

- 原文地址:medium.com
- 原文作者:Max Grigorev
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:TUARAN
- 校对者:xionglong58, Fengziyin1234
2019,跟上 AI 的脚步:AI 和 ML 接下来会发生什么重要的事?
过去的一年,在 AI 领域里发生了许多事情,也有很多发现和丰富的发展。很难在各种观点中提取出有效的信号,如果它存在,那么这个信号又说明了什么。这篇文章的目的正在于此:我将尝试提取过去一年在 AI 领域里一些共通的模式。如果幸运的话,我们将看到一些(AI 的)趋势是如何延伸到不久的将来。
有这样的一种说法(黑猫类比):“最难的事就是在一间黑暗的房间里找到一只黑猫,尤其是房间里没有猫的时候。”多么智慧啊。

看见那只猫了吗?
毫无疑问,这是一篇观点文章。我并不是要全面的记录 AI 这一年的成就。我只是想概诉一下这些趋势中的一些。另外声明:这篇文章的论点以美国为中心。比如,在中国,正发生许多有趣的事,但不幸的是,我对那令人兴奋的生态系统并不熟悉。
这篇博文适合谁看?如果你还在继续阅读,它可能适合你:一个想要开阔眼界的工程师;一个寻找下一步他们的精力将投向何处的企业家;一个寻找下一笔交易的投资家;或者只是一名为技术欢呼的人,迫不及待的想知道这股旋风将把我们带往何处。
算法
算法论述,无疑是由深度神经网络主导的。当然,你会听到有人在到处部署一个“经典的”机器学习模型(比如梯度提升树或者多臂老虎机)。并声称这是所以人需要的唯一的东西。有人声称深度学习正处于垂死挣扎的境地。即使是顶级研究人员也在质疑某些 DNN 架构的效率和健壮性。但是,不论你承不承认,DNNs 无处不在:在自动驾驶汽车中,在自然语言系统中,在机器人中 —— 你能说上名字的任何事上。DNNs 在比如自然语言处理、生成式对抗网络和深层强化学习上有着最为明显的飞跃。
深度自然语言处理:BERT 等
尽管在2018年以前,DNNs 在文本研究上已经取得了一些突破(例如 word2vec、GLOVE 和 LSTM-based 模型),但是它(DNNs)缺少一个关键的概念上的元素:迁移学习。就是说,在大量公开可用的数据上来训练一个模型,然后在您使用的特定数据集上“微调”它。在计算机视觉中,使用在著名的 ImageNet 数据集上发现的模式来解决特定的问题通常是解决方案的一部分。
问题是,用于迁移学习的技术并不能很好地应用于 NLP 问题。从某种意义上说,像 word2vec 这样的预先训练嵌入式的程序填补了这一空缺,但是它们只能在单词级别上工作,无法捕捉语言的高级结构。
然而,到了2018年,情况发生了变化。ELMo,情境化嵌入成为改善 NLP 迁移学习的第一个重要步骤。 ULMFiT 甚至更进一步:由于对嵌入式的语义捕获能力不满意,作者找到了一种对整个模型采用迁移学习的方法。

就是这个人!
