

前言
我们上一节讲了关于 MapReduce 中的应用场景和架构分析,最后还使用了一个CountWord的Demo来进行演示,关于MapReduce的具体操作。如果还不了解的朋友可以看看上篇文章:初识MapReduce的应用场景(附JAVA和Python代码)
接下来,我们会讲解关于MapReduce的编程模型,这篇文章的主要目的就是讲清楚Mapreduce的编程模型有多少种,它们之间是怎么协调合作的,会尽量从源码的角度来解析,最后就是讲解不同的语言是如何调用Hadoop中的Mapreduce的API的。
目录
- MapReduce 编程模型的框架
- 五种编程模型的详解
- InputFormat
- OutPutFormat
- Mapper
- Reducer
- Partitioner
- 总结
MapReduce 编程模型的框架
我们先来看一张图,关于MapReduce的编程模型
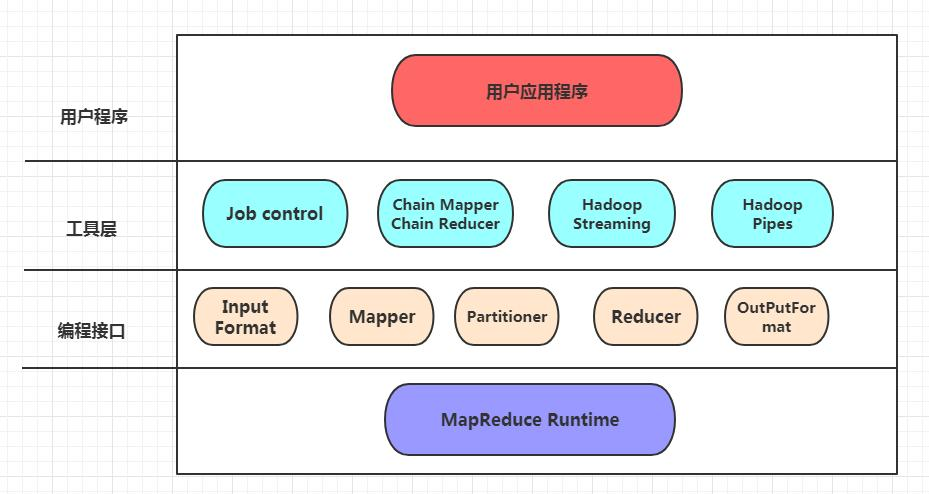
- 用户程序层
用户程序层是指用户用编写好的代码来调用MapReduce的接口层。
-
工具层
- Job control 是为了监控
Hadoop中的MapReduce向集群提交复杂的作业任务,提交了任务到集群中后,形成的任务是一个有向图。每一个任务都有两个方法submit()和waitForCompletion(boolean),submit()方法是向集群中提交作业,然后立即返回,waitForCompletion(boolean)就是等待集群中的作业是否已经完成了,如果完成了,得到的结果可以当作下个任务的输入。 chain Mapper和chain Reducer的这个模块,是为了用户编写链式作业,形式类似于Map + Reduce Map *,表达的意思就是只有一个Reduce,在Reduce的前后可以有多个MapHadoop Streaming支持的是脚本语言,例Python、PHP等来调用Hadoop的底层接口,Hadoop Pipes支持的是C++来调用。
- Job control 是为了监控
-
编程接口层,这一层是全部由
Java语言来实现的,如果是Java来开发的话,那么可以直接使用这一层。
详解五种编程模型
InputFormat
作用
对输入进入MapReduce的文件进行规范处理,主要包括InputSplit和RecordReader两个部分。TextOutputFormat是默认的文件输入格式。
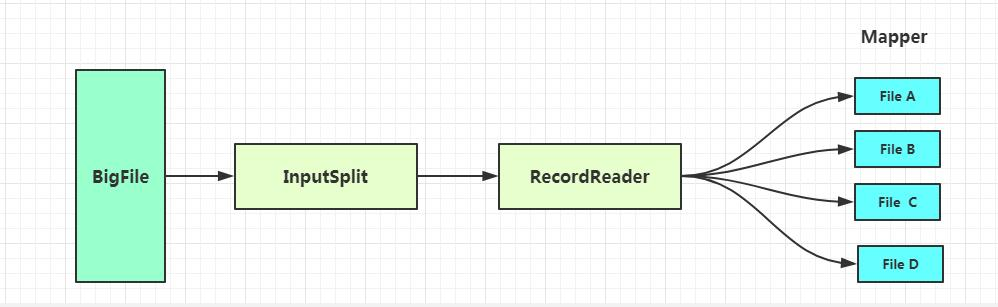
InputSplit
这个是指对输入的文件进行逻辑切割,切割成一对对Key-Value值。有两个参数可以定义InputSplit的块大小,分别是mapred.max.split.size(记为minSize)和mapred.min.split.size(记为maxSize)。
RecordReader
是指作业在InputSplit中切割完成后,输出Key-Value对,再由RecordReader进行读取到一个个Mapper文件中。如果没有特殊定义,一个Mapper文件的大小就是由Hadoop的block_size决定的,Hadoop 1.x中的block_size是64M,在Hadoop 2.x中的
block_size的大小就是128M。
切割块的大小
在Hadoop2.x以上的版本中,一个splitSize的计算公式为
splitSize = max\{minSize,min\{maxSize, blockSize\}\}
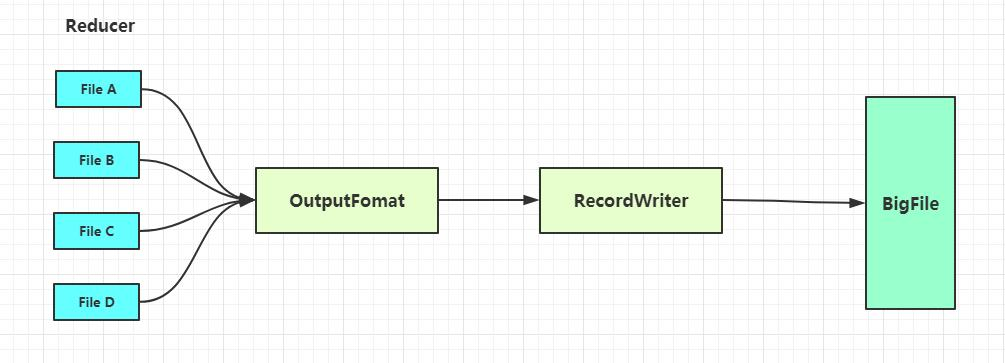
OutputFormat
作用
