

前端优化
资源的合并与压缩
- web前端是bs架构
- web访问是动态增量的过程,通过不断请求远程服务器加载资源
- 优点:减少http请求,减少请求资源的大小
1.资源合并与压缩-压缩
a.html压缩
方法::
- 1.使用在线网站进行压缩
- 2.nodejs提供了html-minifier工具
- 3.后端模板引擎渲染压缩
b.css压缩
- 1.无效代码删除
- 2.css语义合并
c.js压缩与混乱
- 1.无效字符的删除
- 2,剔除注释
- 3.代码语义的缩减和优化
- 4.代码保护(代码压缩,可读性底,有利于保护代码不被看懂或复制) 方法:
- 1.使用在线网站进行压缩
- 2.nodejs提供了html-minifier工具
- 3.使用uglifyjs2对果进行压缩
资源合并与压缩-合并
文件合并存在的问题
- 首屏渲染问题(文件合并成一个文件,首次加载时间会比较长)
- 缓存失效问题(修改其中一处内容,整个文件变动,在浏览器的缓存失效,又要重新加载整个文件)
文件合并建议
- 公共库合并
- 不同页面的合并(vue的异步加载组件)
- 见机行事,随机应变
方法
- 1.使用在线网站进行合并
- 2.使用nodejs或webpack等框架实现文件合并
2.图片相关优化
png8/png24/png32之间的区别
- png8 -- 256色(2^8) 支持透明--适用于颜色种类较少的png图片
- png24 -- (2^24) 不支持透明
- png32 -- (2^24) 支持透明--适用于颜色种类丰富的png图片
不同图片常用的业务场景
- jpg有损压缩,压缩率高,不支行透明
- png支持透明,浏览器兼容好
- webp压缩程序更好,在ios webviewe有兼容性问题
- svg矢量图,代码内嵌,相对较小,图片样式相对简单的场景
进行图片压缩
- 针对真实图片情况,舍弃一些相对无关的色彩信息 css雪碧图:
- 优点:减少Http请求
- 缺点:当雪碧图过大时,加载过慢,在雪碧图上的所有图片就会都没有加载出来 image inline:
- 把图片转成base64格式,然后内嵌在html中
- 优点:减少http请求
- 缺点:代码体量过大 使用矢量图:
- 使用svg进行矢量图绘制
- 使用iconfont解决icon问题
- 与jpg相比,更小,加载更快
- 缺点:颜色比较单调,复杂的图片不适合使用矢量图
在安卓下使用webp:
- webp压缩率更高,大小更小,但是并不所有浏览器兼容 图片压缩网址图片压缩:
3. css和js的装载与执行
html,css,js加载过程
- 输入网站,发起请求,服务器返回一段html,浏览器html解析器解析,从上到下生成dom树,在这个过程中,解析到相应的link,script等外部资源,览器发起请求,加载到相应的资源并解析,生成对应的css树,css树和dom树结合,生成render tree,然后布局,重绘,形成html页面 html渲染过程中的一些特点:
- 顺序执行,并发加载(引入外部资源,并发加载)
- 是否阻塞(css,js加载是否阻塞后续dom加载)
- 依赖关系
- 引入方式 顺序执行,并发加载
- 词法分析--从上到下
- 并发加载--引入外部资源,并发加载
