

数据结构里的平衡多叉树
要理解索引的原理,有个前提,就是要先理解平衡多叉树这种数据结构。
平衡树的作用就是:1.插入数据快(链表的优点) 2.查找数据快(数组的优点)。
也就是说,平衡树这种数据结构兼顾了链表和数组的优点。
多叉就是有多个节点,应用场景是磁盘文件系统。
数据库里的索引
聚簇索引示意图1
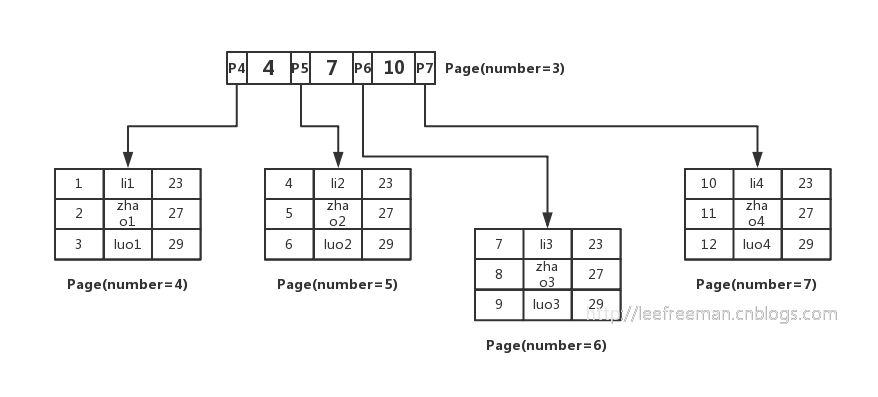
聚集索引示意图2
索引使用的是平衡多叉树这种数据结构。
查找数据的流程:
1.先查找叶子节点(即page页,包含了多个列值)
2.再查找行/记录
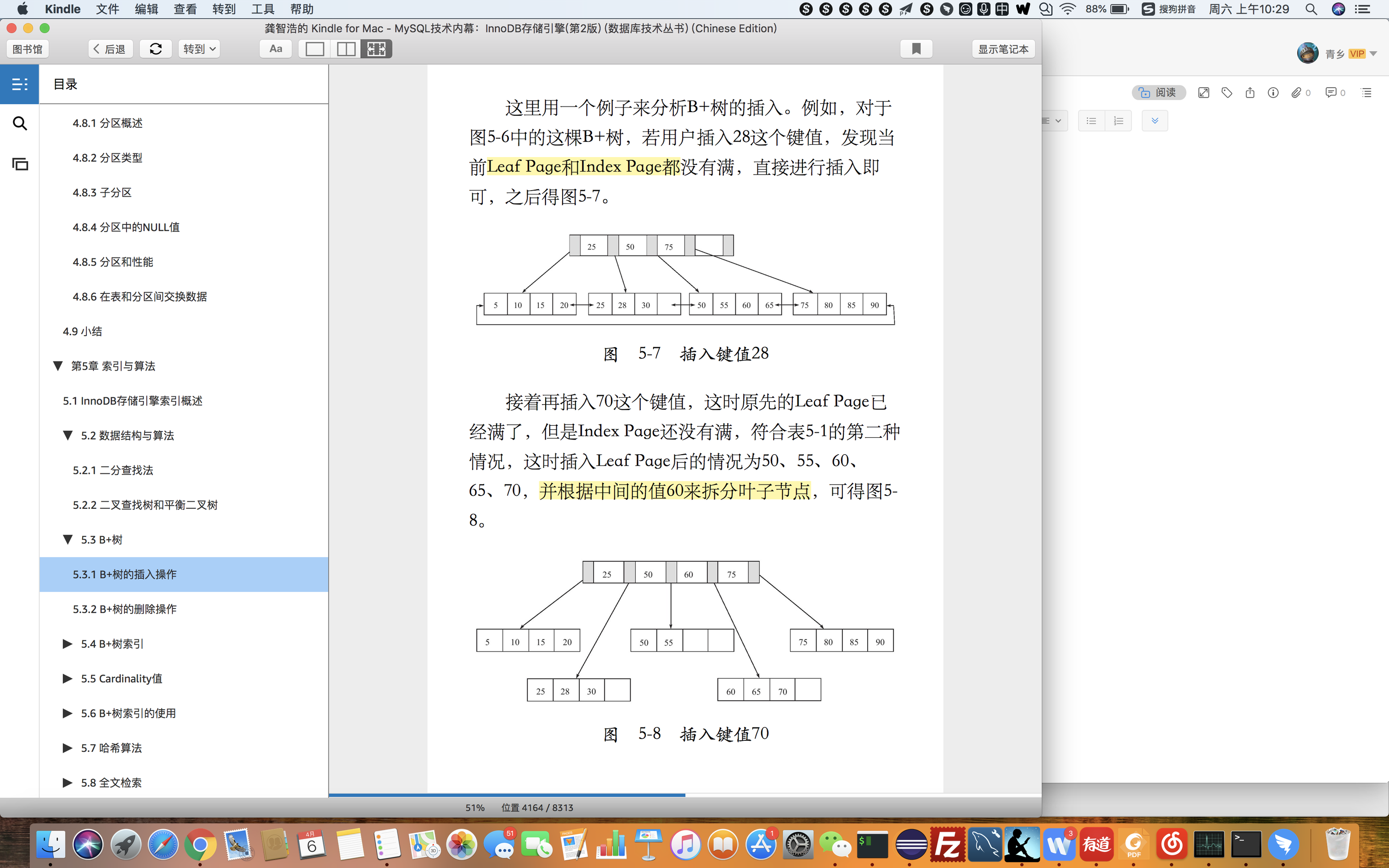
查找叶子节点(即page页)
什么是page页
在mysql innodb存储引擎里,page是最小操作单位,一个page包含了多个行/记录(默认是16KB大小)。
为什么要查找page
索引的叶子节点就是page。page包含了多个列值。我们最终要找的就是某一行记录的列值 所以我们先要找到叶子节点(即page)。
查找步骤
1.先查找非叶子节点
2.最终查找到叶子节点 即page
非叶子节点和叶子节点的区别
我们常说非叶子节点只存储索引 不存储数据 只有叶子节点才存储数据 具体是什么意思?
不管是非叶子节点还是叶子节点,都包含两个内容
1.数据
2.指针
指向其他节点(子节点 兄弟节点)的指针
而非叶子节点和叶子节点的区别在于 存放的数据的不同
1.非叶子节点
存放的也是数据 但是这个数据的作用只是用来索引 即用来查找数据 这个数据并不是我们最终要查找的数据。我们最终要查找的是列值 而列值是存放在叶子节点里(即page页)。
2.叶子节点
我们最终要查找的数据是建立了索引的列的每一行的列值 这个列值是存放在索引的叶子节点 但是每个叶子节点(即page页)包含了多个数据值(每个数据值就是建立了所有的列的某一行的列值)。page的作用是innodb存储引擎在实现索引时为了快速查找数据。
数据从哪里来
上面说了非叶子节点和叶子节点的数据的区别。那么数据是从哪里来?
1.非叶子节点
不同叶子节点的值的中间值
2.叶子节点
就是列值
查找行/记录
mysql把page读写到内存,然后使用二分查找算法查找到行/记录。到此为止,就已经找到了哪一行记录。
page和index-叶子节点的区别?