对输出的文件进行规范处理,主要的工作有两个部分,一个是检查输出的目录是否已经存在,如果存在的话就会报错,另一个是输出最终结果的文件到文件系统中,TextOutputFormat是默认的输出格式。
OutputCommiter
OutputCommiter的作用有六点:
- 作业(
job)的初始化
//进行作业的初始化,建立临时目录。
//如果初始化成功,那么作业就会进入到 Running 的状态
public abstract void setupJob(JobContext var1) throws IOException;
- 作业运行结束后就删除作业
//如果这个job完成之后,就会删除掉这个job。
//例如删除掉临时的目录,然后会宣布这个job处于以下的三种状态之一,SUCCEDED/FAILED/KILLED
@Deprecated
public void cleanupJob(JobContext jobContext) throws IOException {
}
- 初始化
Task
//初始化Task的操作有建立Task的临时目录
public abstract void setupTask(TaskAttemptContext var1) throws IOException;
- 检查是否提交
Task的结果
//检查是否需要提交Task,为的是Task不需要提交的时候提交出去
public abstract boolean needsTaskCommit(TaskAttemptContext var1) throws IOException;
- 提交
Task
//任务结束的时候,需要提交任务
public abstract void commitTask(TaskAttemptContext var1) throws IOException;
- 回退
Task
//如果Task处于KILLED或者FAILED的状态,这Task就会进行删除掉临时的目录
//如果这个目录删除不了(例如出现了异常后,处于被锁定的状态),另一个同样的Task会被执行
//然后使用同样的attempt-id去把这个临时目录给删除掉,也就说,一定会把临时目录给删除干净
public abstract void abortTask(TaskAttemptContext var1) throws IOException;
处理Task Side-Effect File
在Hadoop中有一种特殊的文件和特殊的操作,那就是Side-Eddect File,这个文件的存在是为了解决某一个Task因为网络或者是机器性能的原因导致的运行时间过长,从而导致拖慢了整体作业的进度,所以会为每一个任务在另一个节点上再运行一个子任务,然后选择两者中处理得到的结果最快的那个任务为最终结果,这个时候为了避免文件都输入在同一个文件中,所以就把备胎任务输出的文件取作为 Side-Effect File
RecordWriter
这个是指输出KEY-VALUE对到文件中。
Mapper和Reducer
详解Mapper
InputFormat 为每一个 InputSplit 生成一个 map 任务,mapper的实现是通过job中的setMapperClass(Class)方法来配置写好的map类,如这样
//设置要执行的mapper类
job.setMapperClass(WordMapper.class);
其内部是调用了map(WritableComparable, Writable, Context)这个方法来为每一个键值对写入到InputSplit,程序会调用cleanup(Context)方法来执行清理任务,清理掉不需要使用到的中间值。