- 并发上限--并发加载资源,有上限 css阻塞:
- css head中阻塞页面的渲染
- css阻塞js执行--js执行可能影响dom结构和css样式,执行前要求dom和css已经加载完成,有依赖关系
- css不阻塞外部脚本的加载 js阻塞:
- 直接引入的js阻塞页面的渲染
- js不阻塞资源的加载
- js顺序执行,阻塞后续js逻辑执行 依赖关系:
- 页面渲染依赖于css加载
- js的执行顺序的依赖关系
- js逻辑对于dom节点的依赖关系 js引入方式:
- 直接引入--会阻塞页面加载
- defer--不会阻塞dom渲染,dom渲染完成后,按照从上到下,同步执行
- async--不会阻塞dom渲染,dom渲染完成后,异步加载执行,不存在依赖关系
- 异步动态引入js 加载和执行的一些优化点:
- css样式表置顶
- 用link代替import--外部引用css样式完成后,再解析import,在css样式表内部执行,不会并发执行
- js脚本置底
- 合理使用js的异步加载能力
4. 懒加载与预加载
原理
- 什么是懒加载:图片进入可视区域之后请求图片资源,如果网站图片很多,但是用户只看了几张就退出,后面的图片也没有必要加载,这时就是用到,而且过多资源加载,会影响后面js的加载
- 1,监听scoll整件,当图片进入可视区域后,图片开始加载
- 什么是预加载:图片等静态资源使用前,提前加载,资源使用到时能从缓存中加载,提升用户体验
预加载的三种方法
- 1.直接在页面内通过img标签引入,默认隐藏
- 2.在js里文件new image对象,需要的时候直接引用
- 3.使用XMLHttpRequest对象加载图片,这个方法返回状态和回调函数,监听函数,更好控制整个过程,但是不同域名下的资源有跨域问题
- 4.使用preloadJS库
5. 重绘与回流
- css性能让javascript变慢?是的,这是因为ui是一个线程,js渲染也是一个线程,但这两个线程是互斥,当其中一个线程进行时,另一个是冻结的发重绘与回流,会导致ui频繁渲染,最终导致js变慢
回流
- 当render tree中的一部分或全部,因为元素的规模尺寸,布局,隐藏等改变而需要重新构建。这就称为回流。当页面布局和几何属性(大改变时需要回流
重绘
- 当render tree中的一些元素需要更新属性,在,而这些属性只是影响元素的外观,风格,而不影响布局的,比如背景,字体颜色,则称为重绘。 回流必将引起重绘,而重绘不一定会引起回流
触发页面重布局的属性
- 盒子模型相关属性会触发重布局
- 定位属性及浮动也会触发得布局
- 改变节点内部文字结构也会触发重布局

- 只触发重绘属性


6.浏览器存储
多种浏览器存储方式并存,如何选择?
cookie
- 因为HTTP请求无状态,所以需要cookie去维护客户端状态
cookier的生成方式
- http response header 中的set-cookie,当客户端接收到http response hea中的set-cookie信息时,会自动在客户端生成相应的cookie,客户端再次发起请求时,这些cookie信息将被携带在request header中带给服务端,服务端可以从这些信息中判断用户的相关信息--用于浏览器端和服务端的交互
