ElasticSearch 的核心概念
Near RealTime(NRT) 近实时
近实时有两种意思,一种是从写入数据到可以被搜索到有一个小延迟(大概一秒),还有一种就是基于ElasticSearch 进行搜索和分析可以达到秒级, 下图来说明一下近实时的效果。
- 首先我们先使用Java向ElasticSearch存入一条数据,时间是 ** 2点16分20秒**
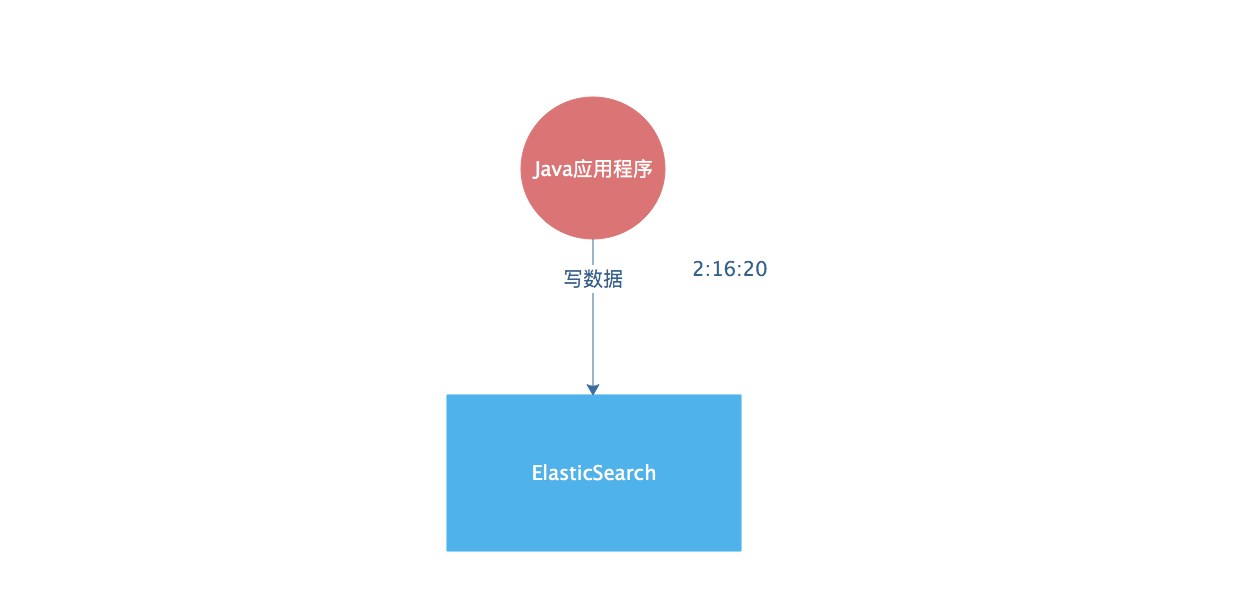
- 在使用一个Java程序从ElasticSearch里面来读取数据,那么在读取数据的时候这个时间的误差应该保持在秒级,不论是这个集群体系有多大,都应该保持这种速度,比如下面这个例子就是将时间延迟控制在了一秒。
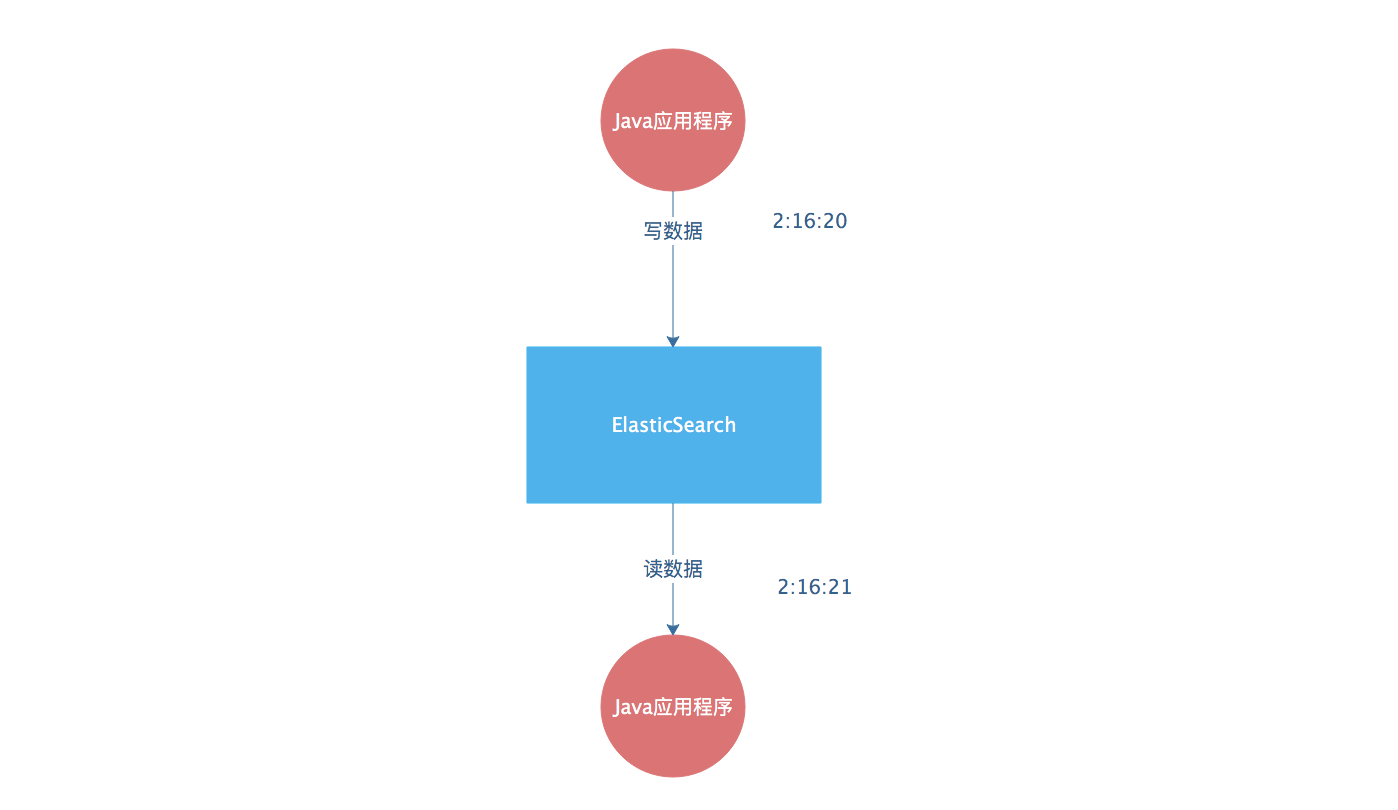
- 这里需要提到一下:实时又分为准实时和近实时,准实时是毫秒级,近实时是秒级
Cluster 集群
集群里面包含多个节点,每个属于那个集群都是通过一个配置(集群名称,默认是elasticSearch)来决定的,对于中小型企业来说,刚开始一个集群就一个节点很正常。
Node 节点
