

File
Java IO 系统本质上就是对文件的读写操作。Java 中使用 File 来抽象一个文件,无论是普通文件或是目录,都可对应于一个 File 对象。它只是抽象的代表了磁盘上的某个文件或目录,内部实际上是依赖一个平台无关的本地文件系统类,并且 File 无法对其所表示文件内容进行任何读写操作(那是流做的事情)。
构建一个 File 实例
属性成员
private static final FileSystem fs = DefaultFileSystem.getFileSystem();
这是 File 类中最核心的成员,它表示为当前系统的文件系统 API,所有向磁盘发出的操作都是基于这个属性的。
private final String path;
path 代表了当前实例的完整路径名称,如果当前的 File 实例表示的是目录的话,那么 path 的值就是这个完整的目录名称,如果表示的是纯文件的话,那么这个 path 的值等于该文件的完整路径 + 文件名称。
public static final char separatorChar = fs.getSeparator();
public static final char pathSeparatorChar = fs.getPathSeparator();
separatorChar 表示的是目录间的分隔符,pathSeparatorChar 表示的是不同路径下的分隔符,这两个值在不同的系统平台下不尽相同。例如 Windows 下这两者的值分别为:「\」 和 「;」,其中封号用于分隔多个不同路径。
File 类提供了四种不同的构造器用于实例化一个 File 对象。
public File(String pathname)
pathname 的值可以是一个目录,也可以是一个纯文件的名称。例如:
File file = new File("C:\\Users\\yanga\\Desktop");
File file1 = new File("C:\\Users\\yanga\\Desktop\\a.txt");
File file2 = new File("a.txt");
当然也可以显式指定一个父路径:
public File(String parent, String child)
第三种构造器其实本质上和第二种是一样的,只不过增加了一个父类 File 实例的封装过程:
public File(File parent, String child)
文件名称或路径相关信息获取
getName 方法可以用于获取文件名称:
public String getName() {
int index = path.lastIndexOf(separatorChar);
if (index < prefixLength) return path.substring(prefixLength);
return path.substring(index + 1);
}
separatorChar 表示为路径分隔符,Windows 中为符号「\」,path 属性存储的当前 File 实例的完整路径名称,所以最后一次出现的位置后面所有的字符必然是我们的文件名称。
getParent 方法用于返回当前文件的父级目录,无论你是纯文件或是目录,你终有你的父目录(当然,虚拟机生成的临时文件自然不是)。
public String getParent() {
int index = path.lastIndexOf(separatorChar);
if (index < prefixLength) {
if ((prefixLength > 0) && (path.length() > prefixLength))
return path.substring(0, prefixLength);
return null;
}
return path.substring(0, index);
}
getPath 方法可以返回当前 File 实例的完整文件名称。
public String getPath() {
return path;
}
- public boolean isAbsolute():是否为绝对路径
- public String getAbsolutePath():获取当前 File 实例的绝对路径
- public String getCanonicalPath():返回当前 File 实例的标准路径
一般而言,「../」表示源文件所在目录的上一级目录,「../../」表示源文件所在目录的上上级目录,并以此类推。getAbsolutePath 方法不会做这种转换的操作,而 getCanonicalPath 方法则会将这些特殊字符进行识别并取合适的语义。
File file = new File("..\\a.txt");
System.out.println(file.getAbsolutePath());
System.out.println(file.getCanonicalPath());
C:\Users\yanga\Desktop\Java\workspace2017\TestFile\..\a.txt
C:\Users\yanga\Desktop\Java\workspace2017\a.txt
文件的属性信息获取
这部分的文件操作其实很简单,无非是一些文件权限的问题,是否可读,是否可写,是否为隐藏文件等。下面我们具体看看这些方法:
- public boolean canRead():该抽象的 File 实例对应的文件是否可读
- public boolean canWrite():该抽象的 File 实例对应的文件是否可写
- public boolean exists():该抽象的 File 实例对应的文件是否实际存在
- public boolean isDirectory():该抽象的 File 实例对应的文件是否是一个目录
- public boolean isFile():该抽象的 File 实例对应的文件是否是一个纯文件
- public boolean isHidden():该抽象的 File 实例对应的文件是否是一个隐藏文件
- public long length():文件内容所占的字节数
需要说明一点的是,length 方法对于纯文件来说,可以正确返回该文件的字节总数,但是对于一个目录而言,返回值将会是一个「unspecified」的数值,既不是目录下所有文件的总字节数,也不是零,只是一个未被说明的数值,没有意义。
文件的操作
- public boolean createNewFile():根据抽象的 File 对象创建一个实际存在的磁盘文件
