

概括
- 使用到的库 urllib\requests\bs4...
- 解析网页内容的知识 正则表达式、bs4、xpath、jsonpath,涉及到动态html
- 涉及到动态html (seleniu+phantomjs/chromeheadless
- scrapy框架 高性能框架的使用
- scrapy-redis组件 redis,分布式爬虫
- 爬虫-反爬虫-反反爬虫
UA、代理、验证码、动态页面
http协议
- 协议:双方规定的传输形式
- http协议:网站原理
| http | https |
|---|---|
| 超文本传输协议 | ssl加密传输协议 |
| 80端口 | 443端口 |
| 链接简单,无状态 | SSL+HTTP构建的可进行加密传输、身份认证 |
- 公钥、私钥
- 通过密钥加密解密
- 对称加解密
- 非对称加解密(私钥加密用公钥进行解密,公钥加密用私钥进行解密
- http请求:请求行,请求头,请求内容
- 请求方式:GET(默认)、POST
- GET请求,在URL地址后附带的数据容量通常不超过1k
- 请求头(需要掌握
| 请求头[掌握] | 告知浏览器(服务器: | 响应头[了解] |
|---|---|---|
| accept | 所支持的数据类型 | |
| Accept-Language | 语言环境 | Content-Language |
| Accept-Charset | 所支持字符集 | |
| Accept-Encoding | 支持的压缩格式 | Content-Encoding |
| Host | 想访问哪台主机 | |
| If-Modified-Since | 缓存数据时间 | Expires:-1 控制浏览器不要缓存 |
| Referer | 客户机是哪个页面来的(用于防盗链 | |
| Connection | 请求完后断开/何持服务器 | |
| X-Requested-With | XMLHTTpRequest代表通过ajax方式进行访问 |
- HTTP响应
- 包括:一个状态行,若杠消息头、实体内容
python如何访问互联网
1.urllib
- url:网页地址
协议,域名系统或ip地址,资源具体地址(可忽略)
- lib
2.模块:
- urllib.request(包含对服务器的请求发出跳转代理安全等)
- urllib.error
- urllib.parse
- urllib.robotparser
- 通过urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)获取网页
- url可为字符串或者request对象(传进字符串会把地址转化为request对象)
- data=None、cafile=None、capath=None、cadefault=False、context=None为默认参数,timeout可选
- date默认时以GET方式提交,被赋值以POST方式代替GET提交
- 调用需要传入的参数为网页地址
- 需要对象接收函数返回值
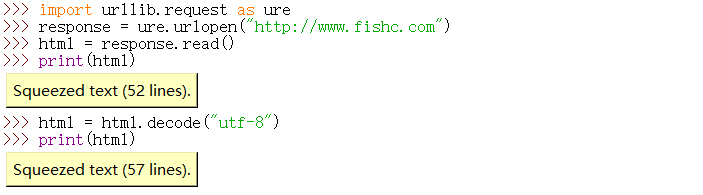
- .decode("utf-8")解码
- .read()读取对象
第一个实例,一只可爱的猫
import urllib.request
req = urllib.request.Request("https://placekitten.com/1080/620")#实例化Request类
response = urllib.request.urlopen(req)#request对象作参数,返回对象赋值给response
cat_img = response.read()
with open("cat_1080_620.jpg","wb") as f:
f.write(cat_img)
# 都是下载到py文件所在文件夹 吗?
(●'◡'●)
- .geturl():返回页面地址
- .info():返回head信息
- .getcode():返回状态码
| 状态码 | 内容 |
|---|---|
| 200 | 请求成功 |
| 301 | 永久重定向 |
| 302 | 临时重定向 |
| 403 | 禁止 |
| 404 | 没有找到处理方式 |

审查元素
-
method(新版chrome中审查元素找不到method可以手动设置显示
- GET:从服务器请求获得数据(也可用来提交数据
- POST:向指定服务器提交被数据
-
状态码
- 200:请求成功
- 301:永久重定向
- 302:临时重定向
- 403:禁止
- 404:找不到页面
-
Reques Headers:客户端发送请求
- 服务端用来判断是否非人类访问,通过User-Agent判断是浏览器访问或者代码访问
- 可进行自定义
- 用python默认为pythonurl
-
Form Date(表单数据):POST提交的主要内容
翻译
- urllib.parse库负责解析功能
- urllib.parse.urlencode(date).encode('utf-8')

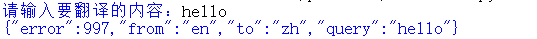
- urllib.parse.urlencode(date).encode('utf-8')