但最有趣的发展无疑是 BERT 的引入。通过让语言模型从英语维基百科的所有文章中学习,团队能够在 11 个 NLP 任务上得到最先进的结果 —— 相当了不起!更好的是,代码和预训练模型都是在线发布的 —— 因此您可以将这一突破应用于您自己的问题。
GANs 的多面
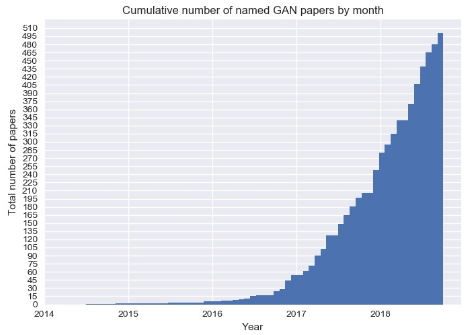
CPU 速度不再呈指数级增长,但是关于生成式对抗网络 (GANs) 的学术论文的数量似乎还在继续增长。GANs 多年来一直是学术界的宠儿。然而,现实生活中的应用程序似乎少之又少,而且在2018年几乎没有什么变化。GANs 仍然有惊人的潜力等待被发现。
新出现的方法是逐步增加使用 GANs:让生成器在整个训练过程中逐步提高输出的分辨率。一篇令人印象深刻的论文样式转换技术来生成逼真的照片使用了这种方法。有多么逼真呢?你告诉我:

这些照片中哪一张是真人?有陷阱的问题:没有一个是真的。
然而,GANs 真正的工作方式和原因是什么呢?我们还没有深入了解这个问题,但是已经采取了一些重要的步骤:麻省理工学院的一个研究小组针对这个问题做了一个高质量的研究。
另一个有趣的应用,虽然在技术上使用的不是 GAN,而是 Adversarial Patch。这个想法是使用黑盒(也就是说,不查看神经网络的内部状态)和白盒方法来创建一个“补丁”,这将欺骗 CNN-based 分类器的“补丁”。这是一个重要的结果:它可以引导我们更好地理解 DNNs 是如何工作的,以及我们离人类层次的概念感知还有多远。
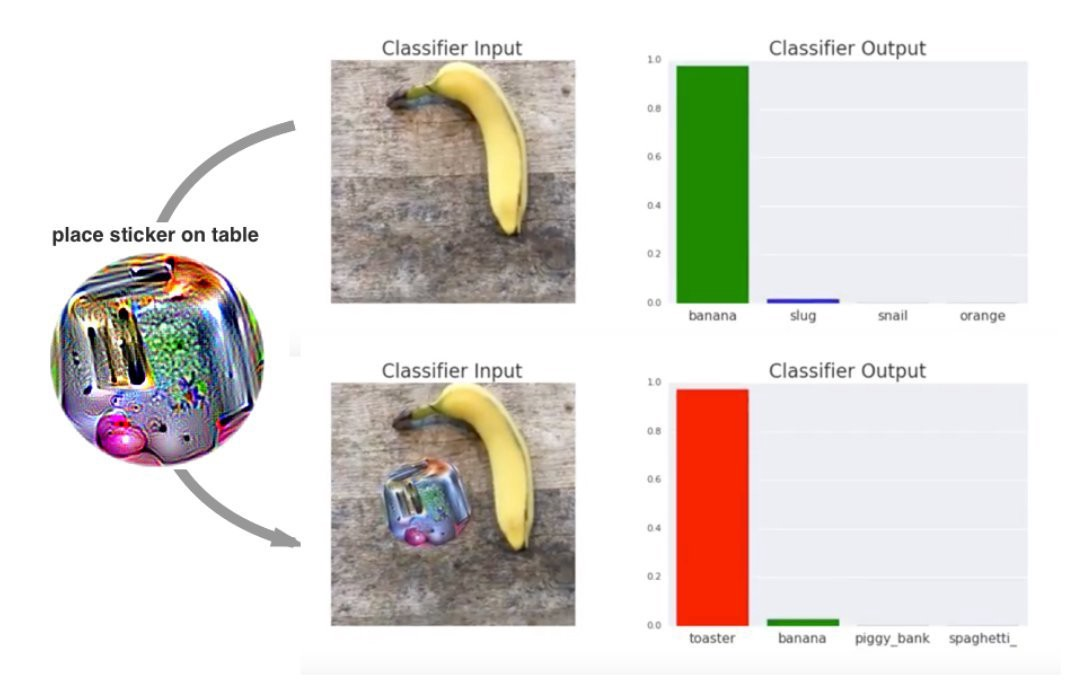
你能分辨香蕉和烤面包机吗?AI 仍然不能。
我们需要强化学习
自2016年 AlphaGo 战胜李世石以来,强化学习一直备受关注。尽管 AI 已经统治了最后一款“经典”游戏,但我们还需要征服什么呢?整个世界!特别是电脑游戏和机器人。
对于训练来说,强化学习依赖于“奖励”信号,这是对它在最后一次尝试中表现如何的评分。电脑游戏提供了一个自然的环境,在那里这样的信号很容易得到,而不是在现实生活中。因此,RL(强化学习)研究的所有注意力都集中在如何教 AI 玩雅达利游戏上。
谈到他们的新发明 DeepMind,AlphaStar 再次成为新闻。这个新模式打败了星际争霸 II 的一个顶级职业玩家。星际争霸比国际象棋或围棋要复杂得多,它拥有巨大的行动空间和隐藏在玩家面前的关键信息,这与大多数棋盘游戏不同。这一胜利对整个领域来说是一个非常重大的飞跃。
OpenAI,这个领域的另一个重要玩家,也没有闲着。他们因 OpenAI Five 而成名,在8月份,该系统在一款极其复杂的电子竞技游戏《dota2》中击败了99.95%的玩家。
尽管OpenAI一直在关注电脑游戏,但他们并没有忽视 RL 真正的潜在应用:机器人。在现实世界中,人们给机器人的反馈很少,而且制作起来也很昂贵:你基本上需要一个人照看你的 R2D2,当它正试图迈出第一步。你需要数以百万计的数据点。为了弥补这一差距,最近的趋势是学习模拟环境,并在投入实际应用之前并行运行大量这些场景,以传授机器人基本的技能。OpenAI 和谷歌都在研究这种方法。