- public boolean delete():删除该 File 对象对应的磁盘文件,删除失败会返回 false
public String[] list() {
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkRead(path);
}
if (isInvalid()) {
return null;
}
return fs.list(this);
}
这个方法会检索出当前实例所代表的目录下所有的「纯文件」和「目录」简单名称集合。例如:
File file = new File("C:\\Users\\yanga\\Desktop");
String[] list = file.list();
for (String str : list){
System.out.println(str);
}
需要注意一点,如果我们的 File 实例对应的不是一个目录,而是一个纯文件,那么 list 将返回 null。
public String[] list(FilenameFilter filter) {
String names[] = list();
if ((names == null) || (filter == null)) {
return names;
}
List<String> v = new ArrayList<>();
for (int i = 0 ; i < names.length ; i++) {
if (filter.accept(this, names[i])) {
v.add(names[i]);
}
}
return v.toArray(new String[v.size()]);
}
这个方法其实是 list 的重载版本,它允许传入一个过滤器用于检索目录时只筛选我们需要的文件及目录。
public interface FilenameFilter {
boolean accept(File dir, String name);
}
只需要重写这个 accept 方法即可,list 的 for 循环每获取一个文件或目录就会尝试着先调用这个过滤方法,如果通过筛选,才会将当前文件的简单名称添加进返回集合中。
当然,File 类中还提供了两个「变种」list 方法,例如:
- public File[] listFiles()
- public File[] listFiles(FilenameFilter filter)
它们不再返回目标目录下的「纯文件」和「目录」的简单名称,而返回它们所对应的 File 对象,其实也没什么,目标目录 + 简单名称 即可构建出这些 File 实例了。
- public boolean mkdir()
- public boolean mkdirs()
两者都是依据的当前 File 实例创建文件夹。
File file = new File("C:\\Users\\yanga\\Desktop\\test2");
System.out.println(file.mkdir());
File file2 = new File("C:\\Users\\yanga\\Desktop\\test3\\hello");
System.out.println(file2.mkdir());
test2 和 test3 在程序执行之前都不存在。
true
false
这源于 mkdir 方法一次只能创建一个文件夹,倘若给定的目录的父级或更上层目录存在未被创建的目录,那么将导致创建失败。
而 mkdirs 方法就是用于解决这种情境的,它会创建目标路径上所有未创建的目录。
File file3 = new File("C:\\Users\\yanga\\Desktop\\test3\\hello\\231");
System.out.println(file3.mkdirs());
即便我们 test3 文件夹就不存在,程序运行之后,test3、hello、231 这三个文件夹都会被创建出来。
File 还有一类创建临时文件的方法,所谓临时文件即:运行期存在,虚拟机关闭时销毁。
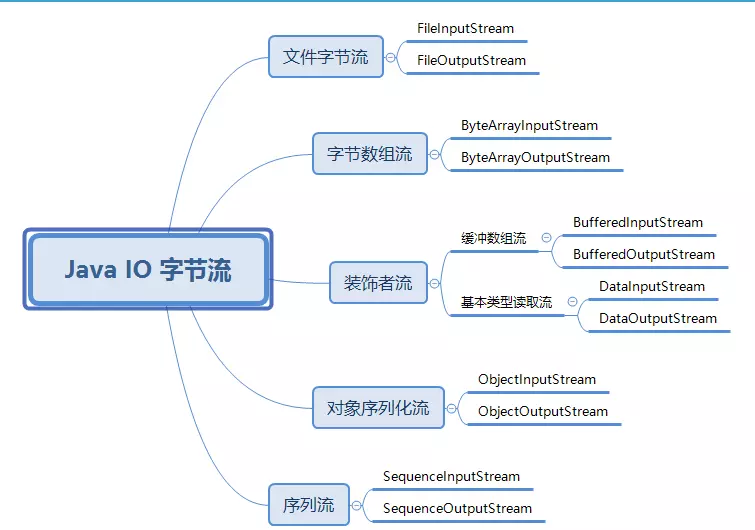
Java 的字节流文件读取
File 类型仅仅用于抽象化描述一个磁盘文件或目录,却不具备访问和修改一个文件内容的能力。
Java 的 IO 流就是用于读写文件内容的一种设计,它能完成将磁盘文件内容输出到内存或者是将内存数据输出到磁盘文件的数据传输工作。
一类是针对二进制文件的字节流,另一类是针对文本文件的字符流。
基类字节流 Input/OutputStream
InputStream 和 OutputStream 分别作为读字节流和写字节流的基类,所有字节相关的流都必然继承自他们中任意一个,而它们本身作为一个抽象类,也定义了最基本的读写操作。
public abstract int read() throws IOException;
这是一个抽象的方法,并没有提供默认实现,要求子类必须实现。而这个方法的作用就是为你返回当前文件的下一个字节。
方法的返回值是使用的整型类型「int」来接收的,为什么不用「byte」? 首先,read 方法返回的值一定是一个八位的二进制,而一个八位的二进制可以取值的值区间为:「0000 0000,1111 1111」,也就是范围 [-128,127]。 read 方法同时又规定当读取到文件的末尾,即文件没有下一个字节供读取了,将返回值 -1 。所以如果使用 byte 作为返回值类型,那么当方法返回一个 -1 ,我们该判定这是文件中数据内容,还是流的末尾呢? 而 int 类型占四个字节,高位的三个字节全部为 0,我们只使用它的最低位字节,当遇到流结尾标志时,返回四个字节表示的 -1(32 个 1),这就自然的和表示数据的值 -1(24 个 0 + 8 个 1)区别开来了。
接下来也是一个 read 方法,但是 InputStream 提供默认实现:
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
public int read(byte b[], int off, int len) throws IOException{
//为了不使篇幅过长,方法体大家可自行查看 jdk 源码
}
这两个方法本质上是一样的,第一个方法是第二个方法的特殊形态,它允许传入一个字节数组,并要求程序将文件中读到的字节从数组索引位置 0 开始填充,供填充数组长度个字节数。 而第二个方法更加宽泛一点,它允许你指定起始位置和字节总数。 InputStream 中还有其他几个方法,基本都没怎么具体实现,留待子类实现,我们简单看看。
