

面试视频总结
1 深浅拷贝
1 首先,python里面的可变对象和不可变对象
list,dict,set都是可变对象,值改变,id地址不变
str,int,tuple都是不可变对象,只改变,id地址也改变
2 深拷贝
是对值的拷贝
3 浅拷贝
是对引用的拷贝
2 常用的内置算法和数据结构

1 enumerate方法的使用,去同時打印列表的索引和值
l=['name', 'age', 'gender']
for k, v in enumerate(l):
print(k,v)
2 sorted的用法
d = {'name': 2, 'age': 1, 'gender': 5, 'addr': 10}
new_d = dict(sorted(d.items(), key=lambda x: x[1], reverse=True)) # True就是从大到小,False就是从小到大
3 collections

1 namedtuple 让tuple属性可读
import collections
Point = collections.namedtuple('Point', 'x,y')
p = Point(1,2)
print(p.x) # 1
print(p.x == p[0]) # True
2 deque 双端队列,可以往队列的两端append值
de = collections.deque() # 定义一个列表
de.append(1) # 往列表右边添加
de.append(2)
de.appendleft(0) # 往列表左边添加
print(de) # [0,1,2]
de.pop() # 删除列表右边的一个值
de.popleft() # 删除列表左边的一个值
print(de) # [1]
3 Counter 需要计数器的地方使用Counter
one_str = 'abcab' # 一个序列
one_list = [1,2,3,4,2,3,2,1]
c1 = collections.Counter(one_str) # Counter({'a': 2, 'b': 2, 'c': 1})
c2 = collections.Counter(one_list) # {2: 3, 1: 2, 3: 2, 4: 1}
c2.most_common() # 按照数量从大到小排列
print(c1)
4 OrderedDict 记录key进入的顺序
# OrderedDict实现LRUCache
d = collections.OrderedDict()
d['a'] = 'a'
d['f'] = 'f'
d['e'] = 'e'
d.move_to_end('a') #将key‘a’放到最后边
print(d.items()) # odict_items([('a', 'a'), ('f', 'f'), ('e', 'e')])
5 defaultdict(int) # 带有默认之的字典
dd = collections.defaultdict(int)
print(dd['a']) # 0
dd['ouyang'] += 1
print(dd) # {'a': 0, 'ouyang': 1}
4 Python dict的底层结构

哈希表是如何解决哈希冲突的?
链接法,探查法
5 list和tuple的区别
1 都是线性结构的,都可以通过索引访问
2 list是可变的,而tuple是不可变的(在tuple中是引用不可变,要是tuole中有一个元素是可变的,就可以操作)
注 保存的引用不可变是指你没法替换掉这个对象,但是如果对象本身是一个可变的,是可以修改这个引用指向的可变对象的
3 list不能作为字典的key,但是tuple可以(可变对象不可哈希)
6 什么是LRUChche?
least-Recently-Used 替换掉最近最少使用的对象
缓存剔除策略,当缓存空间不够用的时候需要一种方式剔除key
常见的有LRU(使用次数计算),LFU(使用时间计算)等
LRU使用一个循环双端队列不断把最新访问的key放在表头实现
如何实现LRUCache???
字典用来缓存,循环双端链表用来记录访问顺序
1 利用Python内置的dict+collections.OrderedDict()
2 dict用来当做k/v键值对的缓存
3 OrderdDict用来实现更新最近访问的key
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity=128):
self.od = OrderedDict()
self.capacity = capacity
def get(self, key): # 每次访问更新最新使用的key
if key in self.od:
val = self.od[key]
self.od.move_to_end(key)
return val
else:
return -1
def put(self, key, value): # 更新k/v
if key in self.od:
del self.od[key]
self.od[key] = value # 更新key到表头
else:
self.od[key] = value
# 判断当前容量是否满了
if len(self.od) > self.capacity:
self.od.popitem(last=False) # 删除最早的元素
Python算法和数据结构
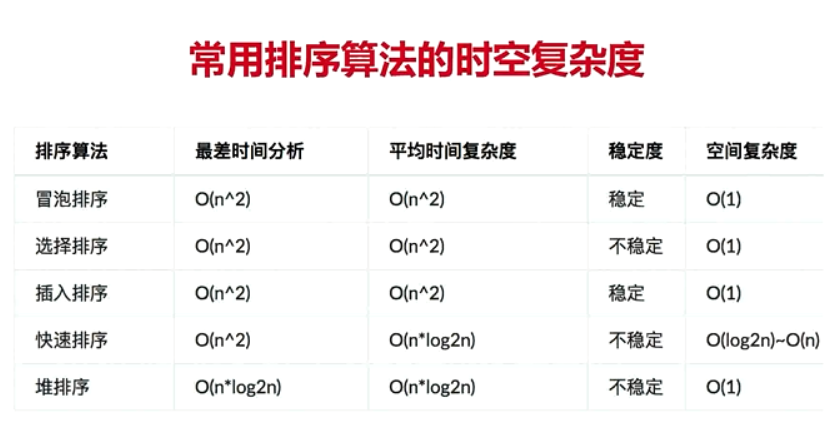
1 Python算法常考题
排序+查找 ,重中之重
1 常考排序算法:冒泡排序,快速排序,归并排序,堆排序
2 线性查找,二分查找
3 能独立实现代码(手写),能够分析时间空间复杂度
2 Python数据结构常考题
python web后端常考数据结构
1 常见的数据结构链表,队列,栈,二叉树,堆
2 使用内置结构实现高级数据结构,比如内置的list.deque实现栈
3 leetcode或者《剑指offer》
常考数据结构值链表
链表有单链表,双链表,循环双端链表
1 如何使用Python来表示链表结构
2 实现链表常见操作,比如插入节点,反转链表,合并多个链表等
3 Leetcode联系常见的题
3 链表反转
class Solution(object):
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
def helper(last, cur):
if cur == None: return cur
next = cur.next
cur.next = last
if next == None: return cur
return helper(cur, next)
return helper(None, head)
4 常考数据结构之队列
1 如何使用Python实现队列
2 实现队列的append和pop操作,如何做到先进先出
3 使用Python的list或者collections.deque实现队列
python实现队列,(队列是先进先出)
from collections import deque
class Queue:
def __init__(self):
self.items = deque()
def append(self, val):
return self.items.append(val)
def pop(self):
return self.items.popleft()
def empty(self):
return len(self.items) == 0
def test_queue():
q = Queue()
q.append(0)
q.append(1)
q.append(2)
q.append(3)
print(q.pop())
print(q.pop())
print(q.pop())
print(q.pop())
test_queue()
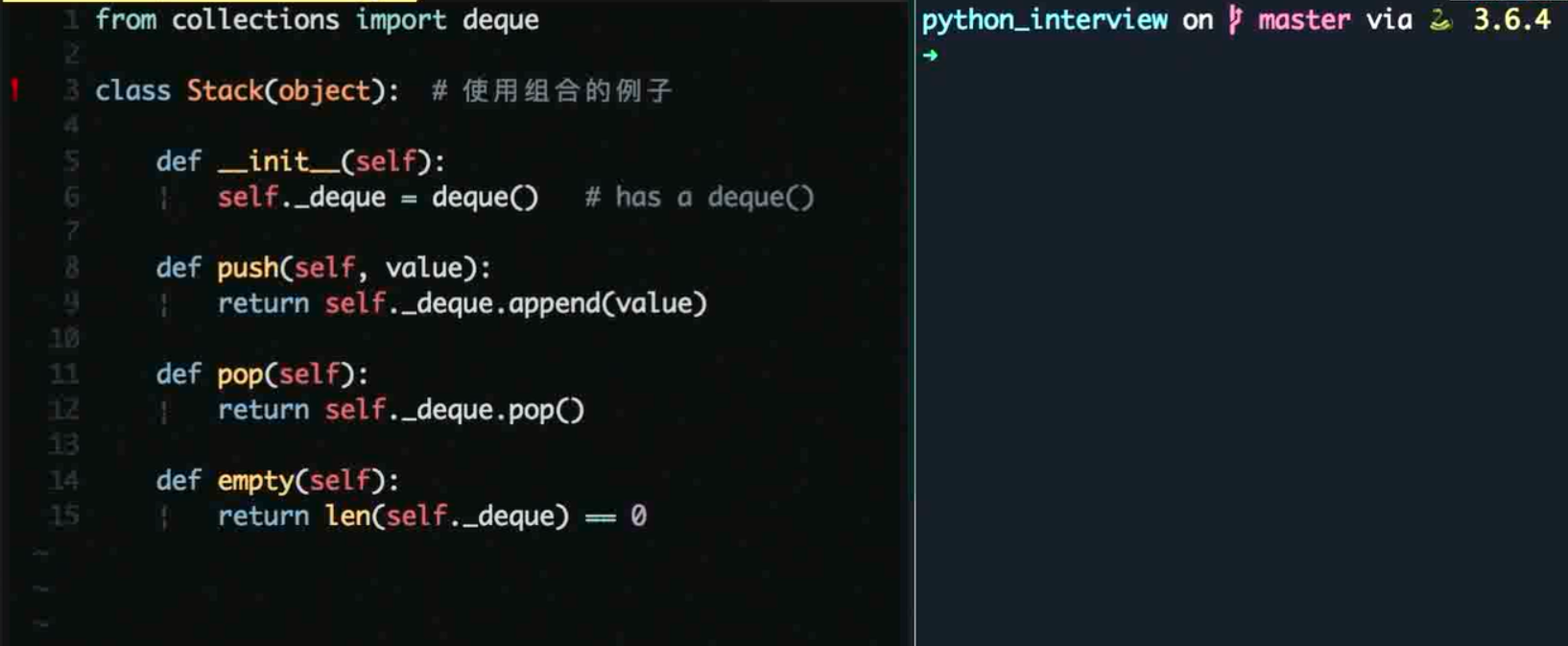
5 常考数据结构之栈(后进先出)
栈(stack)是后进先出结构
from collections import deque
class Stack(object):
def __init__(self):
self.items = deque()
def push(self, val):
return self.items.append(val)
def pop(self):
return self.items.pop()
stack = Stack()
stack.push(1)
stack.push(2)
stack.push(3)
print(stack.pop())
print(stack.pop())
print(stack.pop())
6 常考数据结构之字典与集合
1 Python dict/set底层都是哈希表
2 根据哈希函快速定位一个元素,平均查找O(1),非常快
3 不断加入元素会引起哈希表重新开辟空间,拷贝之前元素到新数组
7 哈希表如何解决冲突
链接法和开放寻址法
1 元素key冲突之后使用一个链表填充相同key的元素
2 开放寻址发是冲突之后根据一种方式(二次探查)寻找下一个可用的槽
3 cPython使用的二次探查
8 常考数据结构之二叉树
先序,中序,后序遍历
-
先(根)序:先处理根,之后是左子树,然后是右子树
-
中(根)序:先处理左子树,然后是根,然后是右子树
-
后根序:先处理左子树,然后是右子树,最后是根


