

1. 概述
数据服务(ds-cn-shanghai.data.aliyun.com) 是DataWorks产品家族的一员,提供了快速将数据表生成API的能力,通过可视化的向导,一分钟“零代码”就可以生成API,让API开发从未有过如此便捷!同时支持自定义API查询SQL功能,对您的个性化复杂查询逻辑支持照样不在话下。
DataWorks数据服务提供HTTP API服务,采用Serverless架构,您只需关注API本身的查询逻辑,无需关心运行环境等基础设施,零运维成本。
DataWorks提供了涵盖“数据集成-数据开发-机器学习-数据服务”全链路数据研发平台,数据服务作为连接数据应用与数据仓库的桥梁,通过MaxCompute Lightning加速引擎,数据服务可以直接将原本只能离线查询的MaxCompute表直接生成数据API并进行实时查询,免去了您手工同步数据的烦恼,数据服务是您将数仓建设成果服务化输出的最佳工具。
目前,DataWorks数据服务已经与数据可视化的神器——DataV(data.aliyun.com/visual/data…深度打通,数据服务生成的API,可以直接在DataV中进行可视化展现。您无需手工同步数据,无需编写复杂的Java代码,无需搭建WebServer,普通数据开发工程师、算法开发工程师、数据分析师甚至是产品业务人员,都可以使用数据服务“开发”数据API,然后快速在DataV中调用API和展示来自MaxCompute的数据成果。数据服务为您解决了从数仓开发和数据大屏展现之间的最后一公里。
本文将重点介绍通过数据服务快速将MaxCompute表生成实时查询API并对接DataV进行大屏分析展现的使用方法。
