

首发于:https://studygolang.com/articles/14481
我在多个场合都被问到为什么使用工作池模式,为什么不在需要的时候启动所需要的 Goroutines ?我的答案一直是:受限于工作的类型、你所拥有的计算资源和所处平台的限制,盲目地使用 Goroutines 将会导致程序运行缓慢,进而伤害整个系统的响应和性能。
每个程序、系统和平台都有短板。不管是内存、CPU 或者带宽资源也都不是无限的。因此对于我们的程序来说,减少资源消耗、重用有限资源是非常重要的。工作池恰好提供了这样一种模式,可以帮助程序管理资源,提供调节资源的选项。
下图展示了工作池的原理:
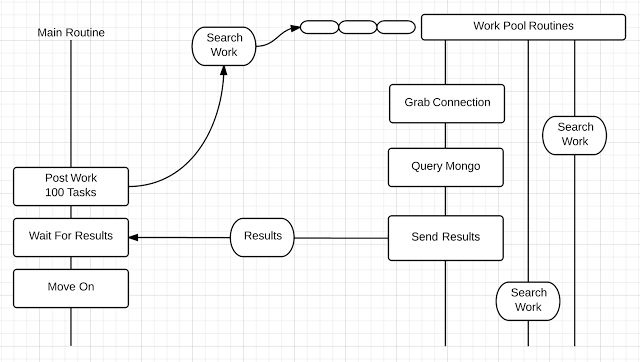
如上图所示,主业务例程提交了100个任务到工作池中。工作池将它们都排入队列,当一个 Goroutine 空闲,工作池从任务队列中取出一个任务分配到此 Goroutine 上,此任务将会得到执行。执行完毕后此 Goroutine 将会再次空闲并等待处理其他任务。Goroutines 的数量和队列的容量是可配置的,这意味着工作池可以用于程序的性能调节。
Go 语言使用 Goroutine 替代了线程。Go 运行环境管理了一个内部的线程池并且在这个池内调度 Goroutines。线程池是最小化 Go 运行环境的负载和最大化程序性能的关键手段。当我们创建了一个新的 Goroutine 时,Go 运行环境将在内部线程池中管理和调度这个 Goroutine。这个原理就和操作系统在空闲的
CPU 核心上调度线程一样。通过 Goroutine 我们可以获得同调度线程池一样的效果,甚至可能更好。
对于处理基于任务的操作我有一个简单的原则:少即是多。我总是想要知道对于特定操作,最好的结果需要的 Goroutines 的最小值是多少。最好的结果不仅仅是全部的任务需要花费多长时间来完成,同样还包括处理这些任务对程序、系统和平台所产生的影响。你必须同时考虑到短期影响和长期影响。
在系统或程序负载较轻的情况下,我们很容易就能获取到非常快的处理速度。但是某天系统负荷的轻微增加就会导致之前的配置不起作用,而我们并没有意识到正是我们在严重伤害和我们交互的系统。我们可能把数据库或者网络服务器用的太狠了,最终造成了系统的宕机。突发的100个并发任务可以运行正常,但是持续一个小时的并发可能就是致命的。
工作池并不是可以解决全世界运算问题的魔力仙女,它却可以用在你的程序中处理基于任务的操作。它可以根据你的系统表现提供配置选项和控制功能。随着系统变化,你也有足够的灵活度来改变。
现在让我们举个例子来证明在处理基于任务的操作方面工作池要比盲目的产生 Goroutines 更有效率。我们的测试程序运行某一个任务,它会获取一个 MongoDB 的连接,在数据库上执行查询命令并返回数据。一般的业务中都会有类似的功能。这个测试程序将会提交100个任务到工作池中,运行5次后统计平均运行时间。
打开终端,运行如下的命令来下载代码:
1 export GOPATH=$HOME/example2 go get github.com/goinggo/workpooltest3 cd $HOME/example/bin我们创建一个包含 100 个 Goroutines 的工作池,用它来模拟盲目的根据任务数产生相同数量的 Goroutine 的模型。
1 ./workpooltest 100 off第一个参数告诉程序创建100个 Goroutines 的工作池,第二个参数告诉程序关闭详细的日志输出。
在我的 Macbook 上,运行上面这个命令的结果是:
1 CPU[8] Routines[100] AmountOfWork[100] Duration[4.599752] MaxRoutines[100] MaxQueued[3]2 CPU[8] Routines[100] AmountOfWork[100] Duration[5.799874] MaxRoutines[100] MaxQueued[3]3 CPU[8] Routines[100] AmountOfWork[100] Duration[5.325222] MaxRoutines[100] MaxQueued[3]4 CPU[8] Routines[100] AmountOfWork[100] Duration[4.652793] MaxRoutines[100] MaxQueued[3]5 CPU[8] Routines[100] AmountOfWork[100] Duration[4.552223] MaxRoutines[100] MaxQueued[3]6 Average[4.985973]输出结果中的参数含义:
CPU[8] : The number of cores on my machineRoutines[100] : The number of routines in the work poolAmountOfWork[100] : The number of tasks to runDuration[4.599752] : The amount of time in seconds the run tookMaxRoutines[100] : The max number of routines that were active during the runMaxQueued[3] : The max number of tasks waiting in queued during the run现在让我们运行 64 个 Goroutines 的工作池:
CPU[8] Routines[64] AmountOfWork[100] Duration[4.574367] MaxRoutines[64] MaxQueued[35]CPU[8] Routines[64] AmountOfWork[100] Duration[4.549339] MaxRoutines[64] MaxQueued[35]CPU[8] Routines[64] AmountOfWork[100] Duration[4.483110] MaxRoutines[64] MaxQueued[35]CPU[8] Routines[64] AmountOfWork[100] Duration[4.595183] MaxRoutines[64] MaxQueued[35]CPU[8] Routines[64] AmountOfWork[100] Duration[4.579676] MaxRoutines[64] MaxQueued[35]Average[4.556335]接着是 24 个 Goroutines 的结果:
CPU[8] Routines[24] AmountOfWork[100] Duration[4.595832] MaxRoutines[24] MaxQueued[75]CPU[8] Routines[24] AmountOfWork[100] Duration[4.430000] MaxRoutines[24] MaxQueued[75]CPU[8] Routines[24] AmountOfWork[100] Duration[4.477544] MaxRoutines[24] MaxQueued[75]CPU[8] Routines[24] AmountOfWork[100] Duration[4.550768] MaxRoutines[24] MaxQueued[75]CPU[8] Routines[24] AmountOfWork[100] Duration[4.629989] MaxRoutines[24] MaxQueued[75]Average[4.536827]最后是 8 个 Goroutines:
CPU[8] Routines[8] AmountOfWork[100] Duration[4.616843] MaxRoutines[8] MaxQueued[91]CPU[8] Routines[8] AmountOfWork[100] Duration[4.477796] MaxRoutines[8] MaxQueued[91]CPU[8] Routines[8] AmountOfWork[100] Duration[4.841476] MaxRoutines[8] MaxQueued[91]CPU[8] Routines[8] AmountOfWork[100] Duration[4.906065] MaxRoutines[8] MaxQueued[91]CPU[8] Routines[8] AmountOfWork[100] Duration[5.035139] MaxRoutines[8] MaxQueued[91]Average[4.775464]让我们收集一下这几个运行结果:
100 Go Routines : 4.985973 :64 Go Routines : 4.556335 : ~430 Milliseconds Faster24 Go Routines : 4.536827 : ~450 Milliseconds Faster8 Go Routines : 4.775464 : ~210 Milliseconds Faster上述测试结果告诉我们如果单核运行 3 个 Goroutines 将获得最好的结果。3 似乎是个神奇的数字,这个配置在我写的每个 Go 程序中都会产生很好的结果。如果我们运行的程序拥有更多的核心,我们可以简单地增加 Goroutines 的数量来充分利用更多的资源和能耗。这就意味着如果 MongoDB 可以处理多出来的连接,那么我们总归可以调整工作池的尺寸和容量来获取最优结果。
我们已经证明了对于特定的操作,每个任务都盲目的产生 Goroutines 并不是最好的解决方案。我们来看看工作池的代码是怎么工作的:
工作池的代码可以在你下载的代码路径中找到:
cd $HOME/example/src/github.com/goinggo/workpoolworkpool.go 这个文件中包含了所有的代码。我移除了全部的注释和部分代码行使我们聚焦在重要的部分。
我们首先看看构建工作池的类型:
1 type WorkPool struct {2 shutdownQueueChannel chan string3 shutdownWorkChannel chan struct{}4 shutdownWaitGroup sync.WaitGroup5 queueChannel chan poolWork6 workChannel chan PoolWorker7 queuedWork int328 activeRoutines int329 queueCapacity int3210 }11 12 type poolWork struct {13 Work PoolWorker14 ResultChannel chan error15 }16 17 type PoolWorker interface {18 DoWork(workRoutine int)19 }WorkPool 是代表工作池的公共类型。它实现了两个 channel。
WorkChannel 处于工作池的核心位置,它管理着需要处理的工作队列。所有 vGoroutines 都会等待这个 channel 的信号。
QueueChannel 用于管理提交工作到 WorkChannel。 QueueChannel 将工作是否进入队列的确认提供给调用方,它同时负责维护 QueuedWork 和 QueuedCapacity 这两个计数器。
PoolWork 结构体定义了发送给 QueueChannel 用于处理进入队列请求的数据。它包含了涉及到用户 PoolWorker 对象的接口和一个接收任务已经进入队列的确认的 channel。
