

参考资料
- 慕课网《Python3 入门机器学习》
文章目录
接下来将分为3篇文章完成线性回归算法的相关内容,这是3个文章的总体大纲。
1. 简单线性回归
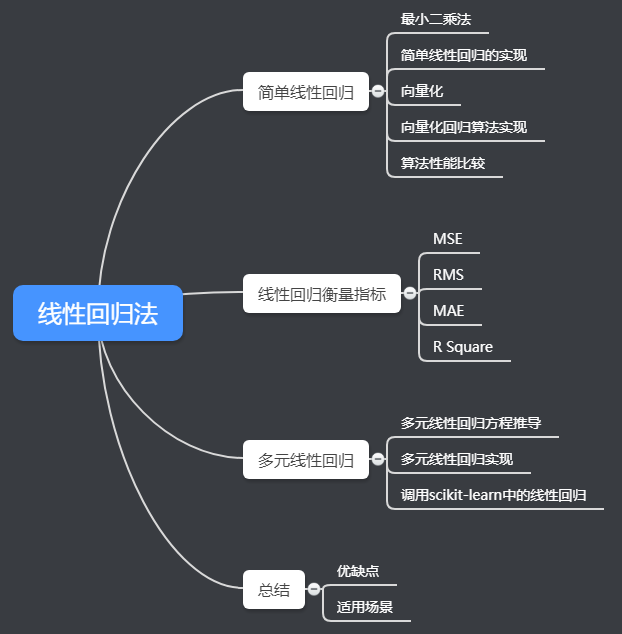
拿波士顿的房价为例,现在有这么一张图,x轴是房子的面积,y轴是房子的价格,我们假设房子面积和房屋价格之间呈现线性关系,那么我们就可以通过线性回归算法对房价进行预测。
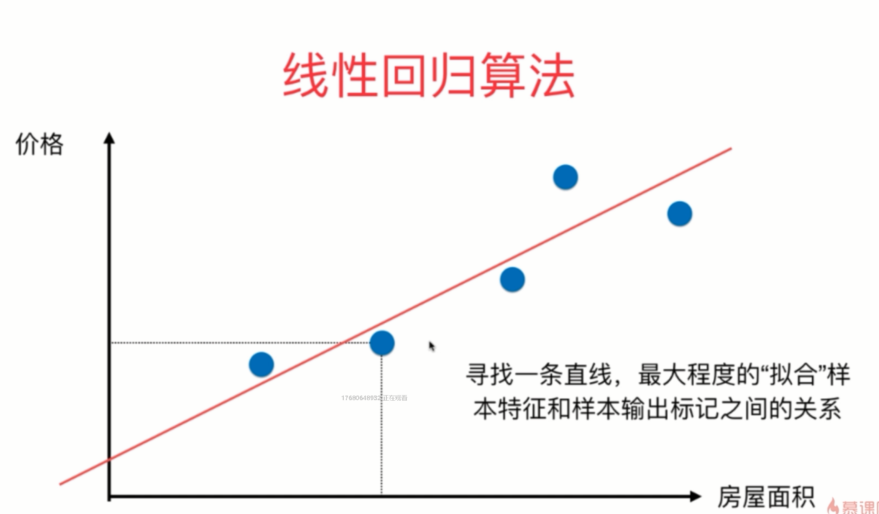
注意: 这里的图跟之前的KNN算法之间的图是不一样的。
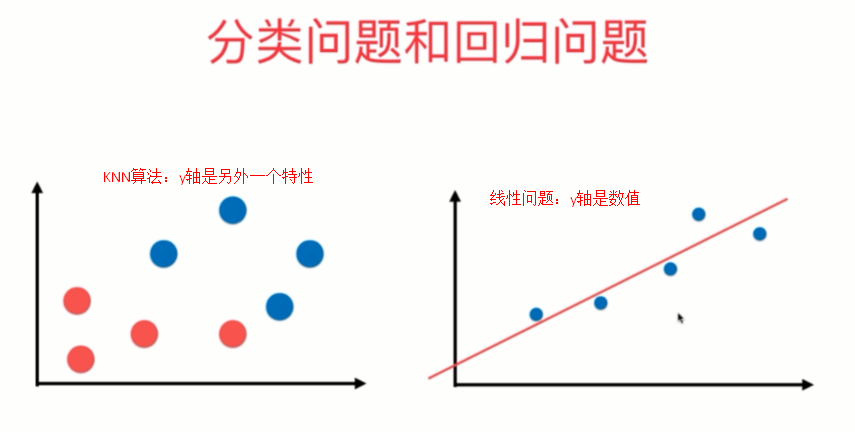
我们中学学过都知道,一条直线可以表示成:y = ax +b 的形式。
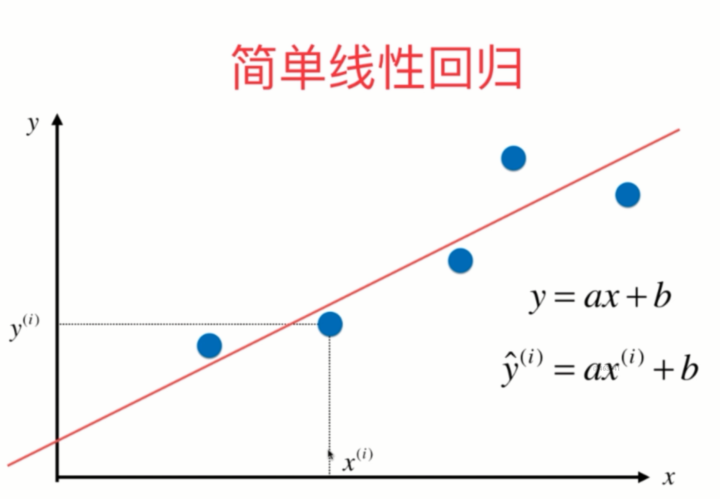
线性回归算法就是假设有一条直线可以尽可能地拟合我们的数据,从而通过这么一条直线来进行预测。
现在假设我们找到了最佳拟合的直线方程:
y = ax+ b
则对于每一个样本点
根据我们的直线方程,预测值为:
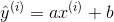
真值为:
那么此时,如果此时这条方程是最佳拟合方程,那么:
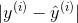
必然是最小的。
但是我们一般不采用绝对值的方式,而是采用平方的方式,所以我们上面的公式可以写成:
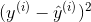
拿我们现在 目标,就是使得:
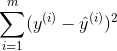
尽可能地小。
又因为
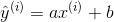
所以,现在,线性回归法的目标就是,找到a和b使得
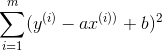