集群里面的一个节点,节点也有一个名称,默认是随机分配的,节点名称很重要(在运维管理操作的时候),每个节点默认会去加入一个名叫 elasticsearch 的集群, 如果直接启动一堆节点,那么他们会自动组成一个名为 elasticsearch 的集群, 当然一个节点也可以组成一个 elasticsearch 集群,只不过状态是yellow(警告),正常的状态应该是green(正常),这个在后面会详细说明为什么会有yellow和green之分。
Document 文档
es中最小的数据单元,它可以是一条简单的客户数据,一条商品分类数据,一条订单数据,通常用json结构表示,每个index下的type中,都可以存储多个document。下面就举例一个简单的商品document。
product document
{
"product_name":"田园布艺沙发",
"product_id":"1",
"category_name": "沙发",
"category_id": "2"
}
Type 类型
一个type里面可以有很多个document,就相当于一个表里面有条记录是一个意思,在ElasticSearch6.0版本之前一个索引是可以有多个type的,但是在6.0之后就只能有一个type了。在7.0过后将会完全抛弃type,为什么type会慢慢的被ElasticSearch移除呢?我们都把type比喻成一张表,把index比喻成数据库,但是在数据库里面的表都是相互独立的,各个字段之间互不影响,但是在ElasticSerarch中,多个type里面如果有相同字段,那么多个type就会同用同一个字段,也就是说他们并不会区分开来,所以后期就慢慢的将type潜移默化了。下面的例子将会展示document在type里面是怎么存储的(这里type和document的数据关系,并不是代表es里面数据结构就是这样,这里只是演示,了解就行)。
{
"type":[
{
"product_name":"田园布艺沙发",
"product_id":"1",
"category_name":"布艺沙发",
"category_id":"2"
},
{
"product_name":"田园实木沙发",
"product_id":"2",
"category_name":"实木沙发",
"category_id":"3"
}
]
}
index 索引
在6.0版本之前index里面可以存多个type,但是在6.0之后就只能存一个type了,这个type里面又有很多的document。就像是下面这样(这里只是体现一个index和type还有document的数据关系,并不是代表es里面数据结构就是这样,这里只是演示,了解就行)
