

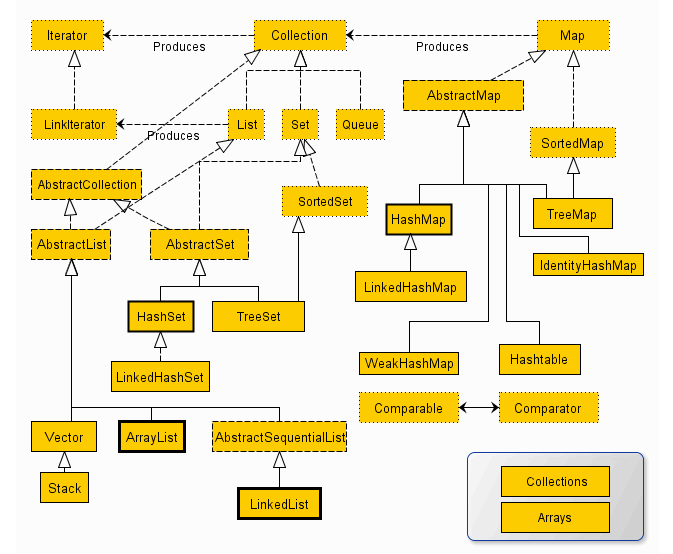
今天我们讨论一下java集合,下面我们来看一下集合图:
从源码上看,每个方法都没有加锁,因此是线程不安全的。 Vector源码
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
//实现了List接口
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
private int size;
}
1、Vector是线程安全的,ArrayList不是线程安全的。
2、ArrayList在底层数组不够用时在原来的基础上扩展0.5倍,Vector是扩展1倍。
我们来看一下ArrayList的add方法
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
Vector的add方法
/**
* Appends the specified element to the end of this Vector.
*
* @param e element to be appended to this Vector
* @return {@code true} (as specified by {@link Collection#add})
* @since 1.2
*/
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
方法实现都一样,就是加了一个synchronized的关键字,再来看看其它方法,先看ArrayList的remove方法
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
Vector的remove方法
public synchronized E remove(int index) {
modCount++;
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
int numMoved = elementCount - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--elementCount] = null; // Let gc do its work
return oldValue;
}
Vector的get方法
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
ArrayList的get方法
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
总结
1.对于Vector集合,只要是关键性的操作,方法前面都加了synchronized关键字,来保证线程的安全性。当执行synchronized修饰的方法前,系统会对该方法加一把锁,方法执行完成后释放锁,加锁和释放锁的这个过程,在系统中是有开销的,因此在单线程的环境中,Vector效率要差很多。
2.多线程环境不允许用ArrayList,需要做处理。
ArrayList、HashSet、HashMap是否线程安全的问题?
Arraylist 与 LinkedList 有什么不同?
-
- 是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
-
- 底层数据结构: Arraylist 底层使用的是 Object 数组;LinkedList 底层使用的是双向链表数据结构(注意双向链表和双向循环链表的区别:);
-
- 插入和删除是否受元素位置的影响: ① ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1) 而数组为近似 O(n) 。
-
- 是否支持快速随机访问: LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。
-
- 内存空间占用: ArrayList 的空间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
补充内容:RandomAccess 接口
public interface RandomAccess {
}
查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
在 binarySearch() 方法中,它要判断传入的 list 是否 RamdomAccess 的实例,如果是,调用 indexedBinarySearch() 方法,如果不是,那么调用 iteratorBinarySearch() 方法
public static <T>
int binarySearch(List<? extends Comparable<? super T>> list, T key) {
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list, key);
else
return Collections.iteratorBinarySearch(list, key);
}
ArraysList 实现了 RandomAccess 接口,
而 LinkedList 没有实现。为什么呢?我觉得还是和底层数据结构有关!ArraysList 底层是数组,而 LinkedList 底层是链表。数组天然支持随机访问,时间复杂度为 O(1) ,所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n) ,所以不支持快速随机访问。,ArraysList 实现了 RandomAccess 接口,就表明了他具有快速随机访问功能。 RandomAccess 接口只是标识,并不是说 ArraysList 实现 RandomAccess 接口才具有快速随机访问功能的!