荣誉奖:Deepfakes
Deepfakes 是一种图片或视频,通常显示一个公众人物在做或在说他们从未做过或说过的事情。它们是通过在大量“目标”人物的镜头上训练 GAN 来创建的,然后生成新媒体,并在其中执行所需的操作。一款名为 FakeApp 的桌面应用程序于 2018 年 1 月发布,它允许任何一个拥有电脑却没有任何计算机科学知识的人制造 deepfakes。虽然由它制作的视频很容易被发现不是正品,但这项技术已经进步了很多。看看这个视频就知道了。
谢谢你,奥巴马?
基础结构
TensorFlow vs PyTorch
现在已经有很多深度学习框架。这个领域是广阔的,这种多样性在表层上是合理的。但在实践中,近来大多数人要么使用 Tensorflow,要么使用 PyTorch。如果您关心可靠性、部署的简易、模型的重新加载,以及 SREs 通常关心的事情,那么您可能会选择 Tensorflow。如果你正在写一篇研究论文,但没有在谷歌工作 —— 你可能用过 PyTorch。
ML作为一种服务无处不在
今年我们看到了更多的人工智能解决方案,它们被打包成一个 API 供软件工程师使用,这些工程师不需要有斯坦福大学机器学习博士学位的朋友在身边。Google Cloud 和 Azure 都改进了旧的服务并添加了新服务。AWS 机器学习服务列表开始变得让人觉着可怕。

天哪,AWS很快就需要二级文件夹的层次结构来提供服务了。
尽管这股热潮已经有所降温, 但是多家初创公司都向它(提供ML 服务)发出了挑战。每家公司都承诺模型训练的速度,推理过程中的易用性和惊人的模型性能。只需输入你的信用卡,上传你的数据集,给模型一些时间来训练或完善,调用一个 REST(或者,对于更有前瞻性的初创公司来说,则选择 GraphQL API,成为 AI 的大师,甚至不需要弄清楚什么是随机失活。
有了这么多的选择,为什么还有人会费心自己构建模型和基础结构呢?实际上,似乎市面上的 MLaaS 产品可以很好地处理80%的用例。如果你想让剩下的20%也能正常工作 —— 那你就太不幸了:你不仅不能真正选择模型,甚至不能控制超参数。或者,如果您需要在云计算之外的某个地方进行推导 —— 这通常不能做到。这绝对是一种权衡。
荣誉奖:AutoML 和 AI Hub
今年推出的两项特别有趣的服务都是由谷歌推出的。
首先,谷歌 Cloud AutoML 是一套针对 NLP 和计算机视觉模型训练而定制的产品。这是什么意思呢? AutoML 设计器通过自动微调几个预先培训的模型并选择其中性能最好的模型来解决模型的定制问题。这意味着您很可能不需要自定义模型。当然,如果你想做一些真正新的或不同的事情,那么这个服务将不再适合你。但是,作为附带的好处,谷歌在大量专有数据的基础上对他们的模型进行了预先培训。想想所有这些猫的照片;这些比 Imagenet 生成的要好的多
