首先新建一个Maven项目
添加maven依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.2.2</version>
</dependency>
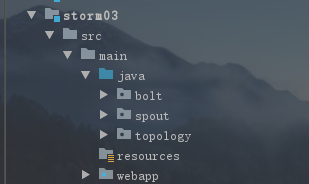
新建目录结构
下面就是代码编写
首先是spout 数据源接收发送的类
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichSpout;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.util.Map;
public class MessageSpout implements IRichSpout {
private SpoutOutputCollector collector;
private int index = 0;
//自己模拟数据源
private String[] arr =
{"java", "php", "ruby", "grouy", "python", "react", "js"};
//open()方法中是在ISpout接口中定义,在Spout组件初始化时被调用。
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector collector) {
this.collector = collector;
}
//close是在ISpout接口中定义,用于表示Topology停止。
@Override
public void close() {
}
@Override
public void activate() {
}
@Override
public void deactivate() {
}
//nextTuple()方法是Spout实现的核心。也就是主要执行方法,用于输出信息,通过collector.emit方法发射
@Override
public void nextTuple() {
if (index < arr.length) {
collector.emit(new Values(arr[index]), index);
index++;
}
}
//ack是在ISpout接口中定义,用于表示Tuple处理成功
@Override
public void ack(Object o) {
System.out.print("消息发送成功" + o);
}
//ack是在ISpout接口中定义,用于表示Tuple处理失败
@Override
public void fail(Object o) {
System.out.print("消息发送失败" + o);
collector.emit(new Values(o), o);
}
//declareOutputFields是在IComponent接口中定义,用于声明数据格式。即输出的一个Tuple中,包含几个字段。因为这里我们只发射一个,所以就指定一个。如果是多个,则用逗号隔开。
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("messageSend"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
接下来是bolt 处理数据的类,我这里写了2个
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Map;
public class ReceiveBolt implements IRichBolt {
private OutputCollector collector;
//prepare 在Bolt启动前执行,提供Bolt启动环境配置的入口。参数基本和Sqout一样。
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector collector) {
this.collector = collector;
}
//execute()方法是Bolt实现的核心。也就是执行方法,每次Bolt从流接收一个订阅的tuple,都会调用这个方法。
@Override
public void execute(Tuple tuple) {
try {
String message = tuple.getStringByField("messageSend");
collector.emit(new Values(message));
collector.ack(tuple);
} catch (Exception e) {
e.printStackTrace();
collector.fail(tuple);
}
}
@Override
public void cleanup() {
}
//和Spout的一样。
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("dispose"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
第二个bolt
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Map;
public class DisposeBolt implements IRichBolt {
private OutputCollector collector;
private FileWriter writer;
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
this.collector = outputCollector;
try {
writer = new FileWriter("D:/test.txt");
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void execute(Tuple tuple) {
String dispose = tuple.getStringByField("dispose");
try {
writer.write(dispose);
writer.write("\r\n");
writer.flush();
} catch (IOException e) {
e.printStackTrace();
collector.fail(tuple);
}
collector.emit(tuple, new Values("word"));
collector.ack(tuple);
}
@Override
public void cleanup() {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
最后就是topology 测试就用本地模式
import bolt.DisposeBolt;
import bolt.ReceiveBolt;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.TopologyBuilder;
import spout.MessageSpout;
public class ResultTopology {
public static void main(String[] args) {
//定义一个拓扑
TopologyBuilder topologyBuilder = new TopologyBuilder();
//设置一个Executeor(线程),默认一个
topologyBuilder.setSpout("messageSpout", new MessageSpout());
//设置一个Executeor(线程),和一个task
topologyBuilder.setBolt("receiveBolt", new ReceiveBolt()).shuffleGrouping("messageSpout");
topologyBuilder.setBolt("disposeBolt", new DisposeBolt()).shuffleGrouping("receiveBolt");
//配置
Config config = new Config();
config.setDebug(true);
//启动本地模式
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("message", config, topologyBuilder.createTopology());
try {
Thread.sleep(30000);
} catch (InterruptedException e) {
e.printStackTrace();
}
cluster.killTopology("message");
cluster.shutdown();
}
}
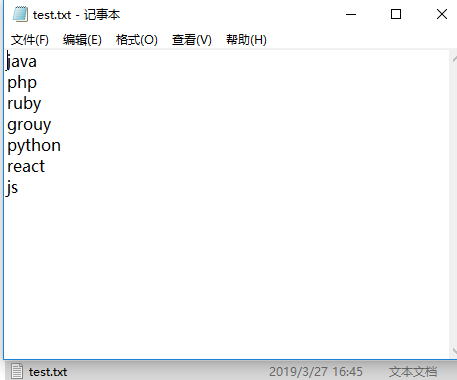
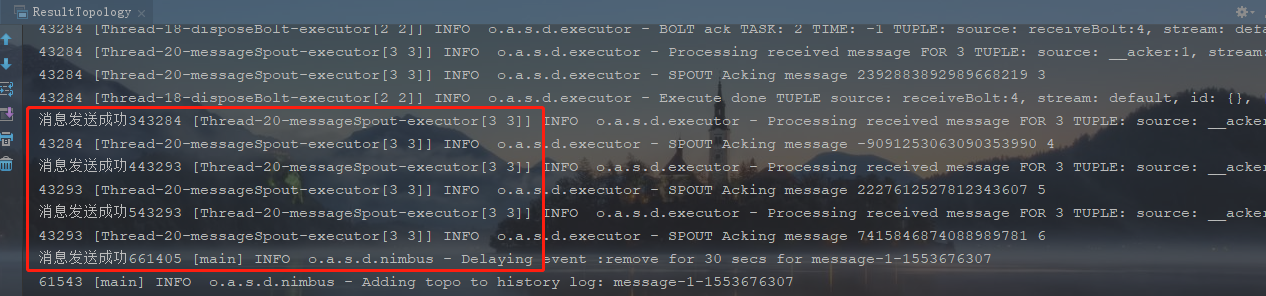
运行的结果