

在开发一个用selenium+chrome的爬虫项目的时候,原先用点击事件是可以完成所有操作的,但是在deploy上服务器的时候,在点击一个图片的点击事件中,click操作一直超时,大佬说用selenium的xpath定位一直会出问题,让我用By.id或则By.name来定位,但是那个element没有ID和name属性啊。。

然后我选择了用cssSelector万能神器来定位,这里推荐一个偷懒的小窍门,如果是cssSelector和xpath语法写不好的话,可以利用chrome里面自带的小工具来获取
但是用了CSSSelector还是报的超时,click操作超时,我真的是很想吐槽一下,本地跑一直没有问题,速度也很快。
后来大佬就说,直接跑里面的js吧。
然后就是今天的主题了,利用chrome+selenium来跑js。
可以看到那个click时间点击的就是执行一个js方法,在selenium中是有方法可以执行js脚本的。
((JavascriptExecutor) this.driver).executeScript(js);
直接传进去js脚本就行。
我刚开始的做法是,直接调用他的方法。

会发现是报这样一个错,clientY未定义。
看了一下报错,报的是这样子的。
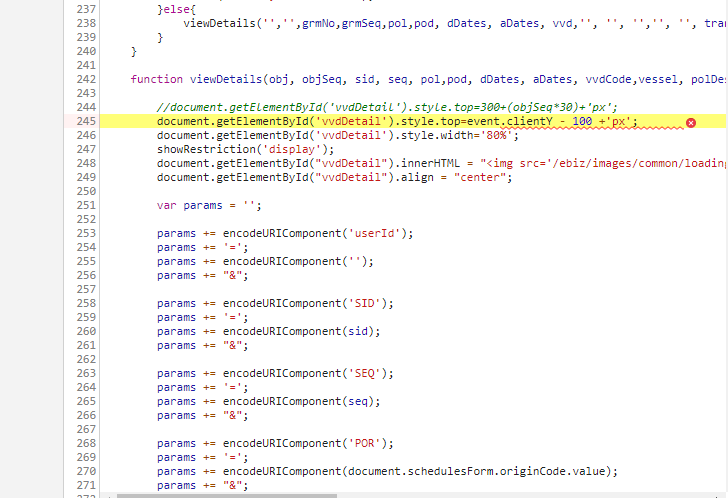
问了一下前端大佬,才发现是因为原先的设计是触发点击事件,然后获取他鼠标悬停的状态,然后来设定新的窗口的位置的。我都没有进行点击事件,那代表event都没有,那clientY必然是获取不到的。
知道原由后,我刚开始想的解决方法是,那就让他获取到鼠标点击事件,让他有这个event,但是想想就觉得不行,如果都能点击了,那之前就不会超时啦。然后就换了一种方案:重写他的js方法,让他的top属性不通过clientY来获取,而是给一个制定好的值,再重新调用这个方法。
在chrome里面的console里面先实验:
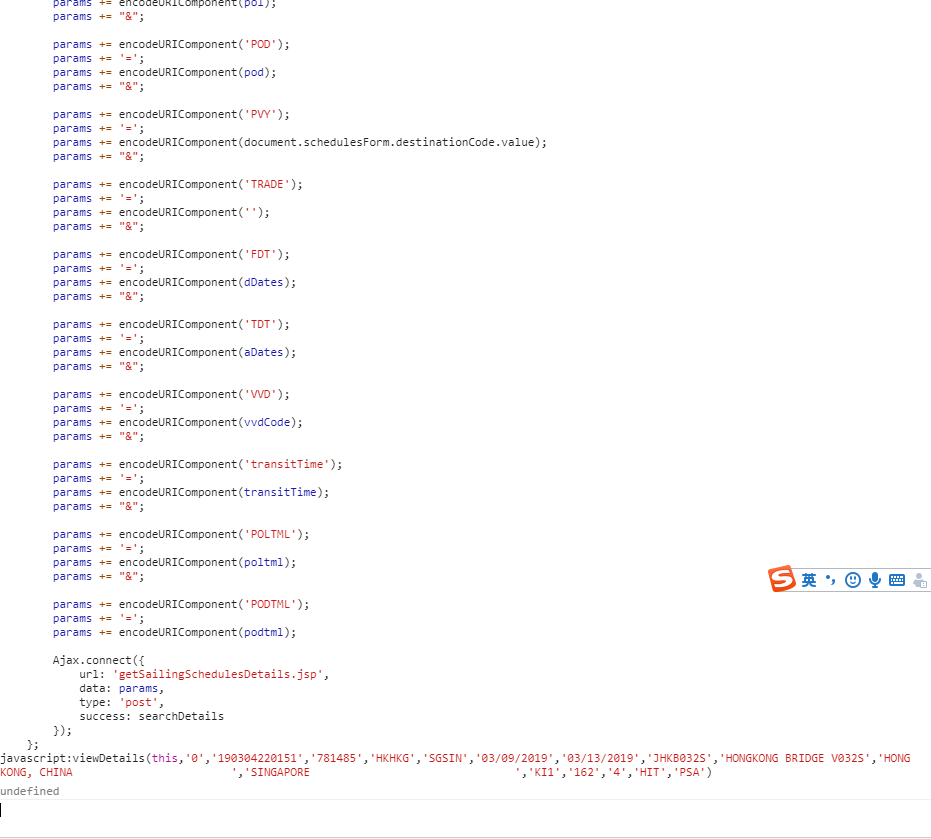
也是第一次发现可以在chrome里面这样子操作,chrome真的是神器,有很多工具真的很好用。
然后换成在后台操作:
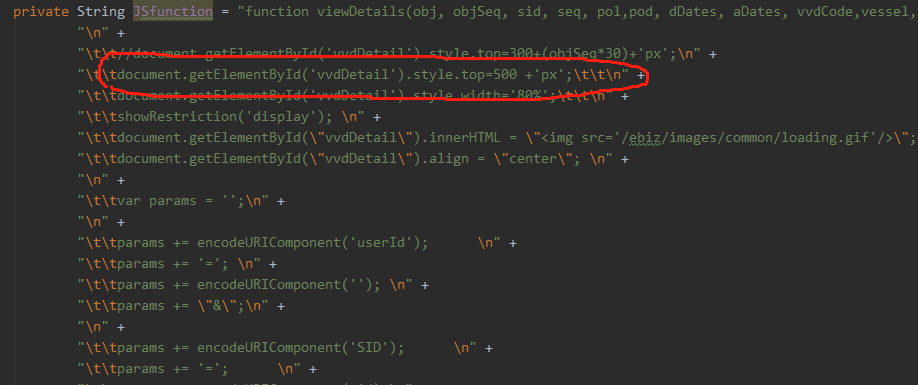

跑unitTest,结果无误。
狗子走丢了,以后就剩我一个人了,一个人也要加油啊。