- cookie属性httponly(服务端设置), 如果您在cookie中设置了HttpOnly属性,那么通过js脚本将无法读取到cookie信息,这样能有效的防止XSS攻击
- js中可以通过document.cookie可以读写cookie--客户端自身存储信息
cookie存储的限制
- 作为浏览器存储,大小4kb左右
- 需在设置过期时间 expire
- 浏览器存储尽量用localstorage
Localstorage
- HTML5设计出来专门用于浏览器存储
- 大小为5M左右
- 仅在客户端使用,不和服务端进行通信
- 接口封闭较好,有专门的api进行设置删除操作
- 浏览器本地缓存方案
sessionstorage
- 会话级别的浏览器存储(浏览器关闭,sessionstorage删除)
- 大小为5M左右
- 仅在客户端使用,不和服务端进行通信
- 接口封闭较好,有专门的api进行设置删除操作
- 对于表单信息的维护
IndexedDB
- IndexedDB 就是浏览器提供的本地数据库,它可以被网页脚本创建和操作。IndexedDB 允许储存大量数据,提供查找接口,还能建立索引。这LocalStorage 所不具备的。就数据库类型而言,IndexedDB 不属于关系型数据库(不支持 SQL 查询语句),更接近 NoSQL 数据库。
function openDB(name,callback){
//建立打开indexDB indexedDB.open()
var request = window.indexedDB.open(name)
request.onerror = function(e){
console.log('open indexedDB error')
}
request.onsuccess = function(e){
myDB.db = e.target.result
console.log(myDB.db)
callback && callback()
};
//在我们请求打开的数据库的版本号和已经存在的数据库版本号不一致的时候调用
request.onupgradeneeded = function (e) {
myDB.db = e.target.result
/*在这里遇到一个问题,如果没有上一步 myDB.db = e.target.result
将会报错
Cannot read property 'createObjectStore' of undefined at IDBOpenDBRequest.request.onupgradeneeded
myDB.db是为undefined,按理说,当触发onupgradeneeded,myDB.db已经建立了,只是没有数据或是版本号有更新,但是myDB.db是已经存在了啊,好奇怪啊
*/
var store = myDB.db.createObjectStore('books',{
keyPath:'isbn'
})
//创建objectstore索引
var titleIndex = store.createIndex('by_title','title',{
unique:true
})