- public long skip(long n):跳过 n 个字节,返回实际跳过的字节数
- public void close():关闭流并释放对应的资源
- public synchronized void mark(int readlimit)
- public synchronized void reset()
- public boolean markSupported()
mark 方法会在当前流读取位置打上一个标志,reset 方法即重置读取指针到该标志处。 事实上,文件读取是不可能重置回头读取的,而一般都是将标志位置到重置点之间所有的字节临时保存了,当调用 reset 方法时,其实是从保存的临时字节集合进行重复读取,所以 readlimit 用于限制最大缓存容量。 而 markSupported 方法则用于确定当前流是否支持这种「回退式」读取操作。
文件字节流 FileInput/OutputStream
首先 FileInputStream 有以下几种构造器实例化一个对象:
public FileInputStream(String name) throws FileNotFoundException {
this(name != null ? new File(name) : null);
}
public FileInputStream(File file) throws FileNotFoundException {
String name = (file != null ? file.getPath() : null);
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkRead(name);
}
if (name == null) {
throw new NullPointerException();
}
if (file.isInvalid()) {
throw new FileNotFoundException("Invalid file path");
}
fd = new FileDescriptor();
fd.attach(this);
path = name;
open(name);
}
核心的就是一个 open 方法,用于打开一个文件。
基类 InputStream 中有一个抽象方法 read 要求所有子类进行实现,而 FileInputStream 使用本地方法进行了实现:
public int read() throws IOException {
return read0();
}
private native int read0() throws IOException;
这个 read0 的具体实现我们暂时无从探究,但是你必须明确的是,这个 read 方法的作用,它用于返回流中下一个字节,返回 -1 说明读取到文件末尾,已无字节可读。
除此之外,FileInputStream 中还有一些其他的读取相关方法,但大多采用了本地方法进行了实现,此处我们简单看看:
- public int read(byte b[]):读取 b.length() 个长度的字节到数组中
- public int read(byte b[], int off, int len):读取指定长度的字节数到数组中
- public native long skip(long n):跳过 n 的字节进行读取
- public void close():释放流资源
关于 FileOutputStream,还需要强调一点的是它的构造器,其中有以下两个构造器:
public FileOutputStream(String name, boolean append)
public FileOutputStream(File file, boolean append)
参数 append 指明了,此流的写入操作是覆盖还是追加,true 表示追加,false 表示覆盖。
字节数组流 ByteArrayInput/OutputStream
所谓的「字节数组流」就是围绕一个字节数组运作的流,它并不像其他流一样,针对文件进行流的读写操作。
字节数组流虽然并不是基于文件的流,但却依然是一个很重要的流,因为它内部封装的字节数组并不是固定的,而是动态可扩容的,往往基于某些场景下,非常合适。
ByteArrayInputStream 是读字节数组流,可以通过以下构造函数被实例化:
protected byte buf[];
protected int pos;
protected int count;
public ByteArrayInputStream(byte buf[]) {
this.buf = buf;
this.pos = 0;
this.count = buf.length;
}
public ByteArrayInputStream(byte buf[], int offset, int length)
buf 就是被封装在 ByteArrayInputStream 内部的一个字节数组,ByteArrayInputStream 的所有读操作都是围绕着它进行的。 所以,实例化一个 ByteArrayInputStream 对象的时候,至少传入一个目标字节数组的。
pos 属性用于记录当前流读取的位置,count 记录了目标字节数组最后一个有效字节索引的后一个位置。
/读取下一个字节
public synchronized int read() {
return (pos < count) ? (buf[pos++] & 0xff) : -1;
}
//读取 len 个字节放到字节数组 b 中
public synchronized int read(byte b[], int off, int len){
//同样的,方法体较长,大家查看自己的 jdk
}
除此之外,ByteArrayInputStream 还非常简单的实现了「重复读取」操作。
public void mark(int readAheadLimit) {
mark = pos;
}
public synchronized void reset() {
pos = mark;
}
因为 ByteArrayInputStream 是基于字节数组的,所有重复读取操作的实现就比较容易了,基于索引实现就可以了。
ByteArrayOutputStream 是写的字节数组流。
protected byte buf[];
//这里的 count 表示的是 buf 中有效字节个个数