到这里我们可以总结一下学习算法的基本思路,就是最优化原理,本质都是通过找到某些参数,让这个损失(其实就是误差)尽可能的小,尽可能的拟合所有数据点。
对于这类思想,有一门专门的学科,叫“最优化原理”,还有另外一种方法,叫“凸原理”。希望深耕的朋友可以了解一下。
在求解a和b的之前,我们要了解一下最小二乘法。
1.1 最小二乘法
现在我们要求一个函数的最小值,其实就是这个这个函数的极值。学过高数的朋友都知道, 求函数极值最简单的方法就是对函数中的各个变量进行求导,导数为0的地方就是极值的地方。
敲黑板,敲黑板,这是推导的核心。
so,现在我们把
简写成
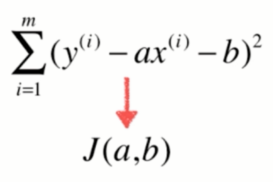
,对它求极值也就是:
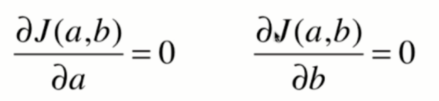
好了,先对b求导:
第一步:求导
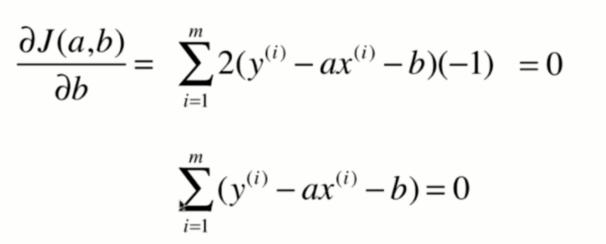
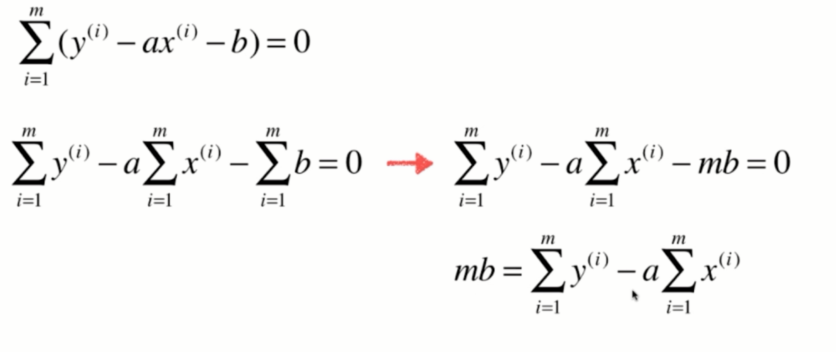
第三步 : 求出b
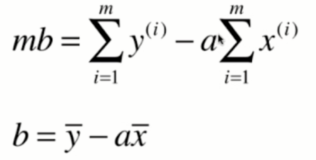
求出b后,我们接下来对a求导:
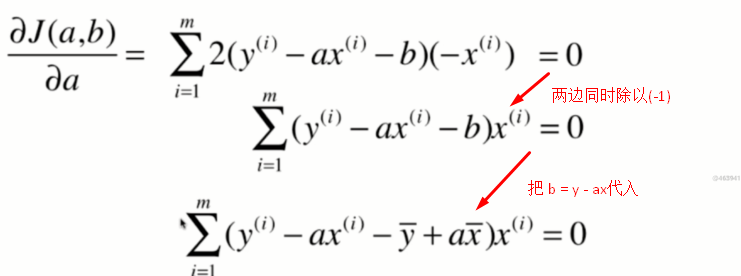
现在要整理一下这个式子,让a可以单独提取出来:

之后提取出a:
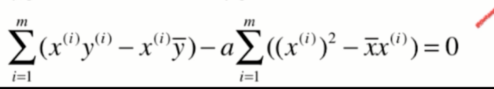
整理后就得到a的表达式:
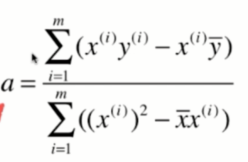
a求解出来了,但是不够简单,现在我们要对它再进行变形。
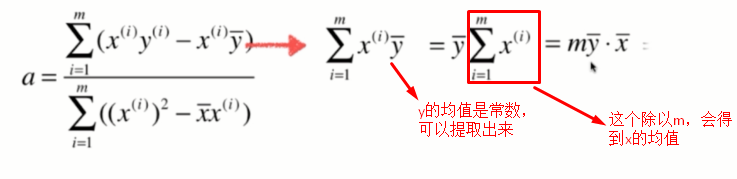
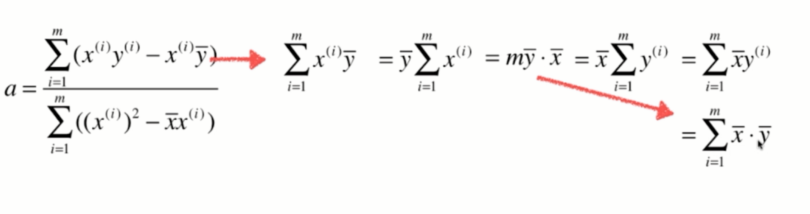
有了这个结论后,我们就可以对式子进行变形:
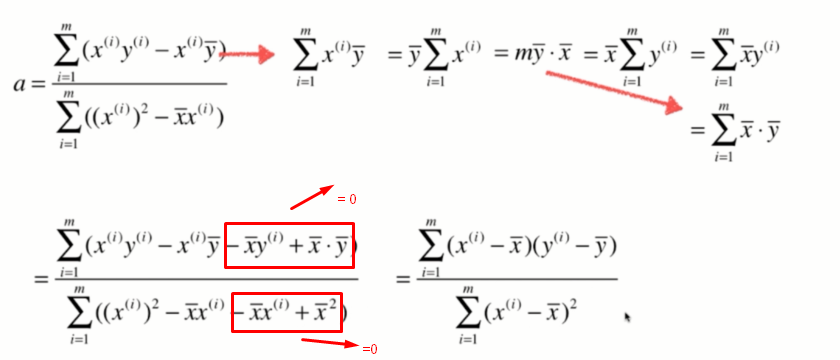
最终我们得到了稍微好看一点的a了:
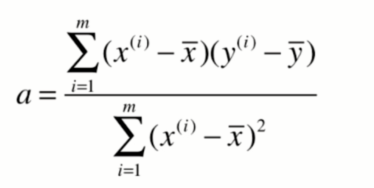
最终a和b的方程如下:

1.2 简单线性回归的实现
接下来,要用代码实现一下简单线性回归算法。
这里定义成
SimpleLinearRegression1是有原因的,因为后面会进行优化这个算法~这个只是初版。
class SimpleLinearRegression1:
def __init(self):
self.a_ = None
self.b_ = None
def fit(self,x_train,y_train):
assert x_train.ndim == 1, "Simple Linear Regressor can only solve single data"
assert len(x_train) == len(y_train),\
"the size of x_train must be equal to the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = 0.0
d = 0.0
for x_i, y_i in zip(x_train, y_train):
num += (x_i - x_mean) * (y_i - y_mean)
d += (x_i - x_mean) ** 2
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self,x_predict):
assert x_predict.ndim == 1,\
"Simple Linear Regressor can only solve single feature data"
assert self.a_ is not None and self.b_ is not None,\