2. 使用数据服务一分钟生成API
通过数据服务生成API主要包含创建数据源->配置API->发布API三个步骤,本文将简要介绍使用方法。
2.1 新建数据源
数据服务支持丰富的数据源类型,基本上常见数据源都囊括了,包含:
关系型数据库:RDS/DRDS/MySQL/PostgreSQL/Oracle/SQL Server
分析型数据库:AnalyticDB(ADS)
NoSQL数据库:TableStore(OTS)/MongoDB
大数据存储:Lightning(MaxCompute)
在数据服务中的“服务开发”点击新建按钮,在下拉菜单中选择“新建数据源”。
随后将打开数据集成中的数据源页面,在这里可以新建您需要访问的数据源。
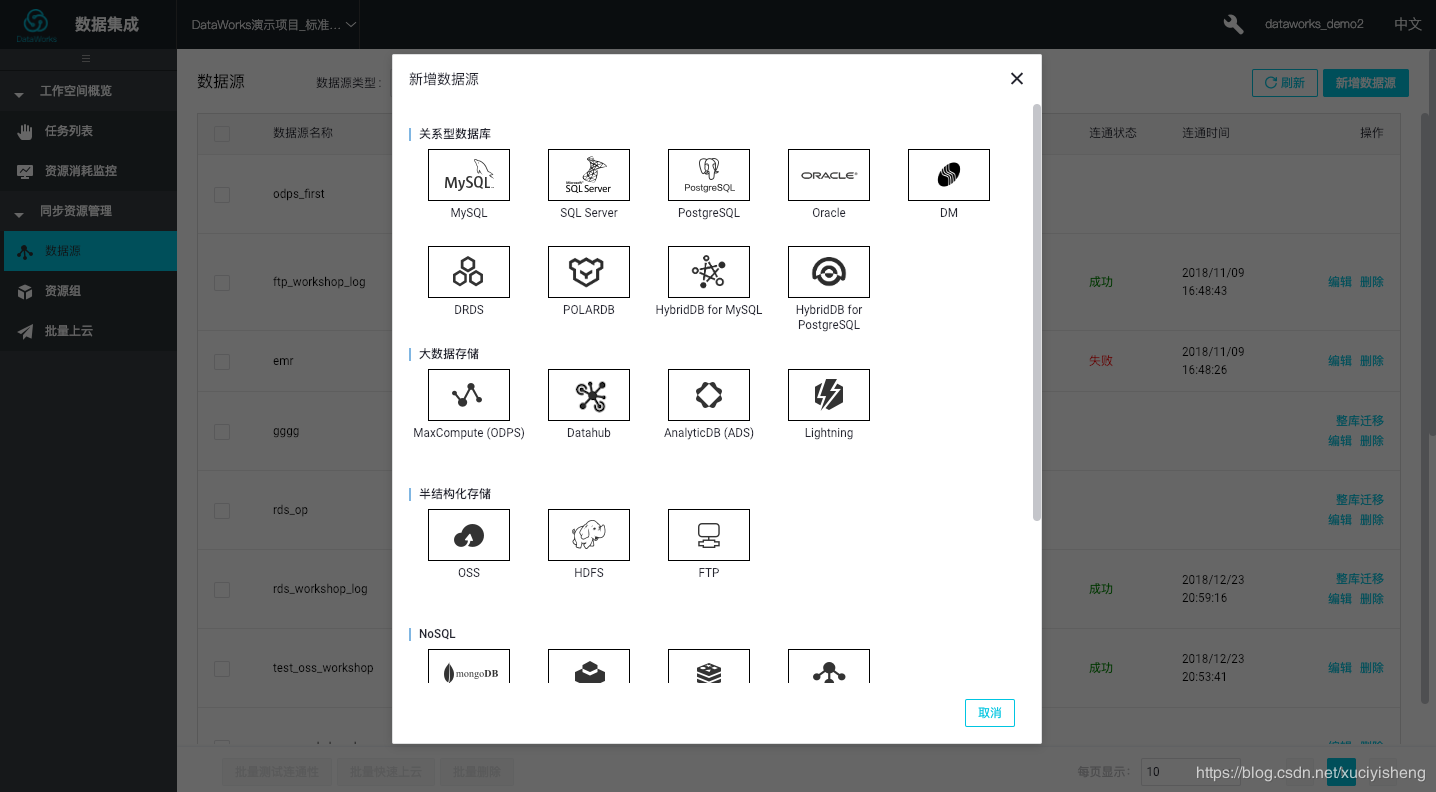
本文将以Lightning数据源为例。通过Lighning数据源可以直接实时查询MaxCompute中的数据。只要开通了MaxCompute服务就可以直接使用Lightning服务。
点击“新建数据源”,选择“Lightning”,按页面提示进行配置,测试连通性测试通过后即可。您可以点击这里(help.aliyun.com/document_de…)查看Lightning的连接信息,如Lightning Endpoint、Port。
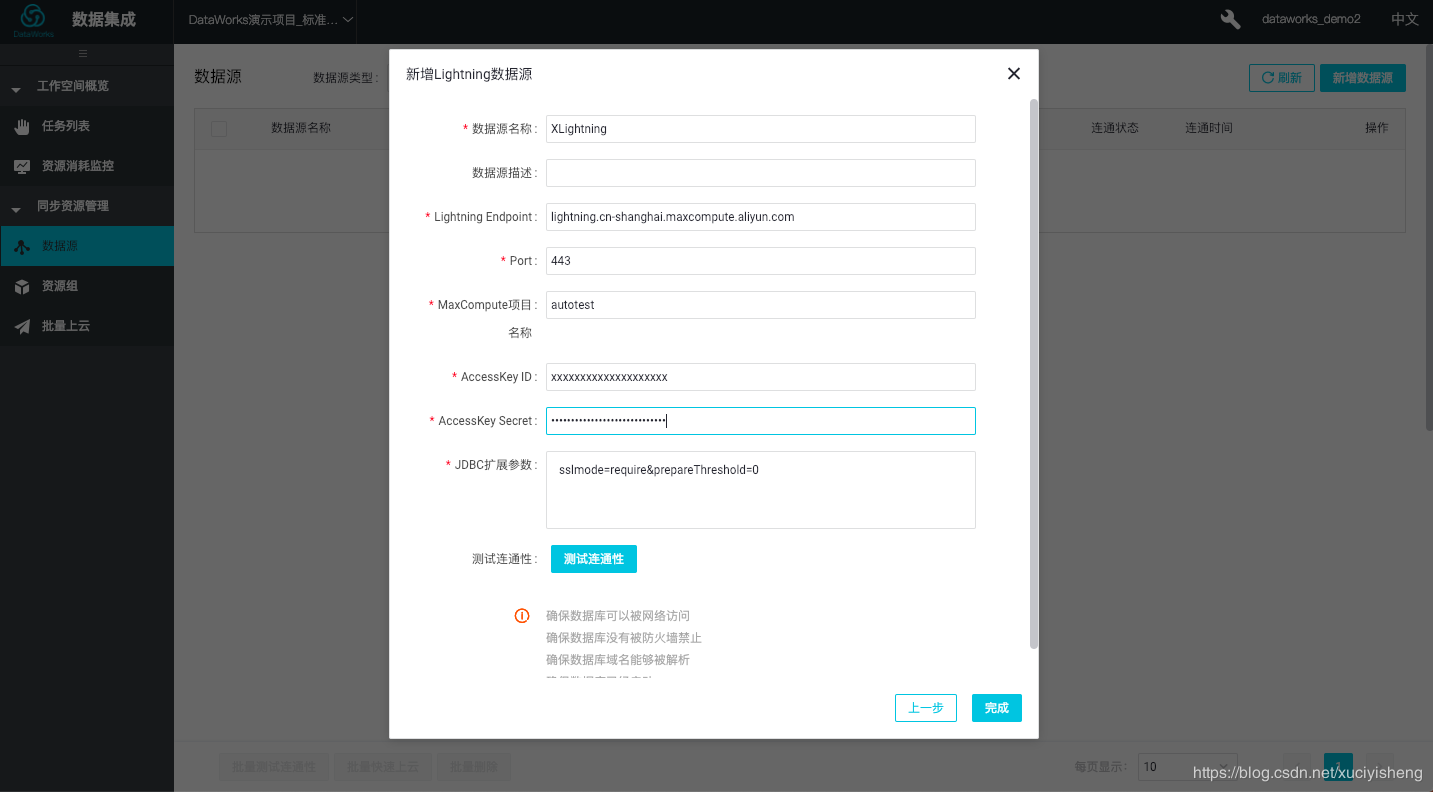
注意:JDBC扩展参数中的“sslmode=require&prepareThreshold=0”是必须的,不可删除,否则会无法连接。
2.2 新建API