protected int count;
构造器:
public ByteArrayOutputStream() {
this(32);
}
public ByteArrayOutputStream(int size) {
if (size < 0) {
throw new IllegalArgumentException("Negative initial size: "+ size);
}
buf = new byte[size];
}
构造器的核心任务是,初始化内部的字节数组 buf,允许你传入 size 显式限制初始化的字节数组大小,否则将默认长度 32 。
从外部向 ByteArrayOutputStream 写内容:
public synchronized void write(int b) {
ensureCapacity(count + 1);
buf[count] = (byte) b;
count += 1;
}
public synchronized void write(byte b[], int off, int len){
if ((off < 0) || (off > b.length) || (len < 0) ||
((off + len) - b.length > 0)) {
throw new IndexOutOfBoundsException();
}
ensureCapacity(count + len);
System.arraycopy(b, off, buf, count, len);
count += len;
}
看到没有,所有写操作的第一步都是 ensureCapacity 方法的调用,目的是为了确保当前流内的字节数组能容纳本次写操作。 而这个方法也很有意思了,如果计算后发现,内部的 buf 不能够支持本次写操作,则会调用 grow 方法做一次扩容。扩容的原理和 ArrayList 的实现是类似的,扩大为原来的两倍容量。 除此之外,ByteArrayOutputStream 还有一个 writeTo 方法:
public synchronized void writeTo(OutputStream out) throws IOException {
out.write(buf, 0, count);
}
将我们内部封装的字节数组写到某个输出流当中。
- public synchronized byte toByteArray()[]:返回内部封装的字节数组
- public synchronized int size():返回 buf 的有效字节数
- public synchronized String toString():返回该数组对应的字符串形式
注意到,这两个流虽然被称作「流」,但是它们本质上并没有像真正的流一样去分配一些资源,所以我们无需调用它的 close 方法。
装饰者缓冲流 BufferedInput/OutputStream
装饰者流其实是基于一种设计模式「装饰者模式」而实现的一种文件 IO 流。
在这之前,我们使用的文件读写流 FileInputStream 和 FileOutputStream 都是一个字节一个字节的从磁盘读取或写入,非常耗时。 而我们的缓冲流可以预先从磁盘一次性读出指定容量的字节数到内存中,之后的读取操作将直接从内存中读取,提高效率。
依然先以 BufferedInputStream 为例,我们简单提一下它的几个核心属性:
private static int DEFAULT_BUFFER_SIZE = 8192;
protected volatile byte buf[];
private static int MAX_BUFFER_SIZE = Integer.MAX_VALUE - 8;
protected int count;
protected int pos;
protected int markpos = -1;
protected int marklimit;
buf 就是用于缓冲读的字节数组,它的值将随着流的读取而不停的被填充,继而后续的读操作可以直接基于这个缓冲数组。
DEFAULT_BUFFER_SIZE 规定了默认缓冲区的大小,即 buf 的数组长度。MAX_BUFFER_SIZE 指明了缓冲区的上限。
count 指向缓冲数组中最后一个有效字节索引后一位。pos 指向下一个待读取的字节索引位置。
markpos 和 marklimit 用于重复读操作。
BufferedInputStream 的几个示例构造器:
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
整体上来说,前者只需要传入一个「被装饰」的 InputStream 实例,并使用默认大小的缓冲区。后者则可以显式指明缓冲区的大小。 除此之外,super(in) 会将这个 InputStream 实例保存进父类 FilterInputStream 的 in 属性字段中,并且所有实际的磁盘读操作都由这个 InputStream 实例发出。 下面我们来看最重要的读操作以及缓冲区是如何被填充的。
public synchronized int read() throws IOException {
if (pos >= count) {
fill();
if (pos >= count)
return -1;
}
return getBufIfOpen()[pos++] & 0xff;
}
这个方法想必大家已经很熟悉了,从流中读取下一个字节并返回,但细节上的实现还是稍稍有些不同。
count 指向了缓冲数组中有效字节索引后一位置处,pos 指向下一个待读取的字节索引位置。理论上 pos 是不可能大于 count 的,最多等于。 如果 pos 等于 count,那说明缓冲数组中所有有效字节都已经被读取过了,此时即需要丢弃缓冲区中那些「无用」的数据,从磁盘重新加载一批新数据填充缓冲区。 而事实上,fill 方法就是做的这个事情,它的代码比较多,就不带大家去解析了,你理解了它的作用,想必分析它的实现也是容易的。 如果 fill 方法调用之后,pos 依然 等于 count,那么说明 InputStream 实例并没有从流中读取出任何数据,也即文件流中无数据可读。关于这一点,参见 fill 方法 246 行。 总的来说,如果成功填充了缓冲区,那么我们的 read 方法将直接从缓冲区取出一个字节返回给调用者。
public synchronized int read(byte b[], int off, int len){
//.....
