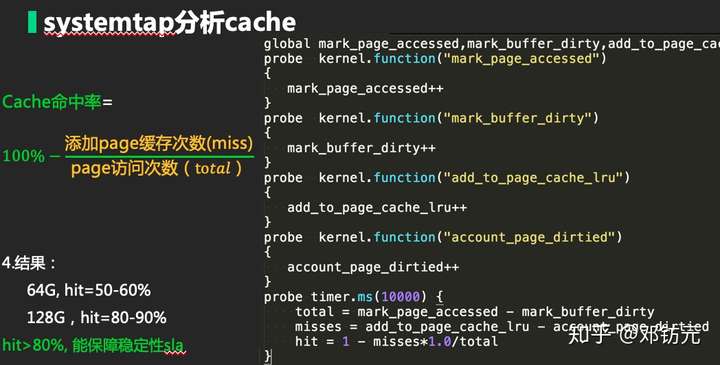
Cache对hbase的影响
1.疑惑:
hbase压测时经常宕掉,在将机器内存从64G升级128G非常稳定
2.排查/猜想:
hbase进程内存设置为50G,升级内存后也未调整
hbase本身堆使用率不高
多增加的内存会被OS用来做文件缓存(应该会大幅提升命中率)
相关资料提示hbase为IO敏感型,缓存命中率与稳定性有啥关系
3.试验:
借助systemtap统计cache命中率
推荐资料

Brendan Gregg:
原SUN公司首席性能和内核专家
Solaris,dtrace等系统
Netflix首席架构师
章亦春:
OpenResty(nginx高性能模块)开源项目创始人
阿里技术专家
