

以下问题基本针对于大厂一面和中等公司的一面二面,更多关于项目里的问题还需根据自身参考。
一、html
1.html5新增的特性?
语义标签,增强型表单,视频和音频,Canvas绘图,SVG绘图,地理定位,拖放API,Web Worker。
2.BFC?
一块独立渲染区域。以下会形成BFC:
- 根元素
- float属性不为none
- position为absolute或fixed
- display为inline-block, table-cell, table-caption, flex, inline-flex
- overflow不为visible
作用:防止margin重叠,自适应两栏布局,清除内部浮动。
3.浏览器渲染过程?
- 解析HTML生成DOM树。
- 解析CSS生成CSSOM规则树。
- 将DOM树与CSSOM规则树合并在一起生成渲染树。
- 遍历渲染树开始布局,计算每个节点的位置大小信息。
- 将渲染树每个节点绘制到屏幕。
二、css
1.css居中
水平居中:text-align:center,,flex,position:absolute+transform
垂直居中:line-height,flex,position:absolute+transform,table-cell
水平垂直居中:flex,position:absolute+transform.
2.absolute和relative,fixed的区别
static 是默认值relative 相对定位 相对于自身原有位置进行偏移,仍处于标准文档流中absolute 绝对定位 相对于最近的已定位的祖先元素, 有已定位(指position不是static的元素)祖先元素, 以最近的祖先元素为参考标准。如果无已定位祖先元素, 以body元素为偏移参照基准, 完全脱离了标准文档流。fixed 固定定位的元素会相对于视窗来定位,这意味着即便页面滚动,它还是会停留在相同的位置。一个固定定位元素不会保留它原本在页面应有的空隙。3.display:none和visibility:hidden区别
display:none指的是元素完全不陈列出来,不占据空间,涉及到了DOM结构,故产生reflow与repaint
visibility:hidden指的是元素不可见但存在,保留空间,不影响结构,故只产生repaint(脱离文档流)
4.选择器优先级,以及选择器的叠加算法。
!important>inline>ID>class>tag
- 第一等级:代表内联样式,如style="",权值为 1000
- 第二等级:代表id选择器,如#content,权值为100
- 第三等级:代表类,伪类和属性选择器,如.content,权值为10
- 第四等级:代表标签选择器和伪元素选择器,如div p,权值为1
三、javascript基础
1.深拷贝与浅拷贝
这个问题呢,基本上是必问的。所以这一题,我们从js的变量说起,从内存空间说起:
其中,JavaScript中变量类型有两种:
- 基础类型(
Undefined, Null, Boolean, Number, String, Symbol)一共6种 - 引用类型(
Object)
基础类型的值保存在栈中,这些类型的值有固定大小,"按值来访问";
引用类型的值保存在堆中,栈中存储的是引用类型的引用地址(地址指针),"按引用访问",引用类型的值没有固定大小,可扩展(一个对象我们可以添加多个属性)。
因此进行拷贝的时候便分为两种拷贝:
- "浅拷贝:栈存储拷贝
- "深拷贝:堆存储拷贝
2.对执行上下文的理解
关于js执行上下文:
执行上下文(Execution Context): 函数执行前进行的准备工作(也称执行上下文环境)
js中执行上下环境(上下文):
- 全局执行上下环境
- 函数执行上下环境
- eval函数环境
因为js是单线程,因此,js代码执行就类似于出栈,入栈过程。js中,全局永远在栈底,代码示例:
function foo () {
function bar () {
return 'I am bar';
}
return bar();
}
foo();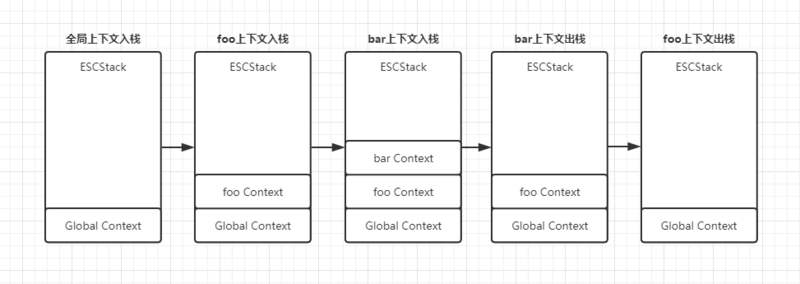
从这里可以看出执行上下文的生命周期:
- 创建阶段(进入执行上下文)
- 执行阶段(代码执行)
关于上下文不同阶段的作用可参考这篇文章
3.什么是原型链?什么是作用域?什么是闭包?js继承的几种方式?