下面再总结一下 list 的遍历方式选择:
- 实现了 RandomAccess 接口的 list,优先选择普通 for 循环 ,其次 foreach,
- 未实现 RandomAccess 接口的 ist, 优先选择 iterator 遍历(foreach 遍历底层也是通过 iterator 实现的),大 size 的数据,千万不要使用普通 for 循环
HashMap 的底层实现
1)JDK1.8 之前
JDK1.8 之前 HashMap 底层是:数组和链表,结合在一起使用也就是链表散列。HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的时数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK 1.8 HashMap 的 hash 方法源码:
JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
对比一下 JDK1.7 的 HashMap 的 hash 方法源码.
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
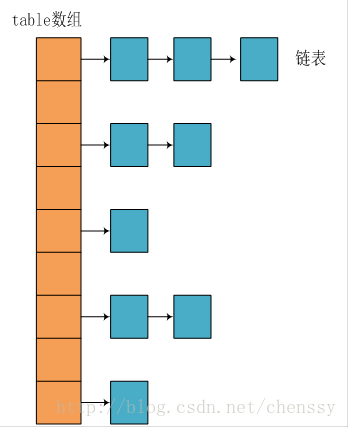
2)JDK1.8 之后
相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间。
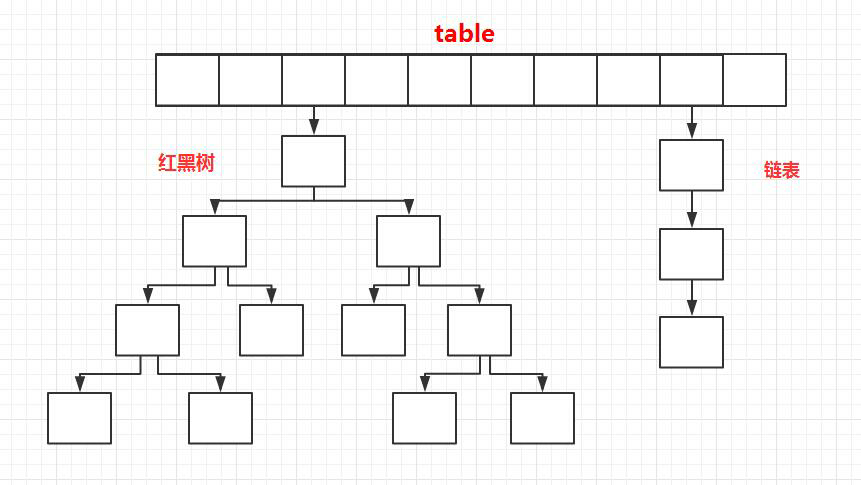
reeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
问完 HashMap 的底层原理之后,面试官可能就会紧接着问你 HashMap 底层数据结构相关的问题!
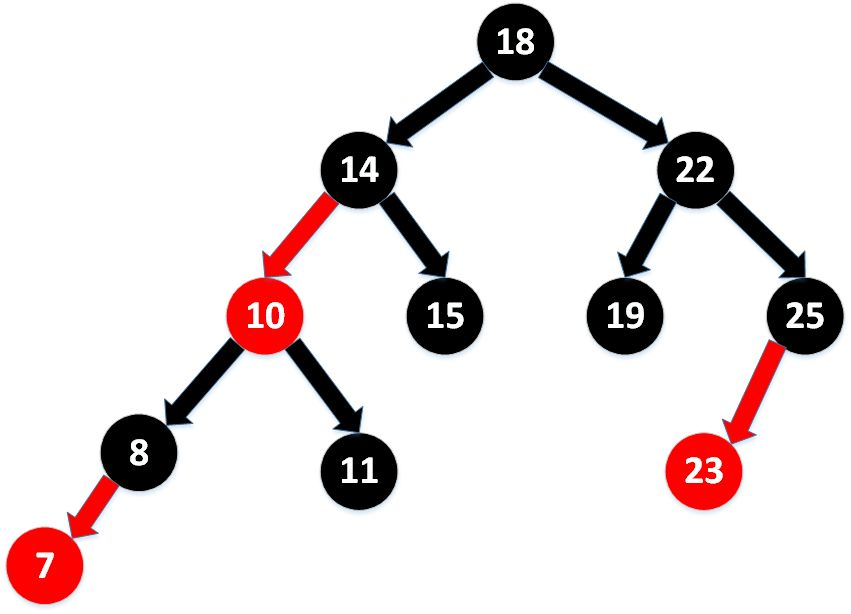
谈谈你对红黑树的理解
红黑树特点:
- 每个节点非红即黑;
- 根节点总是黑色的;
- 每个叶子节点都是黑色的空节点(NIL 节点);
- 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
- 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)
红黑树的应用:
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。
为什么要用红黑树
简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
红黑树这么优秀,为何不直接使用红黑树得了?