{ "index":{ "type":[ { "product_name":"田园布艺沙发", "product_id":"1", "category_name":"布艺沙发", "category_id":"2" }, { "product_name":"田园实木沙发", "product_id":"2", "category_name":"实木沙发", "category_id":"3" } ] } }
shards 分片
ElasticSearch 中特别重要的一个,先简单介绍一下什么是shards,它是一个数据的分片,这里先大概说明一下,下面就来详细解释一下这个shards为什么重要了。
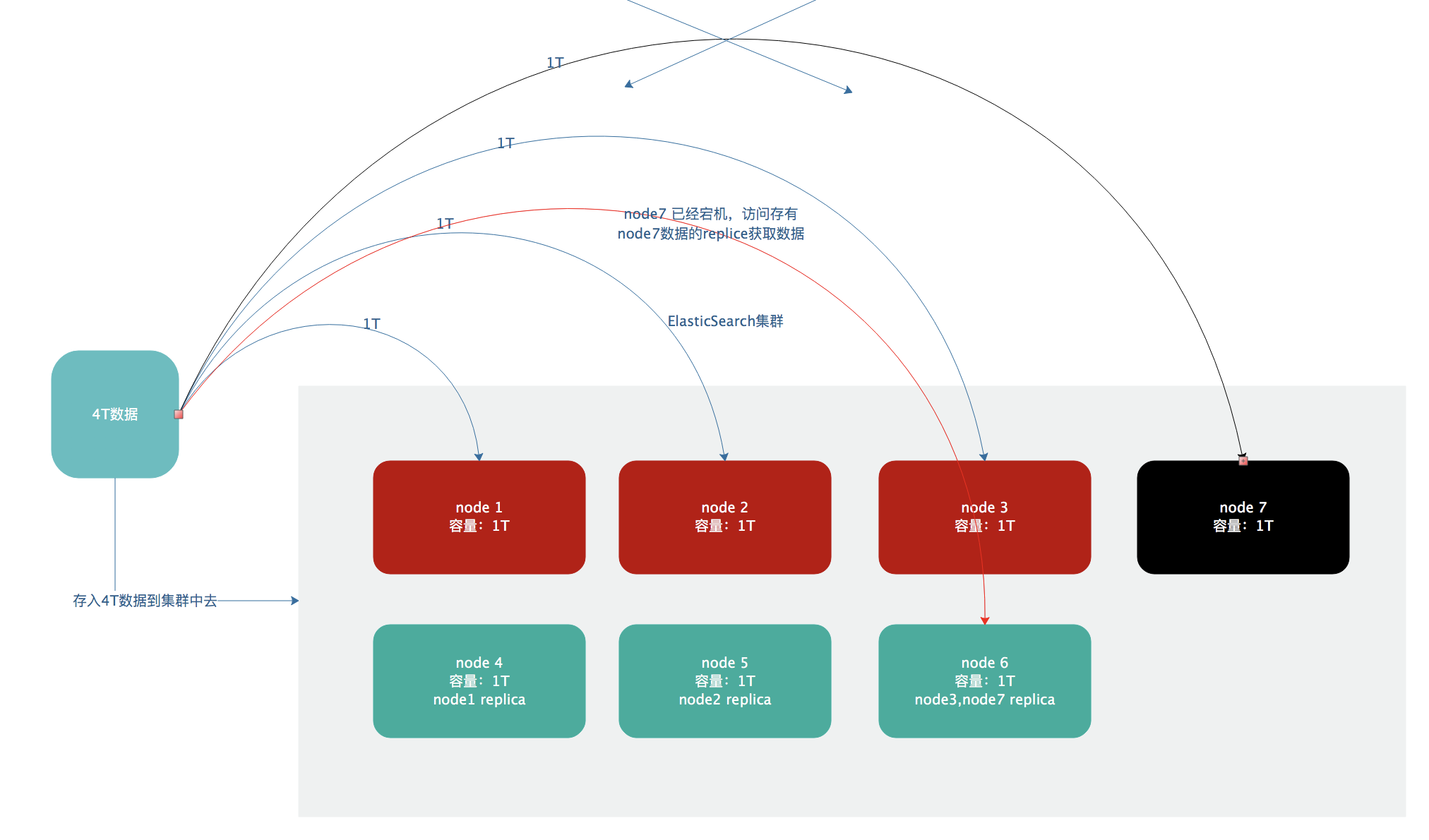
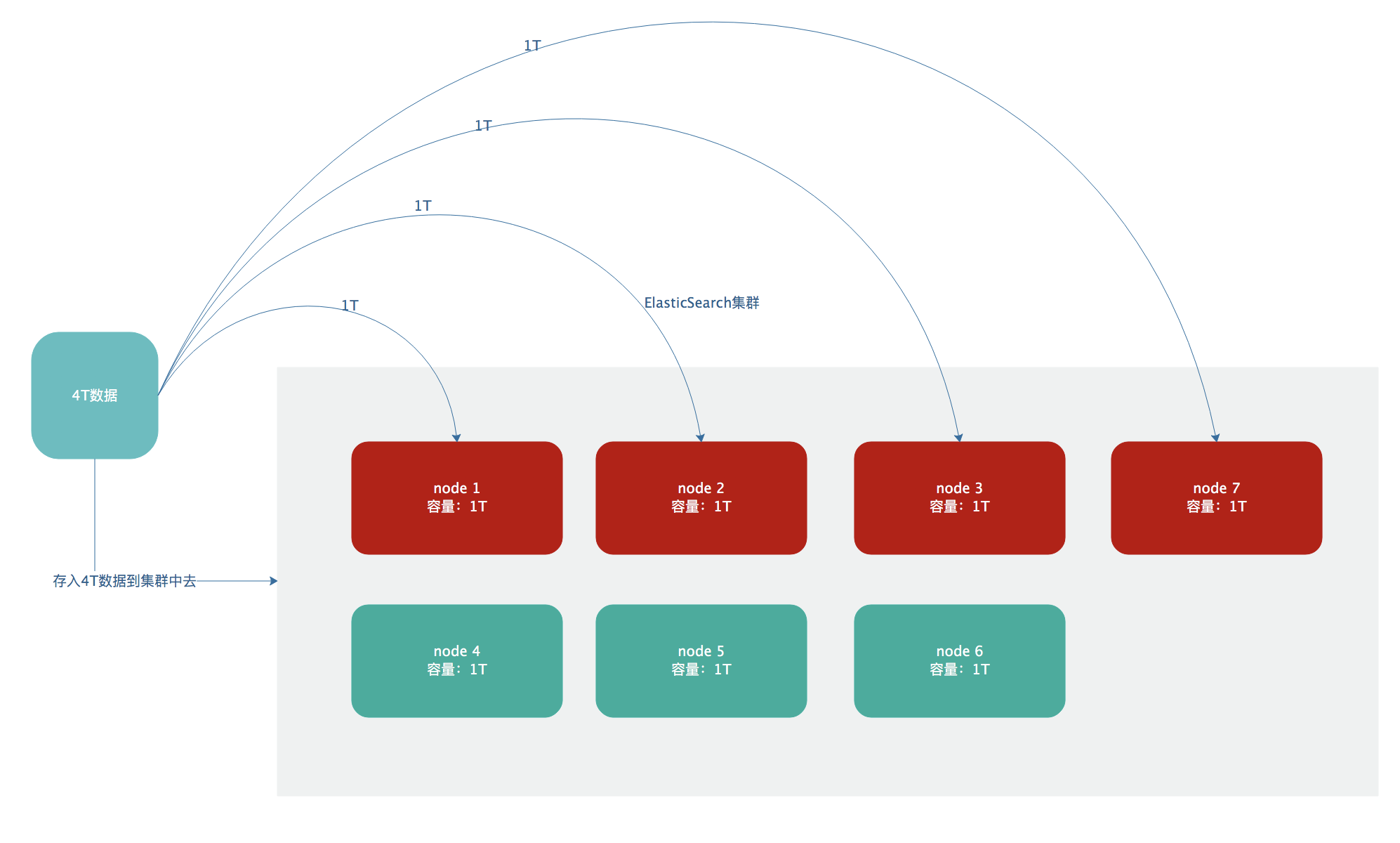
- 现在我们有这么一个需求,要求将3T数据存储在ES集群中,但是我们的每个节点最大容量只有1T,这时候单台服务器就容不下我们的数据。

- 这个时候我们就需要将这个3T的数据拆分成3份存在3个节点上面(不要说这里有6台服务器,为什么不每台服务器存500G呢,我不接受抬杠😄,开玩笑的啦,后面会解释这剩余3台服务器的用处),那么就能存下这次的数据了。