创建好数据源后,回到数据服务产品页面,我们就可以进行API的生成配置了,本文以向导模式生成API为例。
点击"服务开发"-“新建”-“生成API”-“向导模式”,以向导模式可视化配置的方式生成API。在弹出的对话框中填写API基本信息,这里以查询成交金额增长趋势API为例,如下所示:
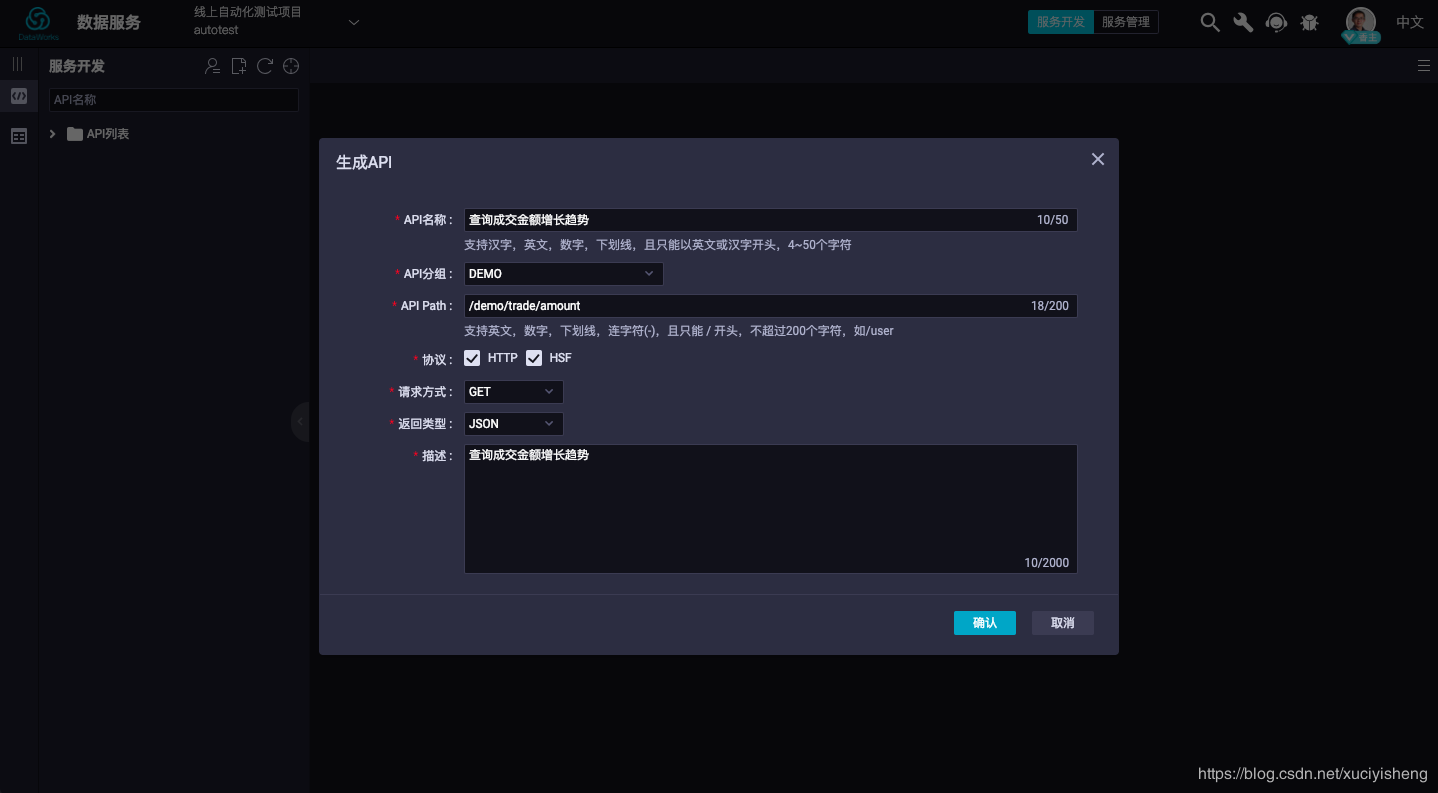
点击确认后,进行API配置页面。
首先进行表设置,依次选择数据源类型-数据源名称-数据表名称。这里选择上一步创建的Lightning数据源,然后选择你要查询的MaxCompute表,这里以成交金额表“demo_trade_amount”为例,该表中存储了一个月的成交金额数据。
选择好表之后,会自动展示表的字段列表。然后勾选你要作为API请求参数的字段和作为返回参数的字段。在本例中,我们为了查询成交金额趋势,因此要返回所有数据,即将日期和成交金额都作为返回参数,不设请求参数。
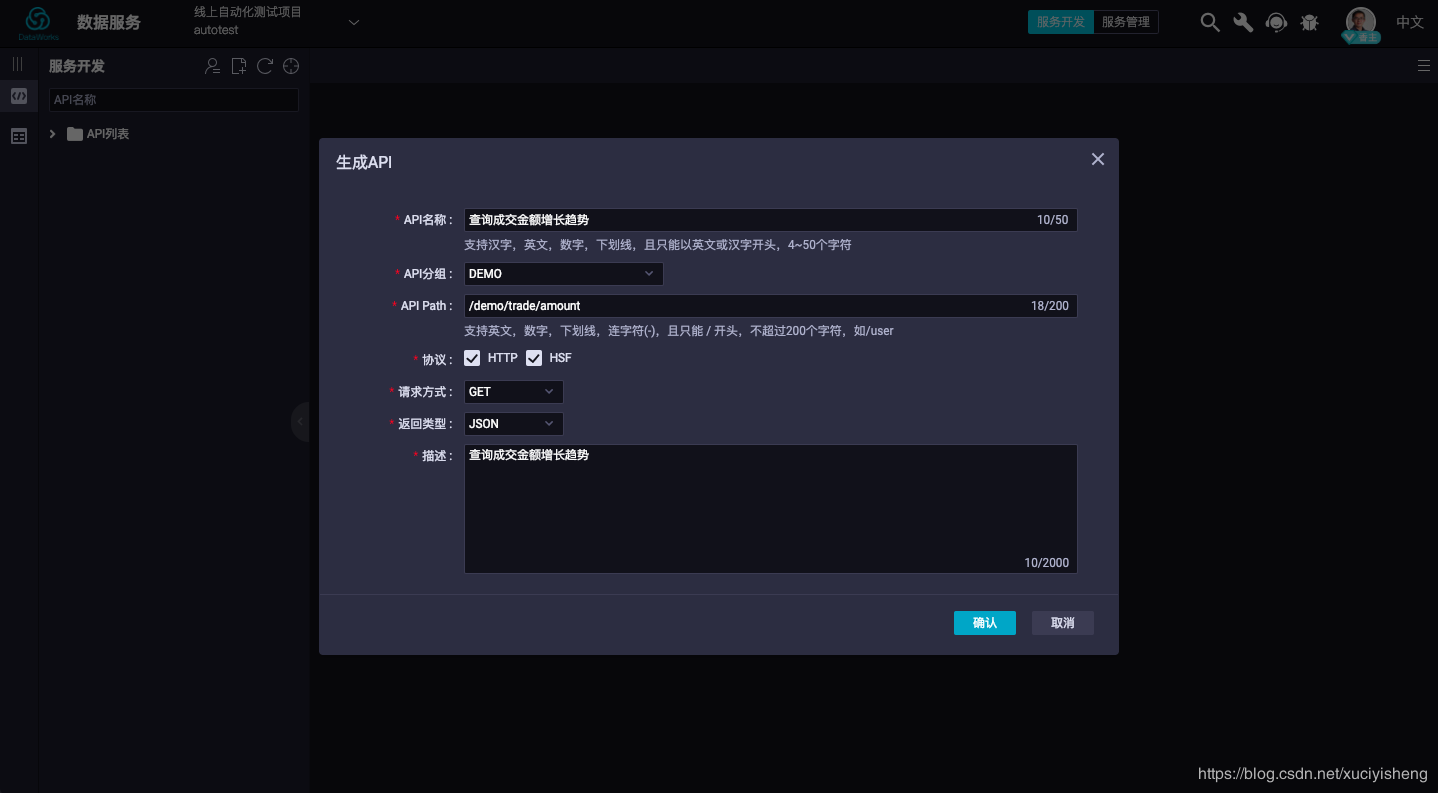
然后点击右侧的“返回参数”,设置参数描述信息。
注意:如果不设置请求参数,则需要开启“返回结果分页”开关,进行分页查询,以避免单次查询返回数据量过大影响性能。
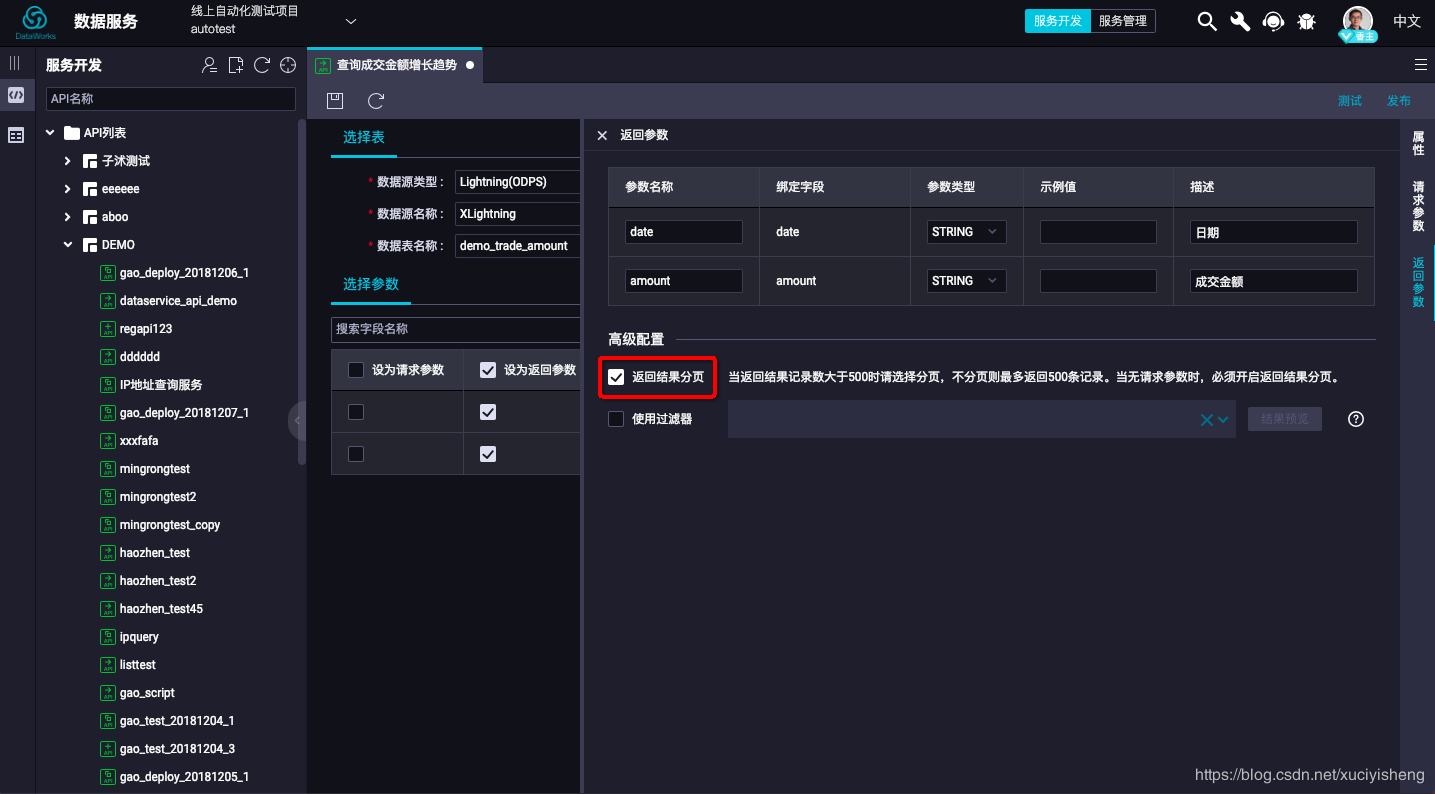
最后进行API测试。点击工具条右边的“测试”,填写API请求参数(由于打开了分页查询开关,系统会自动添加两个分页参数),点击“开始测试”即可,如下图所示。
在测试页面中可以看到API延迟,可以看到通过Lightning查询MaxCompute表只花费了1秒多,比直接通过MaxCompute SQL查询快了几十上百倍!