说一下自己对于这个问题的看法:我们知道红黑树属于(自)平衡二叉树,但是为了保持“平衡”是需要付出代价的,红黑树在插入新数据后可能需要通过左旋,右旋、变色这些操作来保持平衡,这费事啊。你说说我们引入红黑树就是为了查找数据快,如果链表长度很短的话,根本不需要引入红黑树的,你引入之后还要付出代价维持它的平衡。但是链表过长就不一样了。至于为什么选 8 这个值呢?通过概率统计所得,这个值是综合查询成本和新增元素成本得出的最好的一个值。
源码分析
Java7源码分析
先看下Java7里的HashMap实现
//HashMap里的数组
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
//Entry对象,存key、value、hash值以及下一个节点
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
}
//默认数组大小,二进制1左移4位为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//负载因子默认值
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//当前存的键值对数量
transient int size;
//阀值 = 数组大小 * 负载因子
int threshold;
//负载因子变量
final float loadFactor;
//默认new HashMap数组大小16,负载因子0.75
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//可以指定数组大小和负载因子
public HashMap(int initialCapacity, float loadFactor) {
//省略一些逻辑判断
this.loadFactor = loadFactor;
threshold = initialCapacity;
//空方法
init();
}
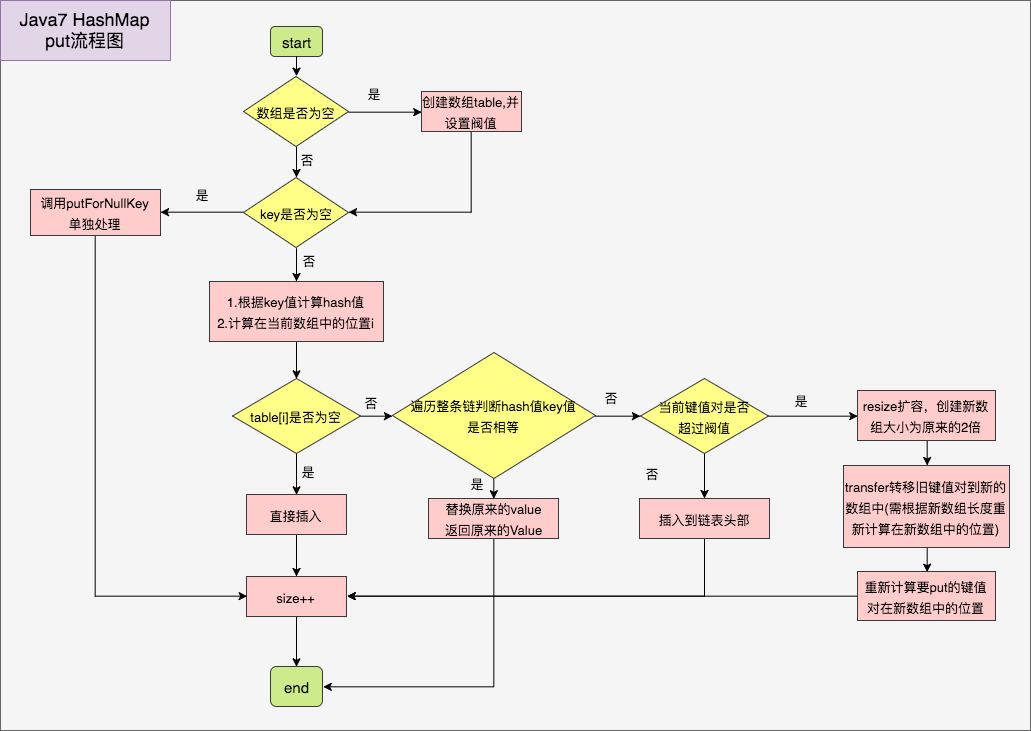
以上就是HashMap的一些先决条件,接着看平时put操作的代码实现,看下Java7代码:
public V put(K key, V value) {
//数组为空时创建数组
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//key为空单独对待
if (key == null)
return putForNullKey(value);
//①根据key计算hash值
int hash = hash(key);
//②根据hash值和当前数组的长度计算在数组中的索引
int i = indexFor(hash, table.length);
//遍历整条链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//③情况1.hash值和key值都相同的情况,替换之前的值
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
//返回被替换的值
return oldValue;
}
}
modCount++;
//③情况2.坑位没人,直接存值或发生hash碰撞都走这
addEntry(hash, key, value, i);
return null;