9 常考数据结构之堆

使用python的heapq实现堆
import heapq
class Topk:
"""
获取大量元素,topk个大元素,固定内存
思路:
1 先放入元素前k个建立一个最小堆
2 迭代剩余元素
如果当前元素小于堆顶元素,跳过该元素(肯定不是钱k大)
否则替换堆顶元素为当前元素,并重新调整堆
"""
def __init__(self, iterable, k):
self.minheap = []
self.capacity = k
self.iterable = iterable
def push(self, val):
if len(self.minheap) >= self.capacity:
min_val = self.minheap[0]
if val < min_val: # 当然你可以直接if val > min_val操作,这里只是显示指出跳出这个元素
pass
else:
heapq.heapreplace(self.minheap, val) # 返回并且pip堆顶对小值,推入新的val值并调整堆
else:
heapq.heappush(self.minheap, val)
def get_topk(self):
for val in self.iterable:
self.push(val)
return self.minheap
def test():
import random
i = list(range(1000))
print(len(i))
random.shuffle(i)
print(len(i))
# print(i)
_ = Topk(i, 10)
print(_.get_topk())
test()
10 Python白板编程(手写代码)
11 链表
链表涉及到指针操作较为复杂,容易出错,经常用作常考题
- 熟悉链表的定义和常见操作
- 常考题:删除一个链表节点
- 常考题:合并两个有序链表
删除链表中的节点
# https://leetcode-cn.com/problems/delete-node-in-a-linked-list/
class Solution:
def deleteNode(self, node):
"""
:type node: ListNode
:rtype: void Do not return anything, modify node in-place instead.
"""
nextnode = node.next
after_next_node = nextnode.next
node.val = nextnode.val
node.next = after_next_node
合并两个有序链表
# https://leetcode-cn.com/problems/merge-two-sorted-lists/
class Solution:
def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
if not l1: return l2
if not l2: return l1
if l1.val <= l2.val:
l1.next = self.mergeTwoLists(l1.next, l2)
return l1
else:
l2.next = self.mergeTwoLists(l2.next, l1)
return l2
12 Python数据结构常考题之二叉树
- 二叉树的操作很多可以用递归的方式解决
二叉树的镜像
# https://leetcode-cn.com/problems/er-cha-shu-de-jing-xiang-lcof/
class Solution:
def mirrorTree(self, root: TreeNode) -> TreeNode:
if root:
root.left, root.right = root.right, root.left
self.mirrorTree(root.left)
self.mirrorTree(root.right)
return root
二叉树的层序遍历
# https://leetcode-cn.com/problems/binary-tree-level-order-traversal/
class Solution:
def levelOrder(self, root: TreeNode) -> List[List[int]]:
if not root:return []
res=[]
cur_nodes = [root]
next_nodes = []
res.append([i.val for i in cur_nodes])
while cur_nodes or next_nodes:
for node in cur_nodes:
if node.left:
next_nodes.append(node.left)
if node.right:
next_nodes.append(node.right)
if next_nodes:
res.append(
[i.val for i in next_nodes]
)
cur_nodes = next_nodes
next_nodes = []
return res
13 栈和队列
后进先出 vs先进先出
- 熟练掌握用Python的list或者 collections.deque()实现栈和队列
- 常考题:用栈实现队列
- leetcode implement-queue-using-stacks
# https://leetcode-cn.com/problems/implement-queue-using-stacks/
from collections import deque
class Stack:
def __init__(self):
self.items = deque()
def push(self, val):
return self.items.append(val)
def pop(self):
return self.items.pop()
def top(self):
return self.items[-1]
def empty(self):
return len(self.items) == 0
class MyQueue:
def __init__(self):
"""
Initialize your data structure here.
"""
self.s1 = Stack()
self.s2 = Stack()
def push(self, x: int) -> None:
"""
Push element x to the back of queue.
"""
self.s1.push(x)
def pop(self) -> int:
"""
Removes the element from in front of queue and returns that element.
"""
if not self.s2.empty():
return self.s2.pop()
while not self.s1.empty():
val = self.s1.pop()
self.s2.push(val)
return self.s2.pop()
def peek(self) -> int:
"""
Get the front element.
"""
if not self.s2.empty():
return self.s2.top()
while not self.s1.empty():
val = self.s1.pop()
self.s2.push(val)
return self.s2.top()
def empty(self) -> bool:
"""
Returns whether the queue is empty.
"""
return self.s1.empty() and self.s2.empty()
14 数据结构之堆
堆常考题基本围绕在合并多个有序(数组、链表):Topk问题
1 理解堆的概念,堆是完全二叉树,有最大堆和最小堆
2 会使用Python内置的heapq模块实现堆的操作
3 常考题:合并k个有序链表leetcode merge-k-sorted-list
合并K个排序链表
# Definition for singly-linked list.
from heapq import heappop, heapify
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
def mergeKLists(self, lists: ListNode):
h = []
for node in lists:
while node:
h.append(node.val)
node = node.next
if not lists: return
heapify(h)
root = ListNode(heappop(h))
curnode = root
while h:
curnode.next = ListNode(heappop(h))
curnode = curnode.next
return root
15 Python字符串常考算法题
了解常用的字符串操作
1 Python内置了很多字符串操作,比如split,upper,repalce
2 反转一个字符串
3 如何判断一个数字是否是回文数(双端变化法)
# https://leetcode-cn.com/problems/reverse-string/
# 反转字符串
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
# s.reverse()
beg = 0
last = len(s)-1
while beg<last:
s[beg],s[last] = s[last], s[beg]
beg +=1
last -= 1
回文数
# https://leetcode-cn.com/problems/palindrome-number/
class Solution:
def isPalindrome(self, x: int) -> bool:
if x<0:return False
# x = [i for i in str(x)]
x = str(x)
beg,last = 0, len(x) - 1
while beg < last:
if x[beg] != x[last]:
return False
beg += 1
last -=1
return True
16 算法与数据结构练习题:反转链表
# https://leetcode-cn.com/problems/reverse-linked-list/
# Definition for singly-linked list.
# class ListNode(object):
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution(object):
def reverseList(self, head):
"""
:type head: ListNode
:rtype: ListNode
"""
def helper(last,cur):
if cur == None: return cur
next = cur.next
cur.next = last
if next == None:return cur
return helper(cur,next)
return helper(None, head)
第5章 编程范式考察点
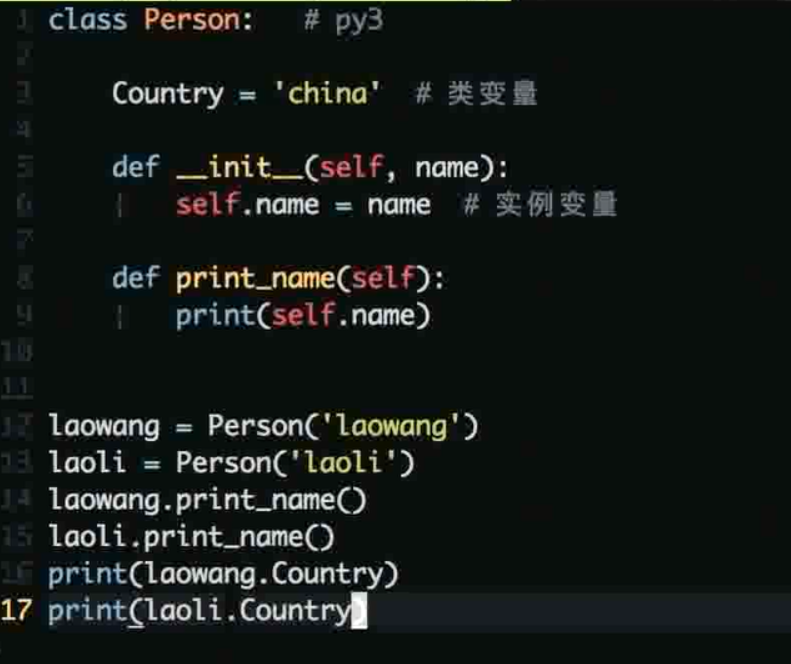
5-1 面向对象基础及Python 类常考问题