页和一行记录的关系?
page-数据结构示意图 //存储的时候,是按照page数据结构存储的。
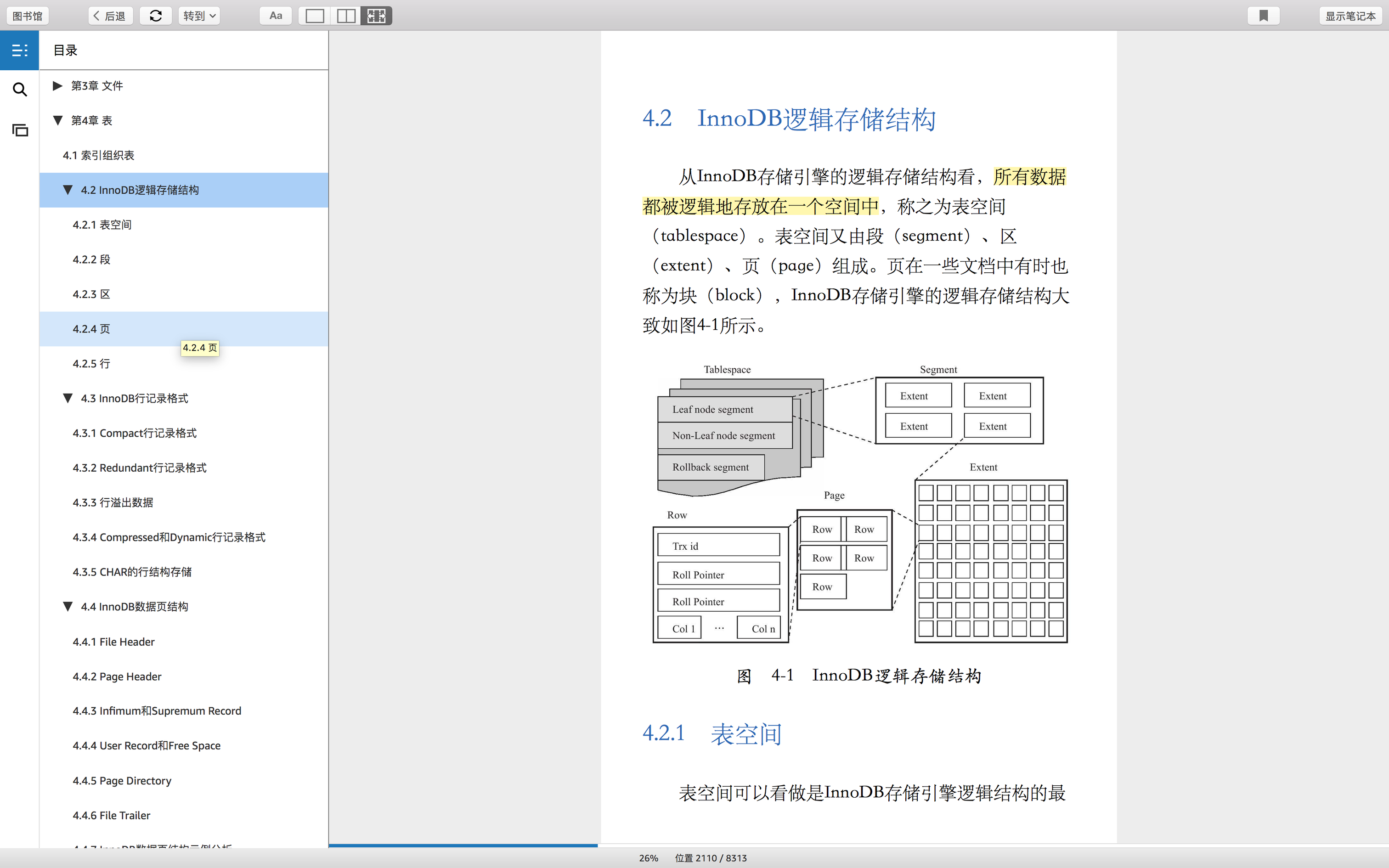
索引-数据结构示意图 //索引查找列的时候,是按索引数据结构查找的,而且只是查找到叶子节点这一层。
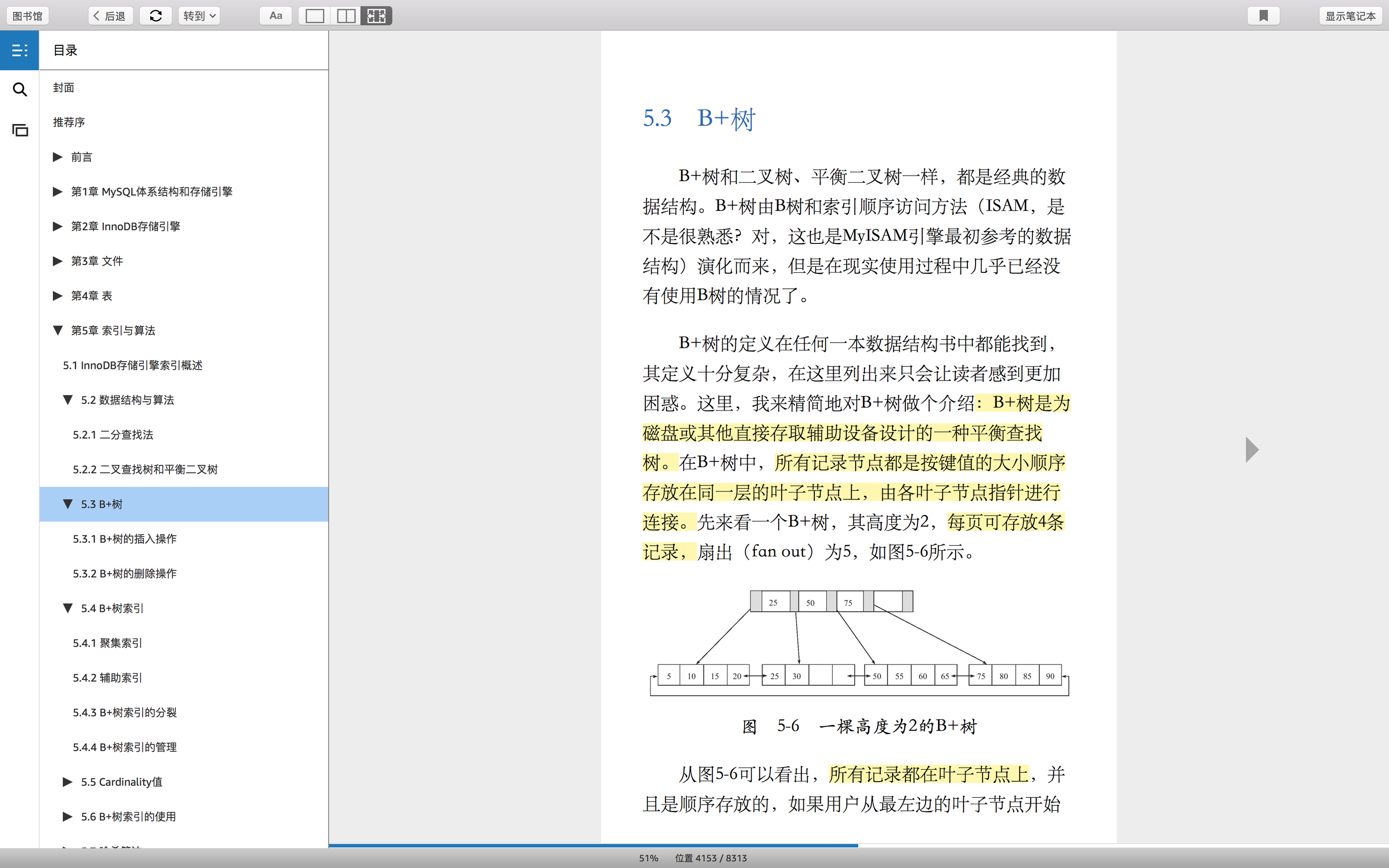
存储的时候,就是按照示意图存储的,说白了,就是上一层总是包含下一层的多个。最终,最小存储单位是page。注意,这个最小存储单位,指的是mysql引擎innoDB的最小存储单位。事实上,page包含了多个记录。
因为page的大小是16KB,一般一行记录是百个字节,所以,一般一个page包含了百个记录。而且,要想查找速度快,page包含的记录数量越多越好,也就是每行记录的数据越小越好。这里有两方面的原因,1.每个page包含的记录数量越多,那么page的数量越少,那么平衡树的查找速度就越快。这是第一点。2.第二点,为什么要每行记录的数据越小越好?因为每行记录的数据越小,那么每个page的记录数量就越多。这也是为什么,设计表的时候,如果一个表的列太多,就把不常用的列和大的列字段放到附加信息表去。
一行记录的数据过大,为什么会导致跨页存储?因为一行记录的列太多/数据太多,导致一行记录跨页存储?