其次,AI Hub 和 TensorFlow Hub。在这两者之前,重用某个人的模型着实是一件苦差事。GitHub 上的随机代码很少工作,文档记录也很差,而且通常不太好处理。还有用于迁移学习的预先训练的权重......你根本都不会试图让他们能正常工作。这正是 TF Hub 要去解决的问题:它是一个可靠的、经过策划的模型存储库,您可以对其进行微调或构建。只需包含几行代码 —— TF Hub 客户端将从谷歌的服务器获取代码和相应的权重 —— 瞧,它可以工作了!AI Hub 则更进一步:它允许您共享整个 ML 信道,而不仅仅是模型!它一直在 alpha 中,它已经比那些文件(什么样的文件呢? 那些最新的 file 是三年前修改的文件。)更加好了,如果您明白我的意思。
硬件
英伟达
如果你在2018年认真了解过 ML,特别是 DNNs,你用过了一个 GPU(或多个)。与此同时,GPU 的领导度过了非常忙碌的一年。在加密热潮降温和随后的股价暴跌之后,英伟达发布了一套基于图灵架构的新一代消费卡。在 2017 年发布了基于 Volta 芯片的专业卡,新卡包含了新的高速矩阵乘法硬件,我们称之为 Tensor Cores。矩阵乘法是 DNNs 的核心,加快这些运算将大大提高神经网络在新的 GPU 上的运行速度。
针对那些对“小”和“慢”的游戏 GPU 不满意的人,英伟达更新了他们的企业级 GPU “超级计算机”。相较于480 TFLOPs的FP16操作来说,DGX-2 是 16 Tesla 系列的怪物。并且价格也被刷新,高达 40 万美元。
自主式硬件也得到了更新。英伟达希望 Jetson AGX Xavier 主板将为下一代自动驾驶汽车助力。一个八核的 CPU,一个视觉加速器,以及深度学习加速器 —— 这是发展中的自动驾驶行业所需要的一切。
在一项有趣的开发中,英伟达为其游戏卡增加了 DNN-based 的特性:深度学习超抽样。这个想法是为了取代抗锯齿处理,目前主要是通过呈现比所需分辨率(比如 4x )更高的图片,然后将其缩放到本机监视器的分辨率来实现的。现在,英伟达允许开发者在发布游戏之前,对运行在游戏上的图像转换模型进行高质量的运行。之后,游戏将使用预训练模型交付给最终用户。在游戏过程中,不需要花费老式的抗锯齿的代价,帧通过在模型上的运行来提高图像质量。
英特尔
2018年,英特尔绝对不是 AI 硬件领域的开拓者。但他们似乎想要改变这一点。
令人惊讶的是,英特尔的大多数活动都发生在软件领域。英特尔正在努力使他们现有的和即将推出的硬件对开发者更加友好。考虑到这一点,他们发布了两个(令人惊讶的,有竞争力的)工具包:OpenVINO 和 nGraph。
他们更新了他们的 Neural Compute Stick:一个小型 USB设备,可以加速DNNs 在任何 USB 端口上运行,甚至是在 Raspberry Pi 上。
关于 Intel 离散型 GPU 阴谋的传闻也越来越多。流言蜚语愈演愈烈,但新设备在 DNNs 应用的适用性还有待观察。真正适用于深度学习的是传说中两张专业深度学习卡,代号为 Spring Hill 和 Spring Crest ,后者是基于多年前英特尔收购的创业公司 Nervana 的技术。
来自通常(和不寻常)的怀疑对象的自定义硬件
谷歌发布了他们的第三代 tpu:一个基于 asic 的 dnn 专用加速器,拥有惊人的 128Gb HMB 内存。256 个这样的设备被组装成一个性能超过 100 千万亿次的吊舱。今年,谷歌让谷歌云上的公众可以使用 tpu,而不仅仅是用这些设备的强大来戏弄世界其他地方。