"must fit before predict"
return np.array([self._predict(x) for x in x_predict])
def _predict(self,x_single):
return self.a_ * x_single + self.b_
只要你把上面看懂了,这个代码没什么难度。 现在我们测试一下:
- 先假造一下测试数据集:
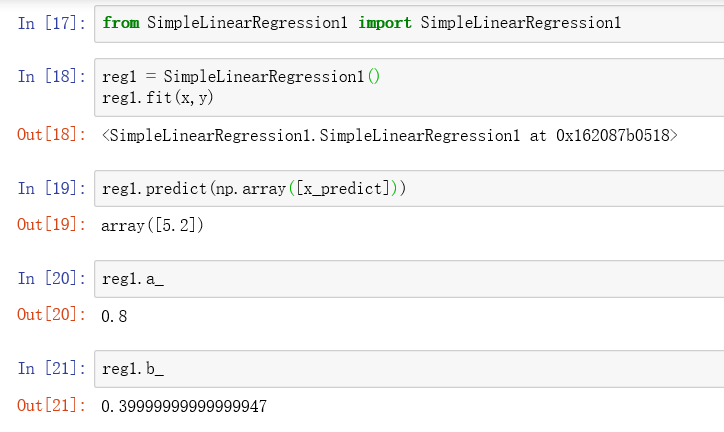
- 调用我们写好的算法进行建模和预测
1.3 向量化
由于采用for循环效率是比较低的,所以我们要把for循环转成采用向量的计算。
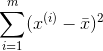
可以看成是下面的向量相乘:
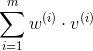
而我们知道,如果把w和v两个向量定义成下图中的样子:
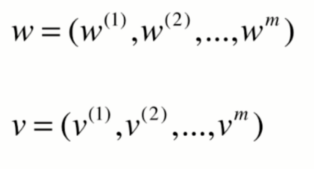
那么此时,公式可以转化成:
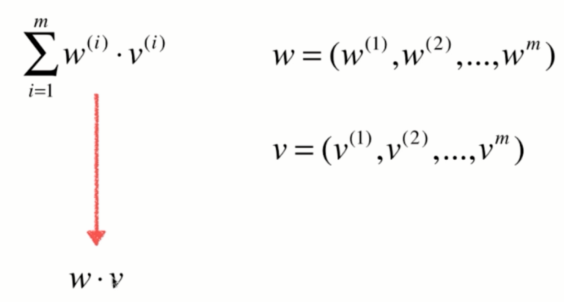
这样我们就可以使用numpy中的向量操作了。
现在我们也明白了,之前为什么一定要把a简化成这种形式,因为这种形式方便转化成向量。
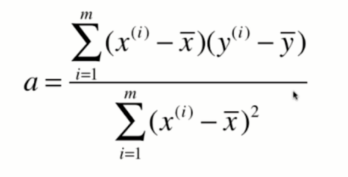
1.4 向量化算法实现
接下来我们改造一下之前采用for循环写的线性回归算法:
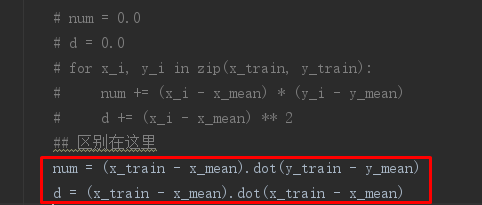
只要把for循环变成乘就可以了。
1.5 性能测试
接下来,我们进行两个线性回归算法的性能测试。
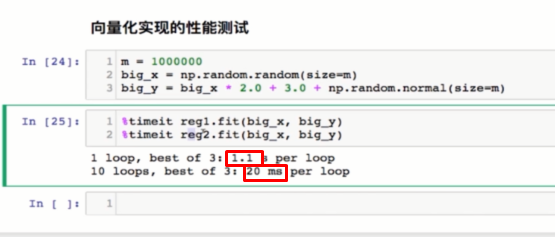
对于一个10万的计算量,采用for循环的每一次计算耗时1.1s,而向量才20ms。差距很大。
下一篇,将完成回归算法衡量指标相关内容,加油~

前路漫漫