因为page的大小有限是16KB,超过了自然需要多个page来存储数据了。由跨页存储导致的跨页问题,查询速度超级慢,因为相当于索引查询了两次!
page和索引的关系?page和叶子节点的关系?
索引底层使用的数据结构是平衡树-多叉树,专门为磁盘存储查找数据设计的一种树数据结构。
索引的终点是叶子节点,事实上,在索引的实现当中,只有叶子节点才存储真正的数据,其他节点都不存储数据,其他节点的值只是用来查找数据。
最重要的一点,记住,索引的叶子节点就是page。
页到底是包含多个列还是多行记录?叶子节点是包含多个列还是多个记录?
page包含多个记录,不是多个列。
叶子节点是包含多个列的值。
那page和叶子节点,到底是一种什么样的关系?是怎么关联起来的?
索引查找的时候是基于树,目的是查找到哪一个叶子节点。树的叶子节点=page,只是包含的内容稍微有点区别,叶子节点是包含了多个列,page是包含了多个记录,它们的列和记录的数量是一样的,可以说就是一一对应的。
页是叶子节点吗?
叶子节点就是page,可以划等号。索引查找的时候,只是查找到了是那一个叶子节点,也就是哪一个page。到这一步,索引/平衡多叉树的二分查找过程事实上已经结束了。
剩下来的,是在page的内部,查找到具体的哪一行记录,也是使用二分查找算法。但是,现在跟索引的基于树的查找已经没有关系了,现在的查找就是在page的内部按索引列的顺序存储了多个记录,基于二分查找算法找到哪一行记录就完了。
索引-聚集索引和非聚集索引的区别
不同点是叶节点是否存放着一整行数据。 1.聚集索引 //默认 找到索引,然后直接就可以查找一整行记录。
2.非聚集索引 // 查找数据的时候多了一个步骤,就是找到索引之后,还需要查一次数据库。具体细节是怎样的?
就是找到叶子节点---索引字段---主键ID---记录集合里查找。感觉还是不够清楚。
没有一整行记录的索引找到索引字段之后,到底是怎么找到一整行记录的?本质的区别是,一个是找到了叶子节点然后立马在叶子节点里查找索引列和记录行,这样快一点;一个是找到了叶子节点之后,然后找索引列,最后再根据索引列查找记录行。
总的来说,如果放一起,就少了一步;如果分开,就多了一步。
放一起的缺点是,需要空间存放,还有字段值改变之后也需要每次需要更新叶子节点存放的数据,所以索引查找速度快了的,但是有其他的麻烦;而分开,速度慢一点,但是没有其他的麻烦。
聚簇索引示意图
总结
1.主键索引/聚集索引示意图
mysql必须至少有一个聚集索引,1.主键默认且必须是聚集索引 2.非主键默认也是聚集索引 //聚集索引查找的时候,只需要查当前字段的索;非聚集索引除了在自己字段索引找到字段的值,然后还要在主键聚集索引再查找一次找到匹配字段值的记录。总之,一个只需要查找一个索引(聚集索引),一个需要查找两个索引(非聚集索引 + 主键聚集索引)。
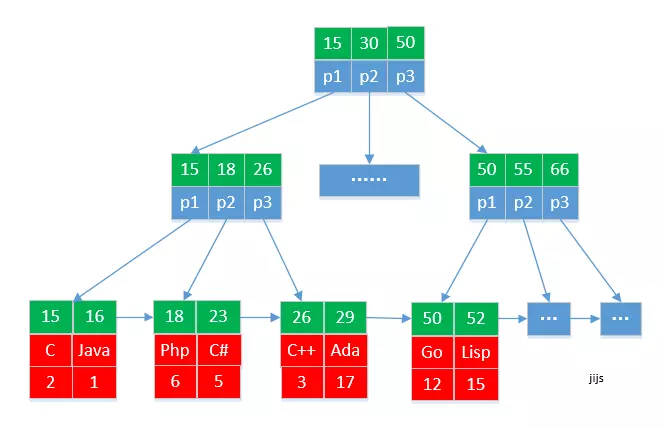
2.非聚集索引/辅助索引/二级索引示意图
参考
www.jianshu.com/p/23524cc57…