之前实现stack/queue就使用到了组合

classmethod/staticmethod区别


type来构建类

编写一个元类
new 生成实例的
init 初始化实例的
class LowercoseMeta(type):
"""修改类的属相名称为小写元素"""
def __new__(mcs, name, bases, attrs):
lower_attrs = {}
for k, v in attrs.items():
if not k.startswith('__'):
lower_attrs[k.lower()] = v
print(k.lower())
else:
lower_attrs[k] = v
return type.__new__(mcs, name, bases, lower_attrs)
class LowercaseClass(metaclass=LowercoseMeta):
BAR = True
def HELLO(self):
print('hello')
print(dir(LowercaseClass))
LowercaseClass().hello()
5-2 装饰器面试常考问题
我们再开发过程中,就尽量遵循开放封闭原则,说白了就是对扩展开放,对修改封闭
装饰器就是在不改变原来代码的前提下,对方法进行增加功能
Decorator
- Python中一切皆对象,函数中也可以当做参数传递
- 装饰器是接受函数作为参数,添加功能后返回一个新函数的函数(类)
- Python中通过@使用装饰器
编写方法装饰器
import time
def log_time(func):
def _log(*args, **kwargs):
beg = time.time()
res = func(*args, **kwargs)
print('use time: {}'.format(time.time() - beg))
return res
return _log
@log_time
def my_sleep():
time.sleep(2)
my_sleep()
编写类装饰器
mport time
class LogTime:
def __init__(self,use_int = False):
self.use_int = use_int
def __call__(self, func):
def _log(*args, **kwargs):
beg = time.time()
res = func(*args, **kwargs)
print('use time: {}'.format(time.time() - beg))
return res
return _log
@LogTime() # 可以给装饰器携带参数
def my_sleep():
time.sleep(1)
my_sleep()
5-3 设计模式
设计模式,动态语言说的少,一般像Java中有创建型,结构型,行为型
创建型模式Python应用面试题
常见创建型设计模式
- 工厂模式(factory):解决对象创建问题
- 构造模式(Builder):控制复杂对象的创建
- 原型模式(Prototype):通过原型的克隆创建信的实例
- 单例模式(Borg/Singleton):一个类智能创建同一个对象
- 对象池模式(Pool):预先分分配同一类型的一组实例
- 惰性计算模式(Lazy Evaluation):延迟计算(Python的property)
工厂模式
1 解决对象创建问题
2 解耦对象的创建和使用
3 包括工厂方法和抽象工厂
class DogToy:
def speak(self):
print('wang wang')
class CatToy:
def speak(self):
print('mao mao')
def toy_factory(toy_type):
if toy_type == 'dog':
return DogToy()
elif toy_type == 'cat':
return CatToy()
构造模式
- 用来控制复杂对象的构造
- 创建和表示分离。比如你要买的电脑,工厂模式直接给你需要的电脑
- 但是构造模式允许你自己定义电脑的配置,组装完后给你
原型模式(prototype)
- 通过克隆原型类创建新的实例
- 可以使用相同的原型,通过修改部分属性来创建新的实例
- 用途:对于一些创建实例开销比较高的地方可以用原型模式
单例模式
单例模式的实现有多种方式
- 单例模式:一个类创建出来的对象都是同一个
- Python的模块其实就是单利的,只会导入一次
- 使用共享同一个实例的方式来创建单例模式
5-4 设计模式:结构型模式Python应用面试题
5-6 Python 函数式编程常考题
-
把电脑的运算视为数据上的函数计算(lambda 演算)
-
高阶函数 .map/reduce/filter
-
无副作用,相同的参数调用始终产生相同的结果
# 1 map
l = list(map(lambda x: x * 2, range(10)))
print(l)
# 但是在编程中我们不这样用,一般使用列表推导式
l = [i * 2 for i in range(10)]
print(l)
# reduce # 对序列元素做运算,每一次的结果作为下一次运算的第一个值
from functools import reduce
r = reduce(lambda x, y: x + y, range(1, 6))
print(r)
# filter #对序列过滤
f = list(filter(lambda x: x % 2 == 0, range(10)))
print(f)
什么是闭包
closure
- 绑定了外部作用域的变量的函数
- 及时程序离开外部作用域,如果闭包依然可见,绑定变量不会销毁
- 每次运行外部函数都会重新创建闭包
from functools import wraps
def cache(func):
store = {}
@wraps(func)
def _(n):
if n in store:
return store[n]
else:
res = func(n)
store[n] = res
return res
return _
@cache
def f(n):
if n <= 1:
return 1
return f(n - 1) + f(n - 2)
print(f(10))
闭包:引用了外部自由变量的函数
自由变量:不在当前函数定义的变量
特性:自由变量会和闭包函数同时存在
第6章 操作系统考察点
6-1 面试常考 linux 命令
早期的一些公司采用的是LAMP/LNMP架构
# LAMP & LNMP
linux+Apache(Nginx)+MySql+Php/Python
如何查询Linux命令的用法
- 使用man命令查询用啊,但是man手册比较晦涩
- 使用工具自带的help,比如pip --help
- 这里介绍一个man的替代工具tldr,pip install tldr
常见的文件操作工具
1 chown/chmod/chgrp
2 ls/rm/cd/cp/mv/touch/rename/ln(软连接和硬链接)等
3 locate/find/grep定位查找和搜索
# find .-name '*.pyc' -delete
文件或者日志查看工具
1 编辑器 vi/nano/vim
2 cat/head/tail 查看文件
3 more/less 交互式查看文件
常见的进程操作工具
1 ps查看进程
2 kill杀死进程
3 top/htop监控进程
# kill执行的原理是什么
常见的网络工具
1. ifconfig 查看网卡信息
2. lsof/netstat 查看端口信息
3. ssh/scp远程登录/复制。 tcpdump抓包
常见的用户和组操作
1. useradd/usermod
2. groupadd/groupmod
参考
学习linux命令
1. man命令可以查询用法。或者cmd --help
2. 《鸟哥的linux私房菜》,学习简单的shell脚本知识
3. 多用才能多
6-2 操作系统线程和进程常考面试题
进程和线程的区别
1. 进程是对运行时程序的封装,是系统资源调度和分配的基本单位
2. 线程是进程的子任务,cpu调度和分配的基本单位,实现进程内并发
3. 一个进程可以包含多个线程,线程依赖进程存在,并共享进程内存
什么是线程安全
1. 一个操作可以在多线程环境中安全使用,获取正确的结果
2. 线程安全的操作好比线程是顺序执行而不是并发执行的(1 += 1)
3. 一般如果涉及到写操作需要考虑如何让多个线程安全访问数据
线程同步的方式
1. 互斥量(锁) :通过互斥机制防止多个线程同时访问公共资源
2. 信号量(Semphare):控制同一时刻多个线程访问同一个资源的线程数