什么是原型:
每个函数默认都有一个 prototype 属性,它就是我们所说的 "原型",或称 "原型对象"。每个实例化创建的对象都有一个 __proto__ 属性(隐式原型),它指向创建它的构造函数的 prototype 属性。
什么是原型链:(基本是基于构造函数)
访问一个对象的属性时,会先在其基础属性上查找,找到则返回值;如果没有,会沿着其原型链上进行查找,整条原型链查找不到则返回 undefined。这就是原型链查找。
function a(){};
a.prototype.name = "追梦子";
var b = new a();
console.log(b.name); //追梦子因此从原型我们可以谈到继承:
1.原型继承
// 创建父类一个类
function Father(name){
//属性
this.name = name || 'father'
// 实例方法
this.run = function(){
console.log(this.name + '正在跑步!');
}
}
//原型上的方法
Father.prototype.sayName = function() {
console.log(this.name+'正在跑步');
}
//原型链继承
function Son(){
this.subName = '儿子'
}
// 创建Son的实例,并将原型指向Father
Son.prototype = new Father()
Son.prototype.saySubName = function() {
console.log(this.subName+'正在跑步');
}
var son = new Son()
console.log(son.sayName()) // father正在跑步
console.log(son) //可以看看son的原型指向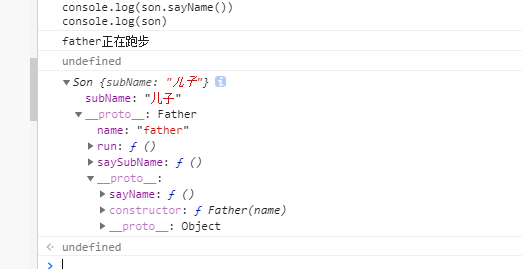
// 创建父类一个类
function Father(name){
//属性
this.color = ['r','e']
}
//原型链继承
function Son(){}
Son.prototype = new Father()
var sonOne = new Son()
sonOne.color.push('d')
console.log(sonOne.color)//["r", "e", "d"]
var sonTwo = new Son()
console.log(sonTwo.color)//["r", "e", "d"]
特点:基于原型链,既是父类的实例,也是子类的实例
缺点:对于上 引用型值的继承容易造成所有实例共享2.构造函数继承
// 创建父类一个类
function Father(name){
//属性
this.color = name || ['r','e']
}
//原型上的方法
Father.prototype.sayColors = function() {
console.log(this.color);
}//构造函数继承
function Son(){
Father.call(this) //只有函数才会有call,apply,bind
}
// 实例1
var sonOne = new Son()
// 实例二
var sonTwo = new Son()
sonOne.color.push('d')
console.log(sonOne.color)//["r", "e", "d"]
console.log(sonTwo.color)// ["r", "e"]
console.log(sonTwo)
console.log(sonTwo instanceof Son) // true
console.log(sonTwo instanceof Father) //false
console.log('是否继承了原型上方法', sonTwo.sayColors()) // error
特点: 可以实现多继承
缺点:只能继承父类实例的属性和方法,不能继承原型上的属性和方法,并且复用性太弱。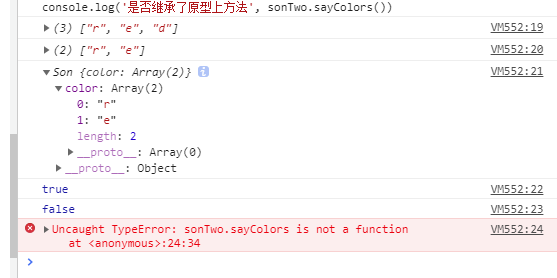
3.组合式继承:(原型继承+构造继承)
function Father(colors){
//属性
this.color = colors || ['r','e']
}
//原型上的方法
Father.prototype.sayColors = function() {
console.log(this.color);
}
//构造函数继承
function Son(name, color){
Father.call(this, color) //第二次调用Father()
this.name = name
this.sayName = function(){
console.log(this.name)
}
}
Son.prototype = new Father() //第一次调用Father()