var authorIndex = store.createIndex('by_author','author')
store.put({
title:'lihui123',
author:'hui1',
isbn:123
})
store.put({
title:'lihui456',
author:'hui2',
isbn:456
})
store.put({
title:'lihui789',
author:'hui3',
isbn:789
})
}
}
var myDB = {
name:'testDB',
version:'1',
bd:null
}
//添加数据
function addData(db,storeName){
//object store
//关联storeName,并设置为可读可写
var transaction = db.transaction(storeName,'readwrite')
var store = transaction.objectStore(storeName)
//获取当前indexeddb中的数据
var request = store.get(123)//key值
request.onsuccess = function (e){
console.log(e.target.result)
}
//添加信息到indexdb中
store.add({
title:'lihui101112',
author:'hui4',
isbn:101112
})
//删除记录 key值是isbn的值
store.delete(123)
//修改已存在的记录
store.get(123).onsuccess = function (e){
var obj = e.target.result
console.log(e.target.result)//{title: "lihui123", author: "hui1", isbn: 123}
obj.author = 'change name';
store.put(obj)
}
}
openDB(myDB.name,function(){
//闭关indexedDB
myDB.db.close()
//删除indexedDB
window.indexedDB.deleteDatabase(myDB.db)
//住indexDB中添加数据
})
setTimeout(function(){
addData(myDB.db,'books')
},2000)
//{title: "lihui123", author: "hui1", isbn: 123}
//objectStore 不同于数据库的表 是通过对象来存储的
service workers 产生的意义
service worker 是一个脚本,浏览器独立于前端网页,将其在后台运行,为实现一些不依赖页面或用户交互的特性打开了一扇大门,在未来这些特性将包括推送消息,背景后台同步,geofencing(地址围栏定位),但它将推出的第一个首要特性,就是拦截和处理网络请求的能力,包括以编程方式来管理被缓存的响应。
- 使用拦截和处理网络请求的能力,去实现一个离线应用
- 使用service worker在后台同时能和页面通信的能力,去实现大规模后台数据处理