3. 事件(信号) :通过通知的方式保持多个线程同步
进程间通信的方式
进程间传递信号或者数据
1. 管道/匿名管道/有名管道(pipe)
2. 信号(Singal):比如用户使用Ctrl+C产生SIGINT程序终止信号
3. 消息队列(Message)
4. 共享内存
5. 信号量
6. 套接字(socket):最常用的方式,我们web应用都是这种方式
Python中如何去使用多线程
threading模块
1. threading.Thread类用来创建线程
2. start() 方法启动线程
3. 可以用jion()等待线程结束
import threading
Lock = threading.Lock()
n = [0]
def foo():
with Lock: # 加一个线程锁
n[0] = n[0] + 1
n[0] = n[0] + 1
threads = []
for i in range(500000):
t = threading.Thread(target=foo)
threads.append(t)
for t in threads:
t.start()
print(n)
Python中如何使用多进程
Python有GIL,可以用多进程实现cpu密集程序
1. multiprocessing 多进程模块
2. Multiprocessing.Process类实现多进程
3. 一般用在cpu密集程序里,避免GIL的影响
# 使用多进程实现斐波那契数列
from multiprocessing import Process
def fib(n):
if n <= 1:
return 1
return fib(n - 1) + fib(n - 2)
if __name__ == '__main__':
jobs = []
for i in range(10, 20):
p = Process(target=fib, args=(i,))
jobs.append(p)
p.start()
print(jobs)
6-3 操作系统内存管理机制与Python垃圾回收面试题
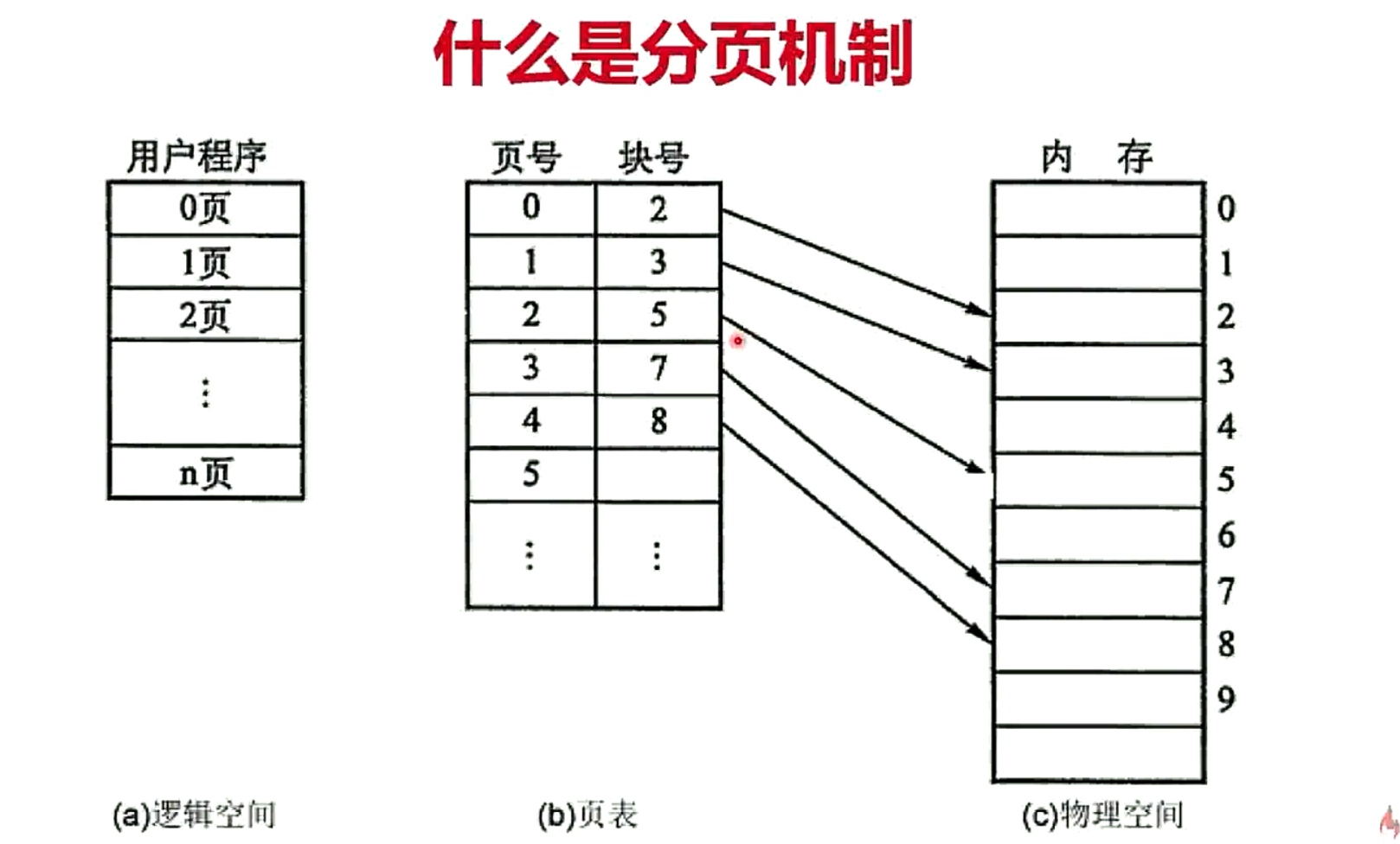
分页机制
逻辑地址和物理地址分离的内存分配管理方案
1. 程序的逻辑地址划分为固定大小的页
2. 物理地址划分为同样大小的帧
3. 通过也表对应逻辑地址和物理地址
第7章 网络编程考察点
7-1 网络协议TCP和UDP面试常考题
互联网协议--TCP/IP五层
应用层--> 网络传输层 --> 网络层 --> 数据链路层 -->物理层
网络传输层 :TCP/IP协议
网络层 : IP协议
数据链路层 : arp协议
- 物理层:物理连接介质,传递电信号
- 数据链路层:必须有网卡,接受一串长二进制数据
- 网络层:规定每一个计算机都要有一个ip地址,ip协议可以跨局域网传输并且ip地址能够唯一标识互联网中第一无二的一台计算机
- 网络传输层:TCP/IP协议都是基于端口工作的,想要进行通信是应用程序之间的通信,ip表示一台第一无二的计算机,port标识一台机器上的一个应用程序,ip+port就能够找到世界上独一无二的一个应用程序,然后就可以进行程序和程序之间的数据传输
TCP协议: 当应用程序想通过TCP协议进行远程通信的时候,彼此之间应该先简历双向通信,基于该双向通道实现数据的远程交互,双向通道知道任意一方主动断开才会失效
三次握手: 建立双向通道的过程我们叫做三次握手,一:客---->服发询问能不能建立连接,二:服---->客好吧,我也要问你能不能建立连接,三:客---->服谢谢合作,发送数据
四次握手:建立连接需要三次握手,终止连接需要四次挥手 一:客---->服,发起断开连接请求,二:服---->客:收到请求同意,客户端向服务端的请求断开 三:服---->客 检查还有没有发往客户端的数据,有的话继续发数据,没有的话请求断开连接 四:客---->服 同意该请求,断开连接,四次挥手完成
UDP协议:当应用程序希望通过UDP协议进行通信的时候,通信多方不建立连接,类似于广播,想要数据的时候去网络中抓取就好了
TCP和UDP类似于: TCP:打电话(你一句,我一句)
UDP: 发短信(我反正发了,不管你看不看)
TCP ---传输控制协议,提供的是面向连接,可靠的字节流服务,当客户端和服务器彼此交易交换数据前,必须在双方之间建立一个TCP连接,之后才能进行数据传输,TCP提供超时重发,丢弃重复数据,流量控制等功能,保证数据能从从一端传到另一端
UDP---用户数据报协议,是一个简单的面向数据报的运输层协议,因为不用建立连接,所以传输速度很快
- 应用层:http协议,ftp协议
从浏览器输入一个url中间经历的过程
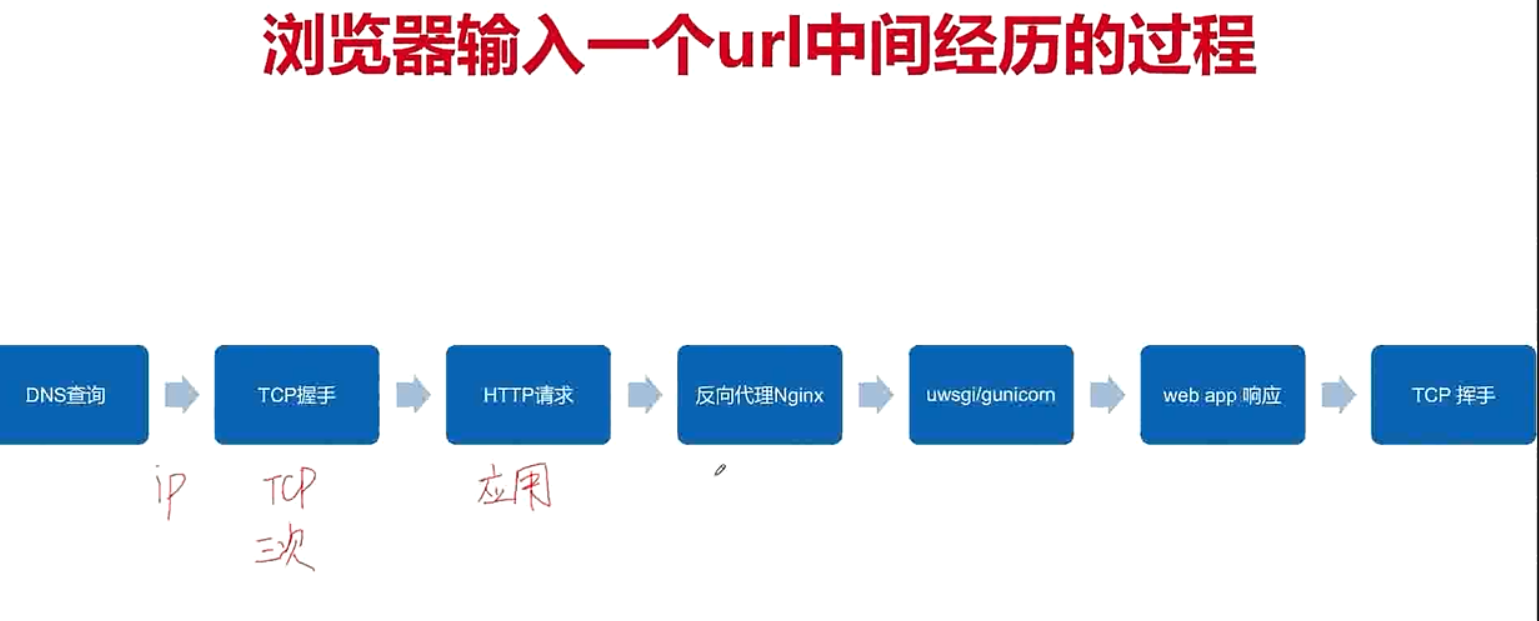
1. 中间涉及到了哪些过程
2. 包含了哪些协议
3. 每个协议都干了什么
先去看有没有dns缓存,不在dns缓存里,而且hosts中也没有的话,就会向本地的dns服务器发起查询,就会把域名对应的ip地址返回给我们
拿过ip地址之后,浏览器就会发送socket请求,通过TCP的三次握手与服务器建立连接
接下来就发起应用层的http请求
然后使用nginx作为反向代理将请求返回到服务器上
在服务器上,uwsgi服务的应用,将请求转发到web应用层,比如flask,django
web app响应之后,对数据库的增删查改
最后将响应发给客户端,完成挥手
TCP和UDP的区别
1. tcp是面向连接的,可靠的,基于字节流的
2. UDP是无连接的,不可靠,面向报文的
7-2 HTTP 面试常考题
HTTP协议简介
HTTP协议是超文本传输协议,是用于万维网服务器和本地浏览器之间传输超文本的传送协议
HTTP是一个属于应用层的面向对象的协议
HTTP协议的特性
1 基于TCP/IP协议之上的应用层协议
2 基于请求,响应模式的,请求客户端发出,达到服务端后返回响应
3 无状态保存,自身不对请求和响应的通信状态进行保存,所以诞生了cookie和session
4 无连接,限制每次连接只处理一个请求,收到客户端的应答之后就断开连接
HTTP请求的组成
1 状态行
2 请求头
3 消息主体
我们想要通过命令行来解析http请求过程
# linux环境中
pip install httpie
# 查看请求参数
http baidu.com
# 查看完整的请求
http -v baidu.com
[root@ouyang ~]# http -v baidu.com
GET / HTTP/1.1 # 请求的方法/路径/http版本
# 下面几行就是http的请求头
Accept: */*
Accept-Encoding: gzip, deflate
Connection: keep-alive # 长连接
Host: baidu.com #域名
User-Agent: HTTPie/2.1.0 # 请求的代理是HTTPie
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: max-age=86400
Connection: Keep-Alive
Content-Length: 81
Content-Type: text/html
Date: Tue, 02 Jun 2020 14:14:27 GMT
ETag: "51-47cf7e6ee8400"
Expires: Wed, 03 Jun 2020 14:14:27 GMT
Last-Modified: Tue, 12 Jan 2010 13:48:00 GMT
Server: Apache
<html>
<meta http-equiv="refresh" content="0;url=http://www.baidu.com/">
</html>
HTTP的响应有哪些构成呢
-状态行
- 响应头
-响应正文
HTTP常见状态码
# 1**信息
服务器收到请求,需要请求者继续执行操作
# 2**成功
操作被成功接收并处理
# 3** 重定向
需要进一步操作完成请求(301永久重定向,302临时重定向)
# 4**客户端错误
请求中有语法错误或者无法完成请求
400错误的请求
401没有权限
402参数错误
403禁止访问
404没有找到
405 方法不被允许
# 5**服务器错误
500 服务器错误
服务器在处理请求过程中发生错误
常见的HTTP请求的方法 GET/POST/PUT/DELETE
HTTP GET/POST区别
- Restful语义上一个是获取,一个是创建
- GET是幂等的,POST非幂等
- GET请求参数放到url(明文),有一定的长度限制; POST放在请求体重,更安全
幂等性
什么事幂等?哪些HTTP方法是幂等的
- 幂等方法是无论调用多少次都得到相同结果的HTTP方法
- 例如: a = 4 是幂等的,但是 a += 4 就是非幂等的
- 幂等的方法客户端可以安全的重发请求