blog.csdn.net/bigtree_372…
参考
姜承饶 《mysql技术内幕:innodb存储引擎》
--- B+树的高最多是多少?---
对数
log1000 = 10 //10是怎么计算的?就是2~10次方刚好超过1000,即1024。
同理,log60000 = 10几
log100万 = 20
1000万 = 20几
树高是多少
不是log1000万 = 20几。 //这种计算方法是适合,以2为底(二分查找算法都是以2为底,索引也是一样),并且每个节点只放一个元素。
索引的节点比较特殊,它的节点是page,而不是普通的一个节点(value + pointer)。一个page(16KB)包含多个数据,叶子节点和非叶子节点包含的数据不一样,所以每个page包含了节点的数量也不一样: 1.非叶子节点 //key的type(8个Byte) + pointer(6个字节) = 14个字节 page大小 / 每个节点的大小 = 10000 / 10 = 1000个节点 //这是大概的粗略算法
2.叶子节点 //可能包含了一整行数据,而不仅仅是索引字段的数据 10000 / 1000 = 10KB/1KB = 10个节点 //即10条记录 //【最佳实践】一般的记录都是1KB左右,即几十个字段*几十个字节=1KB。
所以,总数量=1000 * 10 = 10000 //这是树高为2 总数量=1000 * 1000 * 10 = 1000万级别 //这是树高为3。//【最佳实践】而且一般来说,树高都是3
次数
树高是几层,那么就做几次的磁盘io寻址操作。
速度
B+树索引的本质是B+树在数据库中的实现。但是B+树索引有一个特点是高扇出性,因此在数据库中,B+树的高度一般在2到3层。也就是说查找某一键值的记录,最多只需要2到3次IO开销。按磁盘每秒100次IO来计算,查询时间只需20ms/30ms。
树高一层就是10ms,两层就是20ms,三层就是30ms。
面试题-B+和B的区别?
最后回顾一道面试题
有一道MySQL的面试题,为什么MySQL的索引要使用B+树而不是其它树形结构?比如B树?
现在这个问题的复杂版本可以参考本文;
他的简单版本回答是:
因为B树不管叶子节点还是非叶子节点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少(有些资料也称为扇出),指针少的情况下要保存大量数据,只能增加树的高度,导致IO操作变多,查询性能变低;
总结 B+和B本质上是一样的,都是针对磁盘io的多叉平衡树。B+只是在B的基础之上改进了一点点,目的就是为了提高速度,怎么提高速度?减少树高(树高可以和磁盘io次数划等号)。怎么减少树高?非叶子节点的每个page包含更多的节点。怎么包含更多的节点?非叶子节点的每个page只包含索引组织的索引和指针,不包含数据库表记录的字段值,这样的话每个page包含的节点数量就更多。
为什么索引到了1000万量级就很慢
1000万量级的数据,树高也才3,速度也才30ms。不是很慢啊。为什么说1000万就很慢呢?