到此,一个API就已经生成好了,是不是超简单!
2.3 发布API
API测试通过后就可以进行发布。点击工具条右方的“发布”即可将API发布。发布后,可以点击项部导航条中的“服务管理”查看API详情。若您要调用API,请查看“服务管理”-“API调用”页面,数据服务提供了简单身份认证(AppCode)和加密签名身份认证(AppKey&AppSecret)两种认证方式,您可以自由选择。下方将介绍在DataV中进行数据服务API的调用。
是不是有点小激动?“开发”一个API如来没有过如此简单!这简直不能称之为“开发”!
3. 在DataV中调用数据服务的API
接下来要进行DataV数据大屏的配置,主要分为“添加数据”-“新建可视化”两个步骤。
3.1 添加数据服务为数据源
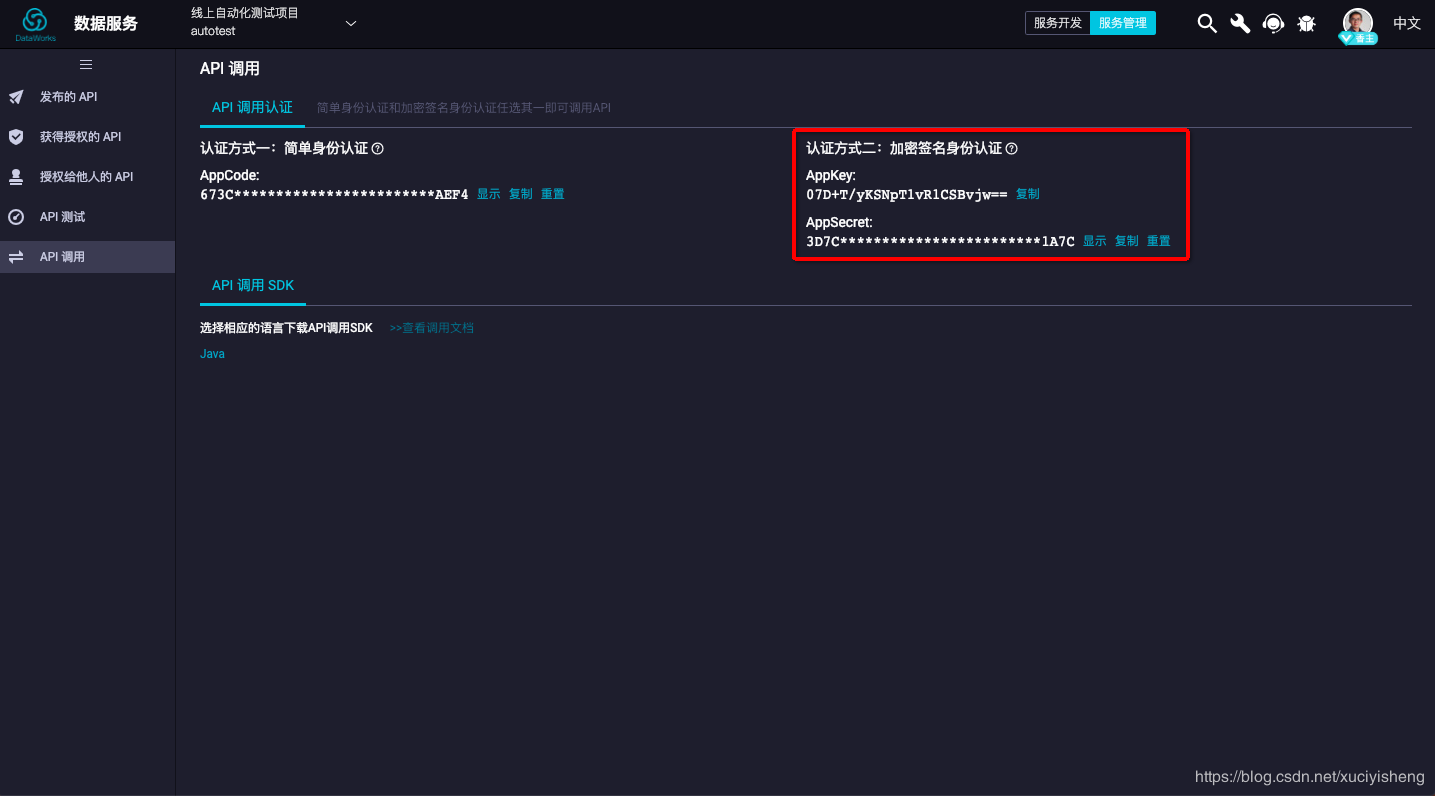
依次点击“我的数据”-“添加数据”,在“类型”中选择“DataWorks数据服务”,填写数据源名称,然后选择您的DataWorks项目(工作空间)。DataV对接数据服务采用的是更加安全的加密签名身份认证,因此这里需要填写AppKey和AppSecret。
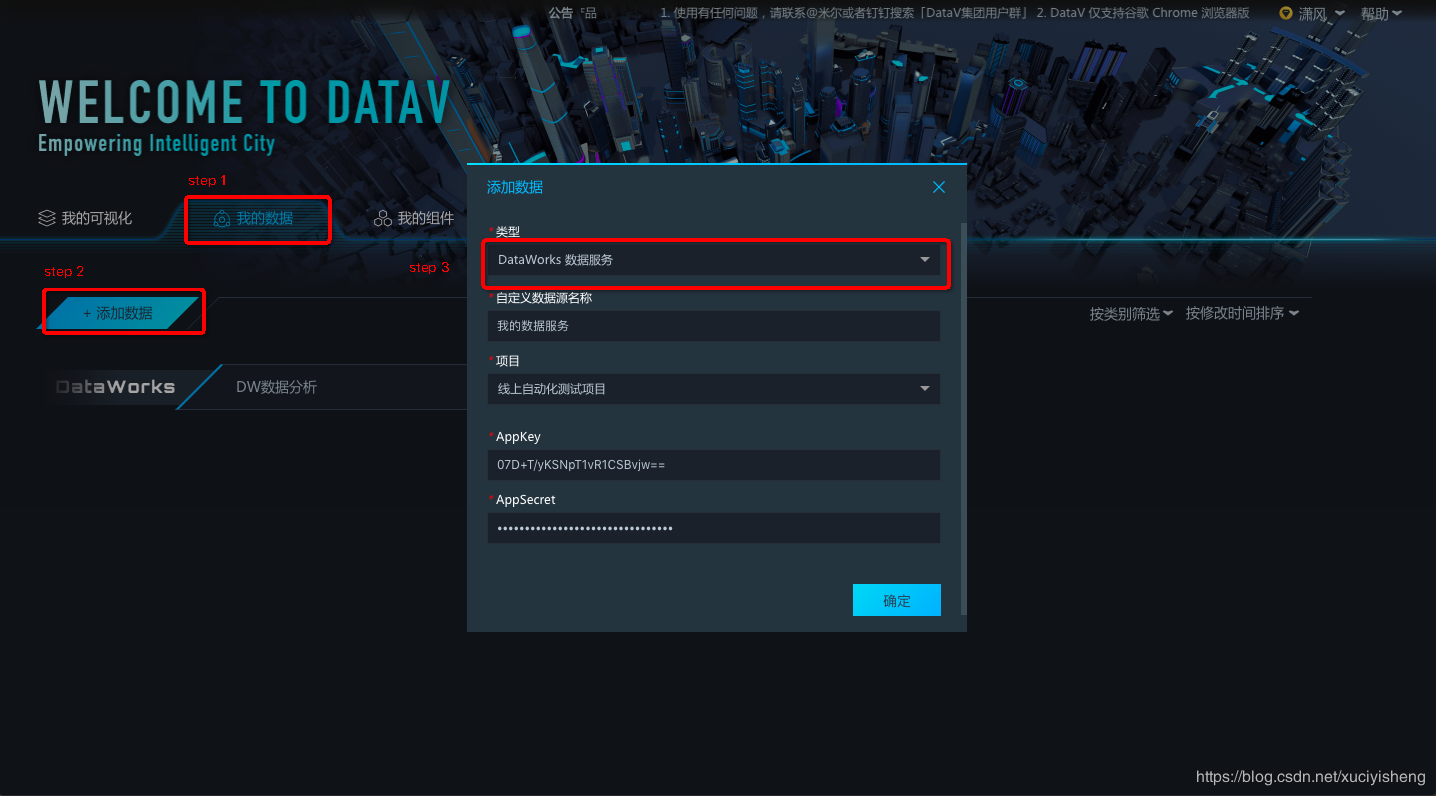