什么是HTTP的长连接
HTTP是一个应用层的协议,还是要遵循TCP协议的
我们都知道,在TCP的三次握手和四次挥手的过程中,时会产生大量的请求的,我们将多次的请求参数打包到一个HTTP请求中,就是HTTP的长连接
# 短连接
建立连接-->数据传输-->关闭连接(连接的建立和关闭开销大)
# 长连接
保持TCP连接不断开,就是我们打开调试的时候的Connection:keep-alive
# 如何区分不同的HTTP请求呢? Content-length|Transfer-Encoding:chunked
cookie和session的区别
HTTP是无状态的,如何标识用户呢?
- Session一般是服务器生成之后给客户端(通过url参数或者cookie)
- Cookie是实现session的一种机制,通过HTTP cookie字段实现
- Session通过在服务器保存sessionid识别用户,cookie存储在客户端
7-3 网络编程常考题
TCP/UDP socket编程;HTTP编程
Socket
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,他是一组简单的接口,在设计模式中,Socket其实就是一个门面模式,它把复杂的TCp/IP协议隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,已符合指定的协议
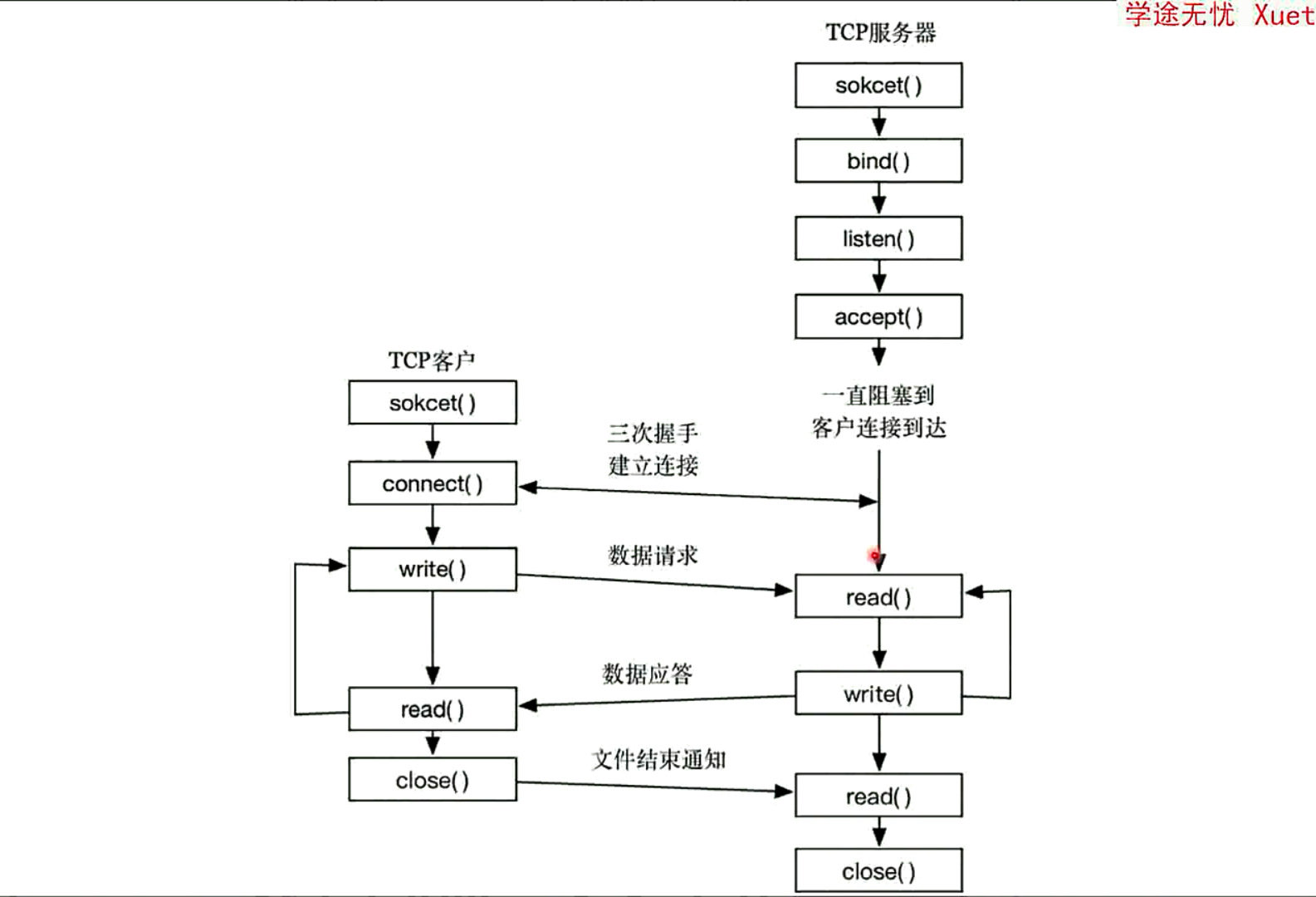
一个简单的socket客户端和服务端交互demo
# tpc_client.py
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(('127.0.0.1', 8888))
s.sendall(b'hello world')
data = s.recv(1024)
print(data.decode())
s.close()
# tpc_server.py
import socket
import time
s = socket.socket()
s.bind(('', 8888))
s.listen()
while True:
print('服务端执行')
client, addr = s.accept() # return conn,addr
print(client)
# timestr = time.ctime(time.time()) + '\r\n'
timestr = time.strftime('%Y-%m-%d %X', time.localtime())
client.send(timestr.encode()) # send 参数 encode('utf-98')
client.close()
使用socket发送HTTP请求
1 使用socket接口发送HTTP请求
2 HTTP建立在TCP基础之上
3 HTTP是基于文本的协议
import socket
s = socket.socket()
s.connect(('www.baidu.com', 80))
http = b"GET / HTTP/1.1\r\nhost: www.baidu.com\r\n\r\n"
s.sendall(http)
buf = s.recv(1024)
print(buf)
s.close()
7-4 并发编程IO多路复用常见考题
五种IO模型
1 阻塞IO 2 非阻塞IO 3 IO多路复用 4 信号驱动的IO 5 异步IO
一般我们使用IO多路复用来实现我们的并发编程
如何提升服务器的并发能力呢?
1 多线程模型,创建新的线程处理请求--IO密集型
2 多进程模型,创建新的进程处理请求--CPU密集型
问题就是线程/进程创建开销比较大,可以用线程池方式解决
线程和进程比较占用资源,难以同时创建太多
所以现在我们很多服务器都是使用IO多路复用来实现单进程同时处理多个socket请求
什么是IO多路复用
操作系统提供的同时监听多个socket的机制
单个进程同时处理多个网络IO
- 为了实现高并发需要一种极致并发处理多个socket
- Linux常见的是select/poll/epoll
- 可以使用单线程但进程处理多个socket
# IO多路复用的过程
1 内核等待数据
2 IO多路复用可以同时监听多个socket,一旦发现有数据过来就发送socket可读,所以效率比较高
阻塞式IO
# 两个过程
1 内核等待数据
2 数据从内核拷贝到用户进程
在阻塞式IO中,当两个过程都完成后,用户才能拿到结果数据
因为一次只能处理一个请求,所以效率比较低