}
skip 方法用于跳过指定长度的字节数进行文件流的继续读取:
public synchronized long skip(long n){
//.....
}
注意一点的是,skip 方法尽量去跳过 n 个字节,但不保证一定跳过 n 个字节,方法返回的是实际跳过的字节数。如果缓冲数组中剩余可用字节数小于 n,那么最终将跳过缓冲数组中实际可跳过的字节数。
最后要说一说这个 close 方法:
public void close() throws IOException {
byte[] buffer;
while ( (buffer = buf) != null) {
if (bufUpdater.compareAndSet(this, buffer, null)) {
InputStream input = in;
in = null;
if (input != null)
input.close();
return;
}
// Else retry in case a new buf was CASed in fill()
}
}
close 方法将赋空「被装饰者」流,并调用它的 close 方法释放相关资源,最终也会清空缓冲数组所占用的内存空间。 BufferedInputStream 提供了读缓冲能力,而 BufferedOutputStream 则提供了写缓冲能力,即内存的写操作并不会立马更新到磁盘,暂时保存在缓冲区,待缓冲区满时一并写入。
protected byte buf[];
protected int count;
buf 代表了内部缓冲区,count 表示缓冲区中实际数据容量,即 buf 中有效字节数,而不是 buf 数组长度。
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}
public BufferedOutputStream(OutputStream out, int size) {
super(out);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
一样的实现思路,必须提供的是一个 OutputStream 输出流实例,也可以选择性指明缓冲区大小。
public synchronized void write(int b) throws IOException {
if (count >= buf.length) {
flushBuffer();
}
buf[count++] = (byte)b;
}
写方法将首先检查缓冲区是否还能容纳本次写操作,如果不能将发起一次磁盘写操作,将缓冲区数据全部写入磁盘文件,否则将优先写入缓冲区。 当然,BufferedOutputStream 也提供了 flush 方法向外提供接口,也即不一定非要等到缓冲区满了才向磁盘写数据,你也可以显式的调用该方法让它清空缓冲区并更新磁盘文件。
public synchronized void flush() throws IOException {
flushBuffer();
out.flush();
}
关于缓冲流,核心内容介绍如上,这是一种能够显著提升效率的流,通过它,能够减少磁盘访问次数,提升程序执行效率。
Java 字符流文件读写
首先需要明确一点的是,字节流处理文件的时候是基于字节的,而字符流处理文件则是基于一个个字符为基本单元的。 但实际上,字符流操作的本质就是「字节流操作」+「编码」两个过程的封装,你想是不是,无论你是写一个字符到文件,你需要将字符编码成二进制,然后以字节为基本单位写入文件,或是你读一个字符到内存,你需要以字节为基本单位读出,然后转码成字符。
基类 Reader/Writer
Java 中是如何表示一个字符的。首先,Java 中的默认字符编码为:UTF-8,而我们知道 UTF-8 编码的字符使用 1 到 4 个字节进行存储,越常用的字符使用越少的字节数。 而 char 类型被定义为两个字节大小,也就是说,对于通常的字符来说,一个 char 即可存储一个字符,但对于一些增补字符集来说,往往会使用两个 char 来表示一个字符。 Reader 作为读字符流的基类,它提供了最基本的字符读取操作。
protected Object lock;
protected Reader() {
this.lock = this;
}
protected Reader(Object lock) {
if (lock == null) {
throw new NullPointerException();
}
this.lock = lock;
}
Reader 是一个抽象类,所以毋庸置疑的是,这些构造器是给子类调用的,用于初始化 lock 锁对象。
public int read() throws IOException {
char cb[] = new char[1];
if (read(cb, 0, 1) == -1)
return -1;
else
return cb[0];
}
public int read(char cbuf[]) throws IOException {
return read(cbuf, 0, cbuf.length);
}
abstract public int read(char cbuf[], int off, int len)
基本的读字符操作都在这了,第一个方法用于读取一个字符出来,如果已经读到了文件末尾,将返回 -1,同样的以 int 作为返回值类型接收,为什么不用 char?原因是一样的,都是由于 -1 这个值的解释不确定性。 第二个方法和第三个方法是类似的,从文件中读取指定长度的字符放置到目标数组当中。第三个方法是抽象方法,需要子类自行实现,而第二个方法却又是基于它的。 还有一些方法也是类似的:
- public long skip(long n):跳过 n 个字符
- public boolean ready():下一个字符是否可读
- public boolean markSupported():见 reset 方法
- public void mark(int readAheadLimit):见 reset 方法
- public void reset():用于实现重复读操作
- abstract public void close():关闭流
Writer 是写的字符流,它用于将一个或多个字符写入到文件中,当然具体的 write 方法依然是一个抽象的方法,待子类来实现。
适配器 InpustStramReader/OutputStreamWriter
适配器字符流继承自基类 Reader 或 Writer,它们算是字符流体系中非常重要的成员了。主要的作用就是,将一个字节流转换成一个字符流。
首先就是它最核心的成员:
private final StreamDecoder sd;
StreamDecoder 是一个解码器,用于将字节的各种操作转换成字符的相应操作。 然后就是构造器:
public InputStreamReader(InputStream in) {
super(in);
try {
sd = StreamDecoder.forInputStreamReader(in, this, (String)null);
} catch (UnsupportedEncodingException e) {
throw new Error(e);
}
}
public InputStreamReader(InputStream in, String charsetName)
throws UnsupportedEncodingException
{
super(in);
if (charsetName == null)
throw new NullPointerException("charsetName");
sd = StreamDecoder.forInputStreamReader(in, this, charsetName);
}
这两个构造器的目的都是为了初始化这个解码器,都调用的方法 forInputStreamReader,只是参数不同而已。
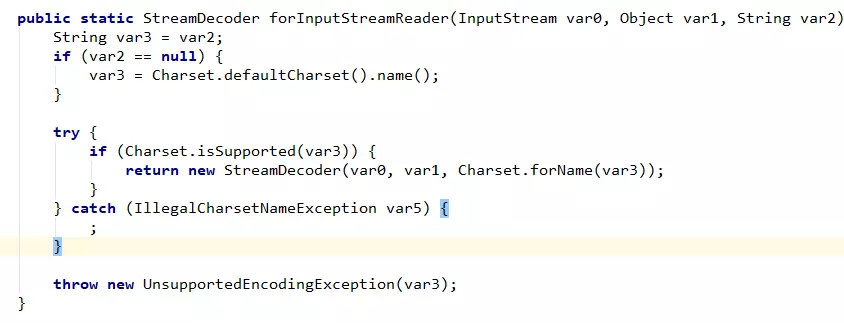
这是一个典型的静态工厂模式,三个参数,var0 和 var1 没什么好说的,分别代表的是字节流实例和适配器实例。
而参数 var2 其实代表的是一种字符编码的名称,如果为 null,那么将使用系统默认的字符编码:UTF-8 。
接着介绍的所有方法几乎都是依赖的这个解码器而实现的。
public String getEncoding() {
return sd.getEncoding();
}
public int read() throws IOException {
return sd.read();
}
public int read(char cbuf[], int offset, int length){
return sd.read(cbuf, offset, length);
}
public void close() throws IOException {
sd.close();
}
OutputStreamWriter 中必然也存在一个相反的 StreamEncoder 实例用于编码字符。 除了这一点外,其余的操作并没有什么不同,或是通过字符数组向文件中写入,或是通过字符串向文件中写入,又或是通过 int 的低 16 位向文件中写入。
文件字符流 FileReader/Writer
FileReader 继承自 InputStreamReader,有且仅有以下三个构造器:
public FileReader(String fileName) throws FileNotFoundException {
super(new FileInputStream(fileName));
}
public FileReader(File file) throws FileNotFoundException {
super(new FileInputStream(file));
}
public FileReader(FileDescriptor fd) {
super(new FileInputStream(fd));
}
理论上来说,所有的字符流都应当以我们的适配器为基类,因为只有它提供了字符到字节之间的转换,无论你是写或是读都离不开它。 而我们的 FileReader 并没有扩展任何一个自己的方法,父类 InputStreamReader 中预实现的字符操作方法对他来说已经足够,只需要传入一个对应的字节流实例即可。
字符数组流 CharArrayReader/Writer
字符数组和字节数组流是类似的,都是用于解决那种不确定文件大小,而需要读取其中大量内容的情况。 由于它们内部提供动态扩容机制,所以既可以完全容纳目标文件,也可以控制数组大小,不至于分配过大内存而浪费了大量内存空间。 先以 CharArrayReader 为例
protected char buf[];
public CharArrayReader(char buf[]) {
this.buf = buf;
this.pos = 0;
this.count = buf.length;
}
public CharArrayReader(char buf[], int offset, int length){
//....