离线应用
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title></title>
<link rel="stylesheet" type="text/css" href="css.css">
</head>
<body class="main">
serviceWork
<script type="text/javascript" src="app.js"></script>
</body>
</html>
app.js 在这个js里注册serviceWorker
if (navigator.serviceWorker) {
//注册serviceWorker scope作用域
navigator.serviceWorker.register('./serviceWorker.js',{scope:'./'})
.then(function(reg){
console.log(reg)
})
.catch(function (e) {
console.log(e)
})
}
serviceWorker.js 在这里入方法
//servicrworker只能在https下使用,本地不能用ip访问,可以用localhost
//install service worker的生命周期函数
self.addEventListener('install',function(e){
e.waitUntil(
caches.open('app-v1')
.then(function (cache){
console.log('open cache')
//要缓存的文件
return cache.addAll([
'./app.js',
'./css.css',
'./index.html'
])
})
)
})
//fetch 所有主页面向网络发起的请求
self.addEventListener('fetch',function(event) {
//service-worker的api
event.respondWith(
//如果在缓存caches里能匹配到就取缓存里的,否则就通过else里的fetch发起请求
caches.match(event.request).then( function (res){
if (res) {
return res
}else{
//通过fetch方法向网络发起请求
fetch(url).then(function(res){
if (res) {
//对于新请求到的资源存储到我们的cachestorage中
caches.addAll([])
}else{
//用户提示
}
})
}
})
)
})
页面通信的能力
msg-demo.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<ul id="msg-box"></ul>
<input type="text" id="msg-input">
<button id="send-msd-button">发送</button>
<script type="text/javascript" src="msgapp.js"></script>