Python如何实现IO多路复用
1 Python的IO多路复用基于操作系统实现(select/poll/epoll)
2 Python3 select 模块
3 Python3 selectors 模块
Python3 中的selectors代码示例
# IO多路复用server.py
from socket import *
import selectors
sel = selectors.DefaultSelector()
def accept(server_fileobj, mask):
conn, addr = server_fileobj.accept()
sel.register(conn, selectors.EVENT_READ, read)
def read(conn, mask):
try:
data = conn.recv(1024)
if not data:
print('closing', conn)
sel.unregister(conn)
conn.close()
return
conn.send(data.upper() + b'_SB')
except Exception:
print('closing', conn)
sel.unregister(conn)
conn.close()
server_fileobj = socket(AF_INET, SOCK_STREAM)
server_fileobj.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server_fileobj.bind(('127.0.0.1', 8088))
server_fileobj.listen(5)
server_fileobj.setblocking(False) # 设置socket的接口为非阻塞
sel.register(server_fileobj, selectors.EVENT_READ,
accept) # 相当于网select的读列表里append了一个文件句柄server_fileobj,并且绑定了一个回调函数accept
while True:
events = sel.select() # 检测所有的fileobj,是否有完成wait data的
for sel_obj, mask in events:
callback = sel_obj.data # callback=accpet
callback(sel_obj.fileobj, mask) # accpet(server_fileobj,1)
# IO多路复用client.py
from socket import *
c=socket(AF_INET,SOCK_STREAM)
c.connect(('127.0.0.1',8088))
while True:
msg=input('>>: ')
if not msg:continue
c.send(msg.encode('utf-8'))
data=c.recv(1024)
print(data.decode('utf-8'))
7-5 Python并发网络库常考题
用过哪些并发网络库?
Tornado
Tornado--并发网络库和同时也是web微框架
Gevent--Gevent绿色线程(greenlet)实现并发,猴子补丁修改内置socket
Asyncio--Python3内置的并发网络库,基于原生协程
Tornado框架
Tornado适用于微服务,实现Restful接口
1 底层基于Linux多路复用
2 可以通过协程或者回调实现异步编程
3 不过生态不完善,相应的一步框架比如ORM不完善
import tornado.ioloop
import tornado.web
from tornado.httpclient import AsyncHTTPClient
class APIHandler(tornado.web.RequestHandler):
async def get(self):
url = 'http://httpbin.org/get'
http_client = AsyncHTTPClient()
resp = http_client.fetch(url)
print(resp.body)
return resp.body
def make_app():
return tornado.web.Application([
(r"/api", APIHandler)
])
if __name__ == '__main__':
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
Gevent
高性能的并发网络库
1 基于清凉价绿色(greenlet)实现并发
2 需要注意 monkey patch,gevent修改了内置的socket改为非阻塞
3 配个gunicorn和gevent部署是作为wusgi server
#example
import gevent.monkey
gevent.monkey.patch_all()
import gevent
import requests
def fatch(i):
url = 'http://httpbin.org/get'
resp = requests.get(url)
print(len(resp.text), i)
def asynchronous():
threads = []
for i in range(1, 10):
threads.append(gevent.spawn(fatch, i))
gevent.joinall(threads)
print('Asynchronous:')
asynchronous()
Asyncio
基于协程实现的内置并发网络库
1 Python3引入到内置库,协程+事件循环
2 生态不够完善,没有大规模生产环境检验
3 目前应用不够广泛,基于Aiohttp可以实现一些小的服务
# example
import asyncio
from aiohttp import ClientSession
async def fetch(url, session):
async with session.get(url) as response:
return await response.read()
async def run(r=10):
url = 'http://httpbin.org/get'
tasks = []
async with ClientSession() as session:
for i in range(r):
task = asyncio.ensure_future(fetch(url, session))
tasks.append(task)
response = await asyncio.gather(*tasks)
for resp_body in response:
print(len(resp_body))
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(run())
loop.run_until_complete(future)
第8章 数据库考察点
8-1 Mysql基础常考题
- 事务的原理,特性,事务并发控制
- 常用的字段,含义和区别
- 常用数据库引擎之间的区别
什么是事务
1 事务是数据库并发控制的基本单位
2 事务可以看做是一系列SQL语句的集合
3 事务必须是要么全部执行成功,要么全部执行失败(回滚)
下面是一个sqlalchemy的回滚的操作

事务的ACID特性
ACID是事务的四个基本特性
- 原子性(Atomicity): 一个事物中所有操作全部完成或失败
- 一致性(Consistency):事务开始和结束之后数据完整性没有被破坏
- 隔离性(Isolation):允许多个事务同时对数据库修改和读写
- 持久性(Durability):事务结束后,修改是永久的不会丢失
事务并发控制可能产生哪些问题
如果不对事务进行控制,可能会产生四种异常情况
- 幻读(phantom read):一个事物第二次查出现第一次没有的结果
- 非重复读(nonrepeatable read):一个事务重复度两次得到不同的结果
- 脏读(dirty read):一个事物读到另一个事物没有提交的修改
- 修改对视(lost update):并发写入造成其中一些写入丢失
四种事务的隔离级别
- 读未提交:别的事务可以读取到为提交修改
- 读已提交:只能读取已经提交的事务
- 可重复度:同一个事务先后查询后结果是一样的
- 串行化:事务完全串行化,隔离级别最高,执行效率最低
如何解决高并发场景下的插入重复
高并发场景下,写入数据库会有数据重复问题
- 使用数据库的唯一索引
- 使用队列异步写入
- 使用redis等实现分布式锁
乐观锁和悲观锁
什么是乐观锁,什么是悲观锁?
- 悲观锁是先获取锁再进行操作,一锁二查三更新,select for update
- 乐观锁先修改,更新的时候发现数据已经变了就回滚
- 使需要根据响应速度,冲突频率,充实代价来判断使用哪一种
InnoDB vs MySIAM
两种引擎常见的区别
- MyISAM不支持事务,Innodb支持事务
- MyISAM不支持外键,InnoDB支持外键
- MySIAM只支持表锁,Innodb支持行锁和表锁
- MySIAM支持全文索引,但是InnoDB不支持全文索引
8-2 Mysql索引优化常考面试题
Mysql索引
- 索引的原理,类型,结构
- 创建索引的注意事项,使用原则
- 如何排查和消除慢查询
为什么需要索引?
- 索引就是数据表中一个或者多个列进行排序的数据结构
- 索引能能够大幅度的提升检索速度
- 创建,更新索引本身也会耗费空间和时间
MySQL索引的数据结构是B-Tree(B加树)
什么是B-Tree?
m阶的多路平衡查找树
1 多路平衡查找树(每个节点最多m(m>=2)个孩子,成为m阶或者度)
2 叶节点具有相同的深度
3 节点中的数据key从左到右是递增的
查找结构进化史
线性查找:
一个个查找;实现简单,缺点是速度慢
二分查找:
有序;简单;要求是有序的,插入特别慢
HASH:
查询快;占用空间;不太适合存储大规模数据
二叉查找树:
插入和查询很快(log(n));无法存储大规模数据,复杂度退化
平衡树:
解决bsi退化的问题,树是平衡的;节点非常多的时候,依然书高很高
多路查找树:
一个父亲多个孩子吉尔碘(度),节点过多书高不会特别深
多路平衡查找树
B-Tree
B+Tree
B+Tree是B-Tree的变形
- Mysql实际使用B+tree作为索引的数据结构
- 只有叶子节点带有指向记录的指针
- 叶子结点通过指针相连。为什么?实现范围查找
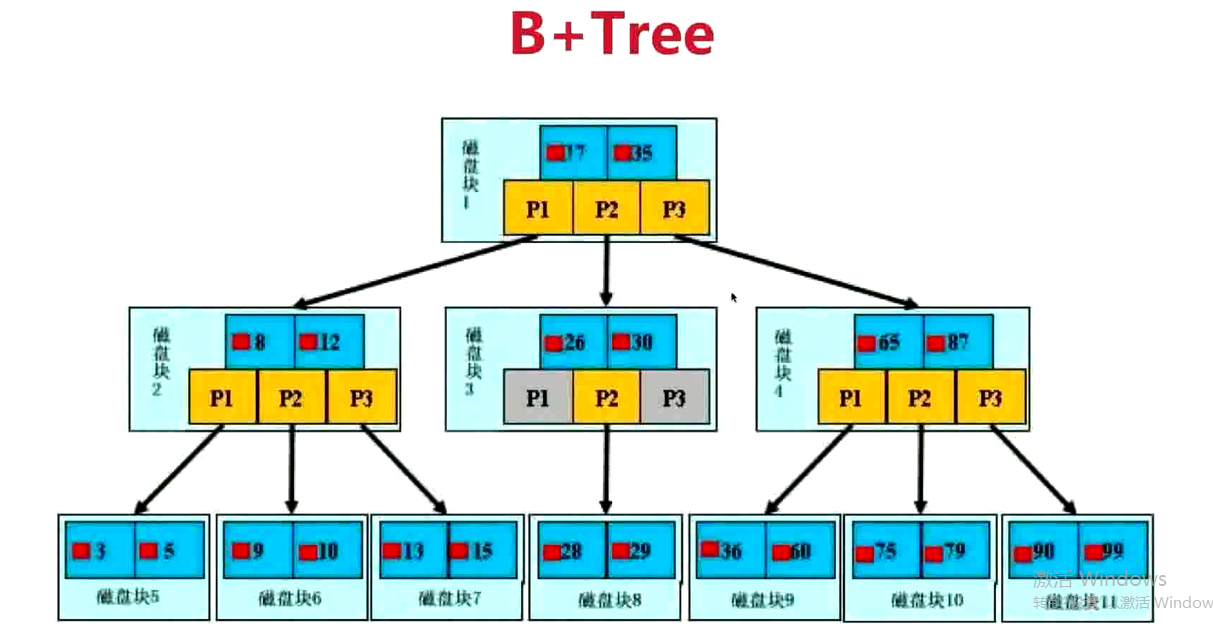
Mysql索引的类型
Mysql创建索引
- 普通索引(CREATE INDEX)
- 唯一索引,索引列的值必须唯一(CREATE UNIQUE INDEX)
- 多列索引
- 主键索引(PRIMARY KEY),一个表只能有一个
- 全文索引(FULLTEXT INDEX), InnoDB不支持
什么时候创建索引?
建表的时候根据查询需求来创建索引
- 经常用作查询条件的字段(WHERE 条件)、
- 经常用作表连接的字段
- 经常出现在group by,order by 之后的字段
创建索引有哪些需要注意的?
最佳实战
- 非空字段 NOT NULL,Mysql 很难对空值做查询优化
- 区分度高,离散度大,作为索引的字段尽量不要有大量相同值
- 索引的长度不要太长(比较耗费时间)
索引什么时候会失效
记忆口诀: 模糊匹配,类型隐转,最左匹配
- 已%开头的LIKE语句,模糊搜索
- 出现隐式类型转换(在Python这种动态语言中需要注意)
- 没有满足最左前缀原则(想先为什么是最左匹配)
聚集索引和辅助索引
区别是在B+Tree的叶节点存储数据还是指针
MyISAM索引是非聚集的,InnoDB逐渐索引是聚集索引
如何排查慢查询
慢查询通常是缺少索引,索引不合理或者业务代码实现导致
- slow_query_log_file开启并且查询慢查询日志
- 通过explain排查索引问题
- 调整数据修改索引;业务代码层限制不合理访问
8-3 SQL语句编写常考题
SQL语句以考察各种常用链接为重点
- 内连接(Inner join) :两个表都存在匹配时,才会返回匹配行
- 外连接(left。right join):返回一个表的行,及时另一个没有匹配
- 全连接(FULL JOIN):只要某一个表存在匹配就返回