}
构造器核心任务就是初始化一个字符数组到内部的 buf 属性中,以后所有对该字符数组流实例的读操作都基于 buf 这个字符数组。
除此之外,这里还涉及一个 StringReader 和 StringWriter,其实本质上和字符数组流是一样的,毕竟 String 的本质就是 char 数组。
缓冲数组流 BufferedReader/Writer
同样的,BufferedReader/Writer 作为一种缓冲流,也是装饰者流,用于提供缓冲功能。大体上类似于我们的字节缓冲流,这里我们简单介绍下。
private Reader in;
private char cb[];
private static int defaultCharBufferSize = 8192;
public BufferedReader(Reader in, int sz){..}
public BufferedReader(Reader in) {
this(in, defaultCharBufferSize);
}
cb 是一个字符数组,用于缓存从文件流中读取出来的部分字符,你可以在构造器中初始化这个数组的长度,否则将使用默认值 8192 。
public int read() throws IOException {..}
public int read(char cbuf[], int off, int len){...}
关于 read,它依赖成员属性 in 的读方法,而 in 作为一个 Reader 类型,内部往往又依赖的某个 InputStream 实例的读方法。
所以说,几乎所有的字符流都离不开某个字节流实例。
标准打印输出流
打印输出流主要有两种,PrintStream 和 PrintWriter,前者是字节流,后者是字符流。 这两个流算是对各自类别下的流做了一个集成,内部封装有丰富的方法,但实现也稍显复杂,我们先来看这个 PrintStream 字节流: 主要的构造器有这么几个:
- public PrintStream(OutputStream out)
- public PrintStream(OutputStream out, boolean autoFlush)
- public PrintStream(OutputStream out, boolean autoFlush, String encoding)
- public PrintStream(String fileName)
显然,简单的构造器会依赖复杂的构造器,这已经算是 jdk 设计「老套路」了。区别于其他字节流的一点是,PrintStream 提供了一个标志 autoFlush,用于指定是否自动刷新缓存。 接着就是 PrintStream 的写方法:
- public void write(int b)
- public void write(byte buf[], int off, int len)
除此之外,PrintStream 还封装了大量的 print 的方法,写入不同类型的内容到文件中,例如:
- public void print(boolean b)
- public void print(char c)
- public void print(int i)
- public void print(long l)
- public void print(float f)
这些方法并不会真正的将数值的二进制写入文件,而只是将它们所对应的字符串写入文件,例如:
print(123);
最终写入文件的不是 123 所对应的二进制表述,而仅仅是 123 这个字符串,这就是打印流。 PrintStream 使用的缓冲字符流实现所有的打印操作,如果指明了自动刷新,则遇到换行符号「\n」会自动刷新缓冲区。 所以说,PrintStream 集成了字节流和字符流中所有的输出方法,其中 write 方法是用于字节流操作,print 方法用于字符流操作,这一点需要明确。 至于 PrintWriter,它就是全字符流,完全针对字符进行操作,无论是 write 方法也好,print 方法也好,都是字符流操作。 总结一下,我们花了三篇文章讲解了 Java 中的字节流和字符流操作,字节流基于字节完成磁盘和内存之间的数据传输,最典型的就是文件字符流,它的实现都是本地方法。有了基本的字节传输能力后,我们还能够通过缓冲来提高效率。 而字符流的最基本实现就是,InputStreamReader 和 OutputStreamWriter,理论上它俩就已经能够完成基本的字符流操作了,但也仅仅局限于最基本的操作,而构造它们的实例所必需的就是「一个字节流实例」+「一种编码格式」。 所以,字符流和字节流的关系也就如上述的等式一样,你写一个字符到磁盘文件中所必需的步骤就是,按照指定编码格式编码该字符,然后使用字节流将编码后的字符二进制写入文件中,读操作是相反的。