因为树高是3的时候,数据量级差不多最多就是1000万量级。如果再多,比如亿级别,可能就要树高变为4,速度就是40ms。40ms速度可能看起来还好,但是要考虑到几个方面的问题,每多一层树高,综合起来看就会有很大的影响 1.树高多一层 就多了一次磁盘IO。 2.很多SQL都是嵌套多层子查询这样的复杂SQL语句查询 所以,又翻了倍。 3.数据库内存缓存 会把磁盘的部分数据和索引缓存到内存,从而加快索引速度。如果数据太多,缓存却有限,必然导致走磁盘的读写增多,走内存的读写变少,速度又更慢了。
参考
juejin.cn/post/684490… //慢查询监控系统 1.哪个sql 2.花了几秒 //实现原理是基于数据库的慢查询记录日志文件,然后监控系统就是展示慢查询日志文件的
---索引入门---
不同数据量的不同解决方案?
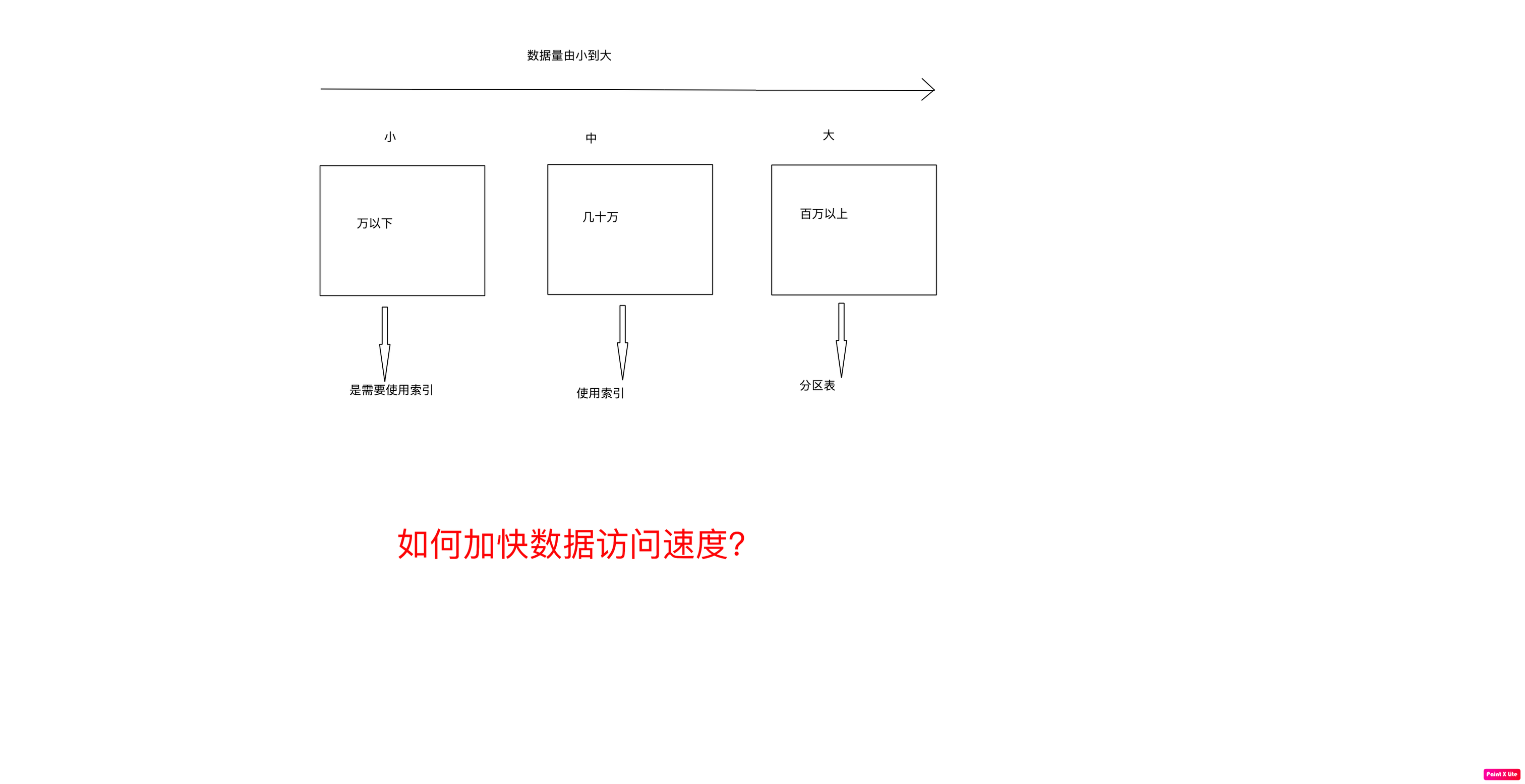
如何使用
1.创建
create index name
on table name(orderId,userId,date); //区别:1.分3次创建3个索引 2.一次创建3个索引 ?