var sonOne = new Son('儿子1', ['r','e', 'd'])
sonOne.sayColors() //["r", "e", "d"]
sonOne.sayName() //儿子1
var sonTwo = new Son('儿子2', ['g','r', 'e'])
sonTwo.sayColors() //["g", "r", "e"]
sonTwo.sayName() //儿子2
console.log(sonTwo) //以下图片是sonTwo
特点:既继承了实例的属性和方法,也继承了原型上的属性和方法
缺点:调用了两次父类构造函数,生成了两份实例

4.寄生式组合继承(不进行两次调用,直接将父类原型复制给子类原型)
function Father(colors){
//属性
this.color = colors || ['r','e']
}
//原型上的方法
Father.prototype.sayColors = function() {
console.log(this.color);
}
//构造函数继承
function Son(name, colors){
Father.call(this, colors)
this.name = name
this.sayName = function(){
console.log(this.name)
}
}
function jisheng(subPro,superPro){
let pro = Object(superPro)
pro.constructor = subPro
subPro.prototype = pro }
jisheng(Son,Father)
var sonOne = new Son('儿子1', ['r','e', 'd'])
sonOne.sayColors() // ['r','e', 'd']
sonOne.sayName() // 儿子1
var sonTwo = new Son('儿子2', ['g','r', 'e'])
sonTwo.sayColors() // ['g','r', 'e']
sonTwo.sayName() // 儿子2
console.log(sonTwo) //以下是sonTwo的截图
什么是作用域:(针对变量)
相当于针对这些变量的访问权限的合集。(相当于一个省(全局作用域)下的各种市,县。。。都有不同的地盘)
var globaValue = '我是省作用域';
function chengdu() {
var fooValue = '我是chengdu作用域'; function wuhou() {
var barValue = '我是wuhou作用域'; }
}
function mianyang() {
var otherValue = '我是mianyang作用域';
}什么是作用域链:和原型链一样,是一个查找过程
var a = 1;
var b = 2;
function b(){
var a = 2;
function c(){
var a = 3;
console.log(a);
console.log(b);
} c();
}
b();//3 2
当在c的作用域中找到a,就停止查找,打印a,继续向上找b,b函数的作用域中没有b,
则继续沿着作用域链往上找,在全局中找到b。因此从作用域我们可以谈到闭包:闭包就是指有权访问另一个函数作用域中的变量的函数。
// 以下就是闭包的应用
function test(){
var arr = [];
for(var i = 0;i < 10;i++){ //i是在test作用域里
arr[i] = function(){ //函数二作用域
return i;
};
}
for(var a = 0;a < 10;a++){
console.log(arr[a]());
}
}
test(); //打印10个10,因为i在test执行的时候最后 for循环遍历i变为10,因此在函数二的作用域中没有i,
就向上找。
//变量被保存在了内存中function test(){
var a = 1
return function(){
a++
console.log(a)
}
}
var func = test()
func() // 2
func() // 3
//闭包中的this指向
var name = "The Window";
var obj = {
name: "My Object",
getName: function(){
return function(){
return this.name;
};
}
};
console.log(obj.getName()()); // 实际上是在全局作用域中调用了匿名函数,this指向了window。
//这里要理解函数名与函数功能(或者称函数值)是分割开的,不要认为函数在哪里,
//其内部的this就指向哪里。匿名函数的执行环境具有全局性,因此其 this 对象通常指向 window。4.new做了什么?