JAVA 的对象序列化
将一个 JAVA 对象所描述的所有内容以文件 IO 的方式写入二进制文件的一个过程。关于序列化,主要涉及两个流,ObjectInputStream 和 ObjectOutputStream。
想要序列化一个对象,JAVA 要求该类必须继承 「java.io.Serializable」接口,而 serializable 接口内并没有定义任何方法,它是一个「标记接口」。
虚拟机执行序列化指令的时候会检查,要序列化的对象所对应的类型是否继承了 Serializable 接口,如果没有将拒绝执行序列化指令并抛出异常。
java.io.NotSerializableException
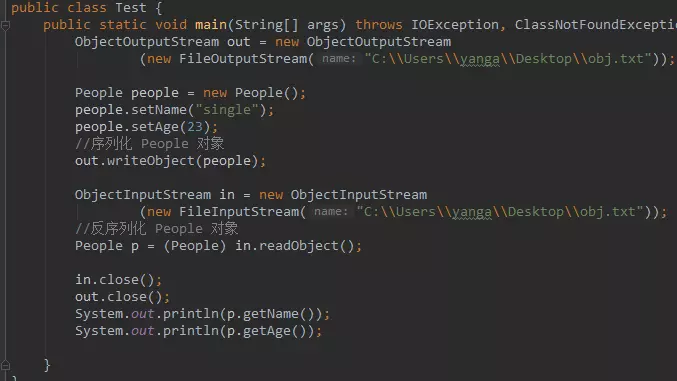
ObjectOutputStream 某种意义上来看也是一种装饰者流,内部所有的字节流操作都依赖我们构造实例时传入的 OutputStream 实例。 这个类的实现很复杂,光内部类就定义了很多,同时它也封装了我们的 DataOutputStream,所以 DataOutputStream 那一套写基本数据类型的方法,这里也有。除此之外的是,它还提供了 DataOutputStream 没有的 writeObject 方法用于将一个继承 Serializable 接口的 Java 对象直接写入磁盘。
writeObject 方法接受一个 Object 参数,并将该参数所代表的 Java 对象序列化进磁盘文件,这里会写入很多东西而不是简简单单的将字段的值写入文件,它是有一个参照格式的,就像我们编译器会按照一定的格式生成字节码文件一样。
序列化的几点高级认识
循环引用的序列化
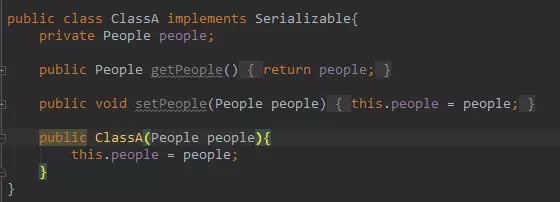
让 ClassA 和 ClassB 的两个对象公用同一个 People 实例,那么有一个问题,我去序列化这两个对象,这个公用的 People 对象会被序列化两次吗?
如果你要序列化的多个对象中,有相同的类类型,Java 只会描述一次该类型,并且如果一份序列化文件中存在对同一对象的多次序列化,Java 也只会保存一份对象数据,后面的都用引用指向这里。
定制序列化
对于所有继承了 Serializable 接口的类而言,进行序列化时,虚拟机会序列化这些类中所有的字段,无视访问修饰符,但是有时候我们并不需要将所有的字段都进行序列化,而只是选择性的序列化其中的某些字段。 我们只需要在不想序列化的字段前面使用 transient 关键字进行修饰即可。
private transient String name;
即便你给你的对象的 name 字段赋值了,最终也不会被保存进文件中,当你反序列化的时候,这个对象的 name 字段依然是系统默认值 null。 除此之外,JAVA 还允许我们重写 writeObject 或 readObject 来实现我们自己的序列化逻辑。 但是这两个方法的声明必须是固定的。
private void writeObject(java.io.ObjectOutputStream s)
private void readObject(java.io.ObjectInputStream s)
没错,它就是 private 修饰的,在你通过 ObjectOutputStream 的 writeObject 方法对某个对象进行序列化时,虚拟机会自动检测该对象所对应的类是否有以上两种方法的实现,如果有,将转而调用类中我们自定的该方法,放弃 JDK 所实现的相应方法。
序列化的版本问题
序列化的版本 ID,我们一直都有提到它,但是始终没有说明这个版本 ID 到底有什么用。用得好的可以拿来实现权限管理机制,用不好也可能导致你反序列化失败。
JAVA 建议每个继承 Serializable 接口的类都应当定义一个序列化版本字段。
private static final long serialVersionUID = xxxxL;
这个值可以理解为是当前类型的一个唯一标识,每个对象在序列化时都会写入外部类型的这个版本号,反序列化时首先就会检查二进制文件中的版本号与目标类型中的版本号是否一样,如果不一样将拒绝反序列化。 这个值不是必须的,如果你不提供,那么编译器将根据当前类的基本信息以某种算法生成一个唯一的序列号,可是如果你的类发生了一点点的改动,这个值就变了,已经序列化好的文件将无法反序列化了,因为你也不知道这个值变成什么了。 所以,JAVA 建议我们都自己来定义这么一个版本号,这样你可以控制已经序列化的对象能否反序列化成功。