AppKey和AppSecret从数据服务的“服务管理”-“API调用”页面中查看,如下所示:
添加好数据服务数据源后,就可以在大屏中进行数据展示了。
3.2 在大屏中调用数据服务API
在“我的可视化”中点击“新建可视化”,本文选择了“智能工厂”模板,如下所示:
模板中的组件自带了静态数据,下面将通过将模板中间的“基本折线图”改为调用上面创建好的“查询成交金额增长趋势”的API为例,讲解如何在组件中使用数据服务API。
选中基本折线图组件,切换到数据面板,在“数据源类型”中选择“DataWorks数据服务”,然后选择刚刚创建的数据源“我的数据服务”,选择“查询成交金额增长趋势”这个API,再设置查询参数,这里将pageSize设置为“31”以查询一个月的数据。
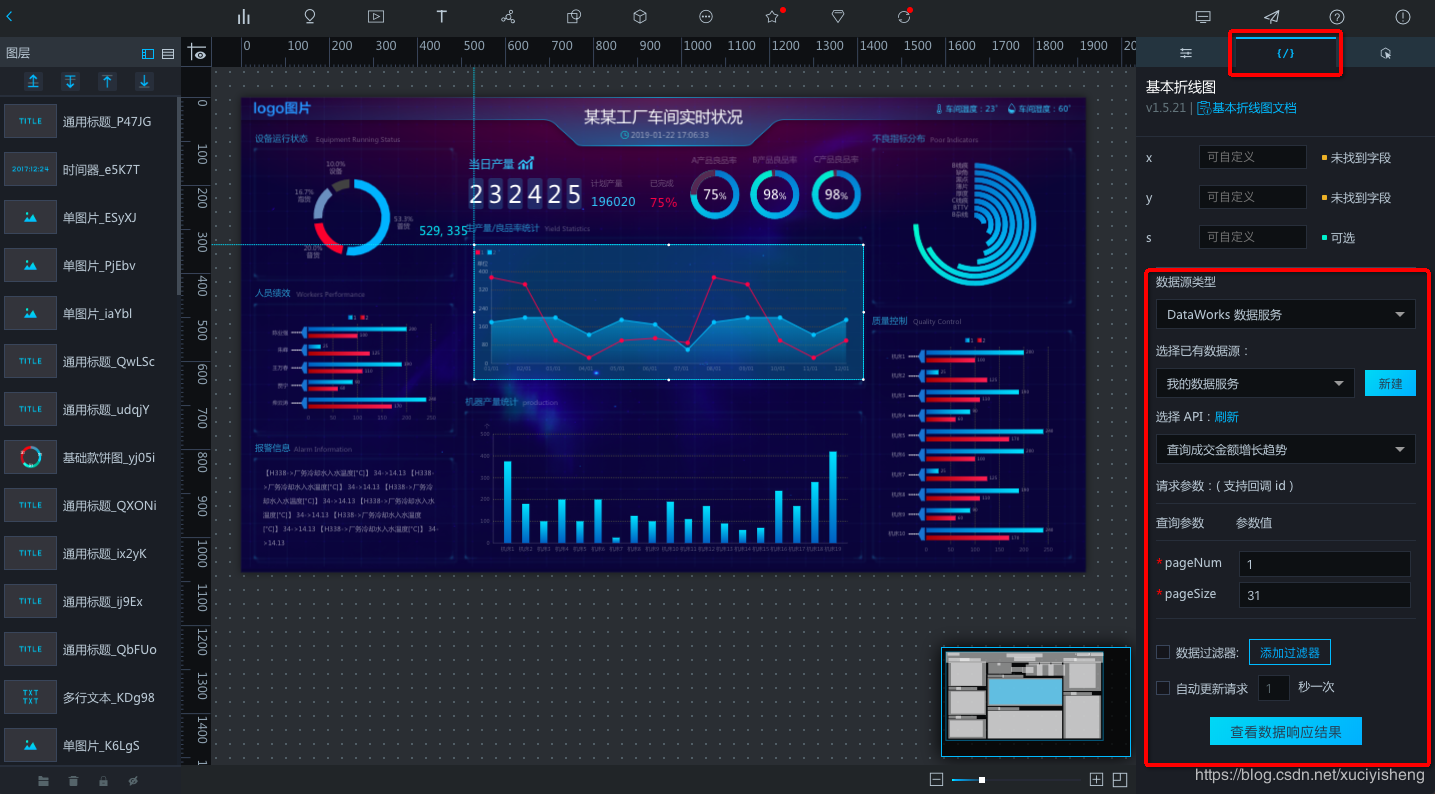
点击“查看数据响应结果”可以看到API的查询结果。
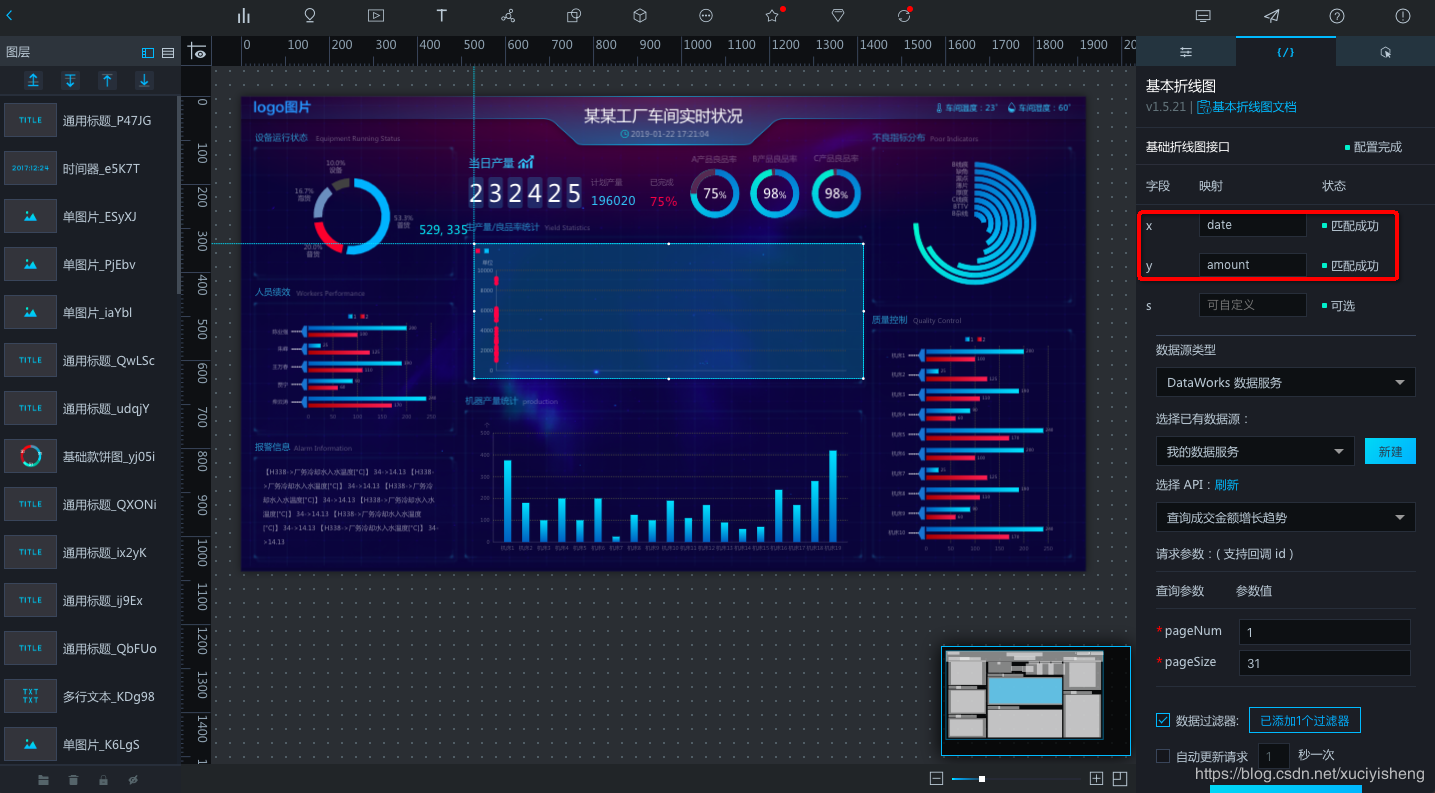
然后填写字段映射关系,在“x”中填写“date”将日期作为横轴,在“y”中填写“amount”将成交金额作为纵轴。