1. 创建一个新的对象,this变量引用该对象,同时还继承了该函数的原型
2. 属性和方法都被添加到this 引用的对象中去
3. 新创建的对象由this所引用,并且最后隐式的返回this
5.promise是什么,手写一个promise?
promise解决异步的三种状态
- pending
- fulfilled
- rejected
(1) promise 对象初始化状态为 pending
(2) 当调用resolve(成功),会由pending => fulfilled
(3) 当调用reject(失败),会由pending => rejected
注意promsie状态 只能由 pending => fulfilled/rejected, 一旦修改就不能再变
6.setTimeOut和promise的区别?
在说区别之前,我们先看一个例子
var p1 = new Promise(function(resolve, reject){
resolve(1);
})
setTimeout(function(){
console.log("will be executed at the top of the next Event Loop");
},0)
p1.then(function(value){
console.log("p1 fulfilled");
})
setTimeout(function(){
console.log("will be executed at the bottom of the next Event Loop");
},0)
p1 fulfilled
will be executed at the top of the next Event Loop
will be executed at the bottom of the next Event Loop。JavaScript通过任务队列管理所有异步任务,而任务队列还可以细分为MacroTask Queue(宏任务)和MicoTask Queue(微任务)两类。
MacroTask Queue(宏任务队列)主要包括setTimeout,setInterval, setImmediate, requestAnimationFrame, NodeJS中的`I/O等。
MicroTask Queue(微任务队列)主要包括两类:
独立回调microTask:如Promise,其成功/失败回调函数相互独立;
复合回调microTask:如 Object.observe, MutationObserver 和NodeJs中的 process.nextTick ,不同状态回调在同一函数体;
总的来说就是如果代码按顺序执行,就是一个进入是最大的宏任务,先执行第一个宏任务然后执行宏任务里的微任务,在执行下一个宏任务。
四、网络和安全
1.post和get的区别?
都是Tcp连接,最大的区别就是:
GET产生一个TCP数据包;POST产生两个TCP数据包。
2.浏览器的缓存机制?
对于一个数据请求来说,可以分为发起网络请求、后端处理、浏览器响应三个步骤。而浏览器则能帮助我们在第一步和第三步优化性能,减少数据请求。
其中,缓存位置分为四种:
Service Worker(运行在浏览器背后的独立线程,必须使用https保障安全)
Memory Cache(内存中的缓存,读取速度快,缓存持续性很短)
Disk Cache(存储在硬盘中的缓存,读取速度慢)
Push Cache(推送缓存,以上三种缓存都没有命中时,它才会被使用,会话中存在)
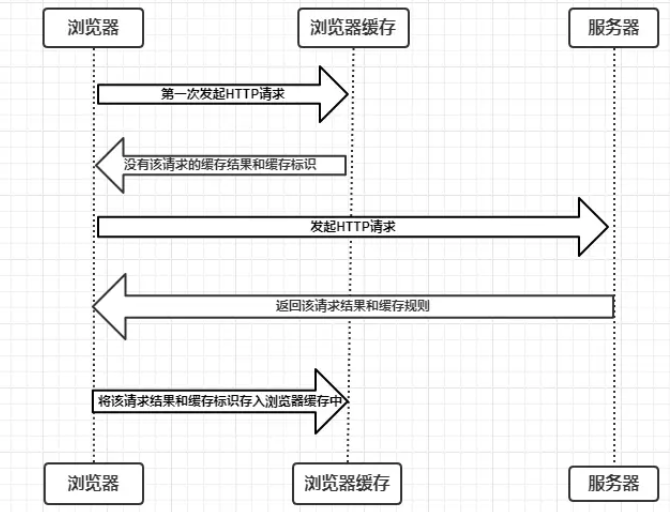
关于浏览器缓存可以参照“深入理解浏览器缓存机制”,以下是浏览器缓存过程分析(图来自网络):
是否需要向服务器重新发起HTTP请求将缓存过程分为两个部分:
- 强制缓存(不会向服务器发送请求,从缓存中读取)
- 协商缓存(强制缓存失效,浏览器重新携带缓存标识发起请求,从而让服务器决定是否启用缓存的过程)
前端清理缓存的几种方法:
//不缓存meta标签
<META HTTP-EQUIV="pragma" CONTENT="no-cache">
<META HTTP-EQUIV="Cache-Control" CONTENT="no-cache, must-revalidate">
<META HTTP-EQUIV="expires" CONTENT="0">
//form表单
<body onLoad="javascript:document.yourFormName.reset()">
//ajax请求时
cache:false ||
beforeSend :function(xmlHttp){
xmlHttp.setRequestHeader("If-Modified-Since","0");
xmlHttp.setRequestHeader("Cache-Control","no-cache");
},
//url参数上加随机数或者随机时间
3.cookie和session的区别以及机制?