PoolWorker 的接口定义了 DoWork 函数,其中的一个参数代表了运行此任务的 Goroutines 的内部 id。此 id 对于记录日志和其他针对 Goroutines 级别的事务都很有帮助。
PoolWorker 接口是工作池中用于接收和运行任务的核心。让我们看一个简单的客户端实现:
1 type MyTask struct {2 Name string3 WP *workpool.WorkPool4 }5 6 func (mt *MyTask) DoWork(workRoutine int) {7 fmt.Println(mt.Name)8 9 fmt.Printf("*******> WR: %d QW: %d AR: %d\n",10 workRoutine,11 mt.WP.QueuedWork(),12 mt.WP.ActiveRoutines())13 14 time.Sleep(100 * time.Millisecond)15 }16 17 func main() {18 runtime.GOMAXPROCS(runtime.NumCPU())19 20 workPool := workpool.New(runtime.NumCPU() * 3, 100)21 22 task := MyTask{23 Name: "A" + strconv.Itoa(i),24 WP: workPool,25 }26 27 err := workPool.PostWork("main", &task)28 29 …30 }我创建了一个 MyTask 的类型,它定义了工作执行的状态。接着我实现一个 MyTask 的函数成员 DoWork,它同时符合 PoolWorker 接口的签名。由于 MyTask 实现了 PoolWorker 的接口,MyTask 类型的对象也被认为是 PoolWorker 类型的对象。现在我们把MyTask类型的对象传入 PostWork 方法中。
要学习更多的 Go 语言中接口和基于对象编程,可以参考如下链接:
https://www.ardanlabs.com/blog/2013/07/object-oriented-programming-in-go.html
我设置 Go 运行环境使用我本机上的全部 CPU和核心,我创建了一个 24 个 Goroutines 的工作池。我本机有 8 个核心,就像上面我们得到的结论,每个核心分配 3 个 Goroutines是比较好的配置。最后一个参数是告诉工作池创建一个容量为 100 个任务的队列。
接着我创建了一个 MyTask 的对象并且提交到队列中。为了记录日志,PostWork 方法的第一个参数可以设置成调用方的名称。如果调用返回的 err 参数是空,表明此任务已经得到提交;如果非空,大概率意味着已经超过了队列的容量,你的任务未能得到提交。
我们到代码内部看看 WorkPool 对象是如何被创建和启动的:
1 func New(numberOfRoutines int, queueCapacity int32) *WorkPool {2 workPool = WorkPool{3 shutdownQueueChannel: make(chan string),4 shutdownWorkChannel: make(chan struct{}),5 queueChannel: make(chan poolWork),6 workChannel: make(chan PoolWorker, queueCapacity),7 queuedWork: 0,8 activeRoutines: 0,9 queueCapacity: queueCapacity,10 }11 12 for workRoutine := 0; workRoutine < numberOfRoutines; workRoutine++ {13 workPool.shutdownWaitGroup.Add(1)14 go workPool.workRoutine(workRoutine)15 }16 17 go workPool.queueRoutine()18 return &workPool19 }我们看到在上面的客户端示例代码中 Goroutines 的数量和队列长度被传入 New 函数。WorkChannel 是一个缓冲 channel,是用于储存需要处理的工作的队列。 QueueChannel是一个非缓冲channel,用于同步对 WorkChannel 缓冲区的访问并维护计数器。
要学习更多关于缓冲和非缓冲 channel的知识,请访问此链接:
http://golang.org/doc/effective_go.html#channels
当 channel 初始化完毕后,我们就可以去创建 Goroutines 了。首先我们对每个Goroutine 的 WaitGroup加1来关闭它们。接着创建 Goroutines。最后开启 QueueRoutine 来接收工作。
要学习关闭Goroutines的代码和 WaitGroup是如何工作的,请阅读此链接:
http://dave.cheney.net/2013/04/30/curious-channels
关闭工作池的实现如下所示:
1 func (wp *WorkPool) Shutdown(goRoutine string) {2 wp.shutdownQueueChannel <- "Down"3 <-wp.sutdownQueueChannel4 5 close(wp.queueChannel)6 close(wp.shutdownQueueChannel)7 8 close(wp.shutdownWorkChannel)9 wp.shutdownWaitGroup.Wait()10 11 close(wp.workChannel)12 }Shutdown函数首先关闭 QueueRoutine,这样就不会接收更多的请求。接着关闭 ShutdownWorkChannel,并等待每个 Goroutine去对WaitGroup 计数器做减操作。一旦最后一个Goroutine 调用了 Done函数,等待函数 Wait 将会返回,工作池将会被关闭。