与此类似,但主要是针对推理应用程序,Amazon 部署了 AWS Inferentia:一种在生产环境中运行模型的更便宜、更有效的方法。
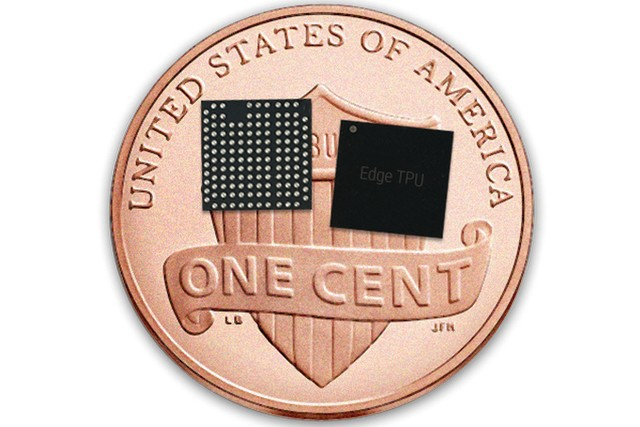
谷歌还宣布 Edge TPU:上面讨论的大烂牌的小弟弟。这种芯片很小:一枚 1 美分硬币的表面可以容纳 10 枚。同时,它可以在实时视频上运行 DNNs,几乎不消耗任何能量。
一个有趣的潜在新参与者是Graphcore。这家英国公司已经筹集了令人印象深刻的3.1亿美元,并在2018年推出了他们的第一款产品—— GC2芯片。根据 benchmark,GC2 在进行推算时,会在消耗更少的功耗的情况下,清除顶级的 Nvidia 服务器 GPU 卡。
荣誉奖:AWS Deep Racer
亚马逊推出了一款小型自动驾驶汽车DeepRacer,并为此成立了一个赛车联盟。这款售价 400 美元的汽车配备了 Atom 处理器、 4MP 摄像头、wifi、多个 USB 端口以及足够运行数小时的电量。自动驾驶模型可以完全在云端使用 3d 仿真环境进行训练,然后直接部署到汽车上。如果你一直梦想着制造自己的自动驾驶汽车,这是你不用开一家由风投支持的公司就能实现这一梦想的机会。
接下来是什么?
把注意力转移到决策智能上
现在的组件 —— 算法、基础结构和硬件 —— 让 AI 比以往任何时候都要好用,企业正在意识到,应用人工智能的最大障碍在于实用性:如何将人工智能从一个想法应用到生产中运行的有效、安全、可靠的系统中去?应用人工智能,或称应用机器学习 (ML),也被称为决策智能,是一门为现实问题创建人工智能解决方案的科学。虽然过去将大部分注意力放在算法背后的科学上,但未来可能会更多地关注该领域端到端的应用程序方面。
人工智能创造的就业机会似乎比它消灭的要多
“人工智能将抢走我们所有的工作”是媒体的普遍说辞,也是蓝领和白领工人的共同担忧。从表面上看,这似乎是一个合理的预测。但到目前为止,事实似乎正好相反。例如,许多人通过创建带标签的数据集而获得报酬。
这些报酬超越了低收入国家通常的收入:有几个应用程序,比如 LevelApp,可以让生活困难的人民仅用手机给自己的数据贴上标签就能赚钱。Harmoni 更进一步:他们甚至向难民营里的移民提供设备,让他们可以贡献自己的力量,并以此谋生。
在数据标签的基础上,新的人工智能技术正在创造整个行业。我们能够做的事情,在几年前甚至是不可想象的,像自动驾驶汽车或药物发现。
更多与 ML 相关的计算将出现在边缘
在面向数据的系统的工作方式中,通常在系统的边缘,即采集端,有更多的数据可用。信道的后期通常以向下采样或以其他方式降低信号的保真度。另一方面,随着越来越复杂的人工智能模型表现得越来越好,数据也越来越多。使人工智能组件更靠近数据的边缘不是更有意义吗?
一个简单的例子:想象一个高分辨率的相机,它能以 30 fps 的速度产生高质量的视频。处理视频的计算机视觉模型,在服务器上运行。摄像机将视频传输到服务器,但上行带宽有限,因此视频被压缩和高度压缩。为什么不将视觉模型移动到摄像机并使用原始视频流呢?
