

数据取值与选择
Series数据选择方法
类比一维np数组和py字典
- 看作字典
import pandas as pd
data = pd.Series([0.25,0.5,0.75,1],index=['a','b','c','d'])
#或者data = pd.Series({'key1':value1,'key2':value2...})
data['b']#显式索引
'a' in data #类比字典表达式,检测键/索引和值
data.keys() #类比字典,输出键
list(data.items()) #类比输出字典
data['e'] = 1.25 # 新增键扩展字典,增加新的索引值扩展
# Series可变,Pandas 在底层已经为可能发生的内存布局和 数据复制自动决策
- 看作一维数组
data['a':'c'] # 显式索引作为切片,闭区间 data[0:2] #隐式索引作为切片,左闭右开 data[(data > 0.3) & (data < 0.8)] #掩码
- 索引器:loc iloc ix
# loc表示取值和切片都是显式的
data.loc[1]
data.loc[1:3]
out:1 a
3 b
# iloc表示取值和切片都是puthon形式(从0开始,左闭右开区间)的隐式索引
data.iloc[1]
data.iloc[1:3]
out:3 b
5 c
# ix:标准的python列表取值方式(主要用于DataFrame对象
DataFrame数据选择方法
- 看作字典
area = pd.Series({'California':423967,'Texas':695662,'New York':141297,'Florida':170312,'Illinois':149995})
pop = pd.Series({'California':38332521,'Texas':26448193,'New York':19651127,'Florida':19552860,'Illinois':12882135})
data = pd.DataFrame({'area':area,'pop':pop})
#获取DataFrame的列
data.area #属性形式
#列名不是纯字符串或者列名与DataFrame方法同名时,不能用属性索引
data['area'] #字典形式,注意引号
#使用字典语法增加列
data['density'] = data['pop'] / data['area']
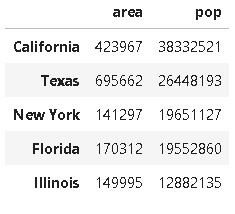
#输出值,按行查看数组数据 data.values # 转置DataFrame多维数组 data.T
转置多维数组
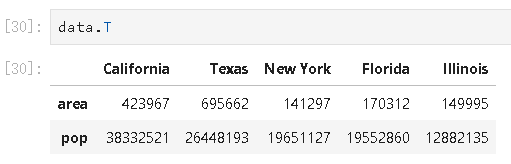
data.dtypes #查看各列数据类型 data.head(n) #查看前n行数据,不输入参数时默认前5行 data.tail(n) #查看后n行数据,不输入参数时默认后5行 data.index #查看行索引 data.columns #查看列索引 data.values #查看所有数值 data.describe() #查看描述性统计,包括count mean min max std 25% 50% 75% #重置数据 #使用iloc索引器可以像操作数组操作DataFrame #获取1-3行得0、2列数据,其中[0,2]部分参数不能使用切片 data.iloc[0:3,[0,2]] data.iloc[0,0] = 1 #所选位置替换为1
pandas数值运算方法
- pandas对象使用numpy通用函数,结果为保留索引得pandas对象
- 通用函数:索引对齐(通过python内置的集合运算规则实现,任何缺失值默认都用NaN填充)
DataFrame索引对齐
rng = np.random.RandomState(42) A = pd.DataFrame(rng.randint(0,10,(2,2)),list='AB') #输出2x2矩阵 B = pd.DataFrame(rng.randint(0,10,(3,3)),list='BCA') #输出3x3矩阵 A+B #输出结果的索引会自动排序,缺失值默认用NaN填充 fill = A.stack().mean() A.add(B,fill_value=fill) #用A中所有值的均值填充缺失值 #计算均值需要用stack将二维数组压缩成一维数组
py运算符与pd方法映射关系

运算
A = rng.randint(10,size=(3,4)) df = pd.DataFrame(A,columns=list'QPST') df - df.iloc[0] #默认按行计算 df.subtract(df['R'],axis=0) #通过axis参数指定按列计算
处理缺失值
- 主要形式 null NaN NA
- 方法
- 通过一个覆盖全局的掩码表示缺失值
- 用一个标签值(sentinel value)表 示缺失值
- None
- None是py单体对象,只能用于py对象构成的数组('object'数组类型
- py中没有定义整数与None之间的算数运算
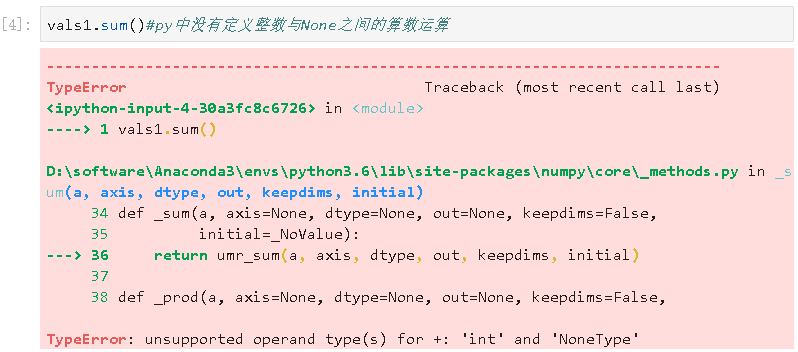
- NaN
- 种按照 IEEE 浮点 数标准设计、在任何系统中都兼容的特殊浮点数
- Nan会和所接触过的数据同化:无论和NaN进行何种操作,最终结果都是NaN
- nansum() nanmin()函数可以忽略缺失值的影响
- pandans把NaN和None看成是等价交换,自动将None转换为NaN;将没有标签值得数据类型自动转换成浮点数缺失值NA
- pandas对不同类型缺失值得转换规则

处理缺失值
- 发现缺失值
- data.isnull()#创建布尔类型掩码标签数组
- data.notnull()
- data[data.notnull()]#布尔类型掩码数组可以直接作为Series或DataFrame索引使用
- 剔除缺失值
- data.dropna()#Series中可以直接使用,DataFrame中无法单独剔除一个值,只能剔除缺失值所在的整行或者整列(没有指定时默认剔除行)
- 参数axis指定剔除行/列
- 参数how设置剔除行或者列缺失值的数量阈值
- 参数thresh设置行或列中非缺失值的最小数量
- 替换缺失值
- data.fillna(0) #用0填充缺失值
- mathod指定填充方式
- data.fillna(method='ffill')#前面没有值时,填充后依然为空
- data.fillna(method='bfill')#后面没有值时,填充后依然为空