为什么需要cookie和session?
http是无状态的,服务端不能跟踪客户端的状态。
cookie机制:
如果不在浏览器中设置过期时间,cookie被保存在内存中,生命周期随浏览器的关闭而结束,这种cookie简称会话cookie。如果在浏览器中设置了cookie的过期时间,cookie被保存在硬盘中,关闭浏览器后,cookie数据仍然存在,直到过期时间结束才消失。
Cookie是服务器发给客户端的特殊信息,cookie是以文本的方式保存在客户端,每次请求时都带上它
session机制:
当服务器收到请求需要创建session对象时,首先会检查客户端请求中是否包含sessionid。如果有sessionid,服务器将根据该id返回对应session对象。如果客户端请求中没有sessionid,服务器会创建新的session对象,并把sessionid在本次响应中返回给客户端。通常使用cookie方式存储sessionid到客户端,在交互中浏览器按照规则将sessionid发送给服务器。如果用户禁用cookie,则要使用URL重写,可以通过response.encodeURL(url) 进行实现;API对encodeURL的结束为,当浏览器支持Cookie时,url不做任何处理;当浏览器不支持Cookie的时候,将会重写URL将SessionID拼接到访问地址后。
4.cookie,localstorage和sessionstorage的区别?
cookie:大小限制4KB,会浪费一部分发送cookie时使用的带宽,要正确的操纵cookie是很困难的。
webStorage包括以下两种:数据存储大小是5MB,字符串类型
localstorage:永久保存,除非手动清除clear()。
sessionstorage:临时保存,关闭了浏览器窗口后就会被销毁
5.XSS(跨站脚本)攻击以及如何防范?
原理: 恶意攻击者往Web页面里插入恶意html代码,当用户浏览该页之时,嵌入其中Web里面的 (html代码/javascript代码) 会被执行,从而达到恶意攻击用户的特殊目的。
- 反射型 XSS:是指发生请求时,XSS代码出现在请求URL中,作为参数提交到服务器,服务器解析并响应。响应结果中包含XSS代码,最后浏览器解析并执行。
- 存储型 XSS:将XSS代码发送到服务器(不管是数据库、内存还是文件系统等。),然后在下次请求页面的时候就不用带上XSS代码了。
- DOM XSS:不同于反射型XSS和存储型XSS,DOM XSS代码不需要服务器端的解析响应的直接参与,而是通过浏览器端的DOM解析。这完全是客户端的事情。
解决方法:过滤危险节点,cookie设置成httponly
6.CSRF(跨站点请求伪造)攻击以及如何防范?
原理:CSRF攻击者在用户已经登录目标网站之后,诱使用户访问一个攻击页面,利用目标网站对用户的信任,以用户身份在攻击页面对目标网站发起伪造用户操作的请求,达到攻击目的。
解决方法:尽量使用POST,限制GET;浏览器Cookie策略;加验证码;Referer Check;Anti CSRF Token服务端加token,在提交请求时附上,看是否与服务端一致。
7.性能优化
HTTP 请求数DNS 查询CDNDOM 元素数量DOM 操作JavaScript 和 CSSJavaScript 、 CSS 、字体、图片等CSS Spriteiconfontiframe 使用src 为空五、框架
1.vue的双向绑定原理?