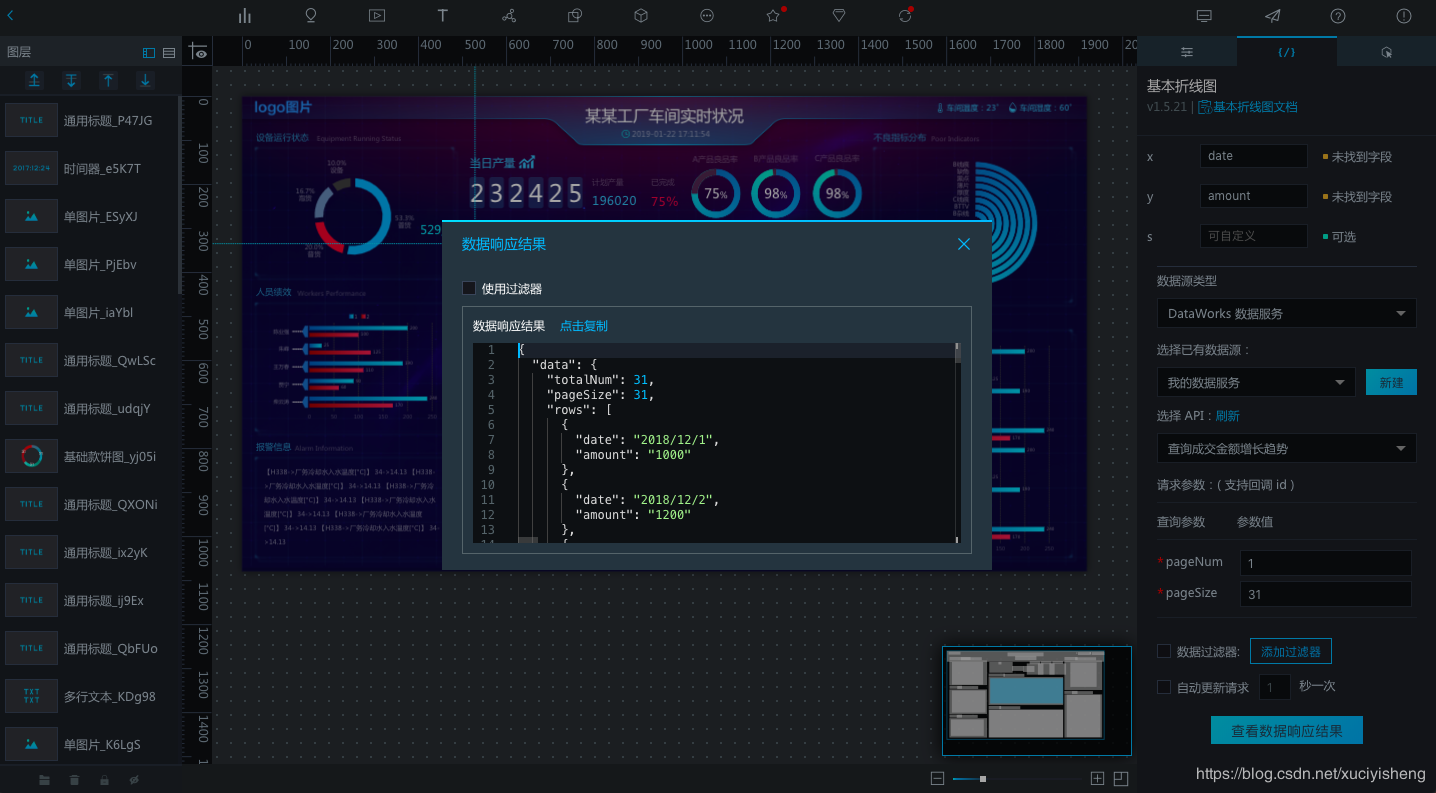
可以看到,当前x和y无法匹配到字段。这是由于DataV对数据格式有一定要求,不能识别结构较深的字段,因此这里要添加一个数据过滤器,过滤掉不必要的字段,在本例中直接返回“rows”数组即可。
勾选“使用过滤器”,点击“新建过滤器”,这里支持编写JS代码对数据结果进行二次过滤和处理,过滤器的data参数为API返回结果JSON对象。在本例中,我们只需要返回API结果中的rows数组,故只需要输入代码 "return data.data.rows;" 即可,然后在下方就可以查看过滤后的结果,点击“完成”即可。
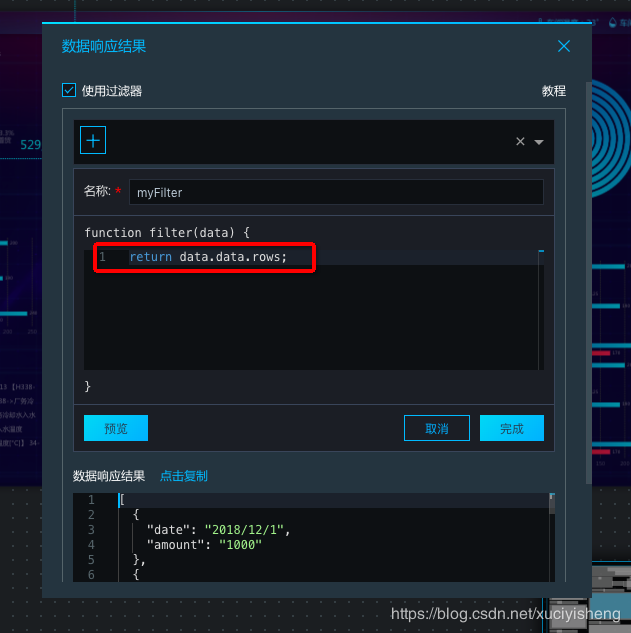
添加好过滤器后就可以看到此时字段已经可以匹配成功了。
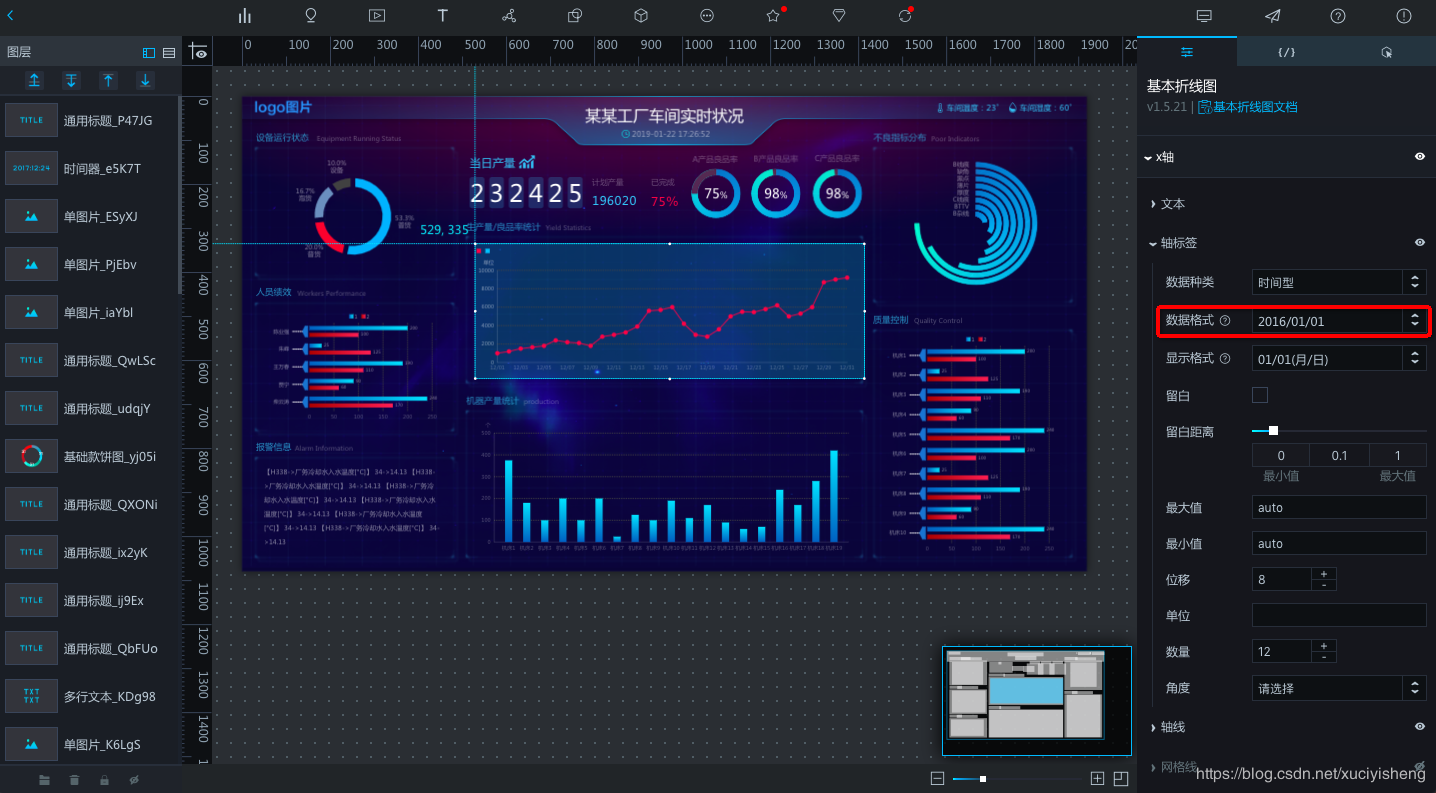
但此时折线图并没有正确展示,由于API返回的日期格式与组件默认的格式不一样,因此我们还需要设置一下折线横轴的日期格式。切换到“配置”面板,在“x轴”-“轴标签”中选择数据种类为“时间型”,数据格式选择本API所返回的格式“2016/01/01”,即可看见折线图已经可以正常展示了。