现在让我们看看 PostWork 和 QueueRoutine 函数:
1 func (wp *WorkPool) PostWork(goRoutine string, work PoolWorker) (err error) {2 poolWork := poolWork{work, make(chan error)}3 4 defer close(poolWork.ResultChannel)5 6 wp.queueChannel <- poolWork7 return <-poolWork.ResultChannel8 }9 func (wp *WorkPool) queueRoutine() {10 for {11 select {12 case <-wp.shutdownQueueChannel:13 wp.shutdownQueueChannel <- "Down"14 return1516 case queueItem := <-wp.queuechannel:17 if atomic.AddInt32(&wp.queuedWork, 0) == wp.queueCapacity {18 queueItem.ResultChannel <- fmt.Errorf("Thread Pool At Capacity")19 continue20 }2122 atomic.AddInt32(&wp.queuedWork, 1)2324 wp.workChannel <- queueItem.Work2526 queueItem.ResultChannel <- nil27 break28 }29 }30 }PostWork 和 QueueRoutine 函数背后的思想是把对 WorkChannel 缓冲区的访问串行化,保证队列顺序和维护计数器。当工作被提交到 channel 的时候,Go运行环境保证它总是会被置于 WorkChannel 的末尾。
当 QueueChannel 收到信号,QueueRoutine 将会接收到一项工作。代码先检查队列是否还有空位,如果有 PoolWorker 的对象将排入 WorkChannel 的缓冲区。当所有的事务都排入队列后,调用方将获得返回结果。
我们来看一下 WorkRoutine 的函数:
1 func (wp *WorkPool) workRoutine(workRoutine int) {2 for {3 select {4 case <-wp.shutdownworkchannel:5 wp.shutdownWaitGroup.Done()6 return78 case poolWorker := <-wp.workChannel:9 wp.safelyDoWork(workRoutine, poolWorker)10 break11 }12 }13 }14 func (wp *WorkPool) safelyDoWork(workRoutine int, poolWorker PoolWorker) {15 defer catchPanic(nil, "workRoutine", "workpool.WorkPool", "SafelyDoWork")16 defer atomic.AddInt32(&wp.activeRoutines, -1)1718 atomic.AddInt32(&wp.queuedWork, -1)19 atomic.AddInt32(&wp.activeRoutines, 1)2021 poolWorker.DoWork(workRoutine)22 }Go 运行环境通过向空闲中的 Goroutine 对应的 WorkChannel 发送信号的方式给 Goroutine 分配工作。当 channel 接收到信号,Go 运行环境将会把channel 缓冲区的第一个任务传给 Goroutine 来处理。这个 channel的缓冲区就像是一个先入先出的队列。
如果全部的Goroutines都处于忙碌状态,那所有的剩下的工作都要等待。只要一个 routine完成它被分配的工作,它就会返回并继续等待 WorkChannel的通知。如果 channel的缓冲区有工作,那 Go运行环境将会唤醒这个Goroutine。
代码使用了 SafelyDo 模式,因为代码会调用处于用户模式下的代码,存在崩溃的可能,而你肯定不希望Goroutine跟着一起停止工作。注意第一个 defer的声明,它将会捕获任何的崩溃,保持代码的持续运行。
其他部分的代码会安全的增加或减少计数器,通过接口调用用户模式下的部分。
要学习更多捕获崩溃的知识请阅读如下的文章:
https://www.ardanlabs.com/blog/2013/06/understanding-defer-panic-and-recover.html
这就是代码的核心以及它如何实现了这样的模式。WorkPool优雅的展示了 channel 的使用。我可以使用很少量的代码来处理工作。增加队列的保证机制和计数器的维护都只是小菜一碟。
请从GoingGo 的代码仓库下载代码并且亲自试试吧。
via: https://www.ardanlabs.com/blog/2013/09/pool-go-routines-to-process-task.html
作者:William Kennedy 译者:lebai03 校对:polaris1119
本文由 GCTT 原创编译,Go语言中文网 荣誉推出