}
先看上面key为空的情况(上面画图的时候总要在第一格留个空key的键值对),执行 putForNullKey() 方法单独处理,会把该键值对放在index0,所以HashMap中是允许key为空的情况。再看下主流程:
步骤①.根据键值算出hash值 — > hash(key)
步骤②.根据hash值和当前数组的长度计算在数组中的索引 — > indexFor(hash, table.length)
static int indexFor(int h, int length) {
//hash值和数组长度-1按位与操作,听着费劲?其实相当于h%length;取余数(取模运算)
//如:h = 17,length = 16;那么算出就是1
//&运算的效率比%要高
return h & (length-1);
}
步骤③情况1.hash值和key值都相同,替换原来的值,并将被替换的值返回。
步骤③情况2.坑位没人或发生hash碰撞 — > addEntry(hash, key, value, i)
void addEntry(int hash, K key, V value, int bucketIndex) {
//当前hashmap中的键值对数量超过阀值
if ((size >= threshold) && (null != table[bucketIndex])) {
//扩容为原来的2倍
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
//计算在新表中的索引
bucketIndex = indexFor(hash, table.length);
}
//创建节点
createEntry(hash, key, value, bucketIndex);
}
如果put的时候超过阀值,会调用 resize() 方法将数组大小扩大为原来的2倍,并且根据新表的长度计算在新表中的索引(如之前17%16 =1,现在17%32=17),看下resize方法:
void resize(int newCapacity) { //传入新的容量
//获取旧数组的引用
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//极端情况,当前键值对数量已经达到最大
if (oldCapacity == MAXIMUM_CAPACITY) {
//修改阀值为最大直接返回
threshold = Integer.MAX_VALUE;
return;
}
//步骤①根据容量创建新的数组
Entry[] newTable = new Entry[newCapacity];
//步骤②将键值对转移到新的数组中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
//步骤③将新数组的引用赋给table
table = newTable;
//步骤④修改阀值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
上面的重点是步骤②,看下它具体的转移操作
void transfer(Entry[] newTable, boolean rehash) {
//获取新数组的长度
int newCapacity = newTable.length;
//遍历旧数组中的键值对