Object.defineProperty2.vue-router采用的原理?以及query和param传参的差别?
hash---- 利用URL中的hash(“#”):HashHistory.push(),HashHistory.replace()利用
Historyinterface在 HTML5中新增的方法:pushState(), replaceState()pushState设置的新URL可以是与当前URL同源的任意URL;而hash只可修改#后面的部分,故只可设置与当前同文档的URL
pushState设置的新URL可以与当前URL一模一样,这样也会把记录添加到栈中;而hash设置的新值必须与原来不一样才会触发记录添加到栈中
pushState通过stateObject可以添加任意类型的数据到记录中;而hash只可添加短字符串
pushState可额外设置title属性供后续使用
3.vuex的原理以及适用场景?
4.v-if和v-show的区别?谈到重排和重绘
v-if: 移除在dom中的显示,将dom元素移除
v-show: dom元素还在,相当于display:none
display:none --元素被隐藏, 和 visibility: hidden
重排和重绘:重排包括重绘,重绘不一定包括重排
引起重排:
(1)页面渲染初始化时;(这个无法避免)
(2)浏览器窗口改变尺寸;
(3)元素尺寸改变时;
(4)元素位置改变时;
(5)元素内容改变时;
(6)添加或删除可见的DOM 元素时。
5.vue的生命周期?
- beforeCreate
- created
- beforeMount
- mounted
- beforeUpdate
- updated
- beforeDestroy
- destroyed
6.angular的双向绑定原理?
7.rxjs对可观察对象的理解?
六、node.js
1.express写中间件
七、数据结构与算法
1.对比栈,队列,数组,链表这些结构的优缺点?2.排序算法?3.广度优先遍历深度优先遍历算法?
八、git
1.git fecth和git pull的区别?
git pull相当于git fecth + git merge。git fecth只能改变远程仓库里的代码,本地head不能改变。