CREATE INDEX employee_idx1 ON employees (last_name, job_id);
CREATE INDEX employee_idx2 ON employees (job_id, last_name); //不同排列顺序的区别?
2.使用
查询时速度快。//如果是查询建立了索引的字段
索引到底是怎么加快查询速度的?
平衡多叉树。
数据结构
B树 //平衡多叉树,磁盘树。
应用场景
被经常查询的字段,即where条件里的字段。
优化索引
为什么需要优化索引?索引有什么问题?
如何优化索引?
主键/唯一键和索引的关系?
Primary and unique keys automatically have indexes, but you might want to create an index on a foreign key
多个索引?会多份数据吗?
会。所以索引占磁盘空间,这是索引不是越多越好,常用查询字段才需要建立索引。
什么样的字段适合建立索引?
数据量大且值不重复,比如一般的字段都是因为这个原因才建立索引的。
数据重复比较多,特别是性别这种字段,只有两个值,那么就不适合建立索引,因为建立索引的目的是为了加快查找的速度。但是数据重复比较多的字段,建立索引起不到这个作用,何况建立索引本身就需要耗费资源(包括cpu、存储资源)。
不适合索引的情况
1.重复值比较多的字段 性别
2.like 特别是前缀有%匹配符
注:比较可以使用索引,即大于 小于 ,因为等于也是比较。
覆盖索引替代回表查询
覆盖索引就是索引字段就是查询字段,而不是多个字段甚至所有字段。
因为如果是查询记录,还要回表查询,特别是非聚集索引。
--- 分页查询 ---
数据量小
1.limit 10 //查询结果集合100条数据,只要前10名
2.方法1 limit 页大小100 起始地址offset0/100/200/9000 //查询结果集合10000条数据,那么每次查询页大小是100条数据,偏移量就是起始地址( 计算方法是offset=pageSize*(第几页pageIndex-1) )
www.liaoxuefeng.com/wiki/117776…
方法2 limit 起始地址0, 页大小100 juejin.cn/post/684490…
持久层框架
mybatis就是对不同的数据库厂商做了一个封装,让程序员在应用程序层面不需要区分不同的数据库。
但是不同的数据库厂商,sql语法是不一样的。比如分页就不一样,mysql是limit offset,而oracle是rownum。
数据量大
在查询起始地址在100万之后的数据,速度也会很慢。
怎么优化?基于子查询,且子查询只查询id这一个字段而不是多个字段/所有自动,且子查询只查询起始地址的第一个数据记录。
步骤
1.子查询
select id
limit 起始地址100万,页大小1
2.外层查询
select 8
from
where id >= 子查询
limit 页大小
参考 segmentfault.com/a/119000000…
claude-ray.github.io/2019/03/11/…
---其他---
sql-分组条件
四、SQL逻辑查询语句执行顺序 (7) SELECT (8) DISTINCT <select_list> (1) FROM <left_table> (3) <join_type> JOIN <right_table> (2) ON <join_condition>
(4) WHERE <where_condition> //分组之前的条件
(5) GROUP BY <group_by_list> (6) HAVING <having_condition> //分组之后的条件
(9) ORDER BY <order_by_condition> (10) LIMIT <limit_number>
作者:itcjj 链接:www.jianshu.com/p/1fa6f5d43… 来源:简书 简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