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//计算在新表中的索引,并到新数组中
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
这段for循环的遍历会使得转移前后键值对的顺序颠倒(Java7和Java8的区别)
总结一下Java7 put流程图:
HashMap 和 Hashtable 的区别/HashSet 和 HashMap 区别
HashMap 和 Hashtable 的区别
-
线程是否安全: HashMap 是非线程安全的,Hashtable 是线程安全的;Hashtable 内部的方法基本都经过 synchronized 修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!);
-
效率: 因为线程安全的问题,HashMap 要比 Hashtable 效率高一点。另外,Hashtable 基本被淘汰,不要在代码中使用它;
-
对 Null key 和 Null value 的支持: HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。但是在 Hashtable 中 put 进的键值只要有一个 null,直接抛出 NullPointerException。
-
初始容量大小和每次扩充容量大小的不同 : ① 创建时如果不指定容量初始值,Hashtable 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为 2 的幂次方大小(HashMap 中的tableSizeFor()方法保证,下面给出了源代码)。也就是说 HashMap 总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。
-
底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。 HashSet 和 HashMap 区别
如果你看过 HashSet 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 clone() 方法、writeObject()方法、readObject()方法是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。)

学习和了解ConcurrentHashMap
哈希表是中非常高效,复杂度为O(1)的数据结构,在Java开发中,我们最常见到最频繁使用的就是HashMap和HashTable,但是在线程竞争激烈的并发场景中使用都不够合理。
HashMap :先说HashMap,HashMap是线程不安全的,在并发环境下,可能会形成环状链表(扩容时可能造成,具体原因自行百度google或查看源码分析),导致get操作时,cpu空转,所以,在并发环境中使用HashMap是非常危险的。
HashTable : HashTable和HashMap的实现原理几乎一样,差别无非是1.HashTable不允许key和value为null;2.HashTable是线程安全的。但是HashTable线程安全的策略实现代价却太大了,简单粗暴,get/put所有相关操作都是synchronized的,这相当于给整个哈希表加了一把大锁,多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞,相当于将所有的操作串行化,在竞争激烈的并发场景中性能就会非常差。