九、webpack
1.sourcemap有多少种?
为什么需要source-map,为了解决代码经过编译打包出错之后定位问题。
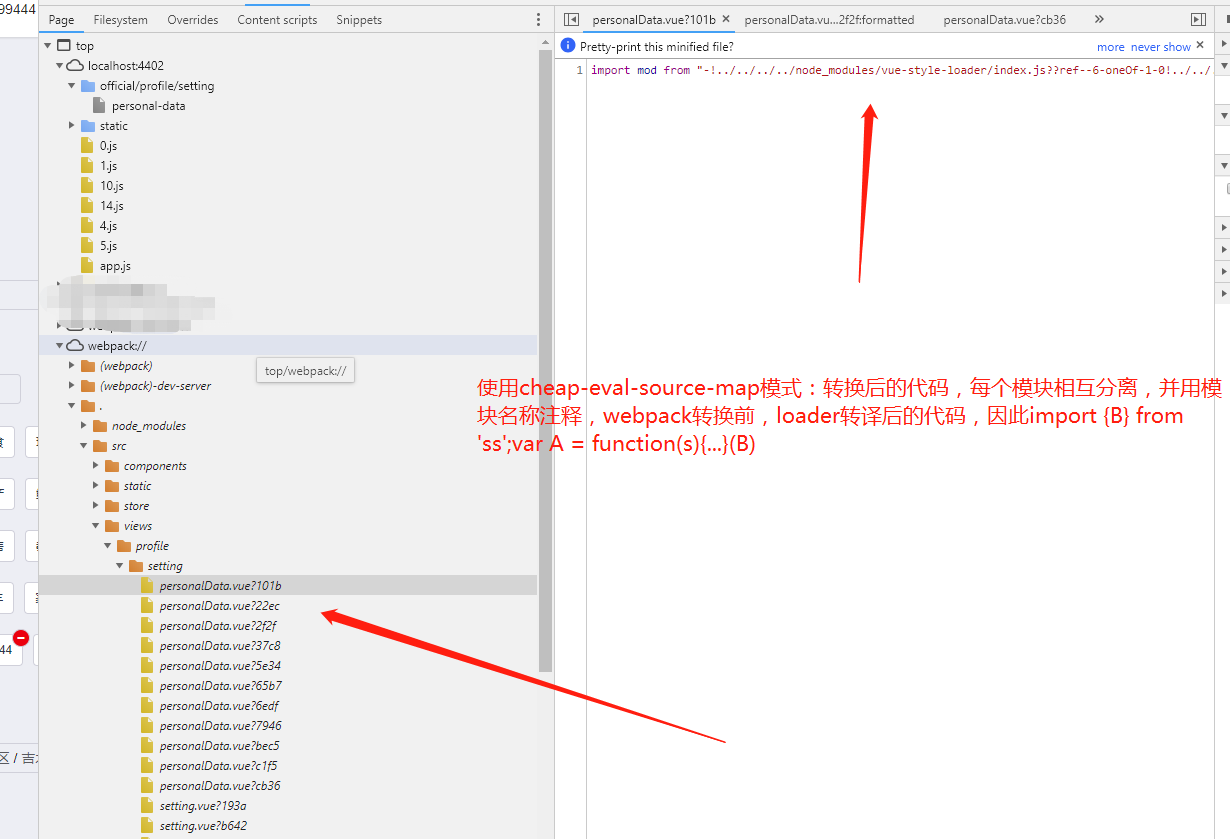
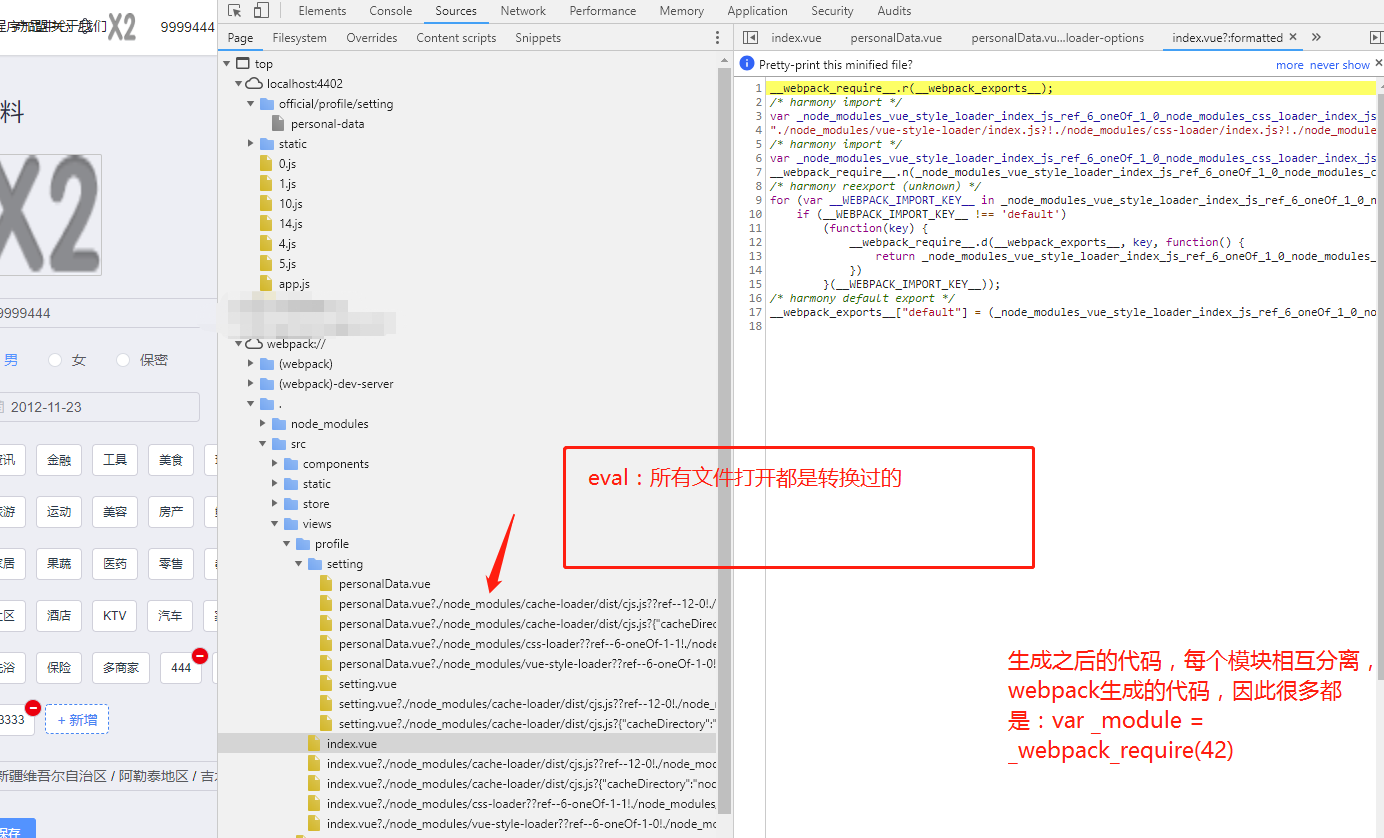
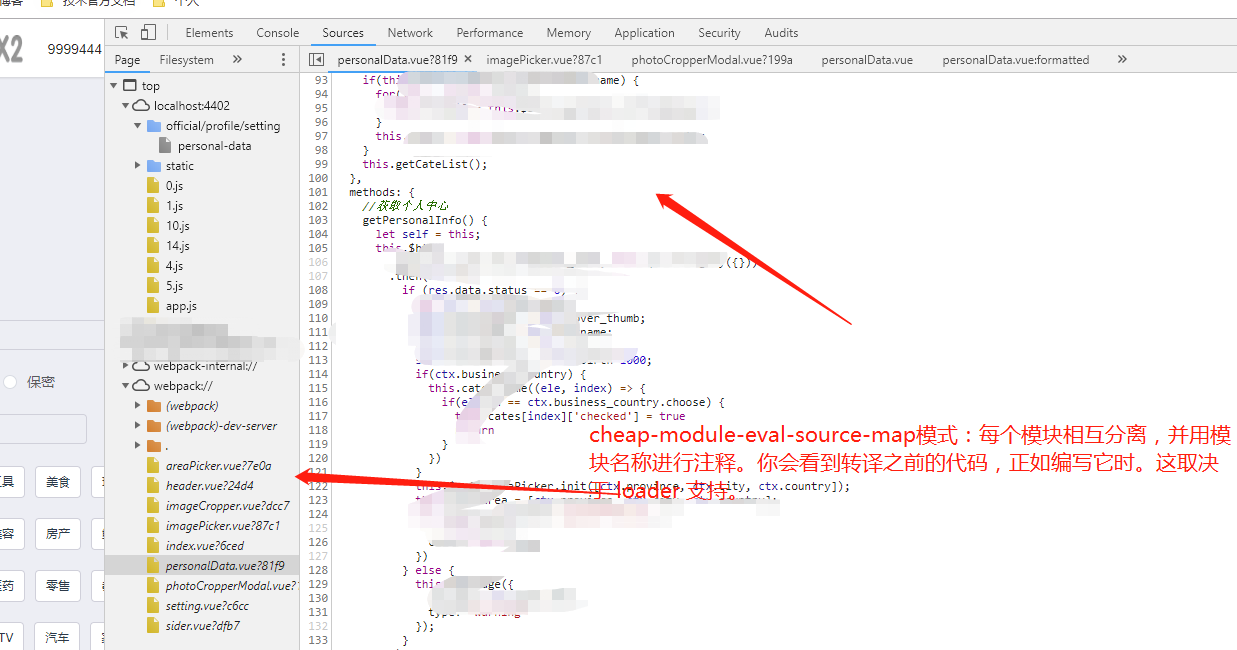
webpack官网一共有11种,无非就是包括:打包后(none),生成后的代码,转换后的代码(仅限行:每行一个映射),原始源代码(仅限行),原始源代码,无源代码内容。对于开发环境,通常希望更快速的 source map,需要添加到 bundle 中以增加体积为代价,但是对于生产环境,则希望更精准的 source map,需要从 bundle 中分离并独立存在。
以下是开发环境常用推荐的:
配置:devtool: 'cheap-eval-source-map'
生产环境是最好不要看到源码,推荐devtool:none