这个时候就引出了shards的概念了,简单来说就是index会被拆分为多个shard(具体被拆分为几个shard是可以配置的,后面再说),每个shard存放了这个index的部分数据,然后这些shard会散落在多台服务器上面。

- shard的好处,第一点,横向扩展,比如说我们数据量增加到了4T的时候,只需要增加一个节点,然后建立一个有4个shard的索引,在将之前的有3个shard的索引的数据倒过来就行了(倒数据很简单,后面会介绍)。
- shard的第二点好处就是,数据分布在多个shard上,多台服务器上面所有的操作都会分布在多台服务器上面并行分布式执行,提神吞吐量和性能,比如说如果只有一个节点,那么所有的请求过来了过后,所有的压力都只有一台服务器来承担。举例,如果现在单台服务器承受的压力只有2000,那么4台服务器就可以承受8000的访问量了。
replica 分片副本
它的作用就是shard的备份,直接上例子,比如我们的节点7宕机了,那么这个节点上面的数据就丢失了无法获取该节点上面的数据,这个时候估计你们也猜到,replica的用处了,它就是shard的备份,如果某个主节点宕机了,那么就会到节点的备份分片replica上面去查询数据(replica的作用不仅仅只有备份,还可以提高吞吐量等等),一个replica存储的数据和shard上是一样的。