最后预览一下,看看成品。
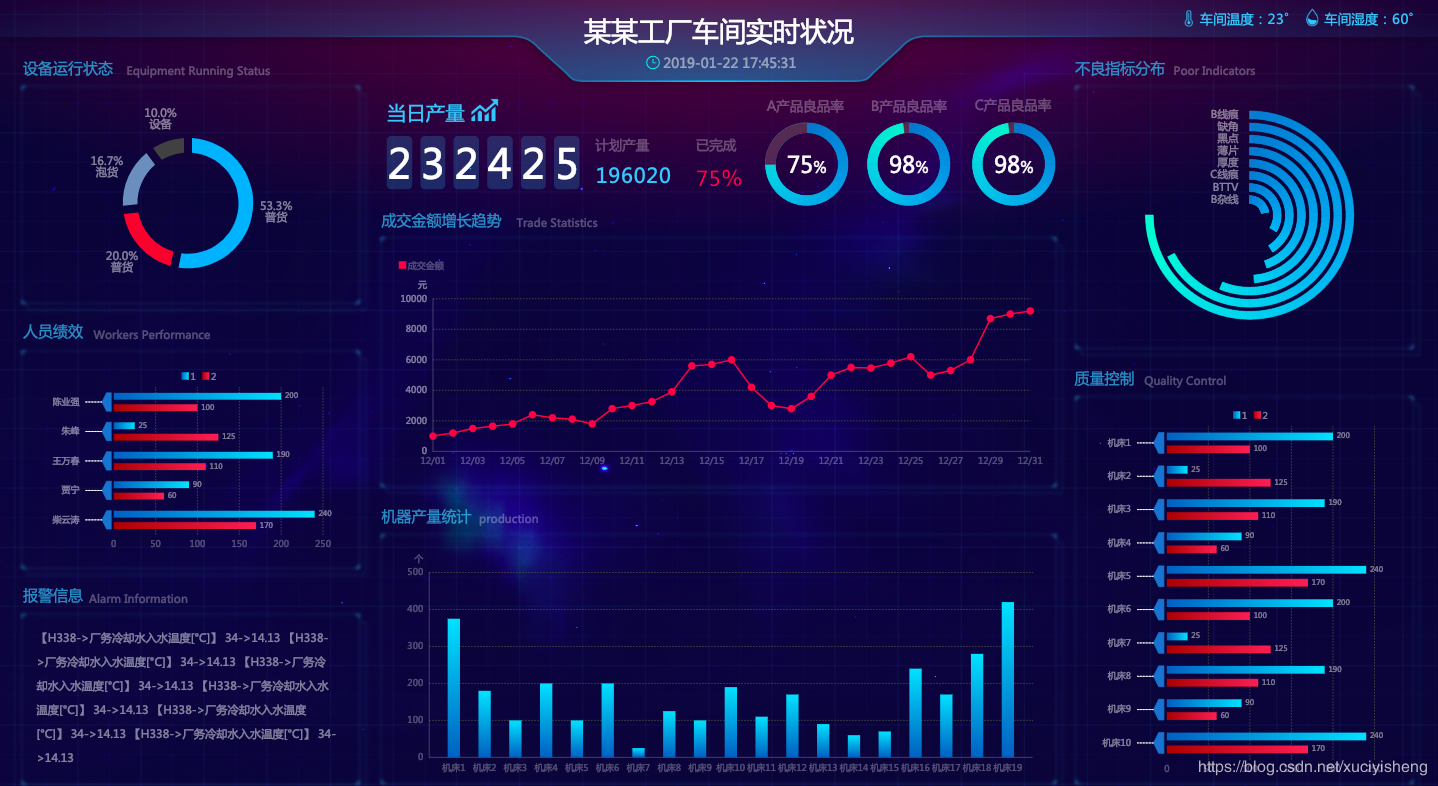
至此,我们就完成了通过数据服务将MaxCompute表生成API,然后在DataV数据大屏中进行展示的所有步骤。采用类似的步骤,将大屏的其他组件的数据源都配置为DataWorks数据服务API就可以完成整个大屏的创作,是不是感觉很easy!
4. 总结
DataWorks数据服务与DataV进行无缝打通后,则不需要使用DataV中的"API"数据源去填写一个URL调用API,直接新建一个DataWorks数据服务作为数据源,就可以直接选用数据服务中的API,无需每个API都设置AppKey和AppSecret认证信息,并且支持通过表单填写API参数,使用起来十分快捷方便和安全可靠。通过数据服务,您可以将MaxCompute中加工好的数据结果,直接在DataV中进行呈现,“数据开发-数据服务-数据分析展现”一气呵成!
最后,提供一些小贴士及注意事项,供大家参考:
- DataWorks数据服务向导模式生成API只支持单表简单条件查询,脚本模式支持用户编写查询SQL语句,支持多表关联查询、函数以及复杂条件。大家可以根据自己的需求灵活选择。
- Lightning采用的PostgreSQL的语法,故在编写SQL时,要注意使用PostgreSQL函数,而不是MaxCompute的UDF。目前Lightning还只支持max_pt这个MaxCompute UDF,可用于获取当前最新分区。还有,连接字符串时使用“||”。
- Lightning目前只支持秒级查询,并且查询的MaxCompute不宜过大(控制在GB级),尽量将分区作为请求参数,尽量避免扫描过多分区,否则会比较慢。
- 如果您要求毫秒级API查询,则建议采用关系型数据库、NoSQL数据库或AnalyticDB作为数据源。
- DataV组件要求的数据格式是个数组,数据服务生成的API返回结果是个带有错误码的完整JSON,因此要使用过滤器对API结果进行处理。您可以选择在DataV中添加过滤器,也可以选择直接在数据服务配置API时添加过滤器。一般来说,对于未分页查询的API,直接返回“data”数组就行,对于分页查询的API直接返回“data.rows"数组。
- 若你要在DataV的折线图或柱状图中添加多个系列,DataV一般要求每个系列的数据是一个对象,并通过字段“s”来区分系列,此时要注意使用过滤器进行格式转换。