</body>
</html>
msgapp.js
if (navigator.serviceWorker) {
var sendBtn = document.getElementById('send-msd-button'),
input = document.getElementById('msg-input'),
msgBox = document.getElementById('msg-box');
sendBtn.addEventListener('click',function(){
//主页面发送信息到serviceWorker
navigator.serviceWorker.controller.postMessage(input.value)
})
//监听message,并在页面加添加相应的内容
navigator.serviceWorker.addEventListener('message',function(event){
msgBox.innerHTML = msgBox.innerHTML+('<li>'+event.data.message+'</li>');
})
//注册serviceWorker
navigator.serviceWorker.register('./msgsw.js',{scope:'./'})
.then(function(reg){
console.log(reg)
})
.catch(function (e) {
console.log(e)
})
}else{
alert("serviceWorker is not supported")
}
msgsw,js
//监听message
self.addEventListener('message',function (event){
//self.clients serviceworker下所管理的页面
var promise = self.clients.matchAll().then( function (clientList){
//拿到发送页的id
var sendId = event.source ? event.source.id:'unknown';
clientList.forEach(function(client){
//发送页不用增加发送内容
if (client.id == sendId) {
return
}else{
//向其他页面发送主页面发送的内容
client.postMessage({
client:sendId,
message:event.data
})
}
})
})
})
工具网站
chrome://inspect/#service-workers 浏览器正在运行的service workers
chrome://servicework-internals 浏览器上注册过service workers记录
PWA
PWA(progressive web apps)是一种web app新模型,并不是具体指某一种前沿的技术或者某地个单一的知识点,我们从英文缩写来看,这是一个渐进式的web App,是通过一系列新的web特性,配合优秀的ui交互设计,逐步的增强web App的用户体验
