

instagram 是国外非常流行的一款社交网站,类似的还有像facebook、twitter,这些社交网站对于掌握时事热点、电商数据来源和竞争对手的动态信息的把我都是很有数据价值的,所以值钱的数据谁都想获取,那就意味着谁都想保护,那么下面就来聊一聊怎么爬取ins的信息。
一、需求分析:
爬取instagram这个用户的图片、评论数、点赞数、文章内容,存为Json格式
二、站点分析:
首先自行准备翻墙工具,准备好以后,打开instagram官方账号,同时按下F12,如下所示:
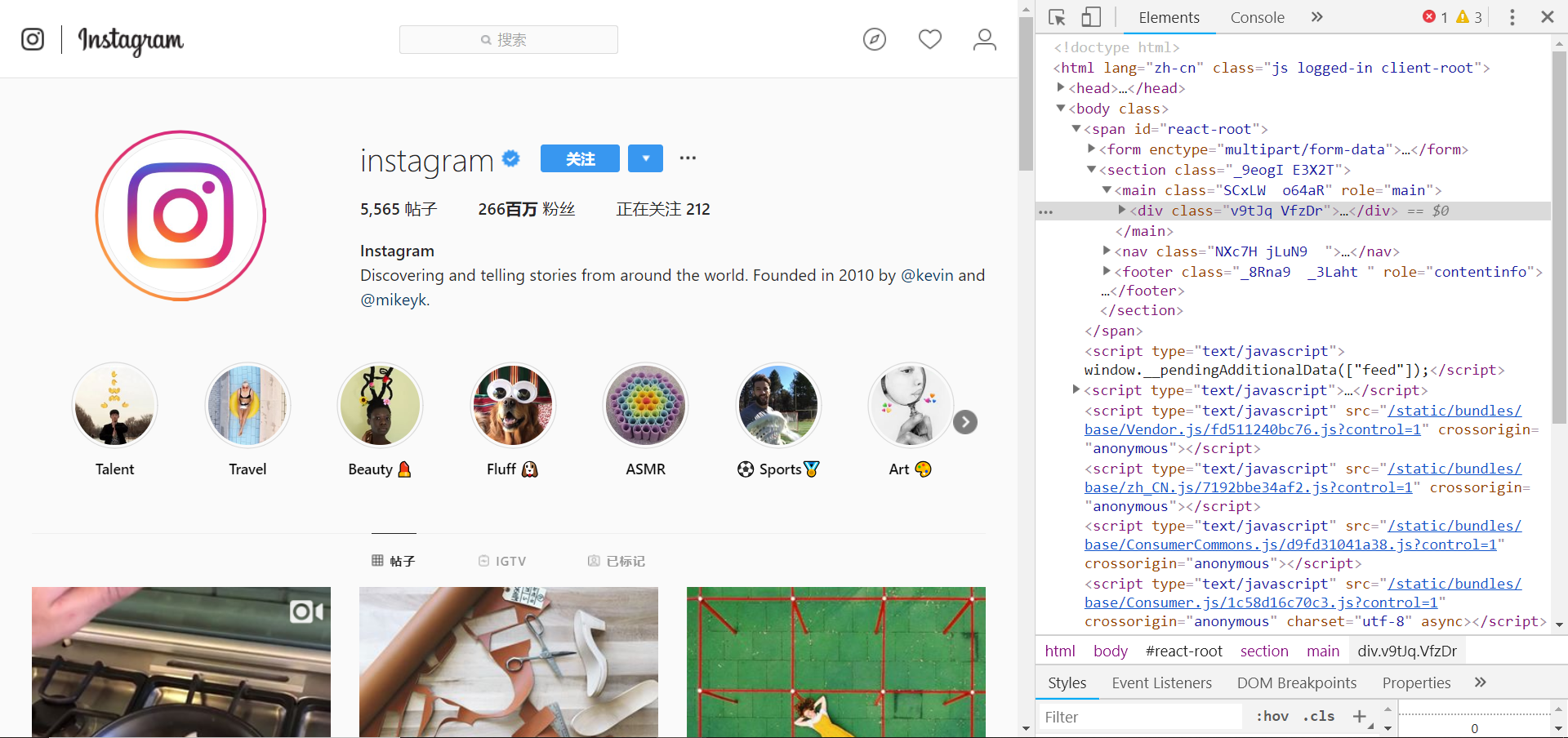
切换到network选项,随便选择一张图片的url,全局搜索,如下图:
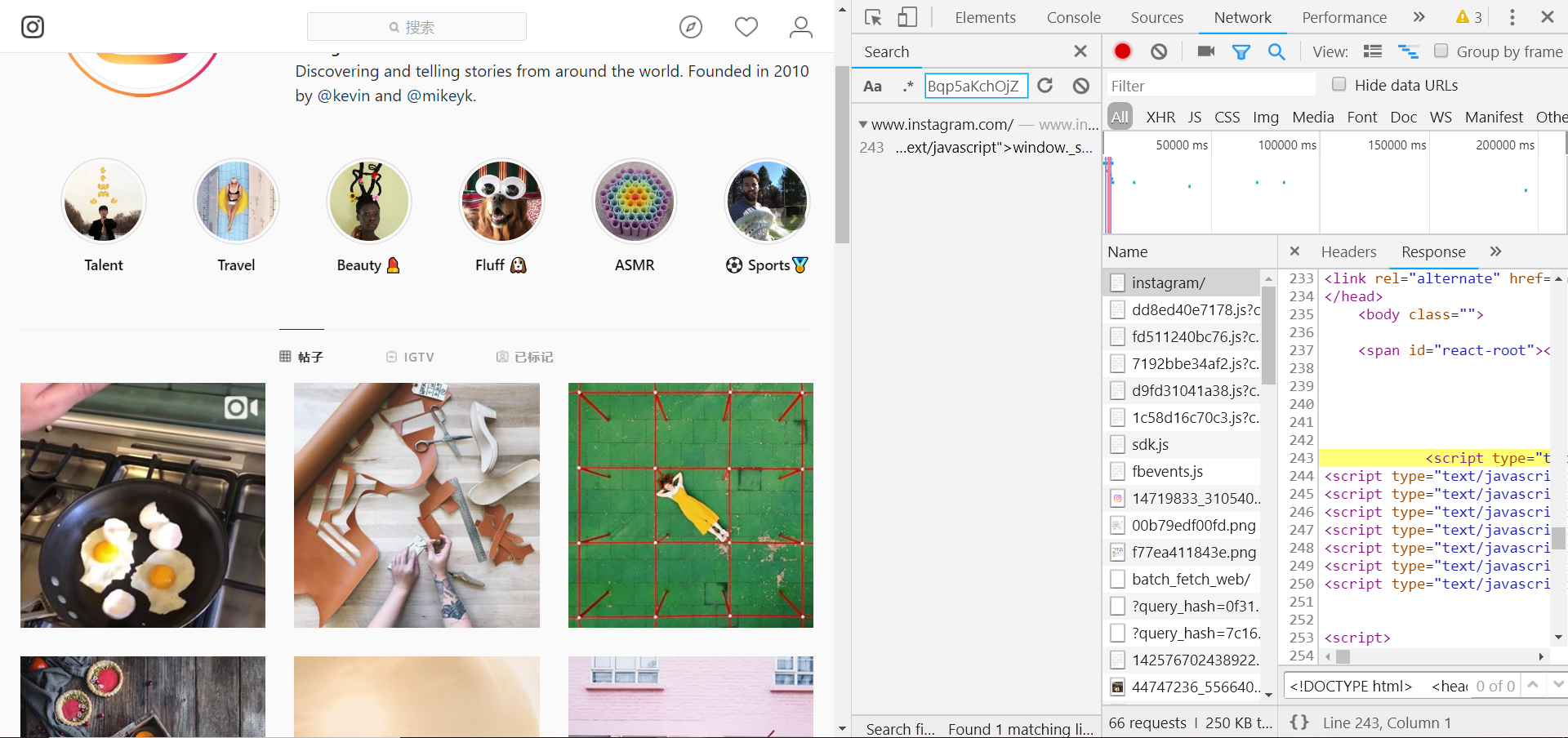
可以发现:instagram把数据写到了script标签里面,这是一种常见的做法,放到js里面去加载,所以我们需要用到正则表达式去做匹配:

解释一下:首先爬取首页的数据,然后正则表达式匹配script标签传来的后台数据,转换成json格式,同时还需要找出user_id和GIS_rhx_gis参数(破解js加密需要用到),最后解析数据。
爬取完首页以后,我们就要爬取下一页的数据了,可以发现下一页的数据是ajax异步加载的方式,返回的是json格式的数据,如下图:
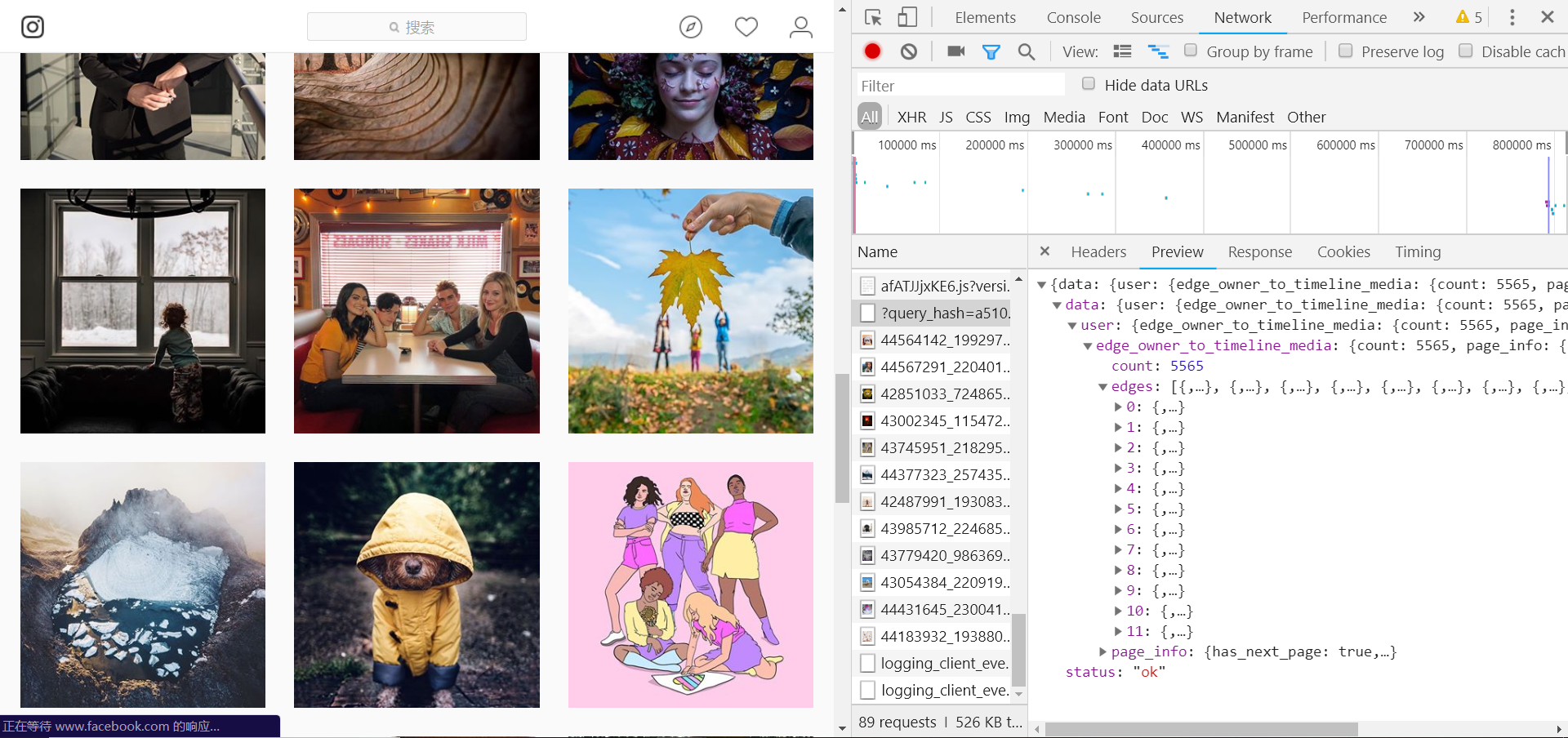
请求的url格式为:
"https://www.instagram.com/graphql/query/?query_hash=5b0222df65d7f6659c9b82246780caa7&variables=%7B\"id\"%3A\"{id}\"%2C\"first\"%3A12%2C\"after\"%3A\"{end_cursor}\"%7D"
经过我测试,发现必须要带上 x-instagram-gis这个参数,否则会报 403 forbideen错误,这是ins的反爬虫机制:
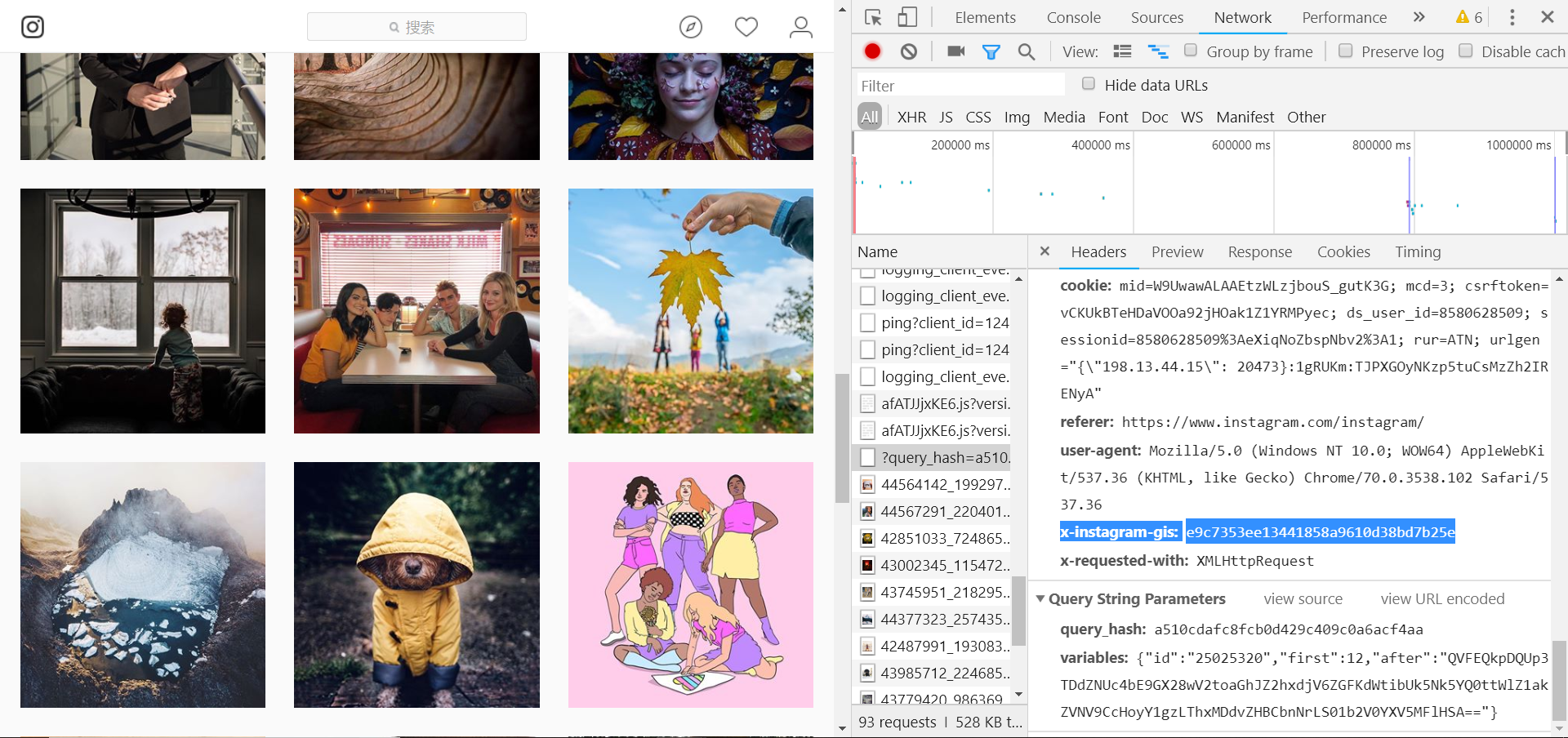
那么如何生成这个参数呢?全局搜索,找到这个参数的js文件,复制一份拷贝到本地,我用的是Pycharm,一路追踪过去,可以找到生成这个参数的方法,我总结为:
1. 从用户首页https://www.instagram.com/instagram/获取user_id、rhx_gis、end_cursor参数
2. variables = '{"id":"' + id + '","first":12,"after":"' + end_cursor + '"}',对 params = rhx_gis + ":" + variables进行md5加密
3. headers加入"x-instagram-gis": params,即可进行抓取
生成这个参数以后,我们就可以下一页的抓取了~
三、源码:
四、最后的话:
如果有帮助的话,可以给个star~,欢迎转发和点赞,转发请注明出处哦
