


1. 问题
运筹模拟的时候,我们通常会给定,某事件服从正态分布/指数分布之类。问题是,我们通常只能观察到样本数据,没有办法观察到其具体服从的分布。所谓服从什么分布,是需要我们从样本数据推测的。
那么问题来了,怎样从数据推测出其所服从的分布(goodness of fit)呢?
2. 分析
市面上有一些专业的统计软件,可以做到从数据到分布的推测。比如Stat::Fit。但289美元的价格可着实不低。所以我们需要另想办法。
常见分布匹配的方法有很多,比如
- Bayesian information criterion
- Kolmogorov–Smirnov test
- Cramér–von Mises criterion
- Anderson–Darling test
- Shapiro–Wilk test
- Chi-squared test
我们以 KS 测试为例。KS 具体理论很多书籍都有详细解释,这里不再重复。有兴趣的朋友可以关注后回复 ks 获取相关资料。
Scipy 的统计模块 stats,可以做 ks 测试。但有个问题是,分布参数需要我们提供。比如指数分布,其概率密度函数为
这里的 就需要我们自己提供。好在scipy里面有现成的方法可以从数据估算参数,就是用分布函数的
fit方法。
于是,我们可以用 fit() 从数据里面先估出分布的参数,然后再用ks test测试其是否满足分布,就可以得出数据到底服从什么分布了。
举个例子。现有一家水煮鱼饭馆,观察到了顾客到来的时间间隔见 data.txt,老板想知道它服从什么分布。
import scipy.stats as stats
import numpy as np
import matplotlib.pyplot as plt
data = np.loadtxt('data.txt', delimiter=',', encoding='utf8')
dists = {'norm': stats.norm, 'lognorm': stats.lognorm, 'expon': stats.expon}
for d in dists:
paras = dists[d].fit(data)
test = stats.kstest(data, dists[d].cdf, paras)
print('{:1}\tpvalue:{:2}'.format(d, test[-1]))
可以得出结果
norm pvalue:0.18025230160179895
lognorm pvalue:0.703843693432498
expon pvalue:0.705389895669437
可见,这个最可能服从指数分布,其 loc = 0.1076,scale = 5.56。
打印其结果如下
x = np.arange(0, 20, 0.01)paras = stats.norm.fit(data) ynorm = stats.norm.pdf(x, paras[0], paras[1])
paras = stats.lognorm.fit(data) ylognorm = stats.lognorm.pdf(x, paras[0], paras[1], paras[2])
paras = stats.expon.fit(data) yexpon = stats.expon.pdf(x, paras[0], paras[1])
fig, ax = plt.subplots()
ax.plot(x, ynorm, label='norm') ax.plot(x, ylognorm, label='lognorm') ax.plot(x, yexpon, label='expon')
ax.legend()
结果为
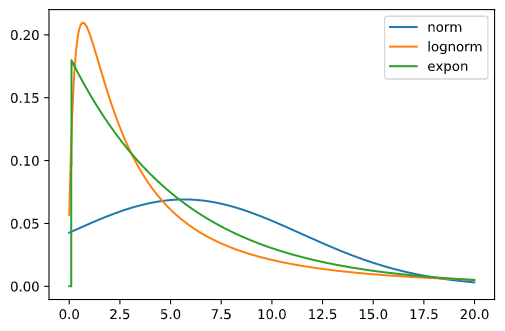
3. 扩展
今天我们大致讨论了如何用 scipy 模块判断样本数据所服从的分布。通过上面的例子我们可以看到,在 70% 左右的置信度上,数据既可能服从指数分布,也可能服从对数正态分布。
其实这也正常。理论分布是我们用来解释世界的一种手段,我们的真是世界到底服从什么分布,从样本是无法确定的。就像上面的图形,expon 和 lognorm 长得也真挺像。
另外,所谓一力降十会,咱有了一个 Python,就可以看淡世间所有繁华。就像有了刘亦菲,还要什么杨幂和阿娇?
4. 交流
独学而无友则孤陋寡闻。现有「数据与统计科学」微信交流群,内有数据行业资深从业人员、海外博士、硕士等,欢迎对数据科学、数据分析、机器学习、人工智能有兴趣的朋友加入,一起学习讨论。
大家可以扫描下面二维码,添加荔姐微信邀请加入,暗号:机器学习加群。

5. 延伸阅读
6. 参考文献
- W. McKinney, Python for Data Analysis. Beijing: O’Reilly, 2017.
- J. VanderPlas, Python Data Science Handbook. Beijing: O’Reilly, 2016.

本文使用 mdnice 排版