HashTable性能差主要是由于所有操作需要竞争同一把锁,而如果容器中有多把锁,每一把锁锁一段数据,这样在多线程访问时不同段的数据时,就不会存在锁竞争了,这样便可以有效地提高并发效率。这就是ConcurrentHashMap所采用的"分段锁"思想。
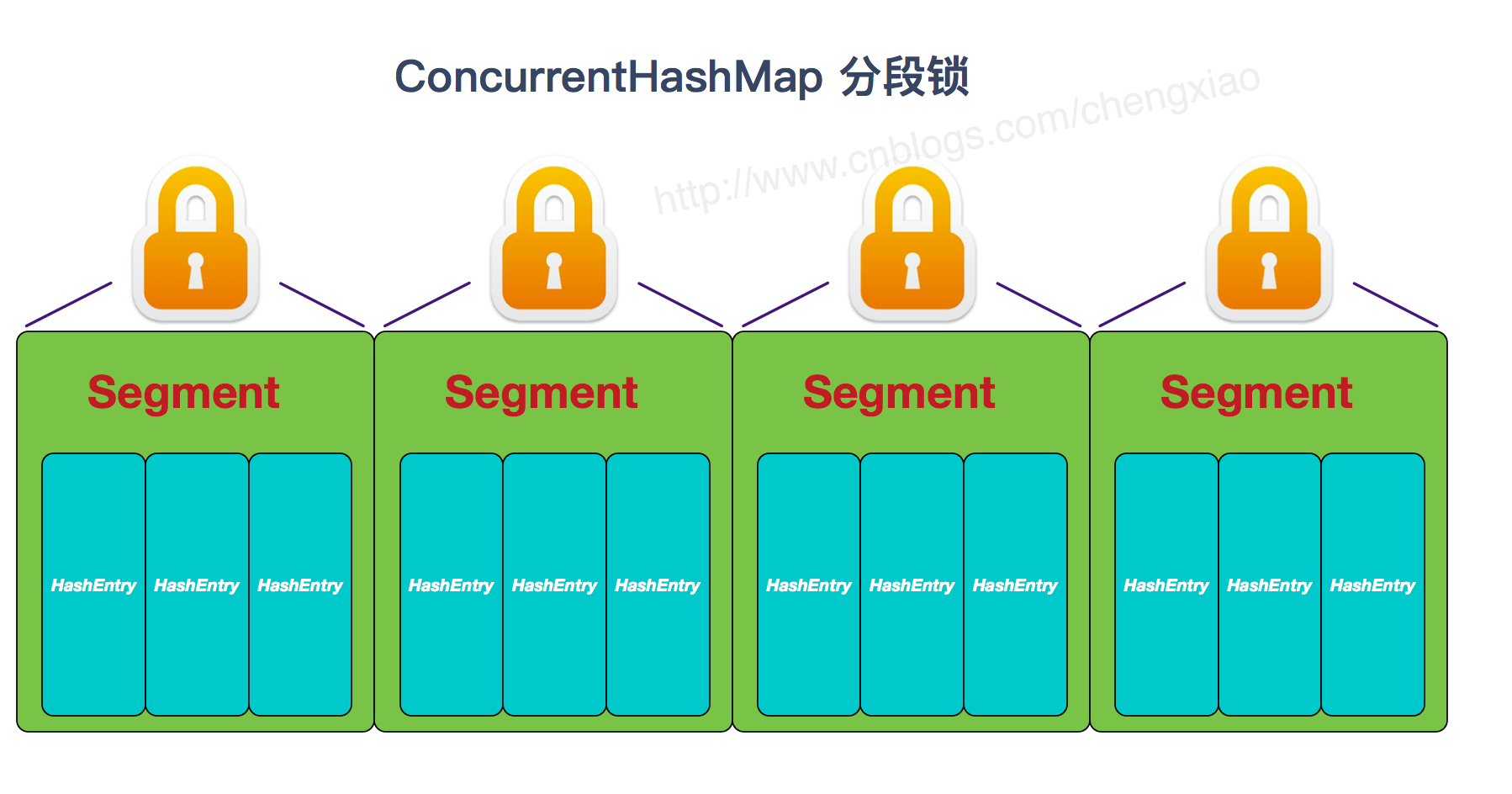
JDK1.7 的 ConcurrentHashMap:
ConcurrentHashMap 线程安全的具体实现方式/底层具体实现
JDK1.7(上面有示意图)
首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
transient volatile HashEntry<K,V>[] table;
Segment 实现了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
static class Segment<K,V> extends ReentrantLock implements Serializable {
}
一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和 HashMap 类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。
对于同一个Segment的操作才需考虑线程同步,不同的Segment则无需考虑。
JDK1.8 ConcurrentHashMap 底层数据结果
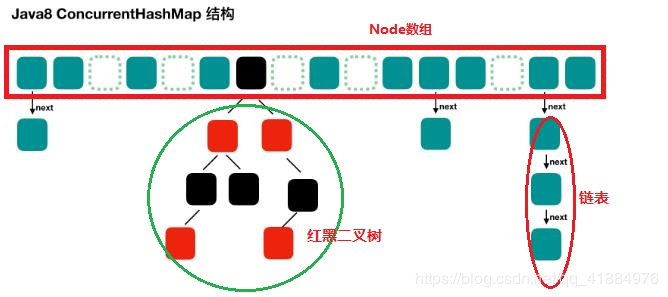
Node数组使用来存放树或者链表的头结点,当一个链表中的数量到达一个数目时,会使查询速率降低,所以到达一定阈值时,会将一个链表转换为一个红黑二叉树,通告查询的速率。
ConcurrentHashMap 取消了 Segment 分段锁,采用 CAS 和 synchronized 来保证并发安全。数据结构跟 HashMap1.8 的结构类似,数组+链表/红黑二叉树。
synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,效率又提升 N 倍。
总结:
ConcurrentHashMap <JDK1.7>, ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 <jdk1.8> 使用的是优化的synchronized 关键字 和 cas操作了维护并发。
(2):底层数据结构: hashMap同hashTable;都是使用数组 + 链表结构 ConcurrentHashMap <jdk1.7> :使用 Segment数组 + HashEntry数组 + 链表 <jdk1.8> :使用 Node数组+链表+ 红黑树
(3) : 效率 hashMap只能单线程操作,效率低下
hashTable使用的是synchronized方法锁,若一个线程抢夺了锁,其他线程只能等到持锁线程操作完成之后才能抢锁操作
jdk1.7 ConcurrentHashMap 使用的分段锁,如果一个线程占用一段,别的线程可以操作别的部分
jdk1.8 简化结构,put和get不用二次哈希,一把锁只锁住一个链表或者一棵树,并发效率更加提升。