内连接
1 将左表和右表能够关联起来的数据连接后返回
2 类似于求两个表的 “交集”
3 select * from A inner join B on a.id=b.id
select a.id as a_id,b.id as b_id,a.val as a_val, b.val as b_id from a INNER JOIN b WHERE a.id=b.id;
外连接
# 外连接包含左连接和有链接
1 左连接返回左标中的记录,即使右表中没有匹配的数据
2 右连接返回右表中的记录,即使左表中没有匹配的记录
3 没有匹配的字段会设置成NULL
mysql中用left join 和 right join 实现左连接和右连接
# 左连接实现
select a.id as a_id,b.id as b_id,a.val as a_val, b.val as b_id from a left JOIN b on a.id=b.id;
# 右连接实现
select a.id as a_id,b.id as b_id,a.val as a_val, b.val as b_id from a right JOIN b on a.id=b.id;
8-4 缓存机制及Redis常考面试题
缓存的使用场景,redis的使用,缓存使用中的坑
question
1 为什么要使用缓存?使用场景
2 Redis的常用数据类型,使用方式
3 缓存问题:数据一致性问题;缓存穿透、击穿、雪崩问题
什么是缓存?为什么要使用缓存?
- 缓解关系型数据库(常见的是Mysql)并发访问的压力:热点数据
- 减少响应时间:内存IO速度比磁盘块
- 提升吞吐量:Redis等内存数据库单机就可以职称很大的并发
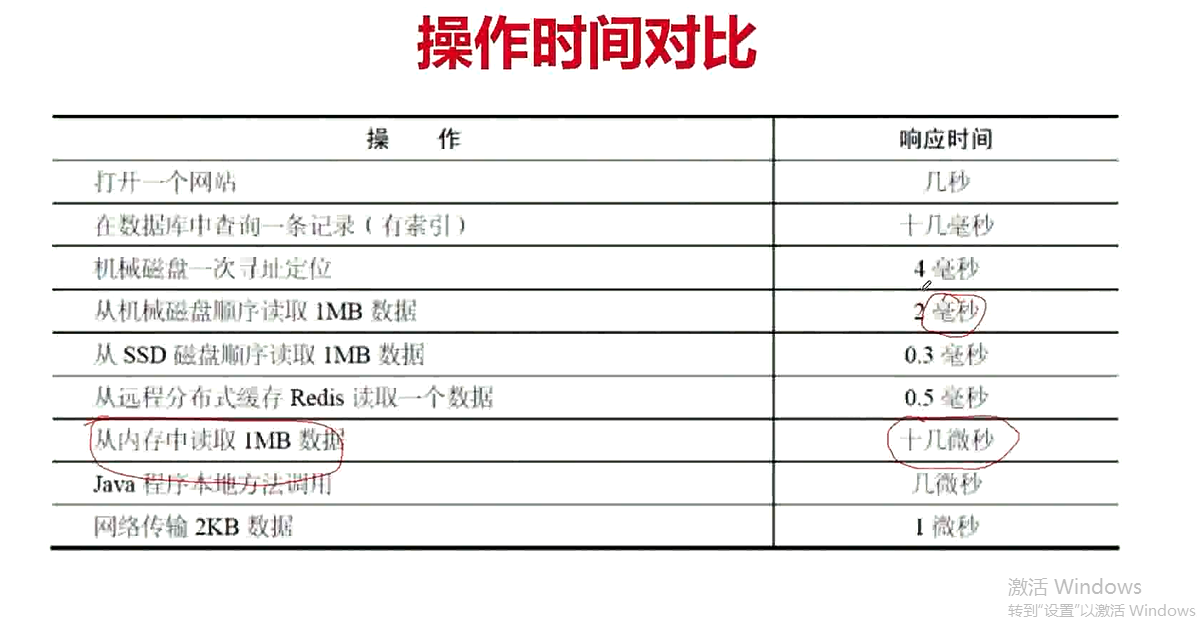
Redis和Memcached的区别
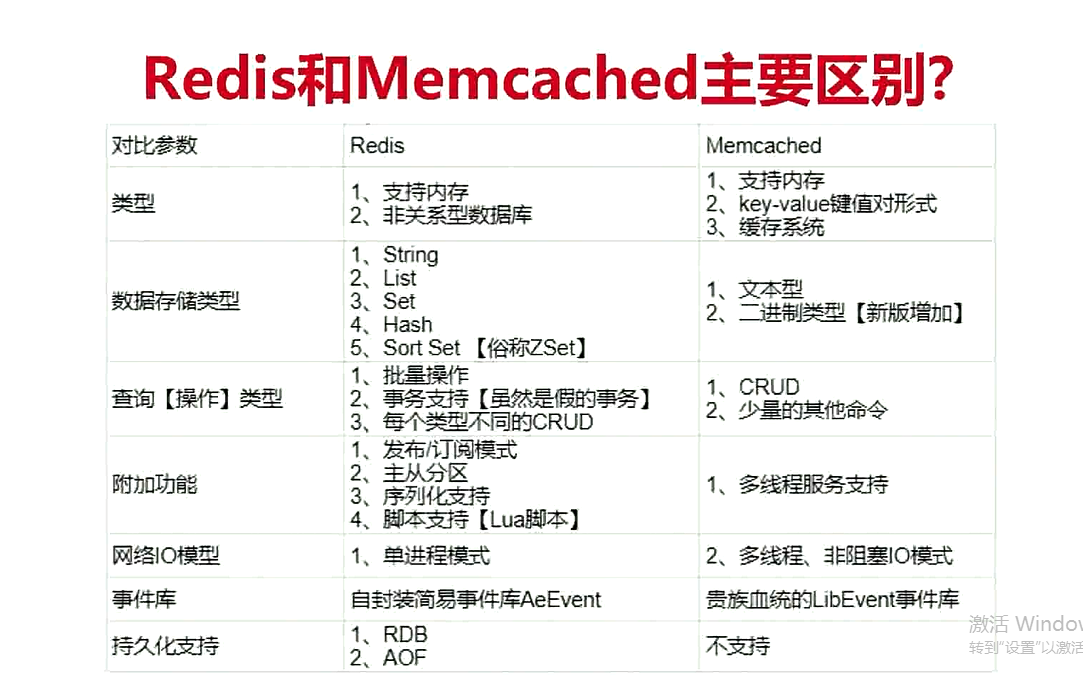
请简述Redis常用数据类型和使用场景
- String(字符串):用来实现简单的kv键值对存储,比如计数器
- List(链表):实现双向链表,比如用户的关注,粉丝列表
- Hash(哈希表):用来存储彼此相关信息的键值对
- Set(集合):存储不重复元素,比如用户的关注着
- Sorted Set(有序集合):实时信息排行榜
Redis内置实现
对于中高级工程师,需要了解Redis各种类型的C底层实现方式
- String: 整数或者sds (Simple Dynamic String)
- List: ziplist或者double linked list
ziplist:通过一个连续的内存块实现list结构,其中的每个entry节点头部保存前后节点长度信息,实现双向链表功能
- Hash: ziplist或者hashtable
- Set: intset 或者hashtable
- SortedSet: skiplist 跳跃表
- 深入学习请参考:《Redis 设计与实现》
Redis实现的跳跃表是什么结构
Sorted Set为了简化实现,使用skiplist而不是平衡树实现
类似于二分查找
Redis有哪些持久化方式?
Redis支持两种方式实现持久化
- 快照方式:把是数据快照及快照放在私盘二进制文件中,dump.rdb
- AOF(Append Only File):每一个些命令追加到aooendonly.aof中
- 可以通过修改Redis修改
什么是Redis事务
和mysql事务有什么不同呢?
- 将多个请求打包,一次性,按序执行多个命令的机制
- Redis通过MULTI,EXEC,WATCH等命令实现事务功能
- Python redis-py poipeline = conn,pipeline(trabsaction=True)
Redis如何实现分布式锁?
就是设置一个key,value,一个操作的时候,就去生成一个锁,其他线程判断有这个key,value的时候,就会等待或者重试
等该线程处理完,就删除这个key,value,其他线程处理的时候就会重复上述过程
- 使用sernx实现加锁,可以同时通过expire添加超时时间
- 锁的value值可以使用一个随机的uuid或者特定的命名
- 释放锁的时候,通过uuid判断是否是该锁,是则执行delete释放锁
使用缓存的模式?
常用的缓存使用模式
- Cache Aside:同时更新缓存和数据库
- Read/Write Through:先更新缓存,缓存负责同步更新数据库
- Write Behind Caching:先更新缓存,缓存定期异步更新数据库
数据库和缓存之间的数据一致性
先跟新数据库后更新缓存,并发写操作肯呢个会导致缓存读取的是脏数据
一般先更新数据库,然后删除缓存
如何解决缓存穿透问题
大量查询不到的数据请求落到后端数据库,数据库压力增大、
- 由于大量缓存查不到就去数据库取,数据库也没有要查的数据
- 解决:对于没查到返回为None的数据也缓存
- 插入数据的时候删除相应的缓存,或者设置较短的超时时间
如何解决缓存击穿问题
某些非常热点的数据key过期,大量请求打到后端数据库
- 热点数据keyu失效导致大量请求打到数据库增加数据库压力
- 分布式锁:获取锁的线程从数据库拉数据更新缓存,其他线程等待
- 异步后台更新:后台任务针对过期的key自动更新
如何解决缓存雪崩问题
- 多级缓存:不同几倍的key设置不同的超时时间
- 随机超时:key的差事时间随机设置,防止同时超时
- 架构层:t提升系统的可用性。监控,报警完善
Mysql思考题(待回答)
- 为什么Mysql数据库的主键使用自增的整数比较好
- 使用uuid可以吗?为什么?
- 如果是分布式系统下我们怎么生成数据库的自增id呢?
Redis应用-分布式锁
Redis的应用之一:实现分布式锁
- 基于Redis编写代码实现一个简单的分布式锁
- 要求:支持超时时间参数
- 深入思考:如果Redis单个节点宕机了,如何处理,还有其他的方案实现分布式锁么?
第9章 Python Web 框架考察点
9-1 Python WSGI与web框架常考点
什么是WSGI?
- Python Web Server Gateway Interface(pep3333) -- Python web 服务器网关接口
- 解决Python Web Server 乱象 mod_pytohn,CGI,FastCGI
- 描述了Web Server (Gunicorn/uWSGI)如何与web框架(Flask/Django交互),web框架如何处理请求