这方面总是存在许多障碍,主要是:边缘设备上可用的计算能力的数量和管理的复杂性(例如将更新的模型推到边缘)。随着专用硬件(如谷歌的 Edge TPU、苹果的神经引擎等)、更高效的模型和优化的软件的出现,计算的局限性正在被消除。通过改进 ML 框架和工具,可以不断地解决管理的复杂性。
人工智能基础设施领域的整合
在此之前的几年里,人工智能基础设施领域充满了活动:盛大的公告、巨额融资以及崇高的承诺。2018年,太空竞赛似乎降温了,虽然仍有一些重要的新入口,但大部分贡献是由现有的大型参与者做出的。
一种可能的解释是,我们对人工智能系统的理想基础结构的理解是不够成熟。因为问题很复杂。这需要长期的、持续的、专注的、资源充足的努力来产生一个可行的解决方案 —— 这是创业公司和小公司不擅长的。如果一家初创公司突然“解决”了人工智能的基础问题,那将是非常令人惊讶的。
另一方面,ML 基础架构工程师非常少见。对于一家规模更大的公司来说,一家拥有数名员工、但处境艰难的初创公司显然是一个有价值的收购目标。几个玩家希望通过在构建内部和外部工具赢得游,他们都在构建内部和外部工具。例如,对于 AWS 和谷歌云,人工智能基础设施服务是一个主要的卖点。
把它们放在一起,空间的主要整合就成为一个合理的预测。
更多定制的硬件
摩尔定律已经逝去,至少对于 CPU 来说是这样,而且这种情况已经持续了很多年。GPU 很快也将遭遇类似的命运。当我们的模型变得更高效时,为了解决一些更高级的问题,我们需要获得更多的计算能力。这可以通过分布式训练来解决,但是它有自己的限制和权衡。
此外,如果您想在资源受限的设备上运行一些更大的模型,分布式训练是没有帮助的。输入自定义 AI 加速器。根据您想要或可以进行的定制,您可以保存一个量级的电力、成本或延迟。
在某种程度上,甚至英伟达的 Tensor Cores 也是这种趋势的一个例子。在没有通用硬件的情况下,我们将看到更多这样的硬件。
减少对训练数据的依赖
标记数据通常要么昂贵,要么难以访问,要么两条都有。这条规则几乎没有例外。开放的高质量数据集,如 MNIST、ImageNet、COCO、Netflix prize 和 IMDB eviews 是令人难以置信的创新的来源。但是许多问题没有相对应的数据集来处理。虽然对于研究人员来说,建立数据集并不是一个很好的职业发展方向,但能够赞助或发布数据集的大公司并不着急:他们正在建立庞大的数据集,并且把这些数据私密保存。
那么,一个小型独立实体,比如创业公司或大学研究小组,是如找到复杂问题的解决方案的呢?通过构建越来越少地依赖监督信号、越来越多地依赖无标记和非结构化数据的系统 —— 得益于互联网和廉价传感器的普及,这些数据非常丰富。
这在一定程度上解释了人们对 GANs、迁移学习和强化学习兴趣的激增:所有这些技术都需要较少(或不需要)的训练数据的投入。
所以,这只是一个泡沫,对吧?
那间黑屋子里有只猫吗?我想肯定有,不止一个,而是多个。虽然有些猫有四条腿,尾巴和胡须 —— 通常情况下 —— 有些是奇怪的动物,我们只是刚刚开始看到它们的基本轮廓。
行业已经进入了 AI 大热的第七年。在那这段时间里,大量的研究工作、学术资助、风险投资、媒体关注和代码编写被投入到这个领域。但我们有理由指出,人工智能的承诺基本上仍未兑现。我们最后一次乘坐优步时,司机仍然是人类。在早晨仍然没有用机器人下蛋。我甚至不得不自己系鞋带,这到底在搞什么名堂!
然而,无数研究生和软件工程师的努力并没有白费。似乎每一家大公司要么已经严重依赖人工智能,要么计划在未来这么做。AI art sells。如果自动驾驶汽车还没有出现,那它们也在不久后就会出现。
现在,要是有人能理顺这些讨厌的鞋带就好了!等等,什么?他们做到了?
- 点击这里观看完整视频
非常感谢 Malika Cantor、Maya Grossman、Tom White、Cassie Kozyrkov 和 Peter Norvig 阅读本文的初稿
Max Grigorev 在谷歌建立了 ML 系统,Airbnb 和多家创业公司。他希望建造更多。他也是一名 google 开发者。我的良师益友 Max Grigorev。
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