关于输入的键值对类型不需要和输出的键值对类型一样,而且输入的键值对可以映射到0个或者多个键值对。通过调用context.write(WritableComparable, Writable)来收集输出的键值对。程序使用Counter来统计键值对的数量,
在Mapper中的输出被排序后,就会被划分到每个Reducer中,分块的总数目和一个作业的reduce任务的数目是一样的。
需要多少个Mapper任务
关于一个机器节点适合多少个map任务,官方的文档的建议是,一个节点有10个到100个任务是最好的,如果是cpu低消耗的话,300个也是可以的,最合理的一个map任务是需要运行超过1分钟。
详解Reducer
Reducer任务的话就是将Mapper中输出的结果进行统计合并后,输出到文件系统中。
用户可以自定义Reducer的数量,使用Job.setNumReduceTasks(int)这个方法。
在调用Reducer的话,使用的是Job.setReducerClass(Class)方法,内部调用的是reduce(WritableComparable, Iterable<Writable>, Context)这个方法,最后,程序会调用cleanup(Context)来进行清理工作。如这样:
//设置要执行的reduce类
job.setReducerClass(WordReduce.class);
Reducer实际上是分三个阶段,分别是Shuffle、Sort和Secondary Sort。
shuffle
这个阶段是指Reducer的输入阶段,系统会为每一个Reduce任务去获取所有的分块,通过的是HTTP的方式
sort
这个阶段是指在输入Reducer阶段的值进行分组,sort和shuffle是同时进行的,可以这么理解,一边在输入的时候,同时在一边排序。
Secondary Sort
这个阶段不是必需的,只有在中间过程中对key的排序和在reduce的输入之前对key的排序规则不同的时候,才会启动这个过程,可以通过的是Job.setSortComparatorClass(Class)来指定一个Comparator进行排序,然后再结合Job.setGroupingComparatorClass(Class)来进行分组,最后可以实现二次排序。
在整个reduce中的输出是没有排序
需要多少个 Reducer 任务
建议是0.95或者是1.75*mapred.tasktracker.reduce.tasks.maximum。如果是0.95的话,那么就可以在mapper任务结束时,立马就可以启动Reducer任务。如果是1.75的话,那么运行的快的节点就可以在map任务完成的时候先计算一轮,然后等到其他的节点完成的时候就可以计算第二轮了。当然,Reduce任务的个数不是越多就越好的,个数多会增加系统的开销,但是可以在提升负载均衡,从而降低由于失败而带来的负面影响。
Partitioner
这个模块用来划分键值空间,控制的是map任务中的key值分割的分区,默认使用的算法是哈希函数,HashPartitioner是默认的Partitioner。
总结
这篇文章主要就是讲了MapReduce的框架模型,分别是分为用户程序层、工具层、编程接口层这三层,在编程接口层主要有五种编程模型,分别是InputFomat、MapperReduce、Partitioner、OnputFomat和Reducer。主要是偏理论,代码的参考例子可以参考官方的例子:WordCount_v2.0
这是MapReduce系列的第二篇,接下来的一篇会详细写关于MapReduce的作业配置和环境,结合一些面试题的汇总,所以接下来的这篇还是干货满满的,期待着就好了。
更多干货,欢迎关注我的公众号:spacedong