手写一个web框架
# 导入内置的WSGI server
from wsgiref.simple_server import make_server
def application(environ, start_response):
print(environ)
status = '200 OK'
headers = [('Content-Type', 'text/html; charset=utf8')]
start_response(status, headers)
return [b'<h1> hello world!!!</h1>']
if __name__ == '__main__':
httpd = make_server('127.0.0.1', 8888, application)
httpd.serve_forever()
常用的Python Web框架对比
Django vs Flask vs Tornado
- Django: 大而全,内置ORM,Admin等组件,第三方插件比较多
- Flaks:微框架,插件机制,比较灵活
- Tornado:异步支持的为框架爱和异步网络库
cookiecutter-flask :统一生成项目模板
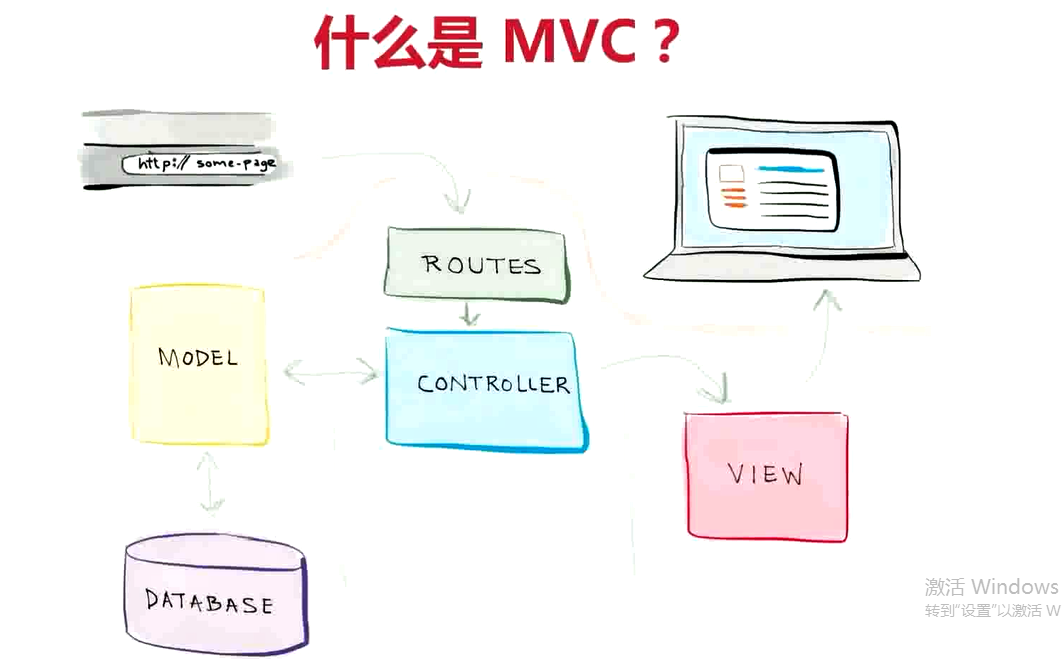
什么是MVC?
MVC: 模型(Model),视图(View), 控制器(Controller)
及饿哦数据,展示,操作
- Model:负责业务对象和数据库的交货
- View:负责与用户的交互展示
- controller:接收请求参数调用模型和试图完成请求
什么是ORM
Object Relational Mapping:对象关系映射
- 用于实现业务对象与数据表中的字段映射
- 优势:代码更加的面向对象,代码量更少,灵活性高,提升开发效率
9-2 web安全常考点
常见的web安全问题,原理和防范措施。安全意识。
- SQL注入
- XSS(跨站脚本攻击mcross-Site Scripting)
- CSRF(跨站请求伪造,Cross-site request forgery)
什么是SQL注入?
- 通过构造特殊的参数传入web应用,导致后端执行了恶意的SQL
- 通常由于程序员未对输入进行过滤,直接动态拼接SQL产生
- 可以使用开源工具sqlmap,SQLLninja检测
import os
from _md5 import md5
import MySQLdb
DATABASE_HOST = os.environ.get('DATABASE_HOST')
DATABASE_PWD = os.environ.get('DATABASE_PWD')
DATABASE_NAME =
create_sql = """
CREATE TABLE IF NOT EXISTS `users` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` varchar(45) NULL,
`email` varchar(45) NULL,
`password` varchar(45) NULL,
PRIMARY KEY(`id`)
);
insert into users (name,email,password) values ('andy','andy@qq.com',md5('andy123'));
insert into users (name,email,password) values ('kate','kate@qq.com',md5('kate123'));
insert into users (name,email,password) values ('alex','alex@qq.com',md5('alex123'));
"""
db = MySQLdb.connect(
host=DATABASE_HOST,
user='user',
password=DATABASE_PWD,
db=DATABASE_NAME
)
cur = db.cursor()
# cur.execute(create_sql) # 创建数据库而且写入数据
# cur.close()
# db.commit()
# sql = "select * from users"
name = input('请输入用户名')
password = input('请输入密码')
sql = "SElECT * FROM users WHERE name='{}' AND password=md5('{}')".format(name,password)
print(sql)
cur.execute(sql)
# print(cur.fetchall())
for row in cur.fetchall():
print(row)
db.close()
# 在我们输入用户名的时候在后面输入 ' -- 就相当于把后面的sql给注释掉,实现了sql的注入
# 我们使用占位符 %s可以防止sql注入
如何防范SQL注入?
web安全一大原则:永远不要相信用户的任何输入
1 对输入的参数做好检查(类型和范围);过滤和转义特殊字符
2 不要直接拼接sql,使用ORM可以大大降低sql注入风险
3 数据库层:做好全县管理配置;不要明文存储敏感信息
什么是XSS?
- 恶意用户将代码植入到提供给其他用户使用的页面中,未经转义的恶意代码输出到其他用户的浏览器被执行
- 用户浏览页面的时候嵌入页面中的脚本(js)会被执行,攻击用户
- 主要分为两类:反射型(非持久型),存储型(持久型)
<script>alert('hello')</script> # xss攻击
documnet.cookie # 黑客可以手机用户的cookie到指定服务器上
9-3 前后端分离与 RESTful 常见面试题
考点聚焦
什么是前后端分离?什么事RESTful
- 前后端分离的意义和方式
- 什么是RESTful
- 如何设计RESTful API
什么是前后端分离?有哪些优点?
后端只负责提供数据接口,不再渲染模板,前端获取数据并呈现
- 前后端解耦,接口复用(前端和客户端公用接口),减少开发量
- 各司其职,前后端同步开发,提升工作效率,定义好接口规范
- 更有利于调试(mock),测试和运维部署
什么是RESTful
是一种软件架构风格,通过url对资源进行增删查改

RESTful的准则

什么是RESTful API?
RESTful风格的API 接口
- 通过HTTP GET/POST/PUT/DELETE 获取/创建/更新/删除资源
- 一般使用JSON格式返回数据
- 一般web框架都有相应的插件支持RESTful API,比如Django就是restframework
如何设计RESTful API

9-4 web安全思考题:什么是https
什么是HTTPS?
- HTTP和HTTPS的区别
- 了解对称加密和非对称加密
- HTTPS的通信过程是什么样的?
第10章 系统设计考察点
10-1 系统设计考点解析
什么是系统设计?






10-2 系统设计真题解析:短网址系统的设计与实现
考点:
如何设计与实现一个短网址系统
- 什么是短网址系统?包含哪些功能(接口)
- 短网址系统的存储设计?需要存储哪些字段?
- 如何设计算法生成短网址
什么是短网址系统
TinyUrl Service
- 把一个长网址转成短网址的服务
- 比如 bitly.com/
- 转换之后网址的后缀不超过7位(自负或者数字)
场景和限制
使用场景:提供短网址服务为公司其他各业务服务
- 功能:一个长网址转成短网址并存储;根据短网址换原长url
- 要求短网址的后缀不超过7位(大小写字母和数字)
数据库存储设计


建表
CREATE TABLE short_url(
id bigint unsigned NOT NULL AUTO_INCREMENT,
token varchar(10),
url varchar(255),
created_at timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `idx_token` (`token`)
);


10-3 系统设计思考题:如何设计一个秒杀系统