- 可靠性:没有网络也能提供基本的页面访问
- 快速性:针对网页渲染用网络数据访问有较好优化
- 融入性:应用可以被增加到手机桌面,并且和普通应该一样,有全屏,推送等特性
检测网站是否PWA:工具lighthouse(chrome扩展工具)
7.缓存优化
cache-control
cache-control属性:
- max-age 指定缓存有效时间,在这个时间内,资源是从缓存中读取,优先级高于Expires
- s-maxage 指定cdn中public的资源有效时间,优先级高于max-age
- no-cache 不在缓存中读取,先从服务器中请求,服务器端返回的资源是否缓存
- no-store 不使用缓存
Expires
- 缓存过期时间,用来指定资源到期时间,是服务器端的具体的时间点,优先级最低
- 告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据,而无需再次请求
Last-Mondified/If-Mondified-Since
- 基于客户端和服务端协商的缓存机制
- last-modified ——response header
- if-modified-since ——request header
- 需在与cache-control共同使用
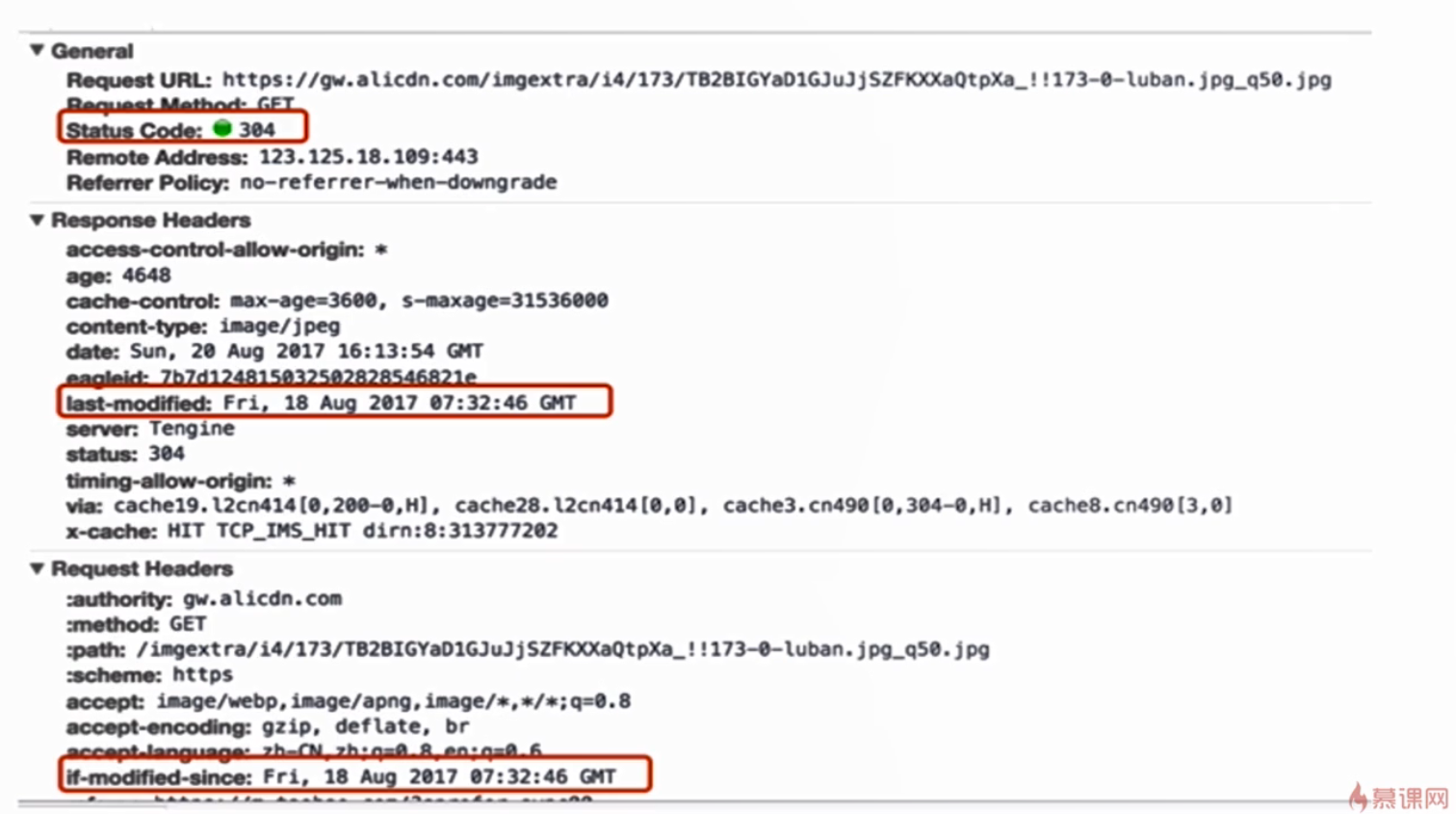
流程:客户端向服务器请求资源,服务端返回response header中的last-modified表示这个资源的更新时间,客户端接收到后,把该资源和last-modified存在浏览器的缓存中,再次请求资源,requset header中的if-modified-since告诉服务器,这个资源的更新时间,如果服务器上的这个资源没有更新,就直接从浏览器的缓存中取该资源,返回304,如果服务器上的该资源已更新,那么会从服务器上重新请求,并返回200,同时response header上的last-modified更新为最新时间,并重新缓存。但是Last-Mondified/If-Mondified-Since的优先级低于 cache-control中max-age的优先级,如果是在max-age的有效时间内,还是以在max-age为主。
last-modified 缺点
- 1.某些服务端不能获取精确的修改时间
- 2.文件修改时间改了,但文件内容却没有变
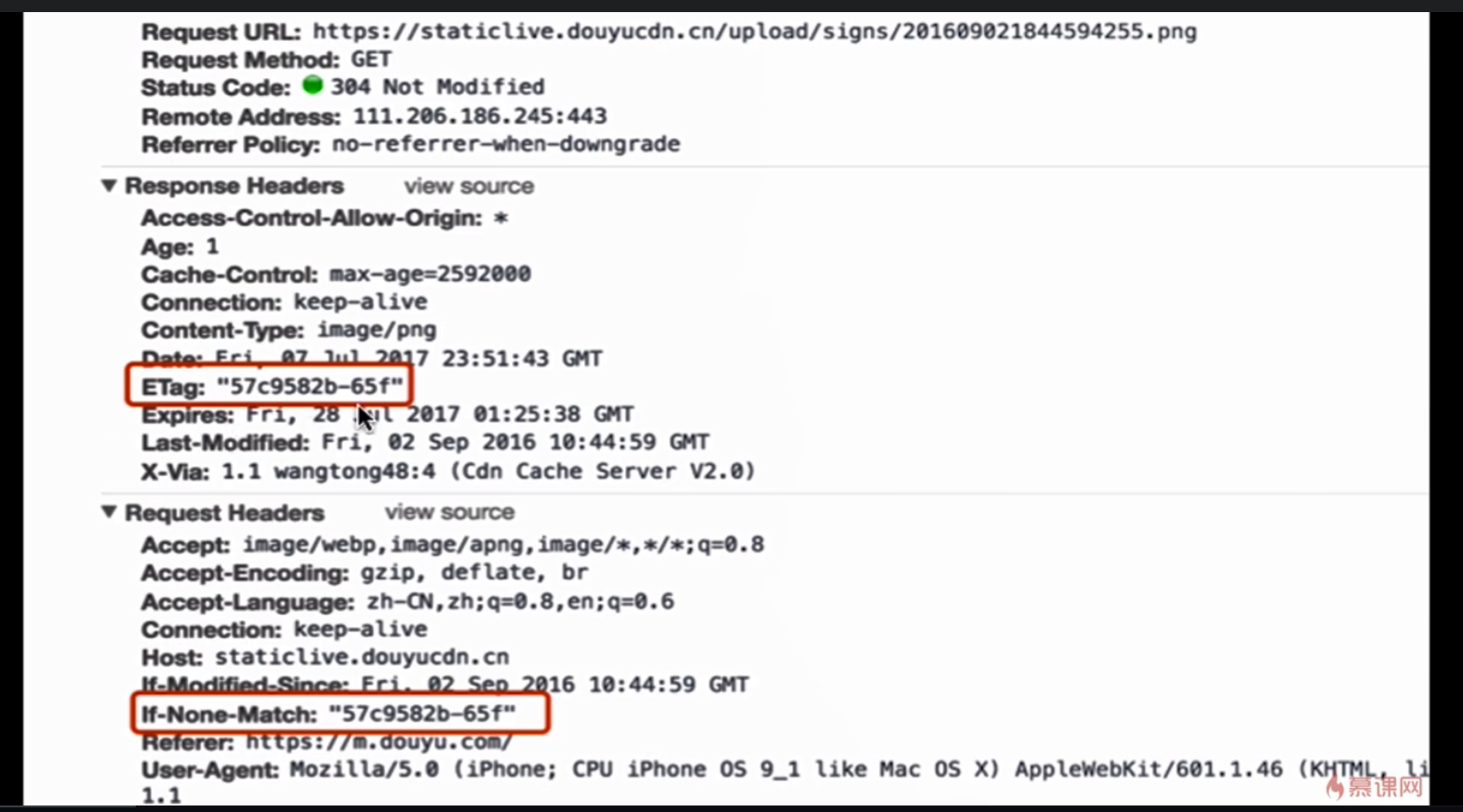
Etag/If-None-Match
- 文件内容的hash值(文件唯一标识,当文件改变,hash值改变)
- Etag ——response header
- If-None-Match ——request header
- 需在与cache-control共同使用
- 优先级比last-modified高
流程与Last-Mondified/If-Mondified-Since相同,但不会存在误差
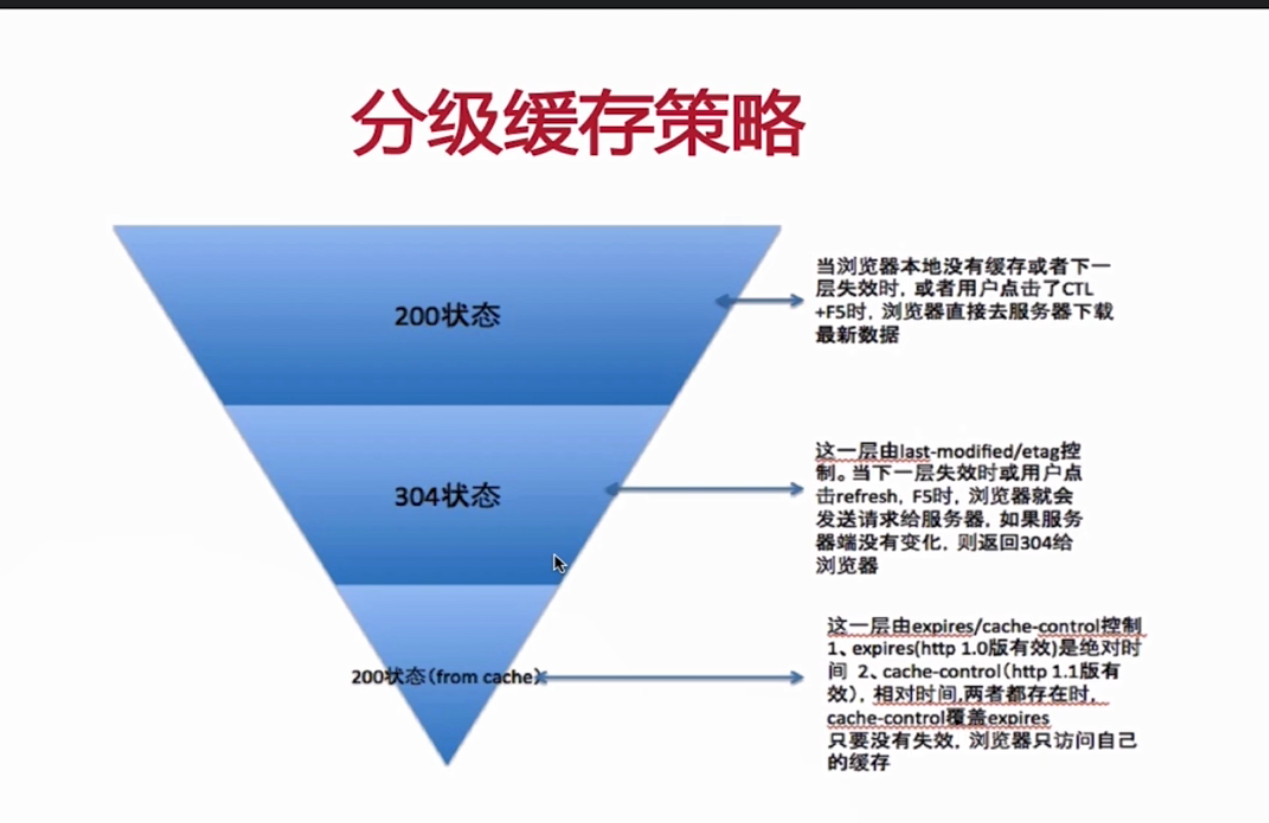
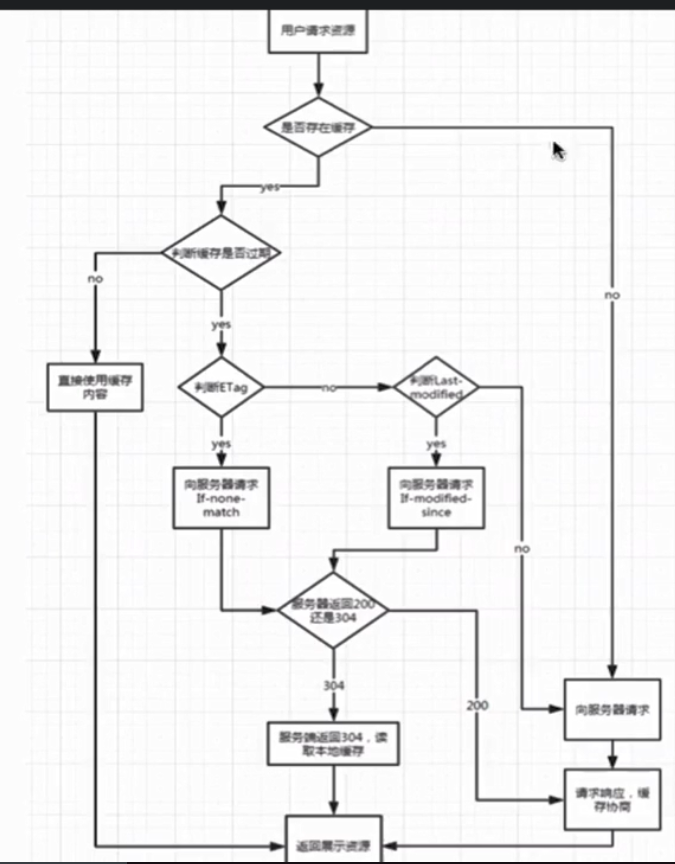
资源请求流程图
服务端性能优化
这方面,前端可操作的地方不多,就不说了
